一、Kafka硬件配置选择
1.1 场景说明
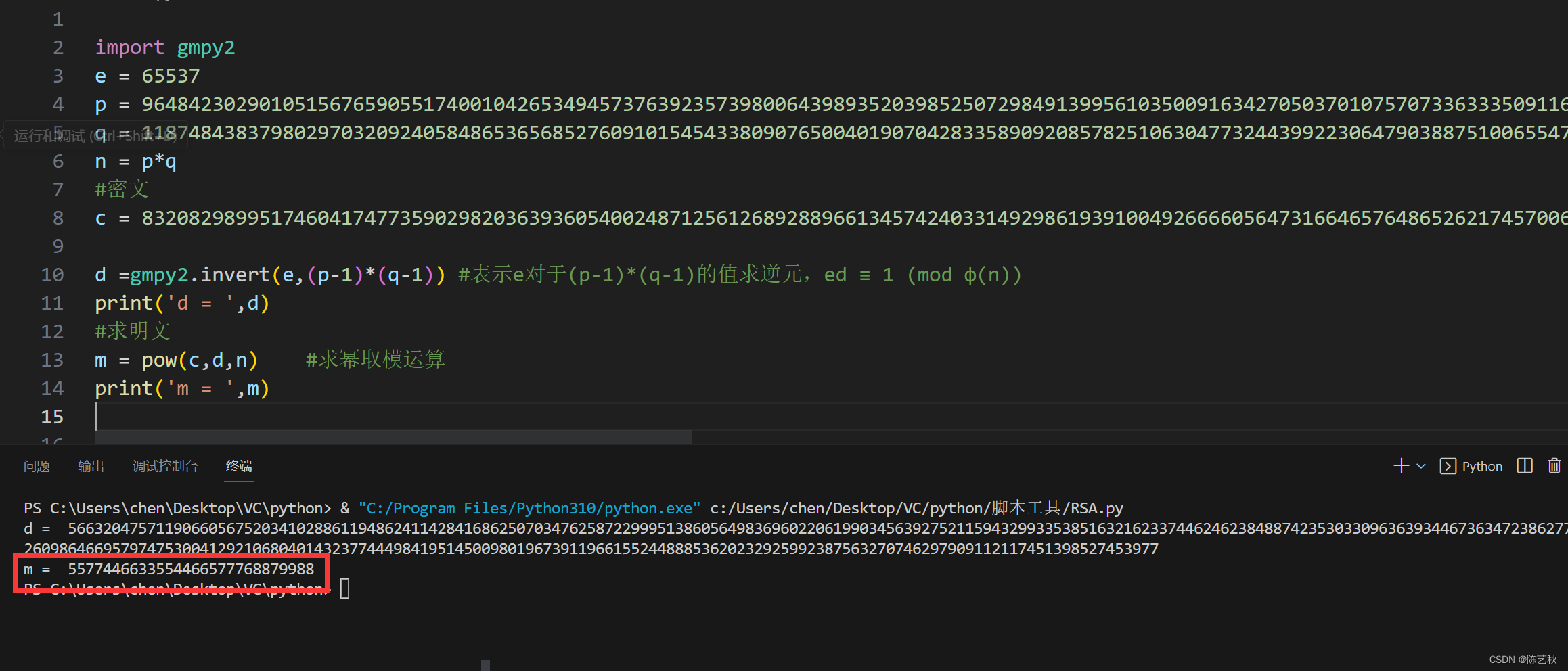
100 万日活,每人每天 100 条日志,每天总共的日志条数是 100 万 * 100 条 = 1 亿条。
1 亿/24 小时/60 分/60 秒 = 1150 条/每秒钟。
每条日志大小:0.5k - 2k(取 1k)。
1150 条/每秒钟 * 1k ≈ 1m/s 。
高峰期每秒钟:1150 条 * 20 倍 = 23000 条。
每秒多少数据量:20MB/s。
1.2 服务器台数选择
服务器台数= 2 * (生产者峰值生产速率 * 副本 / 100) + 1
即 2 * (20m/s * 2 / 100) + 1= 3 台
建议 3 台服务器。
1.3 磁盘选择
kafka 底层主要是顺序写,固态硬盘和机械硬盘的顺序写速度差不多。建议选择普通的机械硬盘。
每天总数据量:1 亿条 * 1k ≈ 100g
100g * 副本 2 * 保存时间 3 天 / 0.7 ≈ 1T
建议三台服务器硬盘总大小,大于等于 1T
1.4 内存选择
Kafka 内存组成:堆内存 + 页缓存
1)Kafka 堆内存建议每个节点:10g ~ 15g
在 kafka-server-start.sh 中修改
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx10G -Xms10G"
fi(1)查看 Kafka 进程号
[atguigu@hadoop102 kafka]$ jps
2321 Kafka
5255 Jps
1931 QuorumPeerMain(2)根据 Kafka 进程号,查看 Kafka 的 GC 情况
[atguigu@hadoop102 kafka]$ jstat -gc 2321 1s 10
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
0.0 7168.0 0.0 7168.0 103424.0 60416.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 60416.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 60416.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 60416.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 60416.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 61440.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 61440.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 61440.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 61440.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 61440.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531参数说明:
S0C:第一个幸存区的大小; S1C:第二个幸存区的大小
S0U:第一个幸存区的使用大小; S1U:第二个幸存区的使用大小
EC:伊甸园区的大小; EU:伊甸园区的使用大小
OC:老年代大小; OU:老年代使用大小
MC:方法区大小; MU:方法区使用大小
CCSC:压缩类空间大小; CCSU:压缩类空间使用大小
YGC:年轻代垃圾回收次数; YGCT:年轻代垃圾回收消耗时间
FGC:老年代垃圾回收次数; FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间;
2)页缓存:页缓存是 Linux 系统服务器的内存。我们只需要保证 1 个 segment(1g)中25%的数据在内存中就好。
每个节点页缓存大小 =(分区数 * 1g * 25%)/ 节点数。例如 10 个分区,页缓存大小=(10 * 1g * 25%)/ 3 ≈ 1g
建议服务器内存大于等于 11G。
1.5 CPU选择
num.io.threads = 8 负责写磁盘的线程数,整个参数值要占总核数的 50%。
num.replica.fetchers = 1 副本拉取线程数,这个参数占总核数的 50%的 1/3。
num.network.threads = 3 数据传输线程数,这个参数占总核数的 50%的 2/3。
建议 32 个 cpu core。
1.6 网络选择
网络带宽 = 峰值吞吐量 ≈ 20MB/s 。选择千兆网卡即可。
100Mbps 单位是 bit;10M/s 单位是 byte ; 1byte = 8bit,100Mbps/8 = 12.5M/s。
一般百兆的网卡(100Mbps )、千兆的网卡(1000Mbps)、万兆的网卡(10000Mbps)。
二、Kafka生产者
2.1 Kafka生产者核心参数配置
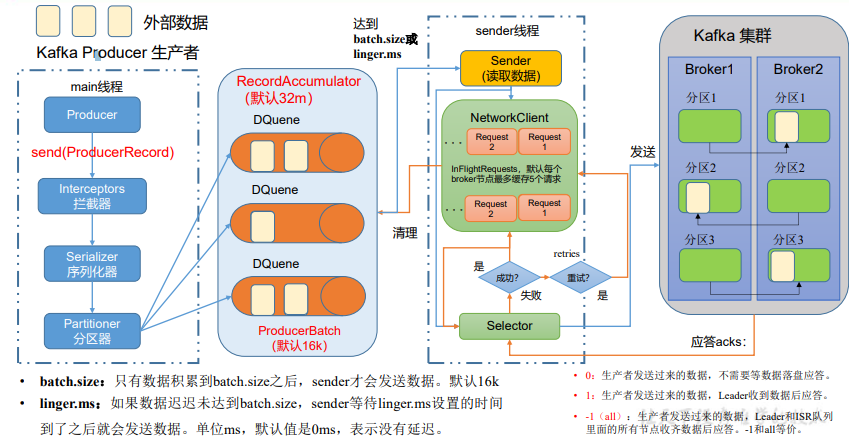
| 参数名称 | 描述 |
| bootstrap.servers | 生 产 者 连 接 集 群 所 需 的 broker 地 址 清 单 。 例 如hadoop102:9092,hadoop103:9092,hadoop104:9092,可以设置 1 个或者多个,中间用逗号隔开。 注意这里并非需要所有的 broker 地址,因为生产者从给定的 broker 里查找到其他 broker 信息。 |
| key.serializer 和 value.serializer | 指定发送消息的 key 和 value 的序列化类型。一定要写全类名。 |
| buffer.memory | RecordAccumulator 缓冲区总大小,默认 32m。 |
| batch.size | 缓冲区一批数据最大值,默认 16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据传输延迟增加。 |
| linger.ms | 如果数据迟迟未达到 batch.size,sender 等待 linger.time之后就会发送数据。单位 ms,默认值是 0ms,表示没有延迟。生产环境建议该值大小为 5-100ms 之间。 |
| acks | 0:生产者发送过来的数据,不需要等数据落盘应答。 1:生产者发送过来的数据,Leader 收到数据后应答。 -1(all):生产者发送过来的数据,Leader+和 isr 队列里面的所有节点收齐数据后应答。默认值是-1,-1 和 all是等价的。 |
| max.in.flight.requests.per.connection | 允许最多没有返回 ack 的次数,默认为 5,开启幂等性要保证该值是 1-5 的数字。 |
| retries | 当消息发送出现错误的时候,系统会重发消息。retries 表示重试次数。默认是 int 最大值,2147483647。 如果设置了重试,还想保证消息的有序性,需要设置MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1否则在重试此失败消息的时候,其他的消息可能发送成功了。 |
| retry.backoff.ms | 两次重试之间的时间间隔,默认是 100ms。 |
| enable.idempotence | 是否开启幂等性,默认 true,开启幂等性。 |
| compression.type | 生产者发送的所有数据的压缩方式。默认是 none,也就是不压缩。 |
2.2 生产者如何提高吞吐量
| 参数名称 | 描述 |
| buffer.memory | RecordAccumulator 缓冲区总大小,默认 32m。 |
| batch.size | 缓冲区一批数据最大值,默认 16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据传输延迟增加。 |
| linger.ms | 如果数据迟迟未达到 batch.size,sender 等待 linger.time之后就会发送数据。单位 ms,默认值是 0ms,表示没有延迟。生产环境建议该值大小为 5-100ms 之间。 |
| compression.type | 生产者发送的所有数据的压缩方式。默认是 none,也就是不压缩。 支持压缩类型:none、gzip、snappy、lz4 和 zstd。 |
2.3 数据可靠性
| 参数名称 | 描述 |
| acks | 0:生产者发送过来的数据,不需要等数据落盘应答。 1:生产者发送过来的数据,Leader 收到数据后应答。 -1(all):生产者发送过来的数据,Leader+和 isr 队列里面的所有节点收齐数据后应答。默认值是-1,-1 和 all是等价的。 |
2.4 数据去重
1)配置参数
| 参数名称 | 描述 |
| enable.idempotence | 是否开启幂等性,默认 true,表示开启幂等性。 |
2)Kafka 的事务一共有如下 5 个 API
// 1 初始化事务
void initTransactions();
// 2 开启事务
void beginTransaction() throws ProducerFencedException;
// 3 在事务内提交已经消费的偏移量(主要用于消费者)
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws
ProducerFencedException;
// 4 提交事务
void commitTransaction() throws ProducerFencedException;
// 5 放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;2.5 数据有序
单分区内,有序(有条件的,不能乱序);多分区,分区与分区间无序;
2.6 数据乱序
| 参数名称 | 描述 |
| enable.idempotence | 是否开启幂等性,默认 true,表示开启幂等性。 |
| max.in.flight.requests.per.connection | 允许最多没有返回 ack 的次数,默认为 5,开启幂等性要保证该值是 1-5 的数字。 |
三、Kafka Broker
3.1 Broker 核心参数配置

| 参数名称 | 描述 |
| replica.lag.time.max.ms | ISR 中,如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值,默认 30s。 |
| auto.leader.rebalance.enable | 默认是 true。 自动 Leader Partition 平衡。建议关闭。 |
| leader.imbalance.per.broker.percentage | 默认是 10%。每个 broker 允许的不平衡的 leader的比率。如果每个 broker 超过了这个值,控制器会触发 leader 的平衡。 |
| leader.imbalance.check.interval.seconds | 默认值 300 秒。检查 leader 负载是否平衡的间隔时间。 |
| log.segment.bytes | Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分 成块的大小,默认值 1G。 |
| log.index.interval.bytes | 默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引。 |
| log.retention.hours | Kafka 中数据保存的时间,默认 7 天。 |
| log.retention.minutes | Kafka 中数据保存的时间,分钟级别,默认关闭。 |
| log.retention.ms | Kafka 中数据保存的时间,毫秒级别,默认关闭。 |
| log.retention.check.interval.ms | 检查数据是否保存超时的间隔,默认是 5 分钟 |
| log.retention.bytes | 默认等于-1,表示无穷大。超过设置的所有日志总大小,删除最早的 segment。 |
| log.cleanup.policy | 默认是 delete,表示所有数据启用删除策略;如果设置值为 compact,表示所有数据启用压缩策略。 |
| num.io.threads | 默认是 8。负责写磁盘的线程数。整个参数值要占总核数的 50%。 |
| num.replica.fetchers | 默认是 1。副本拉取线程数,这个参数占总核数的 50%的 1/3 |
| num.network.threads | 默认是 3。数据传输线程数,这个参数占总核数的 50%的 2/3 。 |
| log.flush.interval.messages | 强制页缓存刷写到磁盘的条数,默认是 long 的最大值,9223372036854775807。一般不建议修改,交给系统自己管理。 |
| log.flush.interval.ms | 每隔多久,刷数据到磁盘,默认是 null。一般不建议修改,交给系统自己管理。 |
3.2 服役新节点、退役旧节点
(1)创建一个要均衡的主题。
[atguigu@hadoop102 kafka]$ vim topics-to-move.json
{
"topics": [
{"topic": "first"}
],
"version": 1
}(2)生成一个负载均衡的计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generate(3)创建副本存储计划(所有副本存储在 broker0、broker1、broker2、broker3 中)。
[atguigu@hadoop102 kafka]$ vim increase-replication-factor.json(4)执行副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increasereplication-factor.json --execute(5)验证副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increasereplication-factor.json --verify3.3 增加分区
1)修改分区数(注意:分区数只能增加,不能减少)
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 33.4 增加副本因子
1)创建 topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --partitions 3 --replication-factor 1 --topic four2)手动增加副本存储
