taskBus 软件无线电平台是一款依靠 stdin-stdout进行数据吞吐的教学平台。在平台创建之初,主要使用 RTL-SDR进行简单的窄带接收应用,并没有考虑采样率超过1.8M的情况。引入 USRP B210/B205mini后,采样率瞬间提高到2M以上,此时,使用信号与槽进行吞吐时,性能问题就暴露无遗了。
前期使用 Qt5 编译的版本,偷懒直接把装有IQ数据的 QByteArray 作为参数,通过信号-槽来周转,在2.5MHz IQ 采样率下,双向PING延迟325ms左右,勉强够用。上周准备把学校工具链全部更新到 Qt 6.5.1,发现平均双向PING延迟高达 2000 毫秒,其中数据吞吐就花去1960毫秒,导致传递QByteArry这种巨无霸时,性能显著下降了。信号与槽并没有被设计成适配 IQ 数据吞吐这种高流量、高频次的调用。这一篇文章对该问题有所提及:
Compared to callbacks, signals and slots are slightly slower because of the increased flexibility they provide, although the difference for real applications is insignificant. In general, emitting a signal that is connected to some slots, is approximately ten times slower than calling the receivers directly, with non-virtual function calls.
那么,如何解决呢?我们先看看正规工业软件的思路。
1. 正规工业软件的处理思路
在使用软件进行SDR处理的领域,比较高性能的软件基本都遵循如下准则:
- 全流程静态内存、环形缓冲器
- 滤波等操作使用SIMD加速的专业工具库
比如我们通过第一个技术,即可在PC上跑满 USRP B210的56MHz带宽。
