目录
- 1. 什么是Python中的装饰器?如何使用装饰器?
- 2. 什么是Python中的迭代器和生成器?它们有什么区别?
- 3. Python中的GIL是什么?它如何影响多线程应用程序?
- 4. 什么是Python中的元类?如何使用元类?
- 5. 如何在Python中实现单例模式?
- 6. Python中的多重继承是什么?如何使用多重继承?
- 7. Python中的协程是什么?如何使用协程?
- 8. 如何在Python中使用上下文管理器?
- 9. 什么是Python中的闭包?如何使用闭包?
- 10. Python中的内存管理是什么?如何优化Python应用程序的内存使用?
- 总结
本文将介绍Python中常见的高级特性,包括装饰器、迭代器和生成器、GIL、元类、单例模式、多重继承、协程、上下文管理器、闭包和内存管理。每个特性都将详细解释其概念、用法和相关注意事项,以帮助读者更好地理解和应用这些特性。
1. 什么是Python中的装饰器?如何使用装饰器?
Python中的装饰器是一种特殊的函数,它可以用来修改其他函数的行为。装饰器可以在不修改原函数代码的情况下,为函数添加额外的功能。
装饰器本质上是一个函数,它接受一个函数作为参数,并返回一个新的函数。在Python中,装饰器使用@符号来表示,可以将其放在函数定义的上方。
下面是一个简单的装饰器示例,它可以用来计算函数的执行时间:
import time
def timer(func):
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print('函数 %s 执行时间为 %f 秒' % (func.__name__, end_time - start_time))
return result
return wrapper
@timer
def my_func():
# 执行一些操作
pass
my_func()
运行结果:

在上面的示例中,我们定义了一个名为timer的装饰器函数,它接受一个函数作为参数,并返回一个新的函数wrapper。wrapper函数用来计算函数的执行时间,并输出结果。然后,我们使用@符号将装饰器应用到my_func函数上。
通过使用装饰器,我们可以在不修改my_func函数的情况下,为其添加额外的功能。在这个例子中,我们为my_func函数添加了计时功能。
需要注意的是,装饰器可以被链式调用,即一个装饰器可以装饰另一个装饰器。此外,装饰器还可以带有参数,以便更灵活地控制其行为。
2. 什么是Python中的迭代器和生成器?它们有什么区别?
Python中的迭代器和生成器是两个非常重要的概念,它们都可以用来遍历序列,但是它们之间有一些区别。
迭代器是一个对象,它可以遍历一个可迭代对象(如列表、元组、字典等),并且可以使用next()方法获取下一个元素。当迭代器遍历完所有元素后,再次调用next()方法会抛出StopIteration异常。在Python中,可以使用iter()函数将一个可迭代对象转换成一个迭代器。
生成器是一种特殊的迭代器,它可以通过函数来实现。生成器使用yield关键字来产生值,每次调用next()方法时,函数会执行到yield语句处,并返回一个值。当函数执行完毕后,会自动抛出StopIteration异常。在Python中,生成器可以使用函数来定义,以便生成一个可迭代的序列。
下面是一个简单的示例,展示了如何使用迭代器和生成器:
my_list = [1, 2, 3, 4, 5]
my_iterator = iter(my_list)
print(next(my_iterator)) # 输出1
print(next(my_iterator)) # 输出2
print(next(my_iterator)) # 输出3
# 生成器示例
def my_generator():
yield 1
yield 2
yield 3
gen = my_generator()
print(next(gen)) # 输出1
print(next(gen)) # 输出2
print(next(gen)) # 输出3
输出结果:
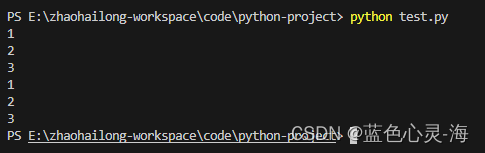
在上面的示例中,我们首先使用iter()函数将一个列表转换成一个迭代器,然后使用next()方法遍历它。接下来,我们定义了一个生成器函数my_generator(),它使用yield关键字来产生值,并返回一个可迭代的序列。最后,我们使用next()方法遍历生成器序列。
总的来说,迭代器和生成器都可以用来遍历序列,但是它们之间有一些区别。迭代器是一个对象,它可以遍历一个可迭代对象,并且可以使用next()方法获取下一个元素。而生成器是一种特殊的迭代器,它可以通过函数来实现,并使用yield关键字来产生值。由于生成器使用函数来定义,因此它更加灵活,可以根据需要动态生成序列,而不需要预先生成一个完整的序列。