(1)创建副本存储计划(所有副本都指定存储在 broker0、broker1、broker2 中)。
[atguigu@hadoop102 kafka]$ vim increase-replication-factor.json输入如下内容:
{
"version":1,
"partitions":[
{
"topic":"four",
"partition":0,
"replicas":[
0,
1,
2
]
},
{
"topic":"four",
"partition":1,
"replicas":[
0,
1,
2
]
},
{
"topic":"four",
"partition":2,
"replicas":[
0,
1,
2
]
}
]
}(2)执行副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increasereplication-factor.json --execute3.5 手动调整分区副本存储
(1)创建副本存储计划(所有副本都指定存储在 broker0、broker1 中)。
[atguigu@hadoop102 kafka]$ vim increase-replication-factor.json输入如下内容:
{
"version":1,
"partitions":[
{
"topic":"three",
"partition":0,
"replicas":[
0,
1
]
},
{
"topic":"three",
"partition":1,
"replicas":[
0,
1
]
},
{
"topic":"three",
"partition":2,
"replicas":[
1,
0
]
},
{
"topic":"three",
"partition":3,
"replicas":[
1,
0
]
}
]
}(2)执行副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increasereplication-factor.json --execute(3)验证副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increasereplication-factor.json --verify3.6 Leader Partition 负载平衡
| 参数名称 | 描述 |
| auto.leader.rebalance.enable | 默认是 true。自动 Leader Partition 平衡。生产环境中,leader 重选举的代价比较大,可能会带来性能影响,建议设置为 false 关闭。 |
| leader.imbalance.per.broker.percentage | 默认是 10%。每个 broker 允许的不平衡的 leader的比率。如果每个 broker 超过了这个值,控制器会触发 leader 的平衡。 |
| leader.imbalance.check.interval.seconds | 默认值 300 秒。检查 leader 负载是否平衡的间隔时间。 |
3.7 自动创建主题
如果 broker 端配置参数 auto.create.topics.enable 设置为 true(默认值是 true),那么当生产者向一个未创建的主题发送消息时,会自动创建一个分区数为 num.partitions(默认值为1)、副本因子为 default.replication.factor(默认值为 1)的主题。
除此之外,当一个消费者开始从未知主题中读取消息时,或者当任意一个客户端向未知主题发送元数据请求时,都会自动创建一个相应主题。这种创建主题的方式是非预期的,增加了主题管理和维护的难度。生产环境建议将该参数设置为 false。
1)向一个没有提前创建 five 主题发送数据
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic five
>hello world2)查看 five 主题的详情
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-serverhadoop102:9092 --describe --topic five四、Kafka 消费者
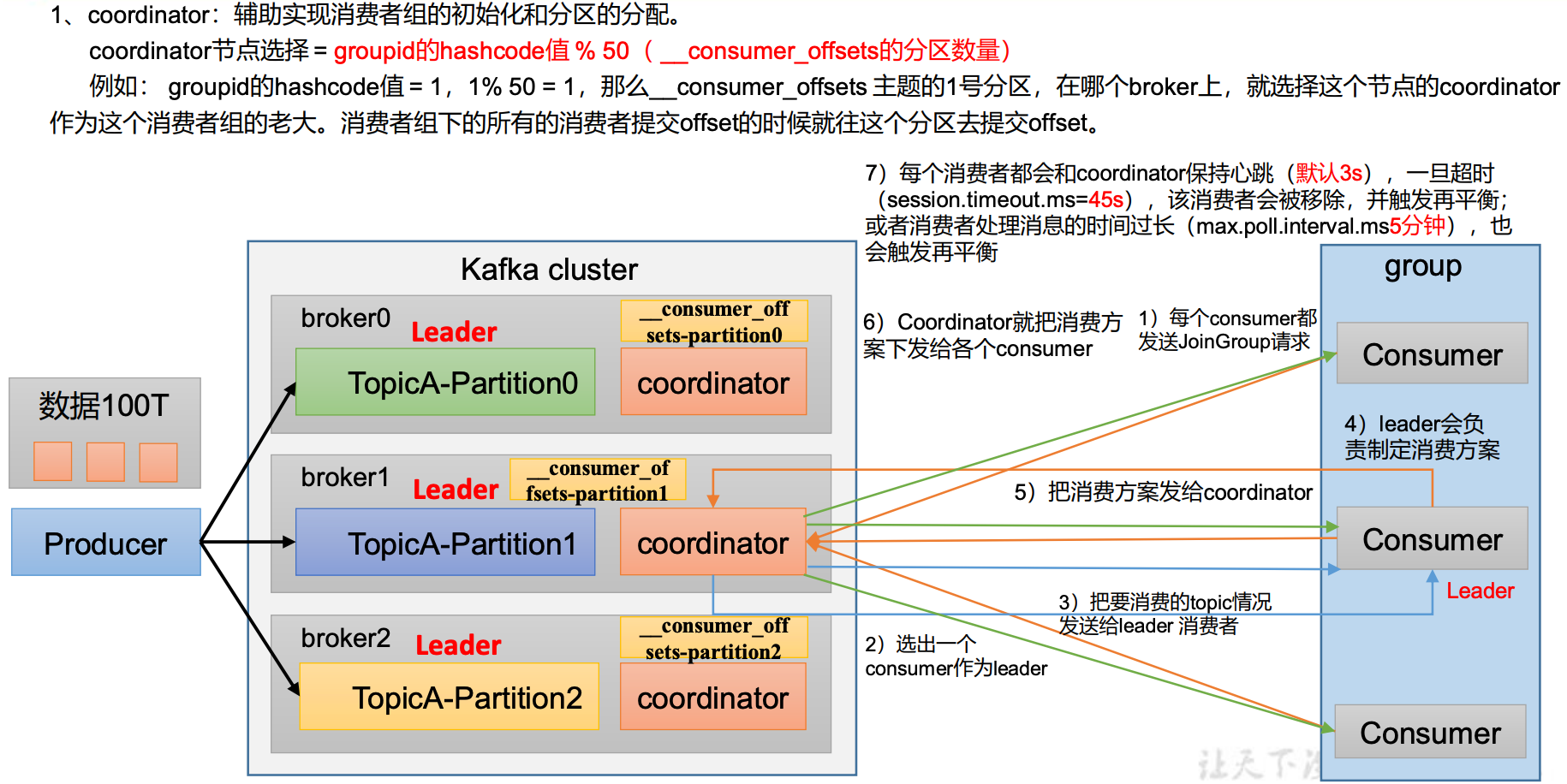
4.1 Kafka 消费者核心参数配置
消费者组初始化流程

消费者组详细消费流程
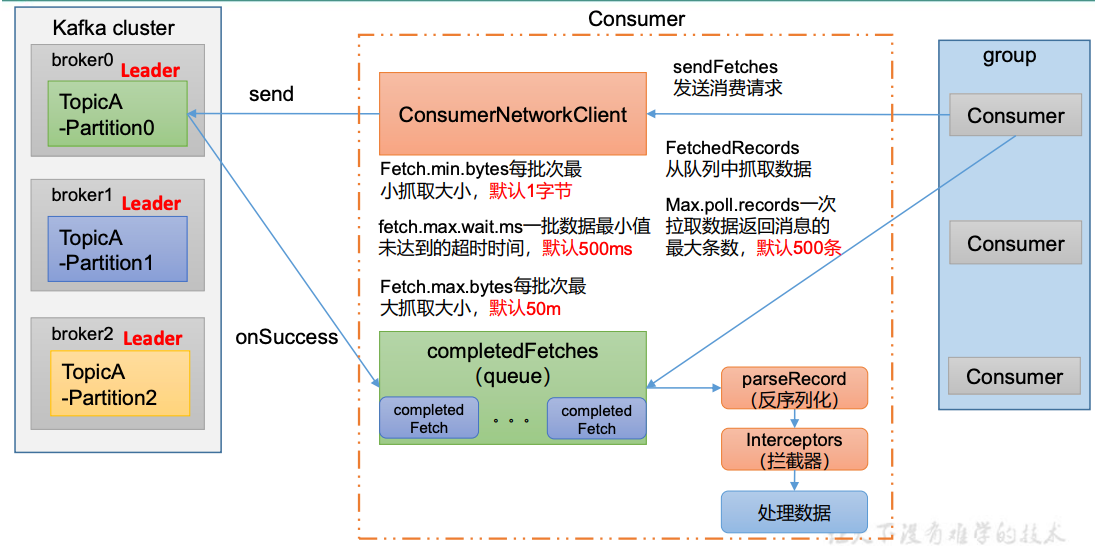
| 参数名称 | 描述 |
| bootstrap.servers | 向 Kafka 集群建立初始连接用到的 host/port 列表。 |
| key.deserializer 和value.deserializer | 指定接收消息的 key 和 value 的反序列化类型。一定要写全类名。 |
| group.id | 标记消费者所属的消费者组。 |
| enable.auto.commit | 默认值为 true,消费者会自动周期性地向服务器提交偏移量 |
| auto.commit.interval.ms | 如果设置了 enable.auto.commit 的值为 true, 则该值定义了消费者偏移量向 Kafka 提交的频率,默认 5s。 |
| auto.offset.reset | 当 Kafka 中没有初始偏移量或当前偏移量在服务器中不存在(如,数据被删除了),该如何处理? earliest:自动重置偏移量到最早的偏移量。 latest:默认,自动重置偏移量为最新的偏移量。 none:如果消费组原来的(previous)偏移量不存在,则向消费者抛异常。 anything:向消费者抛异常。 |
| offsets.topic.num.partitions | __consumer_offsets 的分区数,默认是 50 个分区。不建议修改。 |
| heartbeat.interval.ms | Kafka 消费者和 coordinator 之间的心跳时间,默认 3s。该条目的值必须小于 session.timeout.ms ,也不应该高于session.timeout.ms 的 1/3。不建议修改。 |
| session.timeout.ms | Kafka 消费者和 coordinator 之间连接超时时间,默认 45s。超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是 5 分钟。超过该值,该消费者被移除,消费者组执行再平衡。 |
| fetch.min.bytes | 默认 1 个字节。消费者获取服务器端一批消息最小的字节数。 |
| fetch.max.wait.ms | 默认 500ms。如果没有从服务器端获取到一批数据的最小字节数。该时间到,仍然会返回数据。 |
| fetch.max.bytes | 默认 Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受 message.max.bytes (brokerconfig)or max.message.bytes (topic config)影响。 |
| max.poll.records | 一次 poll 拉取数据返回消息的最大条数,默认是 500 条。 |
4.2 消费者再平衡
| 参数名称 | 描述 |
| heartbeat.interval.ms | Kafka 消费者和 coordinator 之间的心跳时间,默认 3s。该条目的值必须小于 session.timeout.ms,也不应该高于session.timeout.ms 的 1/3。 |
| session.timeout.ms | Kafka 消费者和 coordinator 之间连接超时时间,默认 45s。超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是 5 分钟。超过该值,该消费者被移除,消费者组执行再平衡。 |
| partition.assignment.strategy | 消 费 者 分 区 分 配 策 略 , 默 认 策 略 是 Range +CooperativeSticky。Kafka 可以同时使用多个分区分配策略。可以选择的策略包括:Range、RoundRobin、Sticky、CooperativeSticky |
4.3 指定Offset消费
kafkaConsumer.seek(topic, 1000);4.4 指定时间消费
HashMap timestampToSearch = new HashMap<>();
timestampToSearch.put(topicPartition, System.currentTimeMillis() -1 * 24 * 3600 * 1000);
kafkaConsumer.offsetsForTimes(timestampToSearch);4.5 消费者事务
4.6 消费者如何提高吞吐量
增加分区数;
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-serverhadoop102:9092 --alter --topic first --partitions 3| 参数名称 | 描述 |
| fetch.max.bytes | 默认 Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影响。 |
| max.poll.records | 一次 poll 拉取数据返回消息的最大条数,默认是 500 条 |
五、Kafka 总体
5.1 如何提升吞吐量
1)提升生产吞吐量
- buffer.memory:发送消息的缓冲区大小,默认值是 32m,可以增加到 64m。
- batch.size:默认是 16k。如果 batch 设置太小,会导致频繁网络请求,吞吐量下降;如果 batch 太大,会导致一条消息需要等待很久才能被发送出去,增加网络延时
- linger.ms,这个值默认是 0,意思就是消息必须立即被发送。一般设置一个 5-100毫秒。如果 linger.ms 设置的太小,会导致频繁网络请求,吞吐量下降;如果 linger.ms 太长,会导致一条消息需要等待很久才能被发送出去,增加网络延时。
- compression.type:默认是 none,不压缩,但是也可以使用 lz4 压缩,效率还是不错的,压缩之后可以减小数据量,提升吞吐量,但是会加大 producer 端的 CPU 开销。
2)增加分区
3)消费者提高吞吐量
- 调整 fetch.max.bytes 大小,默认是 50m。
- 调整 max.poll.records 大小,默认是 500 条。
4)增加下游消费者处理能力
5.2 数据精准一次
1)生产者角度
- acks 设置为-1 (acks=-1)。
- 幂等性(enable.idempotence = true) + 事务 。
2)broker 服务端角度
- 分区副本大于等于 2 (--replication-factor 2)。
- ISR 里应答的最小副本数量大于等于 2 (min.insync.replicas = 2)。
3)消费者
- 事务 + 手动提交 offset (enable.auto.commit = false)。
- 消费者输出的目的地必须支持事务(MySQL、Kafka)。
5.3 合理设置分区数
(1)创建一个只有 1 个分区的 topic。
(2)测试这个 topic 的 producer 吞吐量和 consumer 吞吐量。
(3)假设他们的值分别是 Tp 和 Tc,单位可以是 MB/s。
(4)然后假设总的目标吞吐量是 Tt,那么分区数 = Tt / min(Tp,Tc)。
例如:producer 吞吐量 = 20m/s;consumer 吞吐量 = 50m/s,期望吞吐量 100m/s;
分区数 = 100 / 20 = 5 分区
分区数一般设置为:3-10 个
分区数不是越多越好,也不是越少越好,需要搭建完集群,进行压测,再灵活调整分区个数。
5.4 单条日志大于1m
| 参数名称 | 描述 |
| message.max.bytes | 默认 1m,broker 端接收每个批次消息最大值。 |
| max.request.size | 默认 1m,生产者发往 broker 每个请求消息最大值。针对 topic级别设置消息体的大小。 |
| replica.fetch.max.bytes | 默认 1m,副本同步数据,每个批次消息最大值。 |
| fetch.max.bytes | 默认 Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影响。 |
5.5 服务器挂了
在生产环境中,如果某个 Kafka 节点挂掉。正常处理办法:
(1)先尝试重新启动一下,如果能启动正常,那直接解决。
(2)如果重启不行,考虑增加内存、增加 CPU、网络带宽。
(3)如果将 kafka 整个节点误删除,如果副本数大于等于 2,可以按照服役新节点的方式重新服役一个新节点,并执行负载均衡。
5.6 集群压力测试
5.6.1 Kafka 压测
用 Kafka 官方自带的脚本,对 Kafka 进行压测。
- 生产者压测:kafka-producer-perf-test.sh
- 消费者压测:kafka-consumer-perf-test.sh
5.6.2 Kafka Producer 压力测试
先说结论:
- 增大batch.size,能提升吞吐量
- 增大linger.ms,能提升吞吐量
- 增大buffer.memory,能提升吞吐量
- 压缩方式compression.type 设置为 zstd 或gzip,能提升吞吐量
(1)创建一个 test topic,设置为 3 个分区 3 个副本
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrapserver hadoop102:9092 --create --replication-factor 3 --partitions 3 --topic test(2)在/opt/module/kafka/bin 目录下面有这两个文件。我们来测试一下
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=16384 linger.ms=0- record-size 是一条信息有多大,单位是字节,本次测试设置为 1k。
- num-records 是总共发送多少条信息,本次测试设置为 100 万条。
- throughput 是每秒多少条信息,设成-1,表示不限流,尽可能快的生产数据,可测出生产者最大吞吐量。本次实验设置为每秒钟 1 万条。
- producer-props 后面可以配置生产者相关参数,batch.size 配置为 16k。
输出结果:
ap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=16384
linger.ms=0
37021 records sent, 7401.2 records/sec (7.23 MB/sec), 1136.0 ms avg latency, 1453.0 ms max latency.
