车道线实例分割检测是指利用计算机视觉技术对图像或视频中的车道线进行精确的识别和定位任务。该任务旨在区分和标记出每条独立的车道线,并提供它们的准确位置和形状信息。
实例分割是目标检测和语义分割的结合,不仅要找到目标的边界框,还需对目标的每个像素进行分类,达到像素级别的精细分割。相比于传统的车道线检测方法,实例分割可以提供更准确、更细致的结果。
车道线实例分割检测通常采用深度学习模型,如Mask R-CNN、DeepLab等。这些模型基于卷积神经网络架构,通过训练大量标注好的车道线样本来学习车道线的特征和上下文信息。在测试阶段,模型能够对新图像或视频进行预测,并输出每条车道线的边界框或像素级别的掩码。
车道线实例分割检测的应用广泛,包括自动驾驶系统中的环境感知与路径规划、交通监控系统中的违规检测与交通流量分析,以及智能驾驶辅助系统中的车道保持与驾驶员警示等。这项技术有助于提高行驶安全性、降低驾驶压力,并促进智能交通系统的发展。
在前面的一些项目开发实践中,我们已经基于传统的 MaskRCNN模型和DeepLabv3模型开发构建了道理场景下车道线实例分割系统了,这里本文的核心目的就是为了基于更加轻量级的yolov5s-v7.0版本来开发构建道路场景下的车道线实例分割检测识别系统,首先来看下效果图,如下所示:
接下来看下我们准备的数据集,如下所示:
实例数据标注如下:
0 0.051770833333333335 0.3221296296296296 0.058333333333333334 0.314537037037037 0.06484375 0.30694444444444446 0.07140624999999999 0.29935185185185187 0.07796874999999999 0.2917592592592593 0.08447916666666666 0.2840740740740741 0.09104166666666667 0.2764814814814815 0.09755208333333334 0.26888888888888884 0.10411458333333333 0.2612962962962963 