用这种思路改进 taskBus 是未来的方向。但这牵扯到整体架构的改进,并无法在实验课快要结束时,临时补救。
2. 跨线程信号-槽性能问题
现有架构下,使用信号与槽吞吐数据的原因是负责 stdio 的各个线程是独立的,需要根据数据生产、消费的关系,动态的流转数据。这种方式最好的实现是全局环状队列群,每个专题一个队列,消费者去追赶感兴趣的队列进度。但不幸的是,taskBus实现之初并没有考虑性能问题,只想着跑通教学例子就够了。这个吞吐策略的原理如下图:
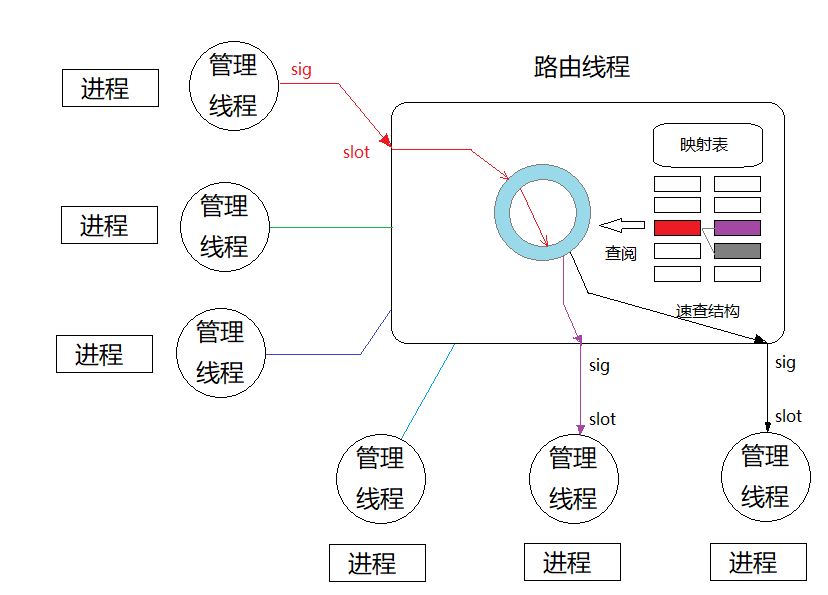
上图显示的是1组生产-消费关系。红色的生产者通过第一组信号-槽,把一包数据交给路由线程;路由线程查阅映射表,把数据通过第二组信号-槽,交给两个消费者。
由于信号-槽不是点对点的连接,而是一种广播机制,导致实质上第二组递交是广播给了所有进程,只是由于携带了目的ID,其他的进程管理者收到后不处理罢了。此外,由于对进程的广播携带的目的ID是唯一的,有几个消费者,就广播几组,造成了递交次数爆炸性增长。设进程数为N,本包的消费者数为Mi,则单包数据周转触发的跨线程信号-槽递交次数:
T i = 1 + N M i T_i=1+NM_i Ti=1+NMi
1秒内,总共生产的包数为K,则总的触发次数
T = K + N ∑ i = 0 K M i T=K+N\sum_{i=0}^{K}M_i T=K+Ni=0∑KMi
在高采样率情况下,如5MHz采样率下,单包2500样点,则整体的吞吐量会奇高,如下图所示:
 此时,有N=9个进程,粗略估计 K=52000 + 5100 = 10500,有8个生产者只有1个消费者消费,1个生产者有3路消费者消费
此时,有N=9个进程,粗略估计 K=52000 + 5100 = 10500,有8个生产者只有1个消费者消费,1个生产者有3路消费者消费
T = 10500 + 9 ( ∑ i = 0 2000 3 + ∑ i = 0 8500 1 ) = 141000 T=10500+9(\sum_{i=0}^{2000}{3} + \sum_{i=0}^{8500}{1})=141000 T=10500+9(i=0∑20003+i=0∑85001)=141000
