目录
向量索引
索引创建机制
数据段建索引
用户主动创建索引
闲时建索引
索引概览
FLAT
IVF_FLAT
IVF_SQ8
IVF_SQ8H
IVF_PQ
RNSG
HNSW
ANNOY
选择索引
常见问题
参考文献
向量索引
向量索引(vector index)是指通过某种数学模型,对向量构建的一种时间和空间上更高效的数据结构。借助向量索引,我们能够高效地查询与目标向量相似的若干个向量。Milvus 的实体目前只支持一个向量字段。你可以为该向量字段指定一种索引类型以提高查询性能。Milvus 会在切换索引类型时自动删除旧索引。
Milvus 目前支持的向量索引类型大都属于 ANNS(Approximate Nearest Neighbors Search,近似最近邻搜索)。ANNS 的核心思想是不再局限于只返回最精确的结果项,而是仅搜索可能是近邻的数据项,即以牺牲可接受范围内的精度的方式提高检索效率。
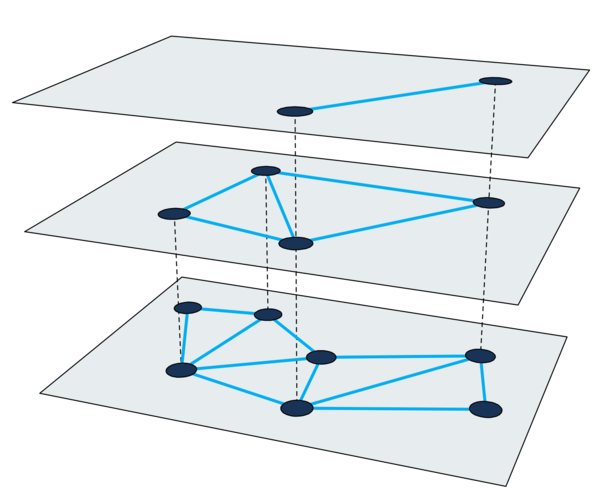
根据实现方式,ANNS 向量索引可分为四大类:
- 基于树的索引
- 基于图的索引
- 基于哈希的索引
- 基于量化的索引
下表将目前 Milvus 支持的索引进行了归类:
| Milvus 支持的索引 | 索引分类 | 适用场景 |
| FLAT | N/A |
|
| IVF_FLAT | 基于量化的索引 |
|
| IVF_SQ8 | 基于量化的索引 |
|
| IVF_SQ8H | 基于量化的索引 |
|
| IVF_PQ | 基于量化的索引 | |
| RNSG | 基于图的索引 | |
| HNSW | 基于图的索引 | |
| ANNOY | 基于树的索引 |
索引创建机制
数据段建索引
Milvus 数据段存储海量数据。在建立索引时,Milvus 为每个数据段单独创建索引。
用户主动创建索引
调用 create_index 接口时,Milvus 会对该字段上的已有数据同步建立索引。每当后续插入的数据的大小达到系统配置的 index_file_size 时,Milvus 会为其在后台自动创建索引。
当插入的数据段少于 4096 行时,Milvus 不会为其建立索引。

闲时建索引
众所周知,建索引是一个比较消耗计算资源和时间的工作。当查询任务和后台建索引任务并发时,Milvus 通常把计算资源优先分配给查询任务,即用户发起的任何查询命令都会打断后台正在执行的建索引任务。之后仅当用户持续 5 秒不再发起查询任务,Milvus 才会恢复执行后台建索引任务。此外,如果查询命令指定的数据段尚未建成指定索引,Milvus 会直接在段内做全量搜索。
索引概览
FLAT
FLAT 索引类型是指对向量进行原始文件存储。搜索时,所有向量都会与目标向量进行距离计算和比较。
FLAT 索引类型提供 100% 的检索召回率。与其他索引相比,当查询数量较少时,它是最有效的索引方法。
- 查询参数| 参数 | 说明 | 取值范围 | | ————- |——————— | ———— | | metric_type | [可选] 距离计算方式 | 详见目前支持的距离计算方式。 |
IVF_FLAT
IVF(Inverted File,倒排文件)是一种基于量化的索引类型。它通过聚类方法把空间里的点划分成 nlist 个单元。查询时先把目标向量与所有单元的中心做距离比较,选出 nprobe 个最近单元。然后比较这些被选中单元里的所有向量,得到最终的结果。
IVF_FLAT 是最基础的 IVF 索引,存储在各个单元中的数据编码与原始数据一致。
- 建索引参数| 参数 | 说明 | 取值范围 | | ———- | ———— |—————- | | nlist | 聚类单元数 |[1, 65536] |
- 查询参数| 参数 | 说明 | 取值范围 | | ———— | —————- | ————— | | nprobe | 查询取的单元数 | [1, 65536]
GPU 版 Milvus 在 nprobe > 2048 时由 GPU 查询切换为 CPU 查询。|
IVF_SQ8