0.110625 0.2537037037037037 0.1171875 0.2461111111111111 0.12369791666666667 0.23851851851851855 0.13026041666666666 0.23092592592592592 0.13677083333333334 0.22324074074074074 0.14333333333333334 0.21564814814814814 0.14984375 0.20805555555555555 0.15640625 0.20046296296296295
2 0.0 0.2588888888888889 0.007604166666666666 0.2556481481481482 0.015156250000000001 0.2523148148148148 0.02276041666666667 0.2490740740740741 0.03036458333333333 0.24574074074074073 0.03796875 0.2424074074074074 0.04552083333333334 0.23916666666666667 0.053125 0.2358333333333333 0.06072916666666666 0.23259259259259257 0.06828125 0.22925925925925925 0.07588541666666666 0.22592592592592592 0.08348958333333334 0.22268518518518518 0.09109375 0.21935185185185185 0.09864583333333334 0.21611111111111111 0.10625 0.2127777777777778 0.11385416666666666 0.20944444444444443 0.12140625 0.2062037037037037 0.12901041666666666 0.20287037037037037 0.13661458333333334 0.19962962962962963
3 0.3333333333333333 0.2873148148148148 0.3259375 0.28277777777777774 0.31854166666666667 0.27824074074074073 0.31114583333333334 0.27379629629629626 0.3038020833333333 0.26925925925925925 0.29640625000000004 0.2647222222222222 0.28901041666666666 0.2601851851851852 0.28161458333333333 0.2556481481481482 0.27421875 0.2512037037037037 0.26682291666666663 0.24666666666666665 0.25942708333333336 0.24212962962962964 0.2520833333333333 0.2375925925925926 0.2446875 0.23314814814814816 0.23729166666666668 0.22861111111111113 0.22989583333333333 0.22407407407407406 0.2225 0.21953703703703703 0.21510416666666668 0.2150925925925926 0.20776041666666664 0.21055555555555555 0.20036458333333332 0.20601851851851852 0.19296875 0.20148148148148148 0.18557291666666667 0.19694444444444442