由于采用 QueuedConnection 进行连接,在 takbus 的主控程序里会产生大量排队,延迟很大, 且采样率越大,越来不及吞吐。同时,信号中传输的是 QByteArray:
void sig_new_errmsg(QByteArrayList);
尽管使用了隐式共享,但在判断包是不是自己需要的专题时,会调用QByteArray 的非常量函数,发生深度拷贝,导致动态内存的分配、清理次数显著提高。
3 采用跨线程直接调用取代信号与槽
既然主要的耗时花在了数据吞吐上,我们就把IQ数据吞吐部分拿出来,直接使用函数调用直连。跨线程的直接调用,最容易发生共享冲突。查看代码,发现生产消费映射表存在大量复杂的索引容器:
/*!
* 索引成员变量,会在refresh_idxes调用时生成
* Index member variables that is generated when refresh_idxes is called
*/
private:
QMap< unsigned int, int> m_idx_instance2vec;
QMap< taskNode * , int> m_idx_node2vec;
QMap< unsigned int, QVector<unsigned int> > m_idx_in2instances;
QMap< unsigned int, QVector<QString> > m_idx_in2names;
QMap< unsigned int, QVector<unsigned int> > m_idx_out2instances;
QMap< unsigned int, QVector<QString> > m_idx_out2names;
private:
QMap< unsigned int, unsigned int> m_hang_in2instance;
QMap< unsigned int, QString> m_hang_in2name;