50535 records sent, 10107.0 records/sec (9.87 MB/sec), 1199.5 ms avg latency, 1404.0 ms max latency.
47835 records sent, 9567.0 records/sec (9.34 MB/sec), 1350.8 ms avg latency, 1570.0 ms max latency.
。。。 。。。
42390 records sent, 8444.2 records/sec (8.25 MB/sec), 3372.6 ms avg latency, 4008.0 ms max latency.
37800 records sent, 7558.5 records/sec (7.38 MB/sec), 4079.7 ms avg latency, 4758.0 ms max latency.
33570 records sent, 6714.0 records/sec (6.56 MB/sec), 4549.0 ms avg latency, 5049.0 ms max latency.
1000000 records sent, 9180.713158 records/sec (8.97 MB/sec), 1894.78 ms avg latency, 5049.00 ms max latency, 1335 ms 50th, 4128 ms 95th, 4719 ms 99th, 5030 ms 99.9th.(3)调整 batch.size 大小
①batch.size 默认值是 16k。本次实验 batch.size 设置为 32k。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=32768 linger.ms=0输出结果:
49922 records sent, 9978.4 records/sec (9.74 MB/sec), 64.2 ms avg latency, 340.0 ms max latency.
49940 records sent, 9988.0 records/sec (9.75 MB/sec), 15.3 ms avg latency, 31.0 ms max latency.
50018 records sent, 10003.6 records/sec (9.77 MB/sec), 16.4 ms avg latency, 52.0 ms max latency.
。。。 。。。
49960 records sent, 9992.0 records/sec (9.76 MB/sec), 17.2 ms avg latency, 40.0 ms max latency.
50090 records sent, 10016.0 records/sec (9.78 MB/sec), 16.9 ms avg latency, 47.0 ms max latency.
1000000 records sent, 9997.600576 records/sec (9.76 MB/sec), 20.20 ms avg latency, 340.00 ms max latency, 16 ms 50th, 30 ms 95th, 168 ms 99th, 249 ms 99.9th.②batch.size 默认值是 16k。本次实验 batch.size 设置为 4k。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=4096 linger.ms=0输出结果:
15598 records sent, 3117.1 records/sec (3.04 MB/sec), 1878.3 ms avg latency, 3458.0 ms max latency.
17748 records sent, 3549.6 records/sec (3.47 MB/sec), 5072.5 ms avg latency, 6705.0 ms max latency.
18675 records sent, 3733.5 records/sec (3.65 MB/sec), 6800.9 ms avg latency, 7052.0 ms max latency.
。。。 。。。
19125 records sent, 3825.0 records/sec (3.74 MB/sec), 6416.5 ms avg latency, 7023.0 ms max latency.
1000000 records sent, 3660.201531 records/sec (3.57 MB/sec), 6576.68 ms avg latency, 7677.00 ms max latency, 6745 ms 50th, 7298 ms 95th, 7507 ms 99th, 7633 ms 99.9th.(4)调整 linger.ms 时间
linger.ms 默认是 0ms。本次实验 linger.ms 设置为 50ms。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=4096 linger.ms=50输出结果:
16804 records sent, 3360.1 records/sec (3.28 MB/sec), 1841.6 ms avg latency, 3338.0 ms max latency.
18972 records sent, 3793.6 records/sec (3.70 MB/sec), 4877.7 ms avg latency, 6453.0 ms max latency.
19269 records sent, 3852.3 records/sec (3.76 MB/sec), 6477.9 ms avg latency, 6686.0 ms max latency.
。。。 。。。
17073 records sent, 3414.6 records/sec (3.33 MB/sec), 6987.7 ms avg latency, 7353.0 ms max latency.
19326 records sent, 3865.2 records/sec (3.77 MB/sec), 6756.5 ms avg latency, 7357.0 ms max latency.
1000000 records sent, 3842.754486 records/sec (3.75 MB/sec), 6272.49 ms avg latency, 7437.00 ms max latency, 6308 ms 50th, 6880 ms 95th, 7289 ms 99th, 7387 ms 99.9th.(5)调整压缩方式
①默认的压缩方式是 none。本次实验 compression.type 设置为 snappy。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=4096 linger.ms=50 compression.type=snappy输出结果:
17244 records sent, 3446.0 records/sec (3.37 MB/sec), 5207.0 ms avg latency, 6861.0 ms max latency.
18873 records sent, 3774.6 records/sec (3.69 MB/sec), 6865.0 ms avg latency, 7094.0 ms max latency.
18378 records sent, 3674.1 records/sec (3.59 MB/sec), 6579.2 ms avg latency, 6738.0 ms max latency.
。。。 。。。
17631 records sent, 3526.2 records/sec (3.44 MB/sec), 6671.3 ms avg latency, 7566.0 ms max latency.
19116 records sent, 3823.2 records/sec (3.73 MB/sec), 6739.4 ms avg latency, 7630.0 ms max latency.
1000000 records sent, 3722.925028 records/sec (3.64 MB/sec), 6467.75 ms avg latency, 7727.00 ms max latency, 6440 ms 50th, 7308 ms 95th, 7553 ms 99th, 7665 ms 99.9th②默认的压缩方式是 none。本次实验 compression.type 设置为 zstd。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=4096 linger.ms=50 compression.type=zstd输出结果:
23820 records sent, 4763.0 records/sec (4.65 MB/sec), 1580.2 ms avg latency, 2651.0 ms max latency.
29340 records sent, 5868.0 records/sec (5.73 MB/sec), 3666.0 ms avg latency, 4752.0 ms max latency.
28950 records sent, 5788.8 records/sec (5.65 MB/sec), 5785.2 ms avg latency, 6865.0 ms max latency.
。。。 。。。
29580 records sent, 5916.0 records/sec (5.78 MB/sec), 6907.6 ms avg latency, 7432.0 ms max latency.
29925 records sent, 5981.4 records/sec (5.84 MB/sec), 6948.9 ms avg latency, 7541.0 ms max latency.
1000000 records sent, 5733.583318 records/sec (5.60 MB/sec), 6824.75 ms avg latency, 7595.00 ms max latency, 7067 ms 50th, 7400 ms 95th, 7500 ms 99th, 7552 ms 99.9th.③默认的压缩方式是 none。本次实验 compression.type 设置为 gzip。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=4096 linger.ms=50 compression.type=gzip输出结果:
27170 records sent, 5428.6 records/sec (5.30 MB/sec), 1374.0 ms avg latency, 2311.0 ms max latency.
31050 records sent, 6210.0 records/sec (6.06 MB/sec), 3183.8 ms avg latency, 4228.0 ms max latency.
32145 records sent, 6427.7 records/sec (6.28 MB/sec), 5028.1 ms avg latency, 6042.0 ms max latency.
。。。 。。。
31710 records sent, 6342.0 records/sec (6.19 MB/sec), 6457.1 ms avg latency, 6777.0 ms max latency.
31755 records sent, 6348.5 records/sec (6.20 MB/sec), 6498.7 ms avg latency, 6780.0 ms max latency.
32760 records sent, 6548.1 records/sec (6.39 MB/sec), 6375.7 ms avg latency, 6822.0 ms max latency.
1000000 records sent, 6320.153706 records/sec (6.17 MB/sec), 6155.42 ms avg latency, 6943.00 ms max latency, 6437 ms 50th, 6774 ms 95th, 6863 ms 99th, 6912 ms 99.9th.④默认的压缩方式是 none。本次实验 compression.type 设置为 lz4。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=4096 linger.ms=50 compression.type=lz4输出结果:
16696 records sent, 3339.2 records/sec (3.26 MB/sec), 1924.5 ms avg latency, 3355.0 ms max latency.
19647 records sent, 3928.6 records/sec (3.84 MB/sec), 4841.5 ms avg latency, 6320.0 ms max latency.
20142 records sent, 4028.4 records/sec (3.93 MB/sec), 6203.2 ms avg latency, 6378.0 ms max latency.
。。。 。。。
20130 records sent, 4024.4 records/sec (3.93 MB/sec), 6073.6 ms avg latency, 6396.0 ms max latency.
19449 records sent, 3889.8 records/sec (3.80 MB/sec), 6195.6 ms avg latency, 6500.0 ms max latency.
19872 records sent, 3972.8 records/sec (3.88 MB/sec), 6274.5 ms avg latency, 6565.0 ms max latency.
1000000 records sent, 3956.087430 records/sec (3.86 MB/sec), 6085.62 ms avg latency, 6745.00 ms max latency, 6212 ms 50th, 6524 ms 95th, 6610 ms 99th, 6695 ms 99.9th.(6)调整缓存大小
默认生产者端缓存大小 32m。本次实验 buffer.memory 设置为 64m。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=4096 linger.ms=50 buffer.memory=67108864输出结果:
20170 records sent, 4034.0 records/sec (3.94 MB/sec), 1669.5 ms avg latency, 3040.0 ms max latency.
21996 records sent, 4399.2 records/sec (4.30 MB/sec), 4407.9 ms avg latency, 5806.0 ms max latency.
22113 records sent, 4422.6 records/sec (4.32 MB/sec), 7189.0 ms avg latency, 8623.0 ms max latency.
。。。 。。。
19818 records sent, 3963.6 records/sec (3.87 MB/sec), 12416.0 ms avg latency, 12847.0 ms max latency.
20331 records sent, 4062.9 records/sec (3.97 MB/sec), 12400.4 ms avg latency, 12874.0 ms max latency.
19665 records sent, 3933.0 records/sec (3.84 MB/sec), 12303.9 ms avg latency, 12838.0 ms max latency.