IVF_SQ8 是在 IVF 的基础上对放入单元里的每条向量做一次标量量化(Scalar Quantization)。标量量化会把原始向量的每个维度从 4 个字节的浮点数转为 1 个字节的无符号整数,因此 IVF_SQ8 索引文件占用的存储空间远小于 IVF_FLAT。但是,标量量化会导致查询时的精度损失。

- 建索引参数同 IVF_FLAT
- 查询参数同 IVF_FLAT
IVF_SQ8H
IVF_SQ8H 是一种优化查询执行的 IVF_SQ8 索引类型。
在不同的 nq(Number of queries,查询数量)与系统参数 gpu_search_threshold 的关系下,查询方式如下:
- nq ≥ gpu_search_threshold:整个查询过程都在 GPU 上执行。
- nq < gpu_search_threshold:在 GPU 上执行在 IVF 里寻找 nprobe 个最近单元的运算,在 CPU 上执行其它运算。
- 建索引参数同 IVF_FLAT
- 查询参数同 IVF_FLAT
IVF_PQ
PQ(Product Quantization,乘积量化)会将原来的高维向量空间均匀分解成 m 个低维向量空间的笛卡尔积,然后对分解得到的低维向量空间分别做矢量量化。最终每条向量会存储在 m × nbits 个 bit 位里。乘积量化能将全样本的距离计算转化为到各低维空间聚类中心的距离计算,从而大大降低算法的时间复杂度。

IVF_PQ 是先对向量做乘积量化,然后进行 IVF 索引聚类。其索引文件甚至可以比 IVF_SQ8 更小,不过同样地也会导致查询时的精度损失。
不同版本的建索引参数和查询参数设置不同,请根据使用的 Milvus 版本查看相应的参数信息。
CPU 版 Milvus GPU 版 Milvus
- 建索引参数 | 参数 | 说明 | 取值范围 | | ————| ——————- | —————- | | nlist | 聚类单元数 | [1, 65536] | | m | 乘积量化因子个数 | dim ≡ 0 (mod m) | | nbits | 分解后每个低维向量的存储位数 (可选) | [1, 16] (默认 8) | - 查询参数 | 参数 | 说明 | 取值范围 | | ———— | —————- | ————— | | nprobe | 查询取的单元数 | [1, nlist] |
- 建索引参数 | 参数 | 说明 | 取值范围 | | ————| ——————- | —————- | | nlist | 聚类单元数 | [1, 65536] | | m | 乘积量化因子个数 | m ∈ {1, 2, 3, 4, 8, 12, 16, 20, 24, 28, 32, 40, 48, 56, 64, 96}, and (dim / m) ∈ {1, 2, 3, 4, 6, 8, 10, 12, 16, 20, 24, 28, 32}。
m x 1024 的值不能超过显卡的 MaxSharedMemPerBlock。 | | nbits | 分解后每个低维向量的存储位数 (可选) | 8 |
- 如果 m 值不在指定区间,但是只要 m 值是 CPU 版 Milvus 支持的(点击上面按钮可查看 CPU 版 Milvus 支持的取值范围),Milvus 会自动由 GPU 建索引切换为 CPU 建索引。
- 如果 nbits 指定值不是 8 但是在 1 和 16 之间,系统会自动切换为 CPU 版 Milvus。
- 查询参数| 参数 | 说明 | 取值范围 | | ———— | —————- | ————— | | nprobe | 查询取的单元数 | [1, min(2048, nlist)] |
如果 nprobe 值不在指定区间,但是只要 nprobe 值是 CPU 版 Milvus 支持的(点击上面按钮可查看 CPU 版 Milvus 支持的取值范围),Milvus 会自动由 GPU 查询切换为 CPU 查询。
RNSG
RNSG(Refined Navigating Spreading-out Graph)是一种基于图的索引算法。它把全图中心位置设为导航点,然后通过特定的选边策略来控制每个点的出度(小于等于 out_degree),使得搜索时既能减少内存使用,又能快速定位到目标位置附近。