3. Python中的GIL是什么?它如何影响多线程应用程序?
Python中的GIL(全局解释器锁)是一种机制,它确保同一时间只有一个线程可以执行Python字节码。这意味着在多线程应用程序中,每个线程都必须等待其他线程释放GIL锁,才能开始执行。这种机制可以确保Python代码的线程安全性,但也会对多线程应用程序的性能产生一定的影响。
由于GIL锁的存在,Python中的多线程应用程序无法利用多核CPU的优势。即使在多核CPU上运行,Python应用程序也只能使用一个CPU核心。这是因为每个线程都必须等待其他线程释放GIL锁,才能开始执行。因此,Python中的多线程应用程序在处理CPU密集型任务时,性能通常比单线程应用程序要差。
然而,在处理I/O密集型任务时,GIL锁不会对性能产生太大的影响。这是因为在执行I/O操作时,线程会释放GIL锁,从而允许其他线程执行Python字节码。因此,Python中的多线程应用程序在处理I/O密集型任务时,仍然可以发挥一定的性能优势。
为了克服GIL锁对多线程应用程序性能的影响,可以使用多进程、协程、异步编程等技术。多进程可以利用多个CPU核心来并行执行任务,协程和异步编程可以通过非阻塞的方式来处理I/O操作,从而避免线程的阻塞。这些技术可以帮助Python开发者在处理CPU密集型和I/O密集型任务时,提高应用程序的性能。
4. 什么是Python中的元类?如何使用元类?
在Python中,元类是一种特殊的类,它可以用来创建其他类。元类可以控制类的创建过程,并可以在类定义时修改类的属性、方法等。元类是Python中的高级特性,通常用于框架、库等高级编程场景。
在Python中,可以通过定义一个继承自type的类来创建元类。这个类可以重写type的一些方法,从而实现自定义的类创建过程。例如,可以重写__new__方法来修改类的属性、方法等。以下是一个简单的元类示例:
class MyMeta(type):
def __new__(cls, name, bases, attrs):
# 修改类的属性
attrs['x'] = 1
# 创建新的类
return super().__new__(cls, name, bases, attrs)
# 使用元类创建类
class MyClass(metaclass=MyMeta):
pass
# 测试类的属性
print(MyClass.x) # 输出1
在上面的示例中,定义了一个名为MyMeta的元类,重写了type的__new__方法,用于修改类的属性。然后,使用元类创建了一个名为MyClass的类,并在类定义时指定了元类。最后,测试了MyClass的属性,输出了1。
需要注意的是,元类并不是Python中常用的特性,大多数情况下,我们可以通过类的继承、装饰器等方式来实现类的定制。元类通常用于框架、库等高级编程场景,需要对类的创建过程进行精细控制。
5. 如何在Python中实现单例模式?