1000000 records sent, 4020.100503 records/sec (3.93 MB/sec), 11692.17 ms avg latency, 13796.00 ms max latency, 12238 ms 50th, 12949 ms 95th, 13691 ms 99th, 13766 ms 99.9th.5.6.3 Kafka Consumer 压力测试
(1)一次拉取条数为 500
修改/opt/module/kafka/config/consumer.properties
max.poll.records=500(2)消费 100 万条日志进行压测
[atguigu@hadoop105 kafka]$ bin/kafka-consumer-perf-test.sh --bootstrap-server hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic test --messages 1000000 --consumer.config config/consumer.properties- --bootstrap-server 指定 Kafka 集群地址
- --topic 指定 topic 的名称
- --messages 总共要消费的消息个数。本次实验 100 万条。
输出结果:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-01-20 09:58:26:171, 2022-01-20 09:58:33:321, 977.0166, 136.6457, 1000465, 139925.1748, 415, 6735, 145.0656, 148547.1418(3)一次拉取条数为 2000
输出结果:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-01-20 10:18:06:268, 2022-01-20 10:18:12:863, 977.5146, 148.2206, 1000975, 151777.8620, 358, 6237, 156.7283, 160489.8188(4)调整 fetch.max.bytes 大小为 100m
①修改/opt/module/kafka/config/consumer.properties 文件中的拉取一批数据大小 100m
fetch.max.bytes=104857600②再次执行
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-01-20 10:26:13:203, 2022-01-20 10:26:19:662, 977.5146, 151.3415, 1000975, 154973.6801, 362, 6097, 160.3272, 164175.0041六、源码环境准备
1、源码下载地址
下载地址:
Apache Kafka

2 安装jdk和scala
安装jdk和scala,配置环境变量
3 加载源码

4 安装gradle
Gradle 是类似于 maven 的代码管理工具。安卓程序管理通常采用 Gradle。
IDEA 自动帮你下载安装,下载的时间比较长(网络慢,需要 1 天时间,有 VPN 需要几分钟)。
七、生产者源码
发送流程
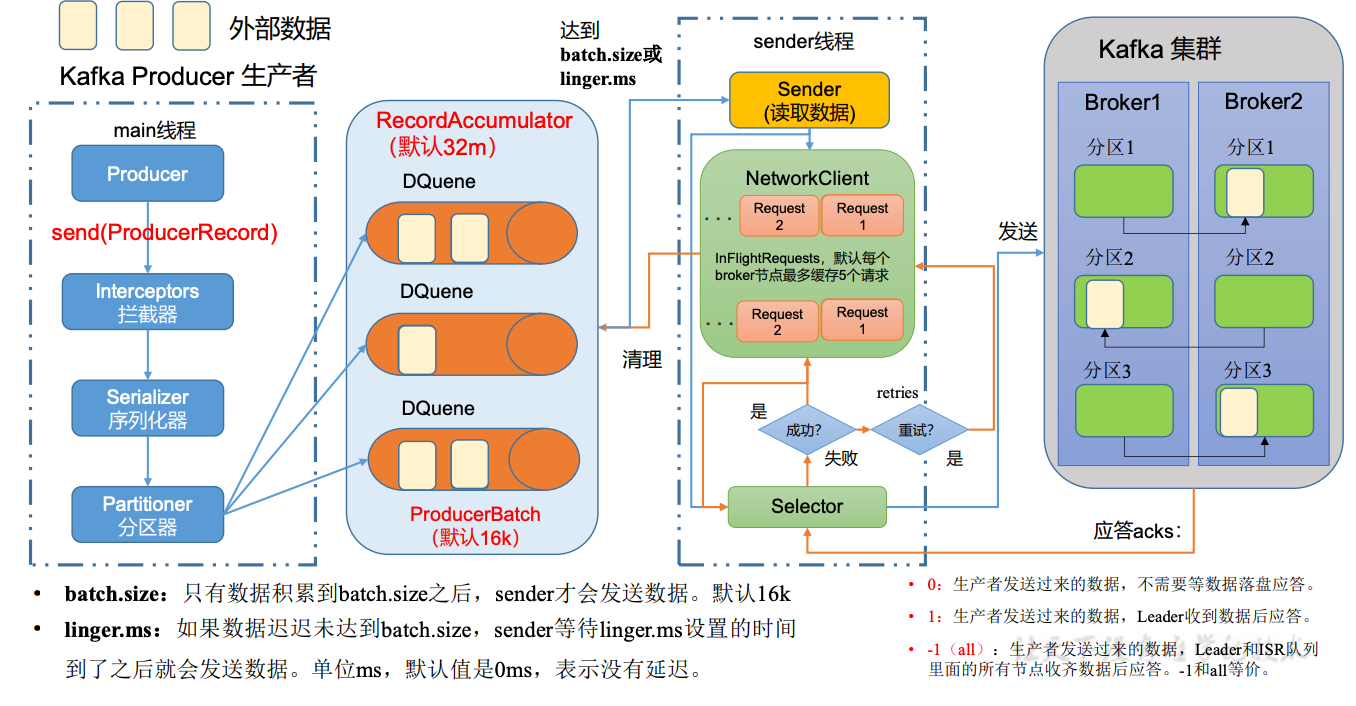
7.1 初始化
生产者main线程初始化
生产者sender线程初始化

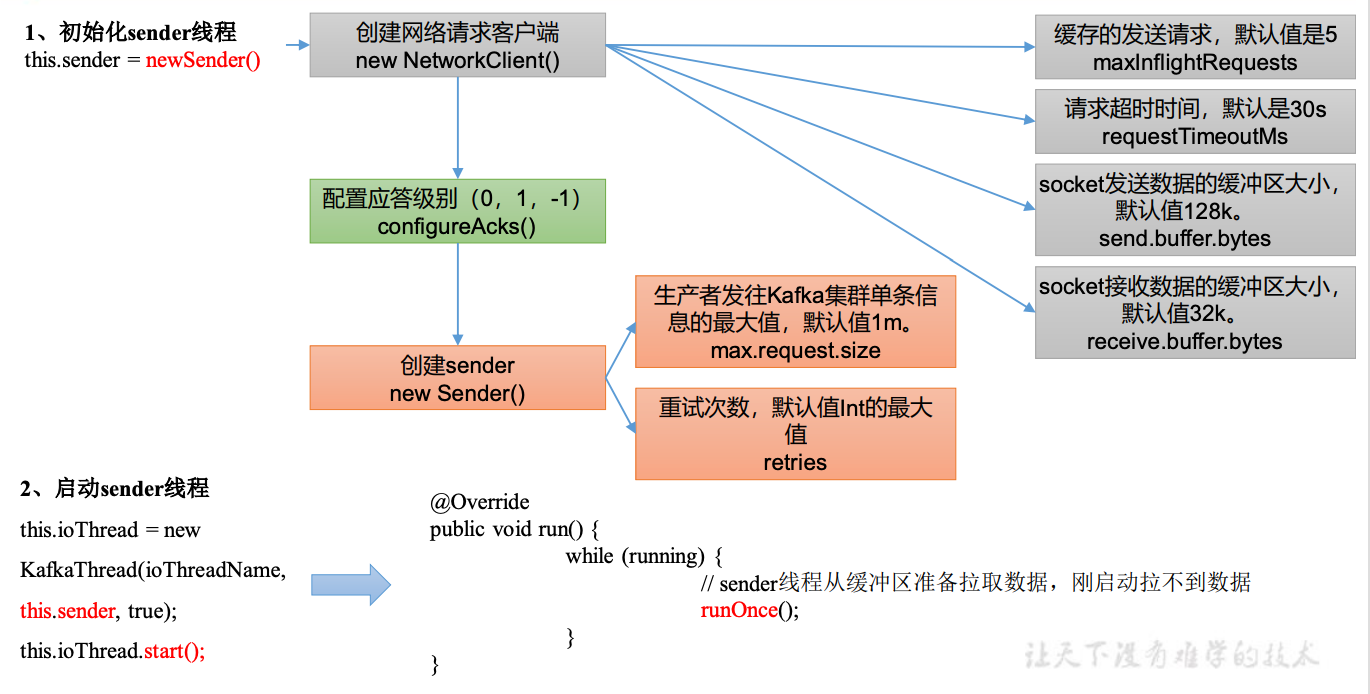
7.1.1 程序入口
1)从用户自己编写的 main 方法开始阅读
public class CustomProducer {
private final static String SERVER_CONFIG = "localhost:9092";
public static void main(String[] args) {
// 1. 创建 kafka 生产者的配置对象
Properties properties = new Properties();
// 2. 给 kafka 配置对象添加配置信息:bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, SERVER_CONFIG);
// key,value 序列化(必须):key.serializer,value.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 3. 创建 kafka 生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
// 4. 调用 send 方法,发送消息
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first", "xiang " + i));
}
// 5. 关闭资源
kafkaProducer.close();
}
}7.1.2 生产者main线程初始化
点击 main()方法中的 KafkaProducer()。
KafkaProducer.java
public KafkaProducer(final Map<String, Object> configs) {
this(configs, null, null);
}
public KafkaProducer(Map<String, Object> configs, Serializer<K> keySerializer, Serializer<V> valueSerializer) {
this(new ProducerConfig(ProducerConfig.appendSerializerToConfig(configs, keySerializer, valueSerializer)),
keySerializer, valueSerializer, null, null, null, Time.SYSTEM);
}
KafkaProducer(ProducerConfig config,
Serializer<K> keySerializer,
Serializer<V> valueSerializer,
ProducerMetadata metadata,
KafkaClient kafkaClient,
ProducerInterceptors<K, V> interceptors,
Time time) {
try {
this.producerConfig = config;
this.time = time;
// 获取事务 id
String transactionalId = config.getString(ProducerConfig.TRANSACTIONAL_ID_CONFIG);
// 获取客户端 id
this.clientId = config.getString(ProducerConfig.CLIENT_ID_CONFIG);
// logContext
LogContext logContext = transactionalId == null ? new LogContext(String.format("[Producer clientId=%s] ", clientId)) : new LogContext(String.format("[Producer clientId=%s, transactionalId=%s] ", clientId, transactionalId));
log = logContext.logger(KafkaProducer.class);
log.trace("Starting the Kafka producer");
Map<String, String> metricTags = Collections.singletonMap("client-id", clientId);
MetricConfig metricConfig = new MetricConfig().samples(config.getInt(ProducerConfig.METRICS_NUM_SAMPLES_CONFIG)).timeWindow(config.getLong(ProducerConfig.METRICS_SAMPLE_WINDOW_MS_CONFIG), TimeUnit.MILLISECONDS).recordLevel(Sensor.RecordingLevel.forName(config.getString(ProducerConfig.METRICS_RECORDING_LEVEL_CONFIG))).tags(metricTags);
List<MetricsReporter> reporters = CommonClientConfigs.metricsReporters(clientId, config);
MetricsContext metricsContext = new KafkaMetricsContext(JMX_PREFIX, config.originalsWithPrefix(CommonClientConfigs.METRICS_CONTEXT_PREFIX));
this.metrics = new Metrics(metricConfig, reporters, time, metricsContext);
this.producerMetrics = new KafkaProducerMetrics(metrics);
// 分区器配置
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class, Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId));
warnIfPartitionerDeprecated();
this.partitionerIgnoreKeys = config.getBoolean(ProducerConfig.PARTITIONER_IGNORE_KEYS_CONFIG);
// 重试时间间隔参数配置,默认值 100ms
long retryBackoffMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG);
// 序列化配置
if (keySerializer == null) {
this.keySerializer = config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, Serializer.class);
this.keySerializer.configure(config.originals(Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId)), true);
} else {
config.ignore(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG);
this.keySerializer = keySerializer;
}
if (valueSerializer == null) {
this.valueSerializer = config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, Serializer.class);
this.valueSerializer.configure(config.originals(Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId)), false);
} else {
config.ignore(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG);
this.valueSerializer = valueSerializer;
}
// 拦截器配置
List<ProducerInterceptor<K, V>> interceptorList = (List) config.getConfiguredInstances(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, ProducerInterceptor.class, Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId));
this.interceptors = interceptors != null ? interceptors : new ProducerInterceptors<>(interceptorList);
ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(this.keySerializer, this.valueSerializer, interceptorList, reporters);
// 生产者发往 Kafka 集群单条信息的最大值,默认 1m
this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);
// 缓存大小,默认 32m
this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);
// 压缩配置,默认 none
this.compressionType = CompressionType.forName(config.getString(ProducerConfig.COMPRESSION_TYPE_CONFIG));
this.maxBlockTimeMs = config.getLong(ProducerConfig.MAX_BLOCK_MS_CONFIG);
int deliveryTimeoutMs = configureDeliveryTimeout(config, log);
this.apiVersions = new ApiVersions();
this.transactionManager = configureTransactionState(config, logContext);
// There is no need to do work required for adaptive partitioning, if we use a custom partitioner.
boolean enableAdaptivePartitioning = partitioner == null && config.getBoolean(ProducerConfig.PARTITIONER_ADPATIVE_PARTITIONING_ENABLE_CONFIG);
RecordAccumulator.PartitionerConfig partitionerConfig = new RecordAccumulator.PartitionerConfig(enableAdaptivePartitioning, config.getLong(ProducerConfig.PARTITIONER_AVAILABILITY_TIMEOUT_MS_CONFIG));
// As per Kafka producer configuration documentation batch.size may be set to 0 to explicitly disable
// batching which in practice actually means using a batch size of 1.
