原文首发于博客文章OpenAI 文档解读
LangChain 主体分为 6 个模块,分别是对(大语言)模型输入输出的管理、外部数据接入、链的概念、(上下文记忆)存储管理、智能代理以及回调系统,通过文档的组织结构,你可以清晰了解到 LangChain的侧重点,以及在大语言模型开发生态中对自己的定位。从本节开始我将对langchian各个模块对照源码进行介绍,首先看Model I/O模块👇
Model I/O
这部分包括对大语言模型输入输出的管理,输入环节的提示词管理(包含模板化提示词和提示词动态选择等),处理环节的语言模型(包括所有LLMs的通用接口,以及常用的LLMs工具;Chat模型是一种与LLMs不同的API,用来处理消息),输出环节包括从模型输出中提取信息。
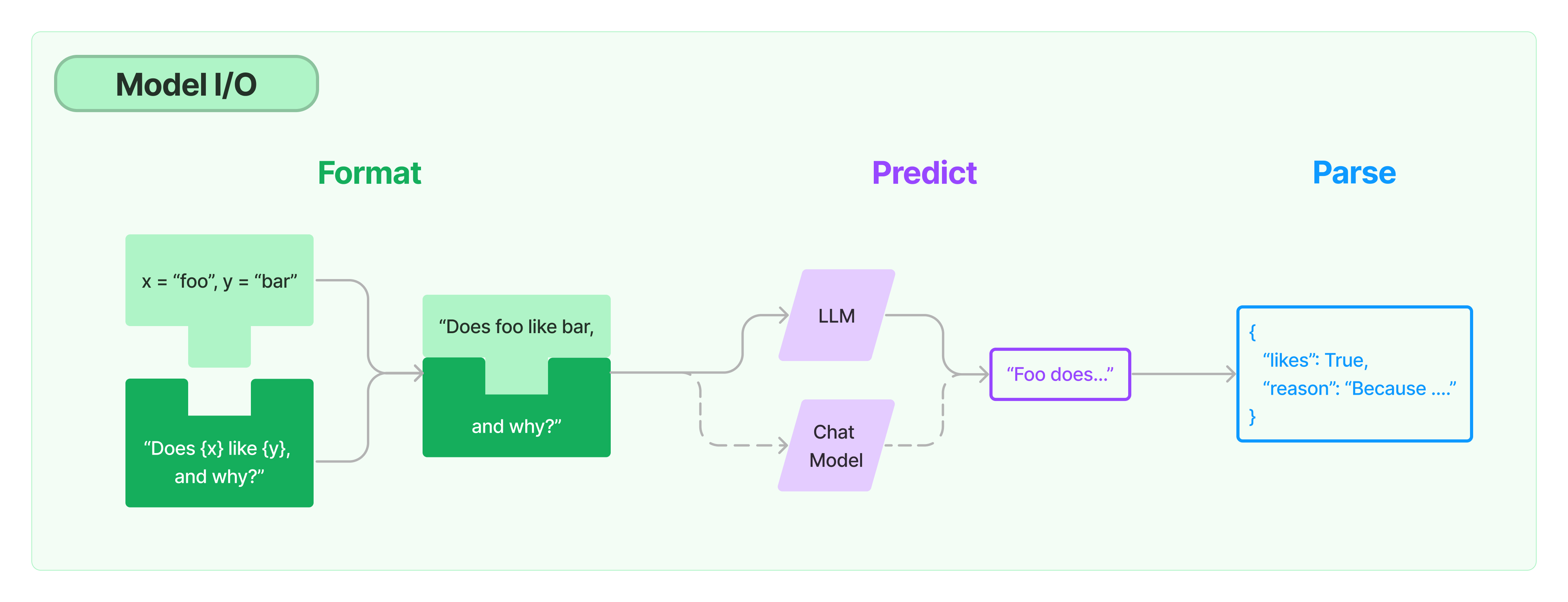
提示词管理
-
提示模板
动态提示词=提示模板+变量,通过引入给提示词引入变量的方式,一方面保证了灵活性,一方面又能保证Prompt内容结构达到最佳from langchain import PromptTemplate no_input_prompt = PromptTemplate(input_variables=[], template="Tell me a joke.") no_input_prompt.format() one_input_prompt = PromptTemplate(input_variables=["adjective"], template="Tell me a {adjective} joke.") # "Tell me a funny chickens." one_input_prompt.format(adjective="funny") multiple_input_prompt = PromptTemplate( input_variables=["adjective", "content"], template="Tell me a {adjective} joke about {content}." ) # "Tell me a funny joke about chickens." multiple_input_prompt.format(adjective="funny", content="chickens") -
聊天提示模板
聊天场景中,消息可以与AI、人类或系统角色相关联,模型应该更加密切地遵循系统聊天消息的指示。这个是对 OpenAI gpt-3.5-tubor API中role字段(role 的属性用于显式定义角色,其中 system 用于系统预设,比如”你是一个翻译家“,“你是一个写作助手”,user 表示用户的输入, assistant 表示模型的输出)的一种抽象,以便应用于其他大语言模型。SystemMessage对应系统预设,HumanMessage用户输入,AIMessage表示模型输出,使用 ChatMessagePromptTemplate 可以使用任意角色接收聊天消息。from langchain.prompts import ( ChatPromptTemplate, PromptTemplate, SystemMessagePromptTemplate, AIMessagePromptTemplate, HumanMessagePromptTemplate, ) from langchain.schema import ( AIMessage, HumanMessage, SystemMessage ) def generate_template(): template="You are a helpful assistant that translates {input_language} to {output_language}." system_message_prompt = SystemMessagePromptTemplate.from_template(template) human_template="{text}" human_message_prompt = HumanMessagePromptTemplate.from_template(human_template) chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt]) # [SystemMessage(content='You are a helpful assistant that translates English to Chinese.', additional_kwargs={}), HumanMessage(content='I like Large Language Model', additional_kwargs={}, example=False)] final_message = chat_prompt.format_prompt(input_language="English", output_language="Chinese", text="I like Large Language Model").to_messages() print(final_message) if __name__ == "__main__": generate_template() -
其他
- 基于 StringPromptTemplate 自定义提示模板StringPromptTemplate
- 将Prompt输入与特征存储关联起来(FeaturePromptTemplate)
- 少样本提示模板(FewShotPromptTemplate)
- 从示例中动态提取提示词
LLMs
-
LLMs
将文本字符串作为输入并返回文本字符串的模型(纯文本补全模型),这里重点说下做项目尽量用异步的方式,体验会更好,下面的例子连续10个请求,时间相差接近5s。
import time import asyncio from langchain.llms import OpenAI def generate_serially(): llm = OpenAI(temperature=0.9) for _ in range(10): resp = llm.generate(["Hello, how are you?"]) print(resp.generations[0][0].text) async def async_generate(llm): resp = await llm.agenerate(["Hello, how are you?"]) print(resp.generations[0][0].text) async def generate_concurrently(): llm = OpenAI(temperature=0.9) tasks = [async_generate(llm) for _ in range(10)] await asyncio.gather(*tasks) if __name__ == "__main__": s = time.perf_counter() asyncio.run(generate_concurrently()) elapsed = time.perf_counter() - s print("\033[1m" + f"Concurrent executed in {elapsed:0.2f} seconds." + "\033[0m") s = time.perf_counter() generate_serially() elapsed = time.perf_counter() - s print("\033[1m" + f"Serial executed in {elapsed:0.2f} seconds." + "\033[0m") -