在Python中,可以通过使用装饰器或元类来实现单例模式。下面分别介绍这两种方法的实现方式。
- 使用装饰器实现单例模式
使用装饰器可以将单例模式应用于任何类,具有较好的通用性。下面是一个使用装饰器实现单例模式的示例代码:
def singleton(cls):
instances = {}
def get_instance(*args, **kwargs):
if cls not in instances:
instances[cls] = cls(*args, **kwargs)
return instances[cls]
return get_instance
@singleton
class MyClass:
pass
在上面的示例中,定义了一个名为singleton的装饰器,它接受一个类作为参数,并返回一个新的函数get_instance。get_instance函数用于创建类的实例,并保证每个类只有一个实例。然后,使用装饰器将MyClass类转换为单例模式。
2. 使用元类实现单例模式
使用元类可以将单例模式应用于所有子类,具有更高的可扩展性。下面是一个使用元类实现单例模式的示例代码:
class Singleton(type):
instances = {}
def __call__(cls, *args, **kwargs):
if cls not in cls.instances:
cls.instances[cls] = super().__call__(*args, **kwargs)
return cls.instances[cls]
class MyClass(metaclass=Singleton):
pass
在上面的示例中,定义了一个名为Singleton的元类,它重写了__call__方法,用于创建类的实例,并保证每个类只有一个实例。然后,使用元类将MyClass类转换为单例模式。
以上是两种常见的Python实现单例模式的方式,具体使用哪种方式取决于具体的场景和需求。
6. Python中的多重继承是什么?如何使用多重继承?
Python中的多重继承是指一个子类可以继承多个父类的属性和方法。与单一继承不同,多重继承可以让子类具有多个父类的特性,从而实现更加灵活和复杂的功能。
使用多重继承需要注意以下几点:
- 子类的构造函数应该调用所有父类的构造函数,以保证所有父类的属性和方法都能被正确地初始化。
- 如果多个父类中有同名的方法或属性,子类需要显式地指定调用哪个父类的方法或属性。
- 在设计类的时候,应该尽量避免使用多重继承,因为它可能会增加代码的复杂度和维护成本。
下面是一个使用多重继承的示例代码:
class A:
def method_a(self):
print("This is method A.")
class B:
def method_b(self):
print("This is method B.")
class C(A, B):
def method_c(self):
print("This is method C.")
obj = C()
obj.method_a() # 调用父类A的方法
obj.method_b() # 调用父类B的方法
obj.method_c() # 调用子类C的方法
在上面的示例中,定义了三个类A、B和C,其中类C继承了类A和类B的属性和方法。通过创建C类的实例,可以调用所有父类和子类的方法。
7. Python中的协程是什么?如何使用协程?
Python中的协程是一种轻量级的线程,它可以在单线程中实现多个任务之间的切换,从而实现并发执行。协程的优势在于可以避免线程切换的开销,提高程序的运行效率。
在Python中,可以使用asyncio模块来实现协程。使用协程的步骤如下:
- 定义协程函数:使用async关键字定义一个协程函数,该函数内部可以使用await关键字来等待其他协程或异步任务的完成。
- 创建事件循环:使用asyncio模块的get_event_loop()方法创建一个事件循环对象。
- 将协程函数加入事件循环:使用事件循环对象的run_until_complete()方法将协程函数加入事件循环中。
- 运行事件循环:使用事件循环对象的run_forever()方法运行事件循环,直到所有协程函数执行完成。
下面是一个使用协程的示例代码:
import asyncio
async def coroutine_func():
print("start coroutine function")
await asyncio.sleep(1) # 等待1秒
print("end coroutine function")
loop = asyncio.get_event_loop() # 创建事件循环对象
loop.run_until_complete(coroutine_func()) # 将协程函数加入事件循环
loop.close() # 关闭事件循环
在上面的示例代码中,定义了一个协程函数coroutine_func(),该函数内部使用await关键字等待1秒。通过创建事件循环对象并将协程函数加入事件循环中,可以实现协程的并发执行。最后,需要调用事件循环对象的close()方法关闭事件循环。
8. 如何在Python中使用上下文管理器?