1 0.24968749999999998 0.32175925925925924 0.24390625000000002 0.3125 0.238125 0.3031481481481481 0.23234375000000002 0.29379629629629633 0.22651041666666666 0.28453703703703703 0.22072916666666667 0.2751851851851852 0.21494791666666666 0.2659259259259259 0.20911458333333333 0.2565740740740741 0.2033333333333333 0.24722222222222223 0.19755208333333335 0.23796296296296296 0.19177083333333333 0.22861111111111113 0.1859375 0.21935185185185185 0.18015625 0.21000000000000002 0.174375 0.20074074074074075
文本使用到的s系列模型文件如下所示:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 8 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# Backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# Head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
训练数据配置文件如下所示:
#Dataset
path: ./datasets/dataset-segment
train: images/train
val: images/train
test: images/train
# Classes
names:
0: 0
1: 1
2: 2
3: 3
4: 4
5: 5
6: 6
7: 7
这里默认设定的是100次epoch迭代计算,接下来看下结果详情数据,如下所示:
【F1值曲线】
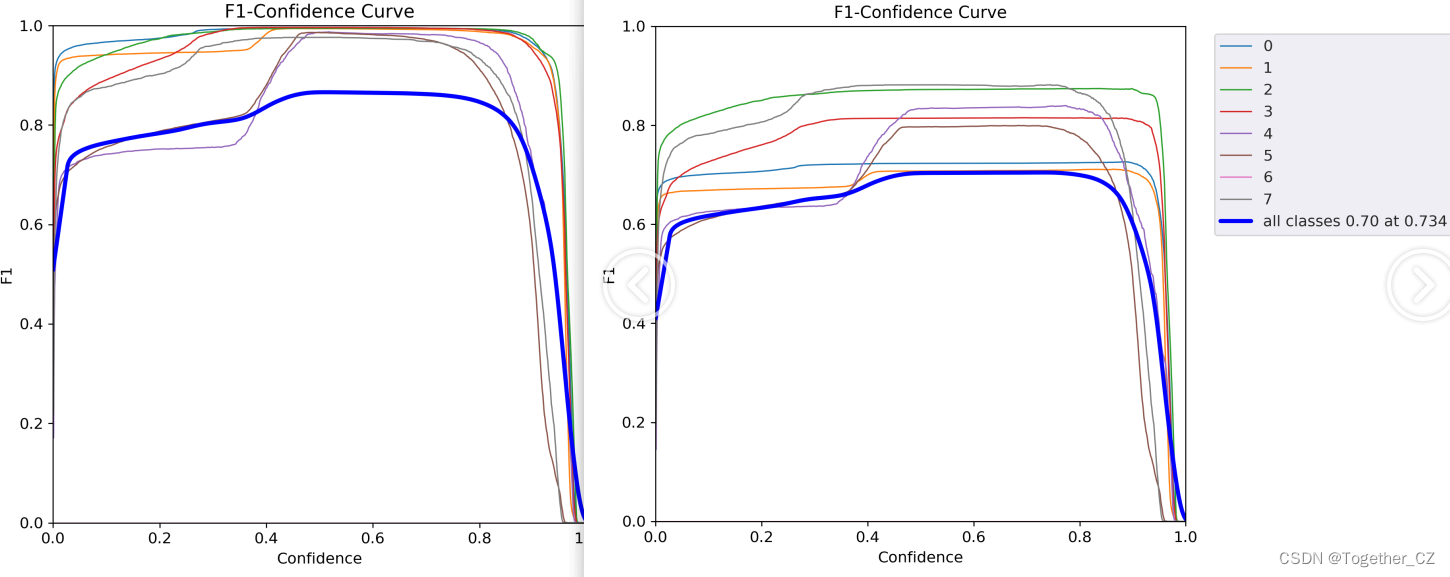
【精确率曲线】
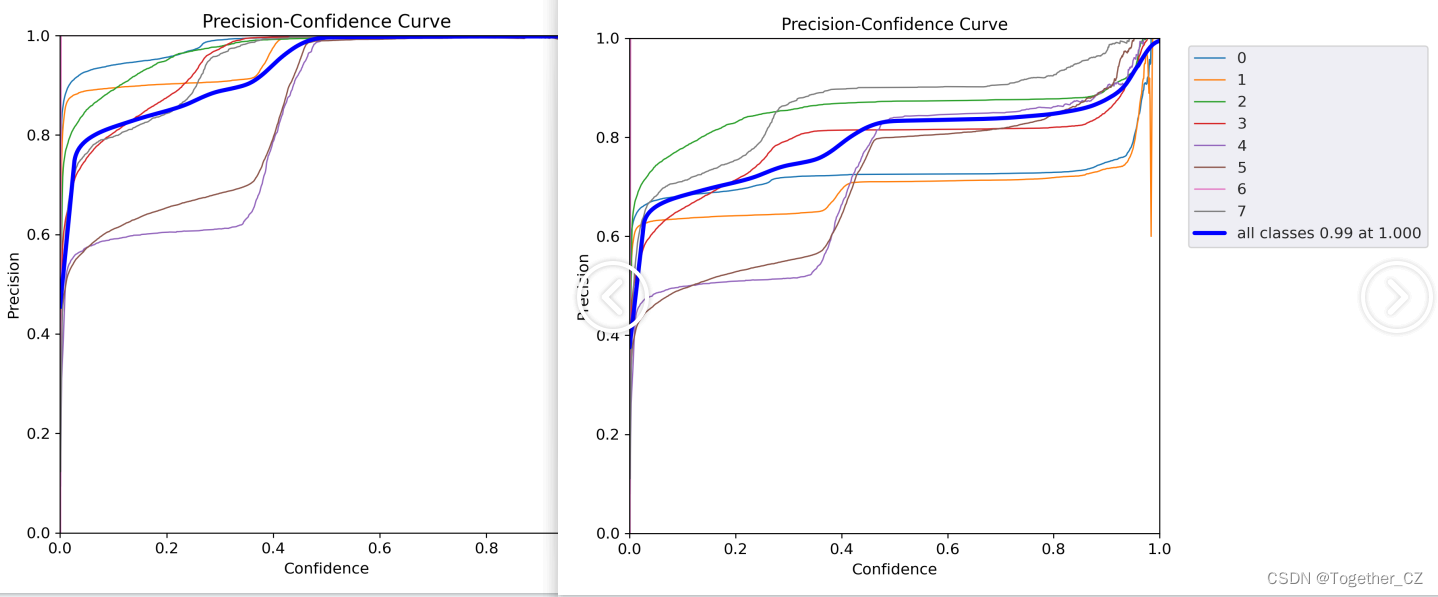
【召回率曲线】