// 上下文环境
// 批次大下,默认 16k
// 是否压缩,默认 none
// linger.ms,默认值 0。
// 重试间隔时间,默认值 100ms。
// delivery.timeout.ms 默认值 2 分钟。
// request.timeout.ms 默认值 30s
int batchSize = Math.max(1, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG));
this.accumulator = new RecordAccumulator(logContext, batchSize, this.compressionType, lingerMs(config), retryBackoffMs, deliveryTimeoutMs, partitionerConfig, metrics, PRODUCER_METRIC_GROUP_NAME, time, apiVersions, transactionManager, new BufferPool(this.totalMemorySize, batchSize, metrics, time, PRODUCER_METRIC_GROUP_NAME));
// Kafka 集群地址
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(config.getList(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG), config.getString(ProducerConfig.CLIENT_DNS_LOOKUP_CONFIG));
// 从 Kafka 集群获取元数据
if (metadata != null) {
this.metadata = metadata;
} else {
// metadata.max.age.ms 默认值 5 分钟。生产者每隔多久需要更新一下自己的元数据
// metadata.max.idle.ms 默认值 5 分钟。网络最多空闲时间设置,超过该阈值,就关闭该网络
this.metadata = new ProducerMetadata(retryBackoffMs, config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG), config.getLong(ProducerConfig.METADATA_MAX_IDLE_CONFIG), logContext, clusterResourceListeners, Time.SYSTEM);
this.metadata.bootstrap(addresses);
}
this.errors = this.metrics.sensor("errors");
// 初始化 sender 线程
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
// 启动发送线程
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics, time.milliseconds());
log.debug("Kafka producer started");
} catch (Throwable t) {
close(Duration.ofMillis(0), true);
throw new KafkaException("Failed to construct kafka producer", t);
}
}7.1.3 生产者sender线程初始化
点击 newSender()方法,查看发送线程初始化。
KafkaProducer.java
Sender newSender(LogContext logContext, KafkaClient kafkaClient, ProducerMetadata metadata) {
// 缓存的发送请求,默认值是 5。
int maxInflightRequests = producerConfig.getInt(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION);
// request.timeout.ms 默认值 30s。
int requestTimeoutMs = producerConfig.getInt(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG);
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(producerConfig, time, logContext);
ProducerMetrics metricsRegistry = new ProducerMetrics(this.metrics);
Sensor throttleTimeSensor = Sender.throttleTimeSensor(metricsRegistry.senderMetrics);
// maxInflightRequests 缓存的发送请求,默认值是 5。
// reconnect.backoff.ms 默认值 50ms。重试时间间隔
// reconnect.backoff.max.ms 默认值 1000ms。重试的总时间。每次重试失败时,呈指数增加重试时间,直至达到此最大值
send.buffer.bytes 默认值 128k。 socket 发送数据的缓冲区大小
receive.buffer.bytes 默认值 32k。socket 接收数据的缓冲区大小
request.timeout.ms 默认值 30s。
socket.connection.setup.timeout.ms 默认值 10s。生产者和服务器通
//信连接建立的时间。如果在超时之前没有建立连接,将关闭通信。
socket.connection.setup.timeout.max.ms 默认值 30s。生产者和服务
//器通信,每次连续连接失败时,连接建立超时将呈指数增加,直至达到此最大值。
KafkaClient client = kafkaClient != null ? kafkaClient : new NetworkClient(
new Selector(producerConfig.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG), this.metrics, time, "producer", channelBuilder, logContext),
metadata,
clientId,
maxInflightRequests,
producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),
producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
producerConfig.getInt(ProducerConfig.SEND_BUFFER_CONFIG),
producerConfig.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),
requestTimeoutMs,
producerConfig.getLong(ProducerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),
producerConfig.getLong(ProducerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),
time,
true,
apiVersions,
throttleTimeSensor,
logContext);
// acks 默认值是-1。
// acks=0, 生产者发送给 Kafka 服务器后,不需要应答
// acks=1,生产者发送给 Kafka 服务器后,Leader 接收后应答
// acks=-1(all),生产者发送给 Kafka 服务器后,Leader 和在 ISR 队列的所有 Follower 共同应答
short acks = Short.parseShort(producerConfig.getString(ProducerConfig.ACKS_CONFIG));
// max.request.size 默认值 1m。 生产者发往 Kafka 集群单条信息的最大值
// retries 重试次数,默认值 Int 的最大值
// retry.backoff.ms 默认值 100ms。重试时间间隔
return new Sender(logContext,
client,
metadata,
this.accumulator,
maxInflightRequests == 1,
producerConfig.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
acks,
producerConfig.getInt(ProducerConfig.RETRIES_CONFIG),
metricsRegistry.senderMetrics,
time,
requestTimeoutMs,
producerConfig.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),
this.transactionManager,
apiVersions);
}Sender 对象被放到了一个线程中启动,所有需要点击 newSender()方法中的 Sender,并找到 sender 对象中的 run()方法。
Sender.java
@Override
public void run() {
log.debug("Starting Kafka producer I/O thread.");
// main loop, runs until close is called
while (running) {
try {
runOnce();
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
...
}7.2 发送数据到缓冲区
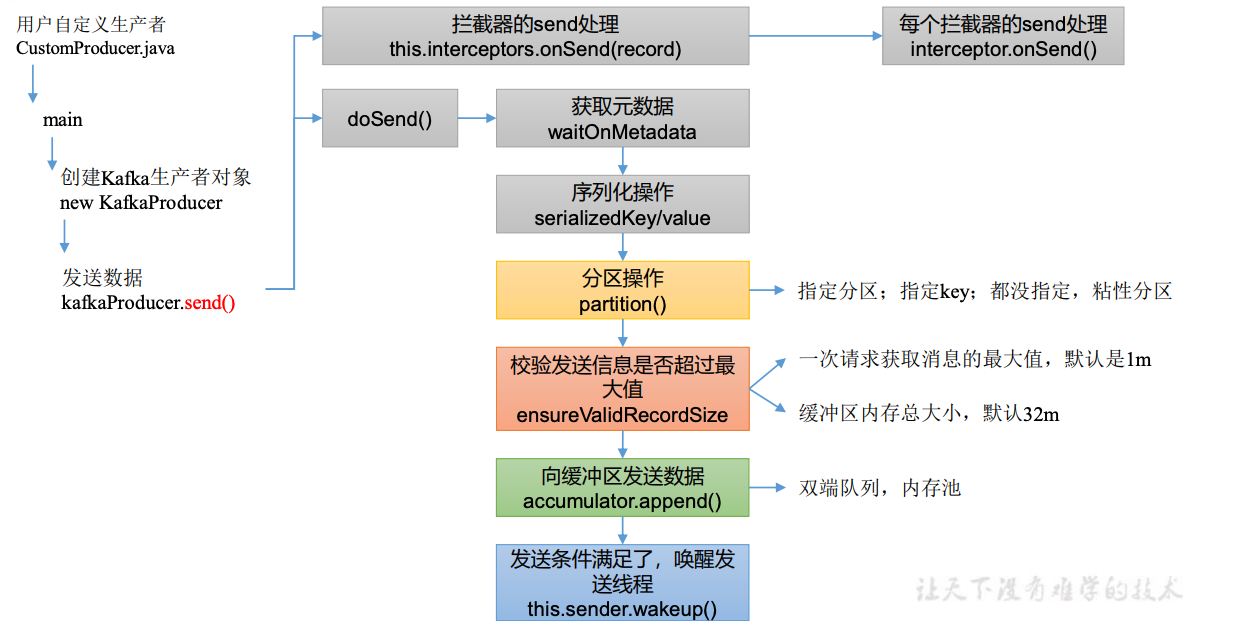
7.2.1 发送总体流程
点击自己编写的 CustomProducer.java 中的 send()方法。
// 4. 调用 send 方法,发送消息
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first", "xiang " + i));
}KafkaProducer.java
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {
return send(record, null);
}
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
// 拦截器处理发送的数据
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}点击 onSend()方法,进行拦截器相关处理。
ProducerInterceptors.java
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record) {
ProducerRecord<K, V> interceptRecord = record;
for (ProducerInterceptor<K, V> interceptor : this.interceptors) {
try {
// 拦截器处理
interceptRecord = interceptor.onSend(interceptRecord);
} catch (Exception e) {
if (record != null)
log.warn("Error executing interceptor onSend callback for topic: {}, partition: {}", record.topic(), record.partition(), e);
else
log.warn("Error executing interceptor onSend callback", e);
}
}
return interceptRecord;
}从拦截器处理中返回,点击 doSend()方法。
KafkaProducer.java
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
AppendCallbacks<K, V> appendCallbacks = new AppendCallbacks<K, V>(callback, this.interceptors, record);
try {
throwIfProducerClosed();
// first make sure the metadata for the topic is available
long nowMs = time.milliseconds();
ClusterAndWaitTime clusterAndWaitTime;
try {
// 从 Kafka 拉取元数据。maxBlockTimeMs 表示最多能等待多长时间。
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
nowMs += clusterAndWaitTime.waitedOnMetadataMs;
// 剩余时间 = 最多能等待时间 - 用了多少时间;
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
// 更新集群元数据
Cluster cluster = clusterAndWaitTime.cluster;
// 序列化操作
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() + " to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() + " specified in key.serializer", cce);
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() + " to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() + " specified in value.serializer", cce);
}
// 分区操作(根据元数据信息)
int partition = partition(record, serializedKey, serializedValue, cluster);
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(), compressionType, serializedKey, serializedValue, headers);
// 校验发送消息的大小是否超过最大值,默认是 1m
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? nowMs : record.timestamp();
// A custom partitioner may take advantage on the onNewBatch callback.
boolean abortOnNewBatch = partitioner != null;
// 内存,默认 32m,里面是默认 16k 一个批次
RecordAccumulator.RecordAppendResult result = accumulator.append(record.topic(), partition, timestamp, serializedKey, serializedValue, headers, appendCallbacks, remainingWaitMs, abortOnNewBatch, nowMs, cluster);
assert appendCallbacks.getPartition() != RecordMetadata.UNKNOWN_PARTITION;
if (result.abortForNewBatch) {
int prevPartition = partition;
onNewBatch(record.topic(), cluster, prevPartition);
partition = partition(record, serializedKey, serializedValue, cluster);
if (log.isTraceEnabled()) {
log.trace("Retrying append due to new batch creation for topic {} partition {}. The old partition was {}", record.topic(), partition, prevPartition);
}
result = accumulator.append(record.topic(), partition, timestamp, serializedKey, serializedValue, headers, appendCallbacks, remainingWaitMs, false, nowMs, cluster);
}
// Add the partition to the transaction (if in progress) after it has been successfully
// appended to the accumulator. We cannot do it before because the partition may be
// unknown or the initially selected partition may be changed when the batch is closed
// (as indicated by `abortForNewBatch`). Note that the `Sender` will refuse to dequeue
// batches from the accumulator until they have been added to the transaction.
if (transactionManager != null) {
transactionManager.maybeAddPartition(appendCallbacks.topicPartition());
}
// 批次满了 或者 创建了一个新的批次,唤醒 sender 发送线程
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), appendCallbacks.getPartition());
//唤醒 sender 发送线程
this.sender.wakeup();
}
return result.future;
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null) {
TopicPartition tp = appendCallbacks.topicPartition();
RecordMetadata nullMetadata = new RecordMetadata(tp, -1, -1, RecordBatch.NO_TIMESTAMP, -1, -1);
callback.onCompletion(nullMetadata, e);
}
this.errors.record();
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
if (transactionManager != null) {
transactionManager.maybeTransitionToErrorState(e);
}
return new FutureFailure(e);
} catch (InterruptedException e) {
this.errors.record();
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
throw new InterruptException(e);
} catch (KafkaException e) {
this.errors.record();
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
throw e;
} catch (Exception e) {
// we notify interceptor about all exceptions, since onSend is called before anything else in this method
this.interceptors.onSendError(record, appendCallbacks.topicPartition(), e);
throw e;
}
}7.2.2 分区选择
KafkaProducer.java
详解默认分区规则
int partition = partition(record, serializedKey, serializedValue,cluster);
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
// 指定了分区,那就直接用该分区号
if (record.partition() != null)
return record.partition();
if (partitioner != null) {
// 分区器选择分区
int customPartition = partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
if (customPartition < 0) {
throw new IllegalArgumentException(String.format("The partitioner generated an invalid partition number: %d. Partition number should always be non-negative.", customPartition));
}
return customPartition;
}
if (serializedKey != null && !partitionerIgnoreKeys) {
return BuiltInPartitioner.partitionForKey(serializedKey, cluster.partitionsForTopic(record.topic()).size());
} else {
return RecordMetadata.UNKNOWN_PARTITION;
}
}点击 partition,跳转到 Partitioner 接口。选中 partition,点击 ctrl+ h,查找接口实现类
int partition(String topic, Object key, byte[] keyBytes, Objectvalue, byte[] valueBytes, Cluster cluster);选择默认的分区器 DefaultPartitioner
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster, int numPartitions) {
// 没有指定 key:
if (keyBytes == null) {
return stickyPartitionCache.partition(topic, cluster);
}
// 指定 key:按照 key 的 hash 值对分区取模
// hash the keyBytes to choose a partition
return BuiltInPartitioner.partitionForKey(keyBytes, numPartitions);
}StickyPartitionCache
// 没有指定 key 和分区的处理方式
public int partition(String topic, Cluster cluster) {
Integer part = indexCache.get(topic);
if (part == null) {
return nextPartition(topic, cluster, -1);
}
return part;
}
public int nextPartition(String topic, Cluster cluster, int prevPartition) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
Integer oldPart = indexCache.get(topic);
Integer newPart = oldPart;
// Check that the current sticky partition for the topic is either not set or that the partition that
// triggered the new batch matches the sticky partition that needs to be changed.
if (oldPart == null || oldPart == prevPartition) {
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() < 1) {
Integer random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
newPart = random % partitions.size();
} else if (availablePartitions.size() == 1) {
newPart = availablePartitions.get(0).partition();
} else {
while (newPart == null || newPart.equals(oldPart)) {
int random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
newPart = availablePartitions.get(random % availablePartitions.size()).partition();
}
}
// Only change the sticky partition if it is null or prevPartition matches the current sticky partition.
if (oldPart == null) {
indexCache.putIfAbsent(topic, newPart);
} else {
indexCache.replace(topic, prevPartition, newPart);
}
return indexCache.get(topic);
}
return indexCache.get(topic);
}7.2.3 发送消息大小校验
KafkaProducer.java
详解缓冲区大小
ensureValidRecordSize(serializedSize);
private void ensureValidRecordSize(int size) {
if (size > maxRequestSize)
// 一次请求获取消息的最大值,默认是 1m
throw new RecordTooLargeException("The message is " + size + " bytes when serialized which is larger than " + maxRequestSize + ", which is the value of the " + ProducerConfig.MAX_REQUEST_SIZE_CONFIG + " configuration.");
if (size > totalMemorySize)
// 缓冲区内存总大小,默认 32m
throw new RecordTooLargeException("The message is " + size + " bytes when serialized which is larger than the total memory buffer you have configured with the " + ProducerConfig.BUFFER_MEMORY_CONFIG + " configuration.");
}7.2.4 内存池
KafkaProducer.java
RecordAccumulator.RecordAppendResult result = accumulator.append(record.topic(), partition, timestamp, serializedKey, serializedValue, headers, appendCallbacks, remainingWaitMs, abortOnNewBatch, nowMs, cluster);RecordAccumulator
public RecordAppendResult append(String topic,
int partition,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
AppendCallbacks callbacks,
long maxTimeToBlock,
boolean abortOnNewBatch,
long nowMs,
Cluster cluster) throws InterruptedException {
TopicInfo topicInfo = topicInfoMap.computeIfAbsent(topic, k -> new TopicInfo(logContext, k, batchSize));
// We keep track of the number of appending thread to make sure we do not miss batches in
// abortIncompleteBatches().