QMap< unsigned int, QString> m_hang_in2fullname;
QMap< QString, unsigned int> m_hang_fullname2in;
QMap< unsigned int, unsigned int> m_hang_out2instance;
QMap< unsigned int, QString> m_hang_out2name;
QMap< unsigned int, QString> m_hang_out2fullname;
QMap< QString ,unsigned int> m_hang_fullname2out;
QMap< unsigned int, unsigned int> m_iface_inside2outside_in;
QMap< unsigned int, unsigned int> m_iface_inside2outside_out;
QMap< unsigned int, unsigned int> m_iface_outside2inside_in;
QMap< unsigned int, unsigned int> m_iface_outside2inside_out;
private:
std::function<taskCell * (void)> m_fNewCell;
std::function<void (taskCell * pmod, taskNode * pnod,QPointF pt)> m_fInsAppended;
std::function<void (void)> m_fIndexRefreshed;
std::function<QPointF (int)> m_fGetCellPos;
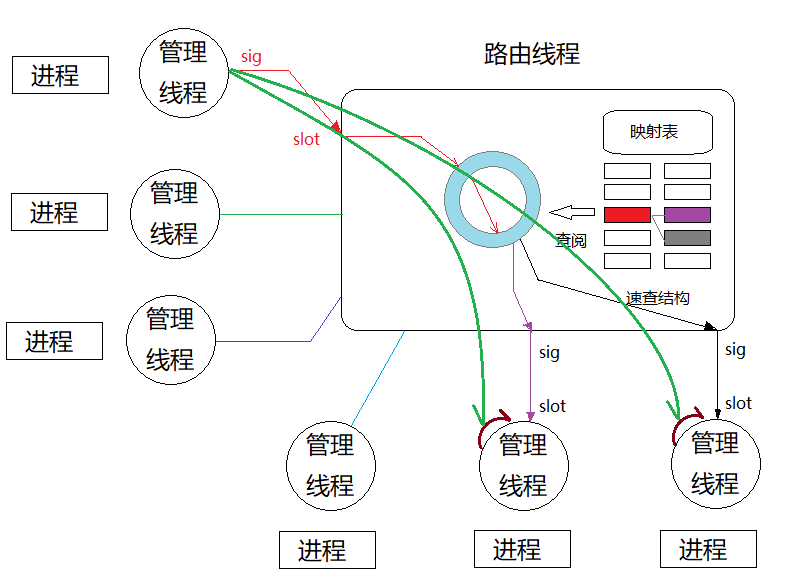
好是头大!不过,仔细分析,发现这些索引是在工程创建时就已经固定,后续不再发生任何修改。如此一来,在各个进程的管理线程中,就能直接调用路由线程的路由函数,并向各个消费者精准推送数据:
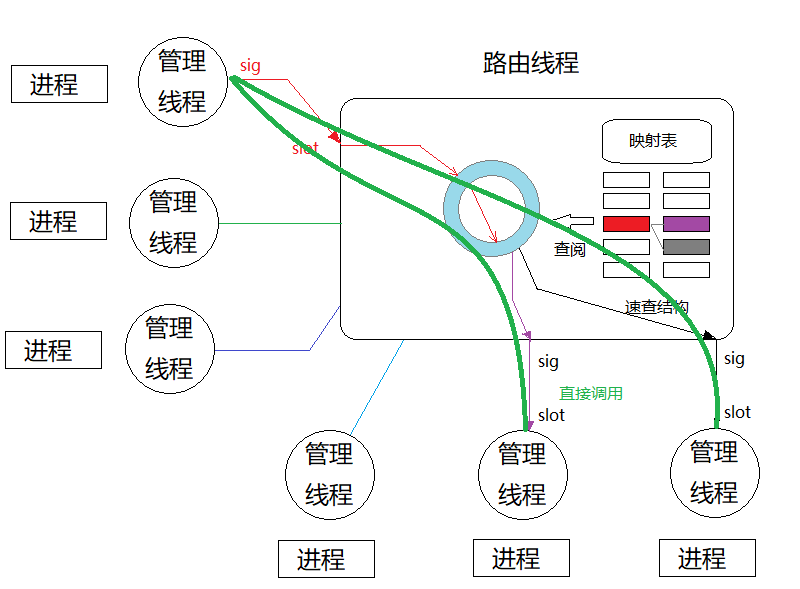
上图是Qt6的直接连接方式,相当于从生产者线程直接调用各个消费者线程管理的进程对象的QProcess::write,此时分析一下调用量:
对单个包而言,发生调用的次数就是消费者的个数 Mi
因此,整体调用次数:
T = ∑ i = 0 K M i T=\sum_{i=0}^{K}M_i T=i=0∑KMi
按照上面的例子的取值,为
T = ∑ i = 0 2000 3 + ∑ i = 0 8500 1 = 14500 T=\sum_{i=0}^{2000}{3} + \sum_{i=0}^{8500}{1}=14500 T=i=0∑20003+i=0∑85001=14500
假设信号与槽和函数调用的本身速度差为10倍,则整体性能提升:
$$ A=10*141000/14500=97 倍。
若原本的延迟为2秒,则优化后应在 20 ms左右,加上处理延迟,不会超过80ms。
4. Qt5 与 Qt6的灵活性差异
对于Qt5而言,从线程A中直接调用线程B管理的 QProcess 的write方法时,数据是写不进去的。Qt6显然是考虑到这个问题,允许这种调用。
为了解决Qt5临门一脚的问题,需要在管理者线程中使用一个异步的信号-槽调用,略微增加了延迟。
5 测试结果
在1M 16bit IQ 采样率下,主要延迟在缓存与处理,延迟90ms。

在2.5M IQ采样率下,平均延迟65ms左右
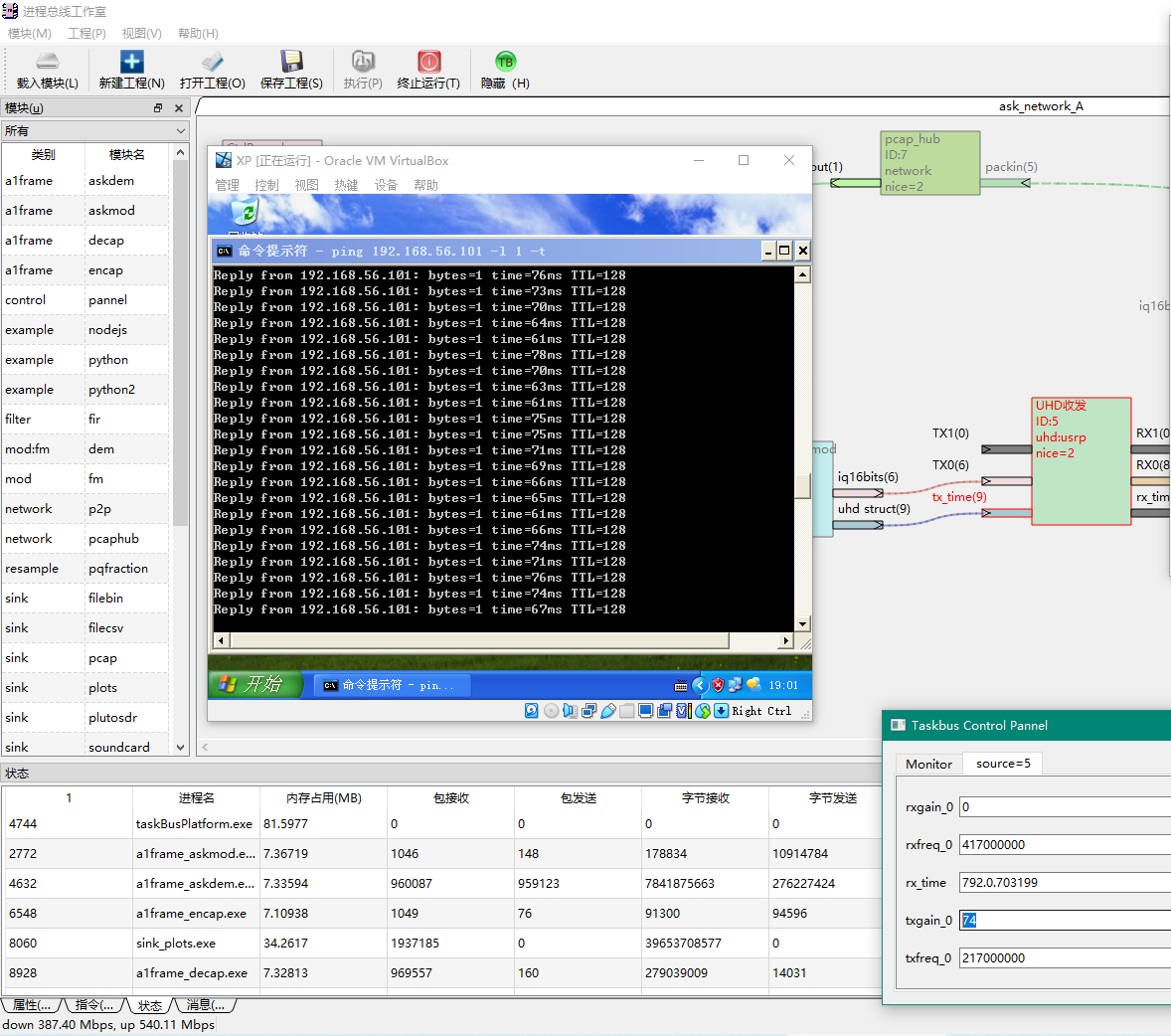
把采样率提高到5M,平均延迟60ms左右。
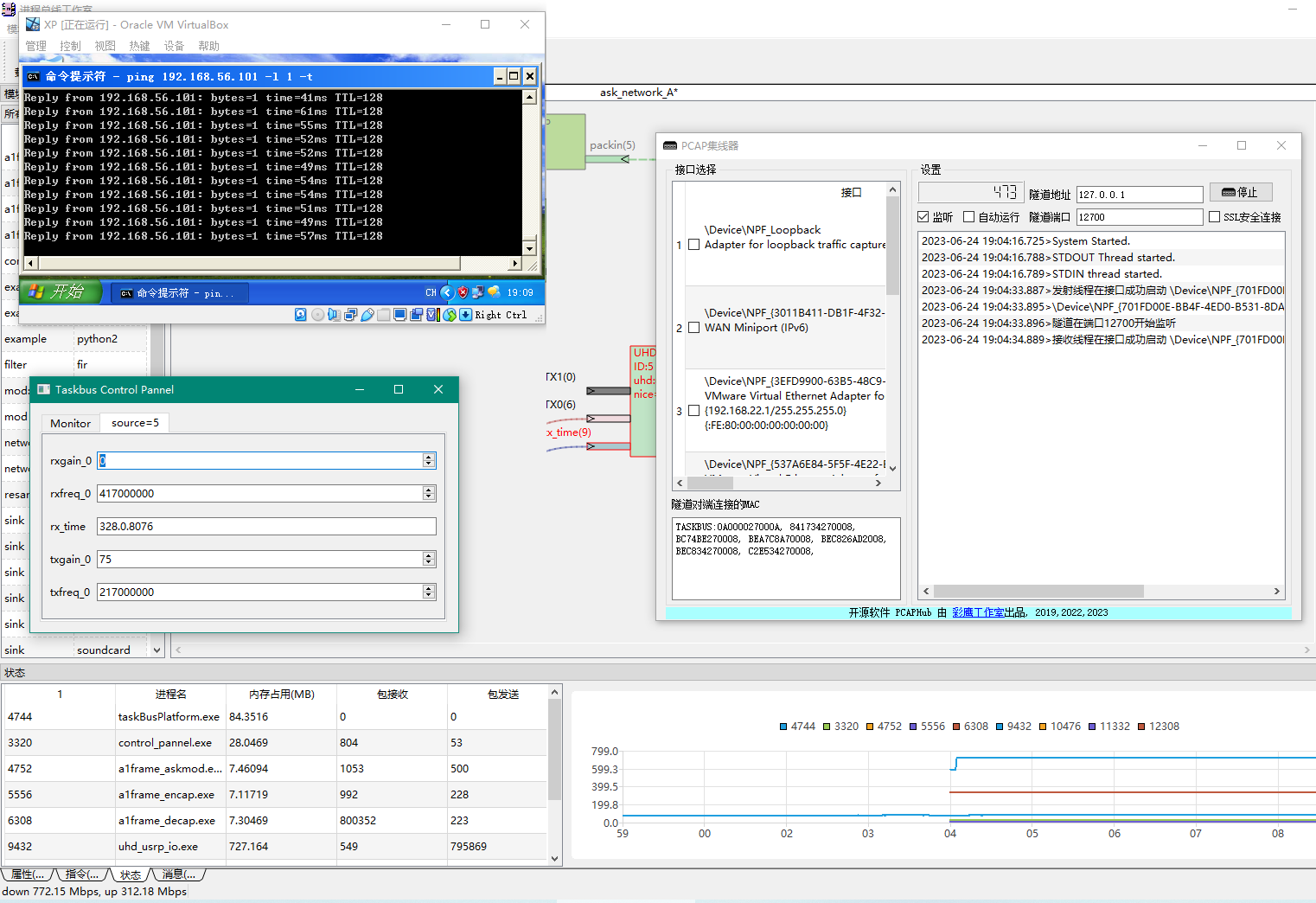 在20M采样率下,进一步缩小到46ms
在20M采样率下,进一步缩小到46ms
6 改进建议
由于没有使用环形静态缓存与SIMD技术,使得对20M信号的软处理已经无法单核完成。对于用于工业应用情景下,挑战56M带宽需要更为严苛的底层优化技术。但通过避免信号与槽的滥用,已经把可用带宽提高了8-10倍。
相关代码参考
taskBus软件仓库