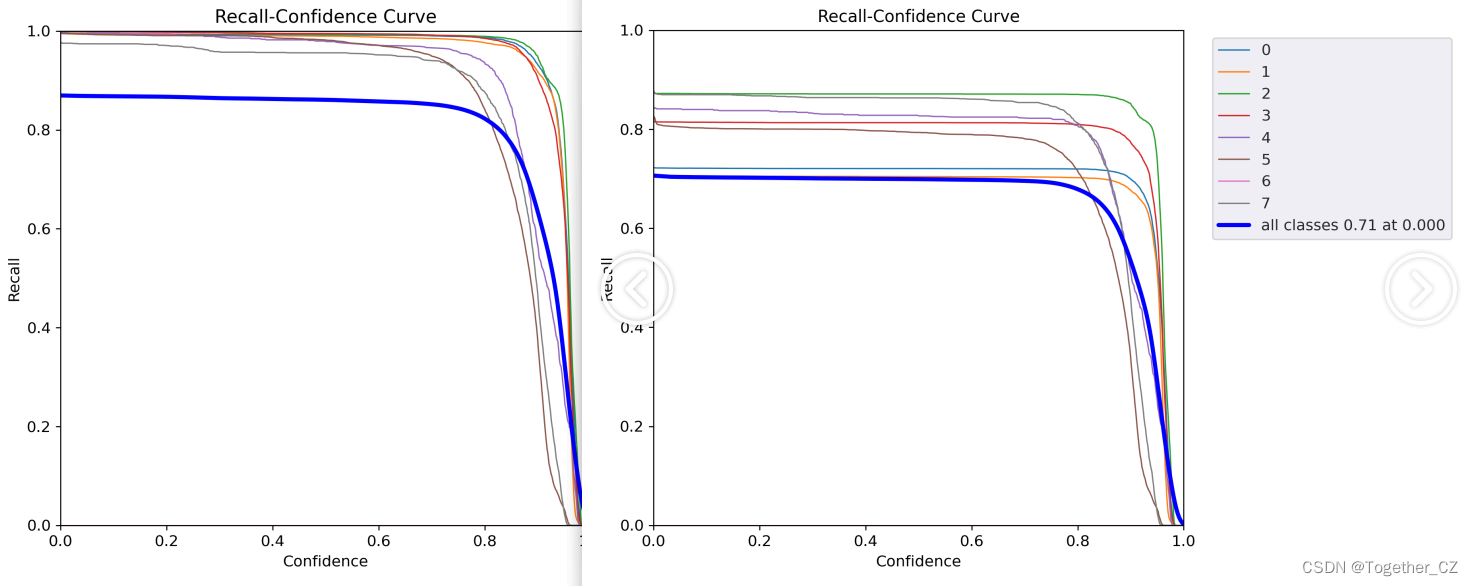
【PR曲线】
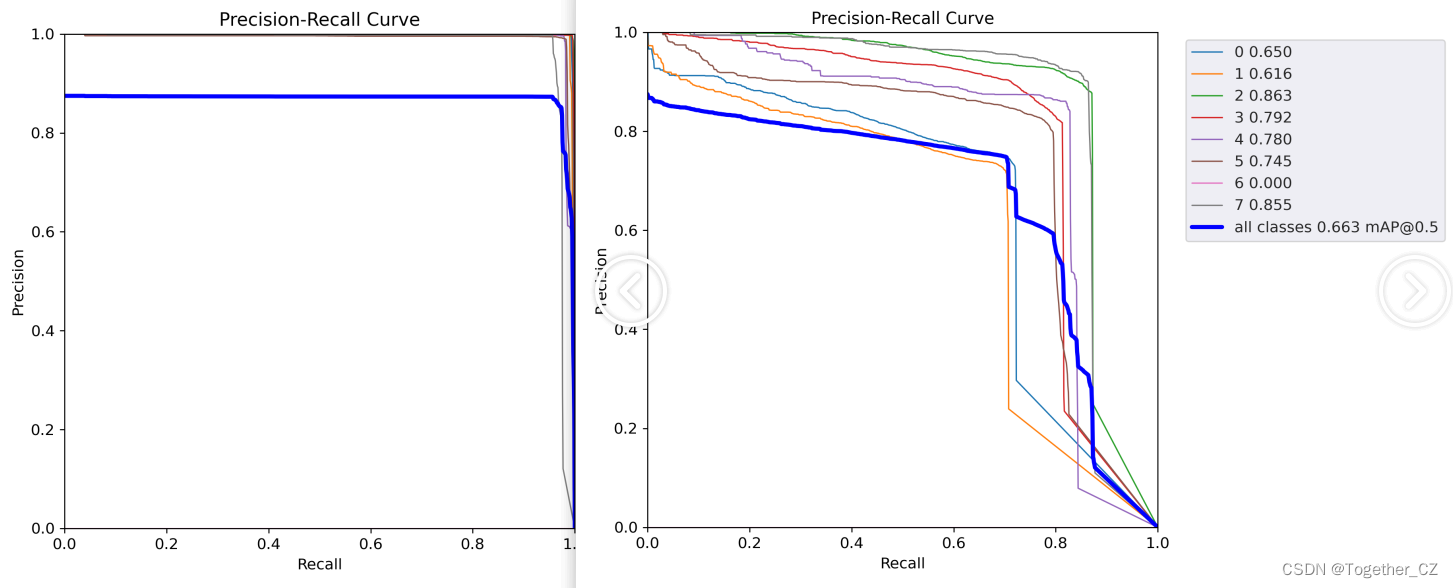
【混淆矩阵】
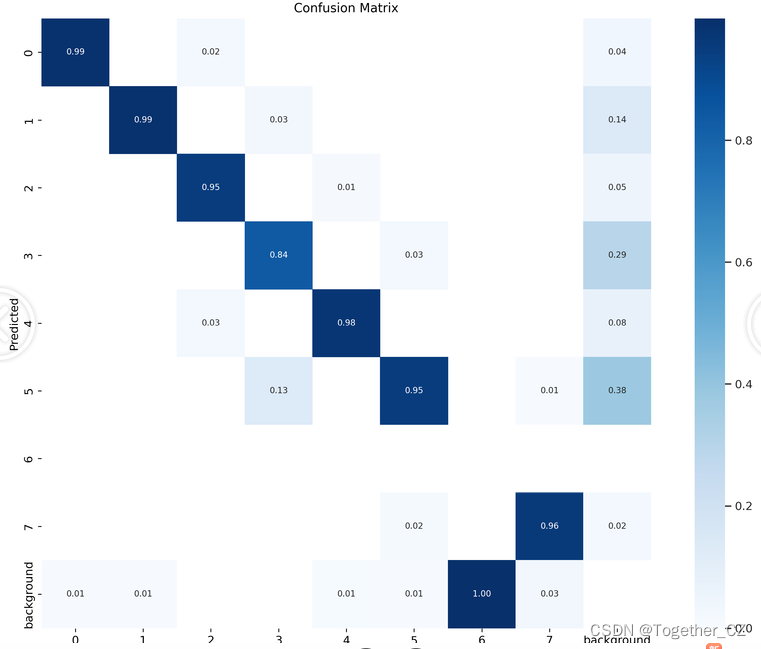
数据类别标签可视化如下所示:
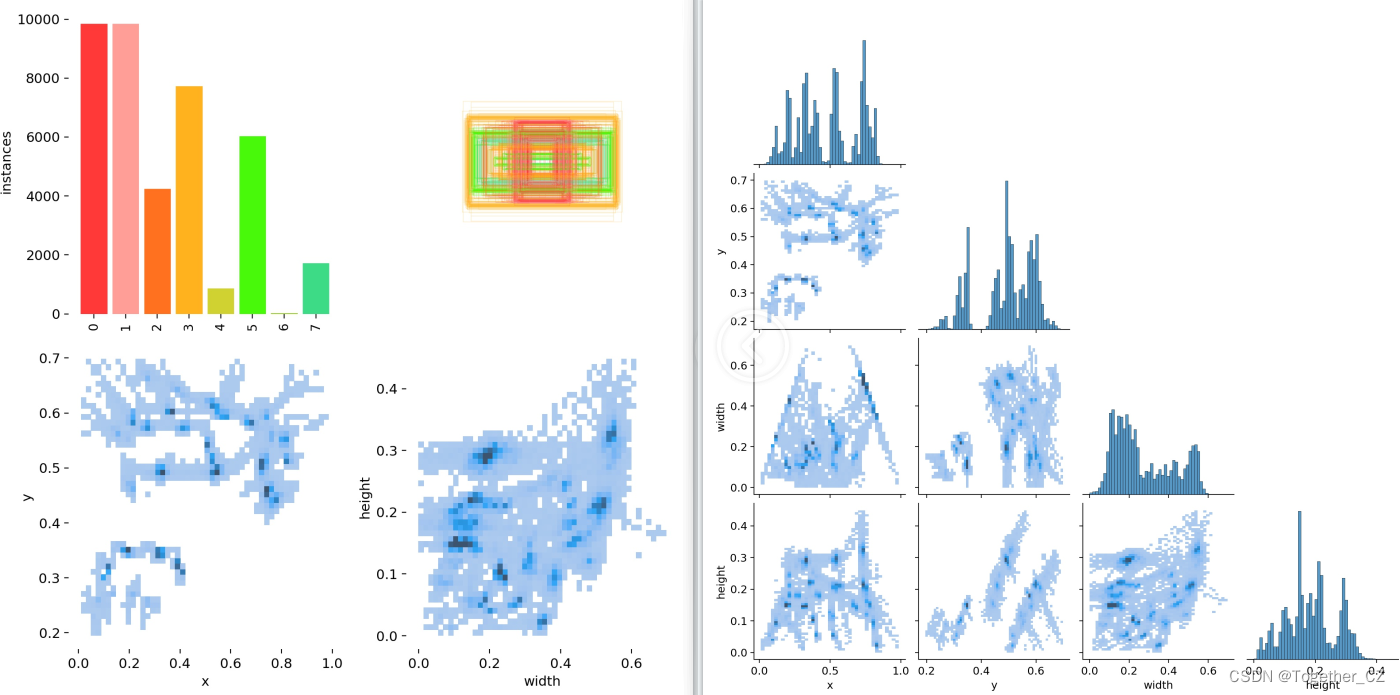
训练过程可视化如下所示:

【batch计算实例】如下所示:

模型参数结构图如下所示:

到这里本文的主要实践工作就结束了,对于未来车道线分割技术在未来有以下几个展望:
-
更高的精度和稳定性:随着深度学习算法的不断发展和改进,车道线分割技术将更加准确和可靠。模型会更好地理解图像中复杂的背景、光照变化以及各种天气条件对车道线的影响,从而提供更精准的分割结果。
-
实时性能的提升:实时性是车道线分割技术在自动驾驶和驾驶辅助系统中的关键要求。未来的算法和硬件设备将更注重优化运算速度,以实现更快的车道线检测和分割,使其能够在实时场景下实际应用。
-
车道线类型的拓展:目前车道线分割主要针对标准的直线、虚线和实线等常见车道线类型。未来的技术可能将扩展到更复杂的车道线情况,如交叉口、环岛、斑马线等特殊标记,以满足不同交通场景下的需求。
-
多模态数据融合:除了单纯的图像信息,未来的车道线分割技术可能会融合其他传感器数据,如激光雷达、高精度地图等,以提供更全面且一致的车道线分割结果。多模态数据融合可以增强算法在各种环境条件下的稳定性和可靠性。
-
自适应与自主学习能力:未来的车道线分割技术可能具备自适应能力,能够根据交通标准和实际驾驶场景进行动态调整并学习新的车道线模式。通过自主学习,算法可以不断优化自身,并适应不断变化的道路标记和驾驶环境。
综上所述,未来车道线分割技术将在精度、实时性、适应性和数据融合等方面不断取得进步,为自动驾驶和驾驶辅助系统提供更可靠和高效的支持。
希望早日可以看到技术带给生活的遍历!



![[Web程序设计]实验: 请求与响应](https://img-blog.csdnimg.cn/4df71480185646718735bde004599e03.jpeg)