为了完成本关任务,你需要掌握: 1、Sqoop 导出( export )的基本参数。 2、配置环境。
Sqoop 导出( export )的基本参数。
Sqoop 能够让 Hadoop 上的 HDFS 和 Hive 跟关系型数据库之间进行数据导入与导出,多亏了import和export这两个工具。本实训主要是针对export(导出)来讲。 数据在Hadoop平台上进行处理后,我们可能需要将结果同步到关系数据库中作为业务的辅助数据,这时候需要将Hadoop平台分析后的数据导出(export)到关系数据库。 我们要学 Sqoop 的导出也必须先知道里面的基本语法。 输入sqoop help export可以查看里面参数含义,导出和导入基本参数都差不多,接下来选取几个常见的参数来分析:
| 选项 | 含义说明 |
|---|---|
--connect <jdbc-uri> | 指定JDBC连接字符串 |
--driver <class-name> | 指定要使用的JDBC驱动程序类 |
--hadoop-mapred-home <dir> | 指定$HADOOP_MAPRED_HOME路径 |
| -P | 从控制台读取输入的密码 |
--username <username> | 设置认证用户名 |
--password <password> | 设置认证密码 |
| --verbose | 打印详细的运行信息 |
--columns <col,col,col…> | 要导出到表格的列 |
| --direct | 使用直接导入模式(优化导入速度 |
--export-dir <dir> | 用于导出的HDFS源路径 |
--num-mappers <n>(简写:-m) | 使用n个mapper任务并行导出 |
--table <table-name> | 要填充的表 |
--staging-table <staging-table-name> | 数据在插入目标表之前将在其中展开的表格。 |
| --clear-staging-table | 表示可以删除登台表中的任何数据 |
| --batch | 使用批量模式导出 |
--fields-terminated-by <char> | 设置字段分隔符 |
--lines-terminated-by <char> | 设置行尾字符 |
--optionally-enclosed-by <char> | 设置字段包含字符 |
配置环境
注意:如果这个环境不配置的话,可能会造成后续关卡不能正常实现。 1、启动Hadoop。
start-all.sh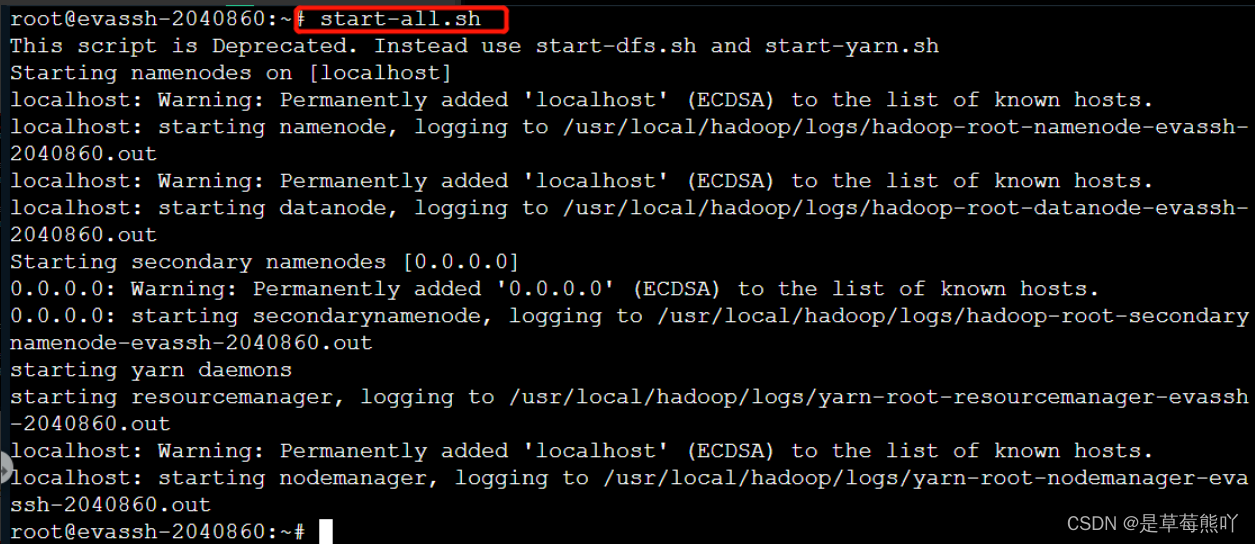
2、Hive连接 MySQL 初始化。
schematool -dbType mysql -initSchema
编程要求
在右侧命令行进行操作: 1.启动Hadoop服务; 2.Hive 连接 MySQL 初始化。
start-all.sh
schematool -dbType mysql -initSchema