缓存
如果多次请求的返回一样,就可以考虑使用缓存,一方面可以减少对API调用次数节省token消耗,一方面可以加快应用程序的速度。
from langchain.cache import InMemoryCache import time import langchain from langchain.llms import OpenAI llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2) langchain.llm_cache = InMemoryCache() s = time.perf_counter() llm("Tell me a joke") elapsed = time.perf_counter() - s # executed first in 2.18 seconds. print("\033[1m" + f"executed first in {elapsed:0.2f} seconds." + "\033[0m") llm("Tell me a joke") # executed second in 0.72 seconds. elapsed2 = time.perf_counter() - elapsed print("\033[1m" + f"executed second in {elapsed2:0.2f} seconds." + "\033[0m") -
流式传输
以打字机效果的方式逐字返回聊天内容
from langchain.llms import OpenAI from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler llm = OpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()], temperature=0) resp = llm("模仿李白的风格写一首唐诗.") print(resp) -
跟踪 token 消耗情况
流式传输的情况下暂不支持计算,可以考虑内容全部传输完成后用tiktoken库计算from langchain.llms import OpenAI from langchain.callbacks import get_openai_callback llm = OpenAI() with get_openai_callback() as cb: resp = llm.generate(["模仿李白的风格写一首唐诗."]) print(resp.generations[0][0].text) print(cb) -
Chat models
将聊天消息列表作为输入并返回聊天消息的模型(对话补全模型) -
其他
- 以json或者yml格式读取保存LLM的(参数)配置(llm.load_llm方法和llm.save方法)
- 为了节省你的token,还可以在测试过程中使用一个模拟LLM输出的
FakeListLLM;还有一个模拟用户输入的HumanInputLLM。 - 与其他 AI相关基础设施的集成,用到随时查询即可
输出解析器
输出解析器用于构造大语言模型的响应格式,具体通过格式化指令和自定义方法两种方式。
# 格式化指令的方式
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
output_parser = CommaSeparatedListOutputParser()
format_instructions = output_parser.get_format_instructions()
prompt = PromptTemplate(
template="列出五个 {subject}.\n{format_instructions}",
input_variables=["subject"],
partial_variables={"format_instructions": format_instructions}
)
model = OpenAI(temperature=0)
_input = prompt.format(subject="大语言模型的特性")
output = model(_input)
# 可移植性, 可扩展性, 可重用性, 可维护性, 可读性
print(output)
output_parser.parse(output)
虽然内置了 DatetimeOutputParser、EnumOutputParser、PydanticOutputParser等解析器,但是我觉得ResponseSchema的控制自由度更好,但是不易于管理。
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
response_schemas = [
ResponseSchema(name="answer", description="answer to the user's question"),
ResponseSchema(name="source", description="source used to answer the user's question, should be a website.")
]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
prompt = PromptTemplate(
template="answer the users question as best as possible.\n{format_instructions}\n{question}",
input_variables=["question"],
partial_variables={"format_instructions": format_instructions}
)
资源推荐
- Guidance:微软开源 prompt 编程框架