在Python中,上下文管理器是一种可以用于管理资源的对象,它可以在代码块执行前和执行后进行一些操作,例如打开和关闭文件、获取和释放锁等。使用上下文管理器可以更加方便地管理资源,避免资源泄漏和错误的发生。在Python中,可以使用with语句来使用上下文管理器。
要使用上下文管理器,需要创建一个实现了__enter__()和__exit__()方法的对象。enter()方法在进入with语句块时被调用,可以在该方法中进行一些准备工作,例如打开文件、获取锁等。exit()方法在离开with语句块时被调用,可以在该方法中进行一些清理工作,例如关闭文件、释放锁等。下面是一个使用上下文管理器的示例代码:
class MyContextManager:
def __enter__(self):
print("enter context")
return self
def __exit__(self, exc_type, exc_value, traceback):
print("exit context")
with MyContextManager() as cm:
print("inside context")
在上面的示例代码中,定义了一个名为MyContextManager的上下文管理器类,该类实现了__enter__()和__exit__()方法。在__enter__()方法中,打印了一条进入上下文的消息,并返回了self。在__exit__()方法中,打印了一条离开上下文的消息。在使用with语句时,会自动调用MyContextManager对象的__enter__()方法进入上下文,并在with语句块执行完毕后自动调用__exit__()方法离开上下文。
在上面的示例代码中,with语句块内部打印了一条“inside context”的消息,表示已经进入上下文。在with语句块执行完毕后,会自动调用MyContextManager对象的__exit__()方法离开上下文,并打印一条“exit context”的消息。
9. 什么是Python中的闭包?如何使用闭包?
闭包是指一个函数对象,它可以访问并操作函数体外定义的变量。在Python中,闭包是通过在函数内部定义一个内部函数,并返回该内部函数的方式实现的。内部函数可以访问外部函数的局部变量,并将其保存在自己的闭包中,即使外部函数已经执行完毕,闭包仍然可以访问这些变量。
以下是一个简单的闭包示例,其中内部函数add()可以访问外部函数的局部变量a,并将其保存在闭包中:
def outer_func(a):
def add(b):
return a + b
return add
add_func = outer_func(10)
print(add_func(5)) # 输出 15
在上面的示例中,outer_func()是一个外部函数,它接受一个参数a,并返回一个内部函数add()。在add()函数中,可以访问外部函数的局部变量a,并将其与传入的参数b相加。在使用outer_func()函数时,可以将其返回的add()函数保存在变量中,并重复使用该函数。在调用add_func(5)时,闭包可以访问外部函数的局部变量a,并将其与传入的参数5相加,最终返回15。
使用闭包可以实现一些特定的功能,例如实现一个计数器或者缓存函数的结果等。在Python中,闭包是一种非常强大和灵活的编程技术,可以帮助我们更好地组织和管理代码。
10. Python中的内存管理是什么?如何优化Python应用程序的内存使用?
Python中的内存管理是通过垃圾回收机制实现的。Python解释器会自动跟踪和管理对象的内存使用情况,并在对象不再被引用时自动释放其占用的内存空间。Python中的垃圾回收机制使用的是引用计数算法和标记-清除算法,可以有效地避免内存泄漏和内存溢出的问题。
为了优化Python应用程序的内存使用,可以采取以下几个措施:
- 使用生成器和迭代器:生成器和迭代器可以帮助我们更有效地处理大量数据,同时减少内存的占用。
- 使用内存映射文件:内存映射文件可以将文件映射到内存中,从而避免将整个文件读入内存的问题。
- 避免使用全局变量:全局变量会一直存在于内存中,因此应该尽可能避免使用全局变量。
- 使用适当的数据结构:使用适当的数据结构可以帮助我们更有效地处理数据,从而减少内存的占用。
- 及时删除不需要的对象:及时删除不需要的对象可以释放内存空间,避免内存泄漏和内存溢出的问题。
- 使用内存分析工具:使用内存分析工具可以帮助我们更好地了解应用程序的内存使用情况,从而进行优化和调试。
总之,Python中的内存管理是非常重要的,合理地管理和优化内存使用可以提高应用程序的性能和稳定性。
总结
Python中的高级特性可以大大提高开发效率和程序性能,但也需要开发者深入理解其概念和用法,以避免出现意外的错误和问题。通过本文的介绍,读者可以更好地掌握Python中常见的高级特性,提高自己的编程水平。