appendsInProgress.incrementAndGet();
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
// Loop to retry in case we encounter partitioner's race conditions.
while (true) {
// If the message doesn't have any partition affinity, so we pick a partition based on the broker
// availability and performance. Note, that here we peek current partition before we hold the
// deque lock, so we'll need to make sure that it's not changed while we were waiting for the
// deque lock.
final BuiltInPartitioner.StickyPartitionInfo partitionInfo;
final int effectivePartition;
if (partition == RecordMetadata.UNKNOWN_PARTITION) {
partitionInfo = topicInfo.builtInPartitioner.peekCurrentPartitionInfo(cluster);
effectivePartition = partitionInfo.partition();
} else {
partitionInfo = null;
effectivePartition = partition;
}
// Now that we know the effective partition, let the caller know.
setPartition(callbacks, effectivePartition);
// check if we have an in-progress batch
// 每个分区,创建或者获取一个队列
Deque<ProducerBatch> dq = topicInfo.batches.computeIfAbsent(effectivePartition, k -> new ArrayDeque<>());
synchronized (dq) {
// After taking the lock, validate that the partition hasn't changed and retry.
if (partitionChanged(topic, topicInfo, partitionInfo, dq, nowMs, cluster))
continue;
// 尝试向队列里面添加数据(没有分配内存、批次对象,所以失败)
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callbacks, dq, nowMs);
if (appendResult != null) {
// If queue has incomplete batches we disable switch (see comments in updatePartitionInfo).
boolean enableSwitch = allBatchesFull(dq);
topicInfo.builtInPartitioner.updatePartitionInfo(partitionInfo, appendResult.appendedBytes, cluster, enableSwitch);
return appendResult;
}
}
// we don't have an in-progress record batch try to allocate a new batch
if (abortOnNewBatch) {
return new RecordAppendResult(null, false, false, true, 0);
}
if (buffer == null) {
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
// 取批次大小(默认 16k)和消息大小的最大值(上限默认 1m)。这样设计的主要原因是有可能一条消息的大小大于批次大小。
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {} with remaining timeout {}ms", size, topic, partition, maxTimeToBlock);
// 根据批次大小(默认 16k)和消息大小中最大值,分配内存
buffer = free.allocate(size, maxTimeToBlock);
nowMs = time.milliseconds();
}
synchronized (dq) {
// After taking the lock, validate that the partition hasn't changed and retry.
if (partitionChanged(topic, topicInfo, partitionInfo, dq, nowMs, cluster))
continue;
RecordAppendResult appendResult = appendNewBatch(topic, effectivePartition, dq, timestamp, key, value, headers, callbacks, buffer, nowMs);
// Set buffer to null, so that deallocate doesn't return it back to free pool, since it's used in the batch.
if (appendResult.newBatchCreated)
buffer = null;
// If queue has incomplete batches we disable switch (see comments in updatePartitionInfo).
boolean enableSwitch = allBatchesFull(dq);
topicInfo.builtInPartitioner.updatePartitionInfo(partitionInfo, appendResult.appendedBytes, cluster, enableSwitch);
return appendResult;
}
}
} finally {
// 如果发生异常,释放内存
free.deallocate(buffer);
appendsInProgress.decrementAndGet();
}
}
private RecordAppendResult appendNewBatch(String topic,
int partition,
Deque<ProducerBatch> dq,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
AppendCallbacks callbacks,
ByteBuffer buffer,
long nowMs) {
assert partition != RecordMetadata.UNKNOWN_PARTITION;
// 尝试向队列里面添加数据(有内存,但是没有批次对象)
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callbacks, dq, nowMs);
if (appendResult != null) {
// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...
return appendResult;
}
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, apiVersions.maxUsableProduceMagic());
// 根据内存大小封装批次(有内存、有批次对象)
ProducerBatch batch = new ProducerBatch(new TopicPartition(topic, partition), recordsBuilder, nowMs);
// 尝试向队列里面添加数据
FutureRecordMetadata future = Objects.requireNonNull(batch.tryAppend(timestamp, key, value, headers, callbacks, nowMs));
// 把新创建的批次放到队列末尾
dq.addLast(batch);
incomplete.add(batch);
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true, false, batch.estimatedSizeInBytes());
}7.3 sender线程发送数据
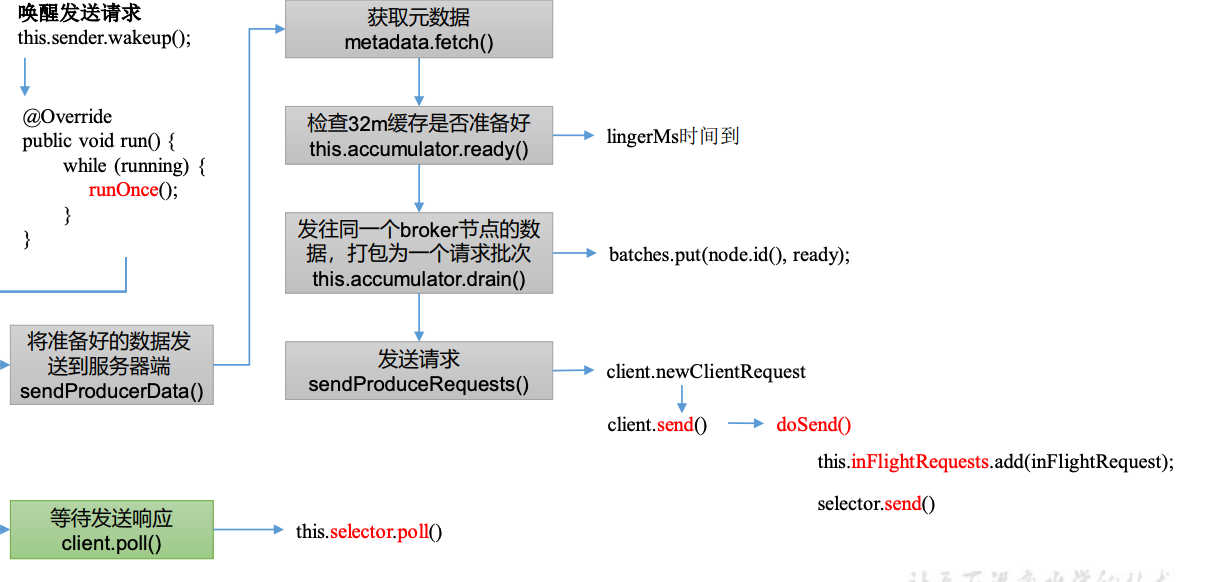
KafkaProducer.java
// 批次满了 或者 创建了一个新的批次,唤醒 sender 发送线程
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), appendCallbacks.getPartition());
//唤醒 sender 发送线程
this.sender.wakeup();
}进入 Sender 发送线程的 run()方法。
public void run() {
log.debug("Starting Kafka producer I/O thread.");
// main loop, runs until close is called
while (running) {
try {
runOnce();
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
...
}
void runOnce() {
if (transactionManager != null) {
try {
// 如果是事务操作,按照如下处理
transactionManager.maybeResolveSequences();
if (transactionManager.hasFatalError()) {
RuntimeException lastError = transactionManager.lastError();
if (lastError != null)
maybeAbortBatches(lastError);
client.poll(retryBackoffMs, time.milliseconds());
return;
}
transactionManager.bumpIdempotentEpochAndResetIdIfNeeded();
if (maybeSendAndPollTransactionalRequest()) {
return;
}
} catch (AuthenticationException e) {
// This is already logged as error, but propagated here to perform any clean ups.
log.trace("Authentication exception while processing transactional request", e);
transactionManager.authenticationFailed(e);
}
}
long currentTimeMs = time.milliseconds();
// 将准备好的数据发送到服务器端
long pollTimeout = sendProducerData(currentTimeMs);
// 等待发送响应
client.poll(pollTimeout, currentTimeMs);
}
// 获取要发送数据的细节
private long sendProducerData(long now) {
// 获取元数据
Cluster cluster = metadata.fetch();
// 1、检查 32m 缓存是否准备好(linger.ms)
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// 如果 Leader 信息不知道,是不能发送数据的
if (!result.unknownLeaderTopics.isEmpty()) {
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic, now);
log.debug("Requesting metadata update due to unknown leader topics from the batched records: {}",
result.unknownLeaderTopics);
this.metadata.requestUpdate();
}
// 删除掉没有准备好发送的数据
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
this.accumulator.updateNodeLatencyStats(node.id(), now, false);
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
} else {
// Update both readyTimeMs and drainTimeMs, this would "reset" the node
// latency.
this.accumulator.updateNodeLatencyStats(node.id(), now, true);
}
}
// 2、发往同一个 broker 节点的数据,打包为一个请求批次
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
addToInflightBatches(batches);
if (guaranteeMessageOrder) {
// Mute all the partitions drained
for (List<ProducerBatch> batchList : batches.values()) {
for (ProducerBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
accumulator.resetNextBatchExpiryTime();
List<ProducerBatch> expiredInflightBatches = getExpiredInflightBatches(now);
List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(now);
expiredBatches.addAll(expiredInflightBatches);
if (!expiredBatches.isEmpty())
log.trace("Expired {} batches in accumulator", expiredBatches.size());
for (ProducerBatch expiredBatch : expiredBatches) {
String errorMessage = "Expiring " + expiredBatch.recordCount + " record(s) for " + expiredBatch.topicPartition + ":" + (now - expiredBatch.createdMs) + " ms has passed since batch creation";
failBatch(expiredBatch, new TimeoutException(errorMessage), false);
if (transactionManager != null && expiredBatch.inRetry()) {
// This ensures that no new batches are drained until the current in flight batches are fully resolved.
transactionManager.markSequenceUnresolved(expiredBatch);
}
}
sensors.updateProduceRequestMetrics(batches);
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
pollTimeout = Math.min(pollTimeout, this.accumulator.nextExpiryTimeMs() - now);
pollTimeout = Math.max(pollTimeout, 0);
if (!result.readyNodes.isEmpty()) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
pollTimeout = 0;
}
// 3、发送请求
sendProduceRequests(batches, now);
return pollTimeout;
}八、消费者源码
消费者组初始化流程
消费者组详细消费流程

8.1 初始化
8.1.1 程序入口
1)从用户自己编写的 main 方法开始阅读
public static void main(String[] args) {
// 1. 创建 kafka 消费者配置类
Properties properties = new Properties();
// 2. 添加配置参数
// 添加连接
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, SERVER_CONFIG);
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 配置消费者组
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
// 是否自动提交 offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 1000);
//3. 创建 kafka 消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
//4. 设置消费主题 形参是列表
consumer.subscribe(Collections.singletonList("first"));
//5. 消费数据
while (true) {
// 读取消息
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
// 输出消息
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.value());
}
// 同步提交 offset
consumer.commitAsync();
}
}8.1.2 消费者初始化
跳转到 KafkaConsumer 构造方法。
public KafkaConsumer(Properties properties) {
this(properties, null, null);
}
public KafkaConsumer(Properties properties,
Deserializer<K> keyDeserializer,
Deserializer<V> valueDeserializer) {
this(Utils.propsToMap(properties), keyDeserializer, valueDeserializer);
}
public KafkaConsumer(Map<String, Object> configs,
Deserializer<K> keyDeserializer,
Deserializer<V> valueDeserializer) {
this(new ConsumerConfig(ConsumerConfig.appendDeserializerToConfig(configs, keyDeserializer, valueDeserializer)),
keyDeserializer, valueDeserializer);
}
KafkaConsumer(ConsumerConfig config, Deserializer<K> keyDeserializer, Deserializer<V> valueDeserializer) {
try {
GroupRebalanceConfig groupRebalanceConfig = new GroupRebalanceConfig(config, GroupRebalanceConfig.ProtocolType.CONSUMER);
// 获取消费者组 id 和客户端 id
this.groupId = Optional.ofNullable(groupRebalanceConfig.groupId);
this.clientId = config.getString(CommonClientConfigs.CLIENT_ID_CONFIG);
LogContext logContext;
// If group.instance.id is set, we will append it to the log context.
if (groupRebalanceConfig.groupInstanceId.isPresent()) {
logContext = new LogContext("[Consumer instanceId=" + groupRebalanceConfig.groupInstanceId.get() + ", clientId=" + clientId + ", groupId=" + groupId.orElse("null") + "] ");
} else {
logContext = new LogContext("[Consumer clientId=" + clientId + ", groupId=" + groupId.orElse("null") + "] ");
}
this.log = logContext.logger(getClass());
boolean enableAutoCommit = config.maybeOverrideEnableAutoCommit();
groupId.ifPresent(groupIdStr -> {
if (groupIdStr.isEmpty()) {
log.warn("Support for using the empty group id by consumers is deprecated and will be removed in the next major release.");
}
});
log.debug("Initializing the Kafka consumer");
// 等待服务端响应的最大等待时间,默认是 30s
this.requestTimeoutMs = config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG);
this.defaultApiTimeoutMs = config.getInt(ConsumerConfig.DEFAULT_API_TIMEOUT_MS_CONFIG);
this.time = Time.SYSTEM;
this.metrics = buildMetrics(config, time, clientId);
// 重试时间间隔
this.retryBackoffMs = config.getLong(ConsumerConfig.RETRY_BACKOFF_MS_CONFIG);
// 拦截器配置
List<ConsumerInterceptor<K, V>> interceptorList = (List) config.getConfiguredInstances(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, ConsumerInterceptor.class, Collections.singletonMap(ConsumerConfig.CLIENT_ID_CONFIG, clientId));
this.interceptors = new ConsumerInterceptors<>(interceptorList);
// key 和 value 反序列化配置
if (keyDeserializer == null) {
this.keyDeserializer = config.getConfiguredInstance(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, Deserializer.class);
this.keyDeserializer.configure(config.originals(Collections.singletonMap(ConsumerConfig.CLIENT_ID_CONFIG, clientId)), true);
} else {
config.ignore(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG);
this.keyDeserializer = keyDeserializer;
}
if (valueDeserializer == null) {
this.valueDeserializer = config.getConfiguredInstance(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, Deserializer.class);
this.valueDeserializer.configure(config.originals(Collections.singletonMap(ConsumerConfig.CLIENT_ID_CONFIG, clientId)), false);
} else {
config.ignore(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG);
this.valueDeserializer = valueDeserializer;
}
// offset 从什么位置开始消费,默认是 latest
OffsetResetStrategy offsetResetStrategy = OffsetResetStrategy.valueOf(config.getString(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG).toUpperCase(Locale.ROOT));
this.subscriptions = new SubscriptionState(logContext, offsetResetStrategy);
ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(this.keyDeserializer, this.valueDeserializer, metrics.reporters(), interceptorList);
// 获取元数据
// 配置是否可以消费系统主题数据
// 配置是否允许自动创建主题
this.metadata = new ConsumerMetadata(retryBackoffMs,
config.getLong(ConsumerConfig.METADATA_MAX_AGE_CONFIG),
!config.getBoolean(ConsumerConfig.EXCLUDE_INTERNAL_TOPICS_CONFIG),
config.getBoolean(ConsumerConfig.ALLOW_AUTO_CREATE_TOPICS_CONFIG),
subscriptions, logContext, clusterResourceListeners);
// 配置连接 Kafka 集群
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(config.getList(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG), config.getString(ConsumerConfig.CLIENT_DNS_LOOKUP_CONFIG));
this.metadata.bootstrap(addresses);
String metricGrpPrefix = "consumer";
FetchMetricsRegistry metricsRegistry = new FetchMetricsRegistry(Collections.singleton(CLIENT_ID_METRIC_TAG), metricGrpPrefix);
FetchMetricsManager fetchMetricsManager = new FetchMetricsManager(metrics, metricsRegistry);
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(config, time, logContext);
this.isolationLevel = IsolationLevel.valueOf(config.getString(ConsumerConfig.ISOLATION_LEVEL_CONFIG).toUpperCase(Locale.ROOT));
// 心跳时间,默认 3s
int heartbeatIntervalMs = config.getInt(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG);
ApiVersions apiVersions = new ApiVersions();
// 创建网络客户端
NetworkClient netClient = new NetworkClient(
new Selector(config.getLong(ConsumerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG), metrics, time, metricGrpPrefix, channelBuilder, logContext),
this.metadata,
clientId,
100, // a fixed large enough value will suffice for max in-flight requests
config.getLong(ConsumerConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getLong(ConsumerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
config.getInt(ConsumerConfig.SEND_BUFFER_CONFIG),
config.getInt(ConsumerConfig.RECEIVE_BUFFER_CONFIG),
config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG),
config.getLong(ConsumerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),
config.getLong(ConsumerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),
time,
true,
apiVersions,
fetchMetricsManager.throttleTimeSensor(),
logContext);
// 创建一个消费者客户端
this.client = new ConsumerNetworkClient(
logContext,
netClient,
metadata,
time,
retryBackoffMs,
config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG),
heartbeatIntervalMs); //Will avoid blocking an extended period of time to prevent heartbeat thread starvation
// 获取消费者分区分配策略
this.assignors = ConsumerPartitionAssignor.getAssignorInstances(
config.getList(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG),
config.originals(Collections.singletonMap(ConsumerConfig.CLIENT_ID_CONFIG, clientId))
);
// no coordinator will be constructed for the default (null) group id
// 创建消费者协调器
// 自动提交 Offset 时间间隔,默认 5s
if (!groupId.isPresent()) {
config.ignore(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG);
config.ignore(ConsumerConfig.THROW_ON_FETCH_STABLE_OFFSET_UNSUPPORTED);
this.coordinator = null;
} else {
this.coordinator = new ConsumerCoordinator(groupRebalanceConfig,
logContext,
this.client,
assignors,
this.metadata,
this.subscriptions,
metrics,
metricGrpPrefix,
this.time,
enableAutoCommit,
config.getInt(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG),
this.interceptors,
config.getBoolean(ConsumerConfig.THROW_ON_FETCH_STABLE_OFFSET_UNSUPPORTED),
config.getString(ConsumerConfig.CLIENT_RACK_CONFIG));
}
FetchConfig<K, V> fetchConfig = new FetchConfig<>(config,
this.keyDeserializer,
this.valueDeserializer,
isolationLevel);
// 抓取数据配置
// 一次抓取最小值,默认 1 个字节
// 一次抓取最大值,默认 50m
// 一次抓取最大等待时间,默认 500ms
// 每个分区抓取的最大字节数,默认 1m
// 一次 poll 拉取数据返回消息的最大条数,默认是 500 条。
// key 和 value 的反序列化
this.fetcher = new Fetcher<>(
logContext,
this.client,
this.metadata,
this.subscriptions,
fetchConfig,
fetchMetricsManager,
this.time);
this.offsetFetcher = new OffsetFetcher(logContext,
client,
metadata,
subscriptions,
time,
retryBackoffMs,
requestTimeoutMs,
isolationLevel,
apiVersions);
this.topicMetadataFetcher = new TopicMetadataFetcher(logContext, client, retryBackoffMs);
this.kafkaConsumerMetrics = new KafkaConsumerMetrics(metrics, metricGrpPrefix);
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics, time.milliseconds());
log.debug("Kafka consumer initialized");
} catch (Throwable t) {
// call close methods if internal objects are already constructed; this is to prevent resource leak. see KAFKA-2121
// we do not need to call `close` at all when `log` is null, which means no internal objects were initialized.
if (this.log != null) {
close(Duration.ZERO, true);
}
// now propagate the exception
throw new KafkaException("Failed to construct kafka consumer", t);
}
}8.2 消费者订阅主题
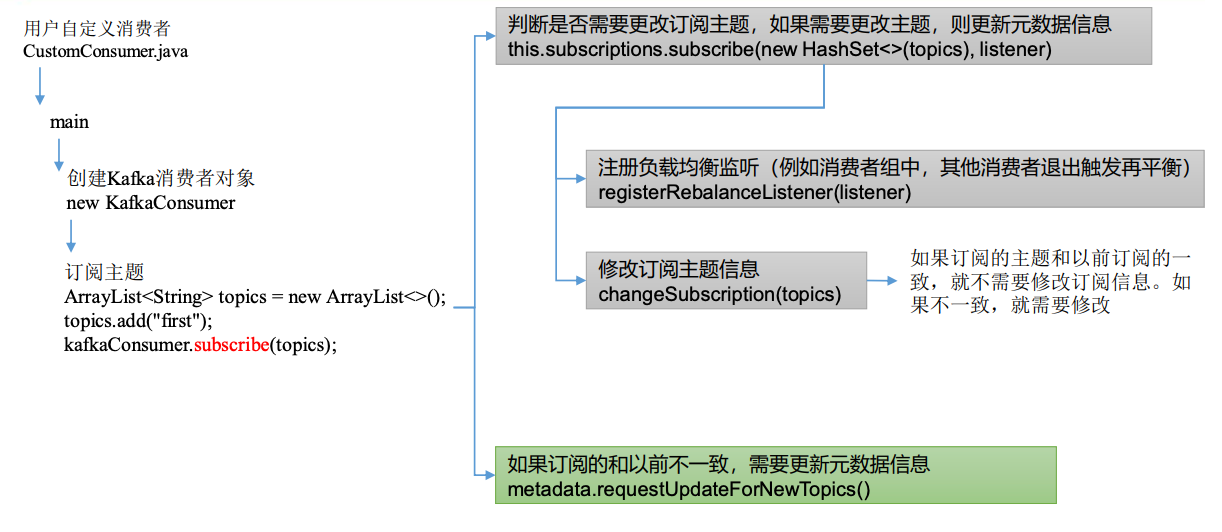
点击自己编写的 CustomConsumer.java 中的 subscribe ()方法。
KafkaConsumer.java
public void subscribe(Collection<String> topics) {
subscribe(topics, new NoOpConsumerRebalanceListener());
}
public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener) {
acquireAndEnsureOpen();
try {
maybeThrowInvalidGroupIdException();
// 异常情况处理
if (topics == null)
throw new IllegalArgumentException("Topic collection to subscribe to cannot be null");
if (topics.isEmpty()) {
// treat subscribing to empty topic list as the same as unsubscribing
this.unsubscribe();
} else {
for (String topic : topics) {
if (Utils.isBlank(topic))
throw new IllegalArgumentException("Topic collection to subscribe to cannot contain null or empty topic");
}
throwIfNoAssignorsConfigured();
// 清空订阅异常主题的缓存数据
fetcher.clearBufferedDataForUnassignedTopics(topics);
log.info("Subscribed to topic(s): {}", Utils.join(topics, ", "));
// 判断是否需要更改订阅主题,如果需要更改主题,则更新元数据信息
if (this.subscriptions.subscribe(new HashSet<>(topics), listener))
metadata.requestUpdateForNewTopics();
}
} finally {
release();
}
}SubscriptionState
public synchronized boolean subscribe(Set<String> topics, ConsumerRebalanceListener listener) {
// 注册负载均衡监听(例如消费者组中,其他消费者退出触发再平衡)
registerRebalanceListener(listener);
// 按照设置的主题开始订阅,自动分配分区
setSubscriptionType(SubscriptionType.AUTO_TOPICS);
// 修改订阅主题信息
return changeSubscription(topics);
}
private boolean changeSubscription(Set<String> topicsToSubscribe) {
// 如果订阅的主题和以前订阅的一致,就不需要修改订阅信息。如果不一致,就需要修改。
if (subscription.equals(topicsToSubscribe))
return false;
subscription = topicsToSubscribe;
return true;
}Metadata
public synchronized int requestUpdateForNewTopics() {
// Override the timestamp of last refresh to let immediate update.
this.lastRefreshMs = 0;
this.needPartialUpdate = true;
this.requestVersion++;
return this.updateVersion;
}8.3 消费者拉取和处理数据

8.3.1 消费总体流程
点击自己编写的 CustomConsumer.java 中的 poll ()方法。
KafkaConsumer.java
public ConsumerRecords<K, V> poll(final Duration timeout) {
return poll(time.timer(timeout), true);
}
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
acquireAndEnsureOpen();
try {
// 记录开始拉取消息时间
this.kafkaConsumerMetrics.recordPollStart(timer.currentTimeMs());
if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) {
throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
}
do {
client.maybeTriggerWakeup();
if (includeMetadataInTimeout) {
// 1、消费者 or 消费者组初始化
updateAssignmentMetadataIfNeeded(timer, false);
} else {
while (!updateAssignmentMetadataIfNeeded(time.timer(Long.MAX_VALUE), true)) {
log.warn("Still waiting for metadata");
}
}
// 2、开始拉取数据
final Fetch<K, V> fetch = pollForFetches(timer);
if (!fetch.isEmpty()) {
if (sendFetches() > 0 || client.hasPendingRequests()) {
client.transmitSends();
}
if (fetch.records().isEmpty()) {
log.trace("Returning empty records from `poll()` "
+ "since the consumer's position has advanced for at least one topic partition");
}
// 3、拦截器处理消息
return this.interceptors.onConsume(new ConsumerRecords<>(fetch.records()));
}
} while (timer.notExpired());
return ConsumerRecords.empty();
} finally {
release();
this.kafkaConsumerMetrics.recordPollEnd(timer.currentTimeMs());
}
}8.3.2 消费者/消费者组初始化
boolean updateAssignmentMetadataIfNeeded(final Timer timer, final boolean waitForJoinGroup) {
if (coordinator != null && !coordinator.poll(timer, waitForJoinGroup)) {
return false;
}
return updateFetchPositions(timer);
}ConsumerCoordinator
public boolean poll(Timer timer, boolean waitForJoinGroup) {
// 获取最新元数据
maybeUpdateSubscriptionMetadata();
invokeCompletedOffsetCommitCallbacks();
if (subscriptions.hasAutoAssignedPartitions()) {
if (protocol == null) {
throw new IllegalStateException("User configured " + ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG +
" to empty while trying to subscribe for group protocol to auto assign partitions");
}
// 3s 发送一次心跳
pollHeartbeat(timer.currentTimeMs());
// 保证和 Coordinator 正常通信(寻找服务器端的 coordinator)
if (coordinatorUnknownAndUnreadySync(timer)) {
return false;
}
// 判断是否需要加入消费者组
if (rejoinNeededOrPending()) {
if (subscriptions.hasPatternSubscription()) {
if (this.metadata.timeToAllowUpdate(timer.currentTimeMs()) == 0) {
this.metadata.requestUpdate();
}
if (!client.ensureFreshMetadata(timer)) {
return false;
}
maybeUpdateSubscriptionMetadata();
}
if (!ensureActiveGroup(waitForJoinGroup ? timer : time.timer(0L))) {
timer.update(time.milliseconds());
return false;
}
}
} else {
if (metadata.updateRequested() && !client.hasReadyNodes(timer.currentTimeMs())) {
client.awaitMetadataUpdate(timer);
}
client.pollNoWakeup();
}
// 是否自动提交 offset
maybeAutoCommitOffsetsAsync(timer.currentTimeMs());
return true;
}
private synchronized boolean ensureCoordinatorReady(final Timer timer, boolean disableWakeup) {
// 如果找到 coordinator,直接返回
if (!coordinatorUnknown())
return true;
// 如果没有找到,循环给服务器端发送请求,直到找到 coordinator
do {
if (fatalFindCoordinatorException != null) {
final RuntimeException fatalException = fatalFindCoordinatorException;
fatalFindCoordinatorException = null;
throw fatalException;
}
// 创建寻找 coordinator 的请求
final RequestFuture<Void> future = lookupCoordinator();
// 发送寻找 coordinator 的请求给服务器端
client.poll(future, timer, disableWakeup);
if (!future.isDone()) {
// ran out of time
break;
}
RuntimeException fatalException = null;
if (future.failed()) {
if (future.isRetriable()) {
log.debug("Coordinator discovery failed, refreshing metadata", future.exception());
client.awaitMetadataUpdate(timer);
} else {
fatalException = future.exception();
log.info("FindCoordinator request hit fatal exception", fatalException);
}
} else if (coordinator != null && client.isUnavailable(coordinator)) {
markCoordinatorUnknown("coordinator unavailable");
timer.sleep(rebalanceConfig.retryBackoffMs);
}
clearFindCoordinatorFuture();
if (fatalException != null)
throw fatalException;
} while (coordinatorUnknown() && timer.notExpired());
return !coordinatorUnknown();
}
protected synchronized RequestFuture<Void> lookupCoordinator() {
if (findCoordinatorFuture == null) {
// find a node to ask about the coordinator
Node node = this.client.leastLoadedNode();
if (node == null) {
log.debug("No broker available to send FindCoordinator request");
return RequestFuture.noBrokersAvailable();
} else {
// 向服务器端发送,查找 Coordinator 请求
findCoordinatorFuture = sendFindCoordinatorRequest(node);
}
}
return findCoordinatorFuture;
}
private RequestFuture<Void> sendFindCoordinatorRequest(Node node) {
log.debug("Sending FindCoordinator request to broker {}", node);
// 封装发送请求
FindCoordinatorRequestData data = new FindCoordinatorRequestData().setKeyType(CoordinatorType.GROUP.id()).setKey(this.rebalanceConfig.groupId);
FindCoordinatorRequest.Builder requestBuilder = new FindCoordinatorRequest.Builder(data);
// 消费者向服务器端发送请求
return client.send(node, requestBuilder).compose(new FindCoordinatorResponseHandler());
}8.3.3 拉取数据
KafkaConsumer
// 2、开始拉取数据
private Fetch<K, V> pollForFetches(Timer timer) {
long pollTimeout = coordinator == null ? timer.remainingMs() :
Math.min(coordinator.timeToNextPoll(timer.currentTimeMs()), timer.remainingMs());
// if data is available already, return it immediately
final Fetch<K, V> fetch = fetcher.collectFetch();
if (!fetch.isEmpty()) {
return fetch;
}
// 2.1 发送请求并抓取数据
sendFetches();
if (!cachedSubscriptionHasAllFetchPositions && pollTimeout > retryBackoffMs) {
pollTimeout = retryBackoffMs;
}
log.trace("Polling for fetches with timeout {}", pollTimeout);
Timer pollTimer = time.timer(pollTimeout);
client.poll(pollTimer, () -> {
return !fetcher.hasAvailableFetches();
});
timer.update(pollTimer.currentTimeMs());
// 2.2 把数据按照分区封装好后,一次处理默认 500 条数据
return fetcher.collectFetch();
}2.1 发送请求并抓取数据
Fetcher.java
public synchronized int sendFetches() {
Map<Node, FetchSessionHandler.FetchRequestData> fetchRequestMap = prepareFetchRequests();
for (Map.Entry<Node, FetchSessionHandler.FetchRequestData> entry : fetchRequestMap.entrySet()) {
final Node fetchTarget = entry.getKey();
final FetchSessionHandler.FetchRequestData data = entry.getValue();
// 初始化抓取数据的参数:
// 最大等待时间默认 500ms
// 最小抓取一个字节
// 最大抓取 50m 数据,
final FetchRequest.Builder request = createFetchRequest(fetchTarget, data);
RequestFutureListener<ClientResponse> listener = new RequestFutureListener<ClientResponse>() {
@Override
public void onSuccess(ClientResponse resp) {
synchronized (Fetcher.this) {
//拉取成功
handleFetchResponse(fetchTarget, data, resp);
}
}
@Override
public void onFailure(RuntimeException e) {
synchronized (Fetcher.this) {
handleFetchResponse(fetchTarget, e);
}
}
};
// 发送拉取数据请求
final RequestFuture<ClientResponse> future = client.send(fetchTarget, request);
future.addListener(listener);
}
return fetchRequestMap.size();
}2.2 把数据按照分区封装好后,一次处理最大条数默认 500 条数据
AbstractFetch
public Fetch<K, V> collectFetch() {
Fetch<K, V> fetch = Fetch.empty();
Queue<CompletedFetch<K, V>> pausedCompletedFetches = new ArrayDeque<>();
// 一次处理的最大条数,默认 500 条
int recordsRemaining = fetchConfig.maxPollRecords;
try {
// 循环处理
while (recordsRemaining > 0) {
if (nextInLineFetch == null || nextInLineFetch.isConsumed) {
// 从缓存中获取数据
CompletedFetch<K, V> records = completedFetches.peek();
// 缓存中数据为 null,直接跳出循环
if (records == null)
break;
if (!records.initialized) {
try {
nextInLineFetch = initializeCompletedFetch(records);
} catch (Exception e) {
if (fetch.isEmpty() && FetchResponse.recordsOrFail(records.partitionData).sizeInBytes() == 0) {
completedFetches.poll();
}
throw e;
}
} else {
nextInLineFetch = records;
}
// 从缓存中拉取数据
completedFetches.poll();
} else if (subscriptions.isPaused(nextInLineFetch.partition)) {
log.debug("Skipping fetching records for assigned partition {} because it is paused", nextInLineFetch.partition);
pausedCompletedFetches.add(nextInLineFetch);
nextInLineFetch = null;
} else {
Fetch<K, V> nextFetch = fetchRecords(recordsRemaining);
recordsRemaining -= nextFetch.numRecords();
fetch.add(nextFetch);
}
}
} catch (KafkaException e) {
if (fetch.isEmpty())
throw e;
} finally {
// add any polled completed fetches for paused partitions back to the completed fetches queue to be
// re-evaluated in the next poll
completedFetches.addAll(pausedCompletedFetches);
}
return fetch;
}8.3.4 拦截器处理数据
在 poll()方法中点击 onConsume()方法。
// 3、拦截器处理消息
// 数据从服务器端,返回后,放入集合中缓存
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
… …
// 从集合中拉取数据处理,首先经过的是拦截器
return this.interceptors.onConsume(new ConsumerRecords<>(records));ConsumerInterceptors
public ConsumerRecords<K, V> onConsume(ConsumerRecords<K, V> records) {
ConsumerRecords<K, V> interceptRecords = records;
for (ConsumerInterceptor<K, V> interceptor : this.interceptors) {
try {
interceptRecords = interceptor.onConsume(interceptRecords);
} catch (Exception e) {
// do not propagate interceptor exception, log and continue calling other interceptors
log.warn("Error executing interceptor onConsume callback", e);
}
}
return interceptRecords;
}8.4 消费者Offset提交
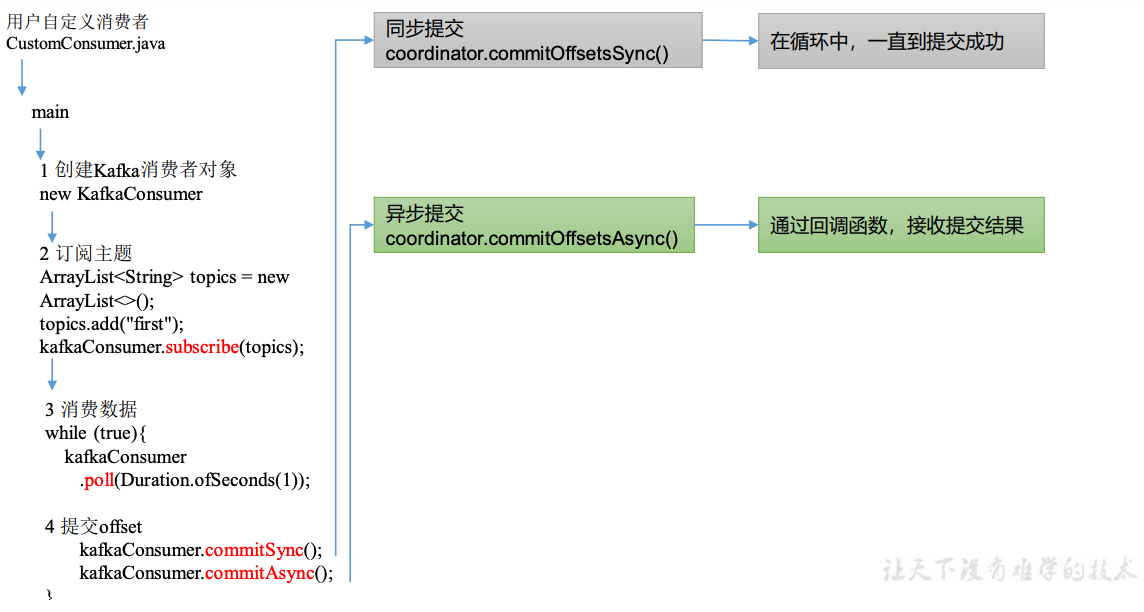
8.4.1 手动同步提交Offset
手动同步提交 Offset
CustomConsumer.java
kafkaConsumer.commitSync();KafkaConsumer.java
public void commitSync() {
commitSync(Duration.ofMillis(defaultApiTimeoutMs));
}
public void commitSync(Duration timeout) {
commitSync(subscriptions.allConsumed(), timeout);
}
public void commitSync(final Map<TopicPartition, OffsetAndMetadata> offsets, final Duration timeout) {
acquireAndEnsureOpen();
long commitStart = time.nanoseconds();
try {
maybeThrowInvalidGroupIdException();
offsets.forEach(this::updateLastSeenEpochIfNewer);
// 同步提交
if (!coordinator.commitOffsetsSync(new HashMap<>(offsets), time.timer(timeout))) {
throw new TimeoutException("Timeout of " + timeout.toMillis() + "ms expired before successfully " + "committing offsets " + offsets);
}
} finally {
kafkaConsumerMetrics.recordCommitSync(time.nanoseconds() - commitStart);
release();
}
}ConsumerCoordinator
public boolean commitOffsetsSync(Map<TopicPartition, OffsetAndMetadata> offsets, Timer timer) {
invokeCompletedOffsetCommitCallbacks();
if (offsets.isEmpty())
return true;
do {
if (coordinatorUnknownAndUnreadySync(timer)) {
return false;
}
// 发送提交请求
RequestFuture<Void> future = sendOffsetCommitRequest(offsets);
client.poll(future, timer);
invokeCompletedOffsetCommitCallbacks();
// 提交成功
if (future.succeeded()) {
if (interceptors != null)
interceptors.onCommit(offsets);
return true;
}
if (future.failed() && !future.isRetriable())
throw future.exception();
timer.sleep(rebalanceConfig.retryBackoffMs);
} while (timer.notExpired());
return false;
}8.4.2 手动异步提交Offset
手动异步提交 Offset
KafkaConsumer.java
public void commitAsync() {
commitAsync(null);
}
public void commitAsync(OffsetCommitCallback callback) {
commitAsync(subscriptions.allConsumed(), callback);
}
public void commitAsync(final Map<TopicPartition, OffsetAndMetadata> offsets, OffsetCommitCallback callback) {
acquireAndEnsureOpen();
try {
maybeThrowInvalidGroupIdException();
log.debug("Committing offsets: {}", offsets);
offsets.forEach(this::updateLastSeenEpochIfNewer);
// 提交 offset
coordinator.commitOffsetsAsync(new HashMap<>(offsets), callback);
} finally {
release();
}
}ConsumerCoordinator
public RequestFuture<Void> commitOffsetsAsync(final Map<TopicPartition, OffsetAndMetadata> offsets, final OffsetCommitCallback callback) {
invokeCompletedOffsetCommitCallbacks();
RequestFuture<Void> future = null;
if (offsets.isEmpty()) {
// No need to check coordinator if offsets is empty since commit of empty offsets is completed locally.
future = doCommitOffsetsAsync(offsets, callback);
} else if (!coordinatorUnknownAndUnreadyAsync()) {
future = doCommitOffsetsAsync(offsets, callback);
} else {
pendingAsyncCommits.incrementAndGet();
// 监听提交 offset 的结果
lookupCoordinator().addListener(new RequestFutureListener<Void>() {
@Override
public void onSuccess(Void value) {
pendingAsyncCommits.decrementAndGet();
doCommitOffsetsAsync(offsets, callback);
client.pollNoWakeup();
}
@Override
public void onFailure(RuntimeException e) {
pendingAsyncCommits.decrementAndGet();
completedOffsetCommits.add(new OffsetCommitCompletion(callback, offsets,
new RetriableCommitFailedException(e)));
}
});
}
client.pollNoWakeup();
return future;
}九、服务器源码

9.1 程序入口
Kafka.scala
def main(args: Array[String]): Unit = {
try {
// 获取参数相关信息
val serverProps = getPropsFromArgs(args)
// 配置服务
val server = buildServer(serverProps)
try {
if (!OperatingSystem.IS_WINDOWS && !Java.isIbmJdk)
new LoggingSignalHandler().register()
} catch {
case e: ReflectiveOperationException =>
warn("Failed to register optional signal handler that logs a message when the process is terminated " + s"by a signal. Reason for registration failure is: $e", e)
}
// attach shutdown handler to catch terminating signals as well as normal termination
Exit.addShutdownHook("kafka-shutdown-hook", {
try server.shutdown()
catch {
case _: Throwable =>
fatal("Halting Kafka.")
// Calling exit() can lead to deadlock as exit() can be called multiple times. Force exit.
Exit.halt(1)
}
})
// 启动服务
try server.startup()
catch {
case e: Throwable =>
// KafkaServer.startup() calls shutdown() in case of exceptions, so we invoke `exit` to set the status code
fatal("Exiting Kafka due to fatal exception during startup.", e)
Exit.exit(1)
}
server.awaitShutdown()
}
catch {
case e: Throwable =>
fatal("Exiting Kafka due to fatal exception", e)
Exit.exit(1)
}
Exit.exit(0)
}