目标检测和实例分割是计算机视觉的基本任务,在从自动驾驶到医学成像的无数应用中发挥着关键作用。目标检测的传统方法中通常利用边界框技术进行对象定位,然后利用逐像素分类为这些本地化实例分配类。但是当处理同一类的重叠对象时,或者在每个图像的对象数量不同的情况下,这些方法通常会出现问题。
诸如Faster R-CNN、Mask R-CNN等经典方法虽然非常有效,但由于其固有的固定大小输出空间,它们通常预测每个图像的边界框和类的固定数量,这可能与图像中实例的实际数量不匹配,特别是当不同图像的实例数量不同时。并且它们可能无法充分处理相同类的对象重叠的情况,从而导致分类不一致。
本文中将介绍Facebook AI Research在21年发布的一种超越这些限制的实例分割方法MaskFormer。可以看到从那时候开始,FB就对Mask和Transformer进行整合研究了。
1、逐像素分类和掩码分类的区别
逐像素分类
该方法指的是为图像中的每个像素分配一个类标签。在这种情况下,每个像素都被独立处理,模型根据该像素位置的输入特征预测该像素属于哪个类。对于边界清晰、定义明确的对象,逐像素分类可以非常准确。但是当感兴趣的对象具有复杂的形状,相互重叠或位于杂乱的背景中时,它可能会遇到困难,这可以解释为这些模型倾向于首先根据其空间边界来查看对象。
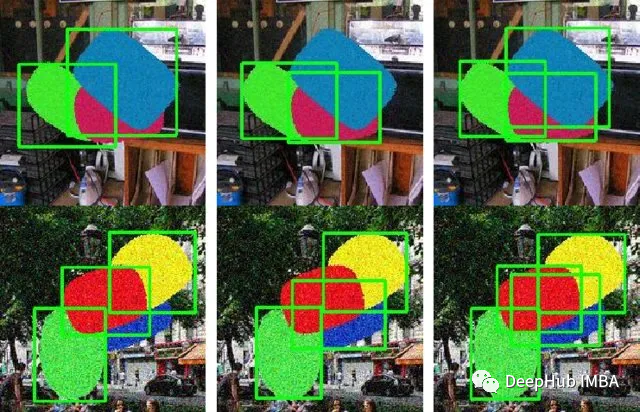
考虑一幅描绘多辆重叠汽车的图像。传统的实例分割模型(如逐像素模型)可能难以应对如下所示的情况。如果汽车重叠,这些模型可能会为整个重叠的汽车创建一个单一的并且是合并后的掩码。可能会把这个场景误认为是一辆形状奇怪的大型汽车,而不是多辆不同的汽车。

掩码分类
掩码分类(在MaskFormer中使用)采用了不同的方法。掩码分类模型不是独立对每个像素进行分类,而是为图像中的每个对象实例预测特定于类的掩码。这个掩码本质上是一个二值图像,表示哪些像素属于对象实例,哪些不属于。换句话说,单个遮罩代表整个对象,而不仅仅是单个像素。
在前一个例子中,使用掩码分类使我们能够识别图像中有多个“car”类实例,并为每个实例分配一个唯一的掩码,即使它们重叠。每辆车都被视为一个独立的实例,并被赋予自己独特的面具,以保持其与其他汽车分开的身份。
使用掩码分类/分割的模型示例:掩码R-CNN, DETR, Max-deeplab…
DETR
DETR的核心是一个被称为Transformer的强大机制,它允许模型克服传统逐像素和掩码分类方法的一些关键限制。
在传统的掩模分类方法中,如果两辆车重叠,可能难以将它们区分为不同的实体。而DETR为这类问题提供了一个优雅的解决方案。DETR不是为每辆车生成掩码,而是预测一组固定的边界框和相关的类概率。这种“集合预测”方法允许DETR以惊人的效率处理涉及重叠对象的复杂场景。

虽然DETR彻底改变了边界框预测,但它并没有直接提供分割掩码——这是许多应用程序中至关重要的细节。这时就出现了MaskFormer:它扩展了DETR的鲁棒集预测机制,为每个检测到的对象创建特定于类的掩码。所以MaskFormer建立在DETR的优势之上,并增强了生成高质量分割掩码的能力。
比如在上面提到的汽车场景中,MaskFormer不仅将每辆车识别为一个单独的实体(感谢DETR的集合预测机制),而且还为每辆车生成一个精确的掩码,准确捕获它们的边界,即使在重叠的情况下也是如此。

DETR和MaskFormer之间的这种协同作用为更准确、更高效的实例分割打开了一个可能性的世界,超越了传统的逐像素和掩码分类方法的限制。
MaskFormer
下面是MaskFormer的架构:
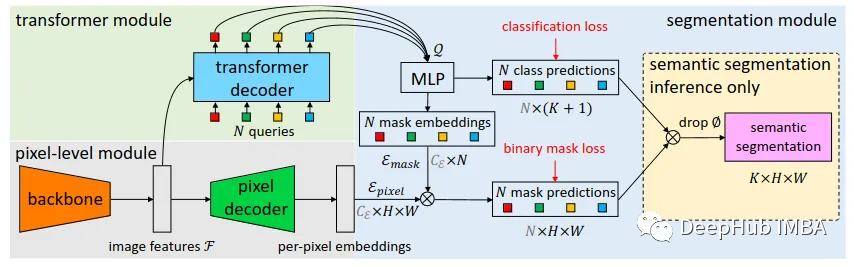
通过主干提取特征:MaskFormer主干网络负责从输入中提取关键的图像特征。这个主干可以是任何流行的CNN(卷积神经网络)架构,比如ResNet,它处理图像并提取一组特征,用F表示。
逐像素嵌入生成:然后将这些特征F传递给像素解码器,该解码器逐渐对图像特征进行上采样,生成我们所说的“逐像素嵌入”(E像素)。这些嵌入捕获图像中每个像素的局部和全局上下文。
段(Per-Segment )嵌入生成:与此同时,Transformer Decoder关注图像特征F并生成一组“N”段嵌入,用Q表示,通过“注意力”的机制为图像的不同部分分配不同的重要性权重。这些嵌入本质上代表了我们想要分类和定位的图像中的潜在对象(或片段)。
这里的术“Segment ”是指模型试图识别和分割的图像中对象的潜在实例。
一般来说,编码器处理输入数据,解码器使用处理后的数据生成输出。编码器和解码器的输入通常是序列,就像机器翻译任务中的句子一样。
而maskformer的“编码器”是骨干网络(用于maskFormer的Resnet50),它处理输入图像并生成一组特征映射。这些特征映射与传统Transformer中的编码器输出具有相同的目的,提供输入数据的丰富的高级表示。
然后使用这些嵌入Q来预测N个类标签和N个相应的掩码嵌入(E掩码)。这就是MaskFormer真正的亮点所在。与传统分割模型预测每个像素的类标签不同,MaskFormer预测每个潜在对象的类标签,以及相应的掩码嵌入。
在获得掩码嵌入后,MaskFormer通过像素嵌入(E像素)与掩码嵌入(E掩码)之间的点积产生N个二进制掩码,然后进行s型激活。这个过程可能会将每个对象实例的二进制掩码重叠。
最后对于像语义分割这样的任务,MaskFormer可以通过将N个二进制掩码与其相应的类预测相结合来计算最终预测。这种组合是通过一个简单的矩阵乘法实现的,给我们最终的分割和分类图像。
MaskFormer用于语义和实例分割
语义分割涉及到用类标签标记图像的每个像素(例如“汽车”,“狗”,“人”等)。但是它不区分同一类的不同实例。例如如果图像中有两个人,语义分割会将所有属于这两个人的像素标记为“人”,但它不会区分A和B。
而实例分割不仅对每个像素进行分类,而且对同一类的不同实例进行分离。比如实例分割需要将所有属于A的像素标记为“A”,所有属于B的像素标记为“B”。

大多数传统的计算机视觉模型将语义分割和实例分割视为独立的问题,需要不同的模型、损失函数和训练过程。但是MaskFormer设计了一个统一的方式处理这两个任务:它通过预测图像中每个对象实例的类标签和二进制掩码来工作。这种方法本质上结合了语义和实例分割的各个方面。
对于损失函数,MaskFormer使用统一的损失函数来处理这个掩码分类问题。这个损失函数以一种与语义和实例分割任务一致的方式评估预测掩码的质量。
所以使用相同的损失函数和训练过程得到的的MaskFormer模型可以不做任何修改地同时应用于语义和实例分割任务。
总结
MaskFormer提供了一种新的图像分割方法,集成了DETR模型和Transformer架构的优点。它使用基于掩码的预测,增强了对图像中复杂对象交互的处理。
MaskFormer的统一方法在图像分割方面向前迈出了一大步,为计算机视觉的进步开辟了新的可能性。它为进一步的研究奠定了基础,旨在提高我们理解和解释视觉世界的能力。
论文地址:
https://avoid.overfit.cn/post/3f38050c2a794e33ac9ee66642740fd3
作者:HannaMergui