RNSG 的建图流程如下:
- 为每个点精确寻找 knng 个最近邻结点。
- 以 knng 个最近邻结点为基础迭代至少 search_length 次,以选出 candidate_pool_size 个可能的最邻近结点。
- 在选出的 candidate_pool_size 个结点里按择边策略构建每个点的出边。
RNSG 的查询流程与建图流程类似,以导航点为起点至少迭代 search_length 次以得到最终结果。
- 建索引参数| 参数 | 说明 | 取值范围 | | ———————————| —————————- | ———— | | out_degree | 结点的最大出度 | [5, 300] | | candidate_pool_size | 结点出边候选池 | [50, 1000] | | search_length | 查询迭代次数 | [10, 300] | | knng | 预计算最近邻结点数 | [5, 300] |
- 查询参数| 参数 | 说明 | 取值范围 | | ———————- | —————- | ————- | | search_length | 查询迭代次数 | [10, 300] |
HNSW
HNSW(Hierarchical Small World Graph)是一种基于图的索引算法。它会为一张图按规则建成多层导航图,并让越上层的图越稀疏,结点间的距离越远;越下层的图越稠密,结点间的距离越近。搜索时从最上层开始,找到本层距离目标最近的结点后进入下一层再查找。如此迭代,快速逼近目标位置。
为了提高性能,HNSW 限定了每层图上结点的最大度数 M 。此外,建索引时可以用 efConstruction,查询时可以用 ef 来指定搜索范围。
- 建索引参数| 参数 | 说明 | 取值范围 | | ———————— | ————————— | ————- | | M | 结点的最大度数 | [4, 64] | | efConstruction | 搜索范围 | [8, 512] |
- 查询参数| 参数 | 说明 | 取值范围 | | ————|———————- | —————— | | ef | 搜索范围 | [top_k, 32768] |
ANNOY
ANNOY(Approximate Nearest Neighbors Oh Yeah)是一种用超平面把高维空间分割成多个子空间,并把这些子空间以树型结构存储的索引方式。
在查询时,ANNOY 会顺着树结构找到距离目标向量较近的一些子空间,然后比较这些子空间里的所有向量(要求比较的向量数不少于 search_k 个)以获得最终结果。显然,当目标向量靠近某个子空间的边缘时,有时需要大大增加搜索的子空间数以获得高召回率。因此,ANNOY 会使用 n_trees 次不同的方法来划分全空间,并同时搜索所有划分方法以减少目标向量总是处于子空间边缘的概率。
- 建索引参数| 参数 | 说明 | 取值范围 | | ————- |——————— | ———— | | n_trees | 空间划分的方法数 | [1, 1024] |
- 查询参数| 参数 | 说明 | 取值范围 | | —————-|————————————————- | ———————— | | search_k | 搜索的结点数。-1 表示用全数据量的 5% | {-1} ∪ [top_k, n × n_trees] |
选择索引
- 若要为你的使用场景选择合适的索引,请参阅 如何选择索引类型。
- 关于索引和向量距离计算方法的选择,请访问 距离计算方式。
常见问题
索引 IVF_SQ8 和 IVF_SQ8H 在召回率上有区别吗?
Milvus 中 FLAT 索引和 IVF_FLAT 索引的原理比较?
参考文献
- RNSG:Fast Approximate Nearest Neighbor Search With The Navigating Spreading-out Graph
- HNSW:Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs
- ANNOY: