目标检测论文总结
【RCNN系列】
RCNN
Fast RCNN
文章目录
- 目标检测论文总结
- 前言
- 一、Pipeline
- 二、模型设计
- 1.改进点
- 2.RoI pooling layer
- 3.Backbone初始化
- 4.采样策略
- 5.损失函数
- 6.其他小细节
- 三、总结
前言
一些经典论文的总结。
一、Pipeline
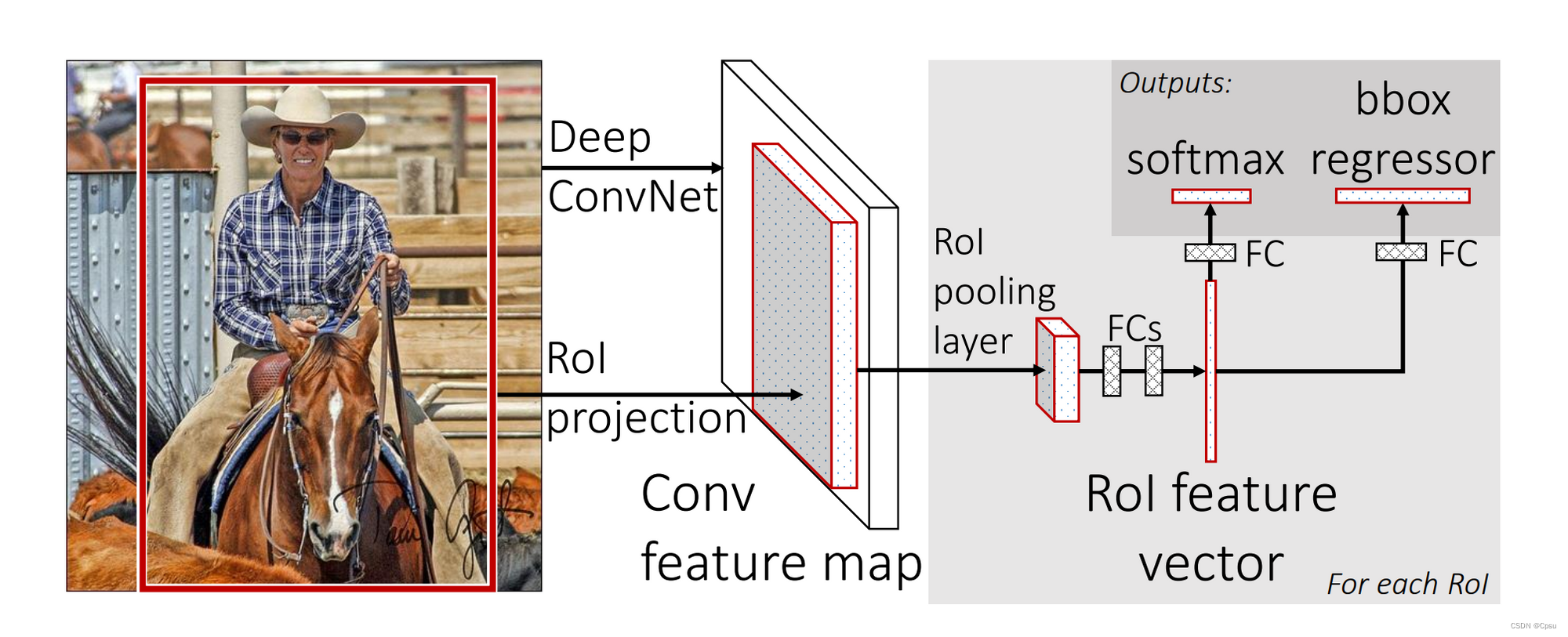
利用Selective Search(比较古老)算法取搜索Input image中可能有物体的区域(不同于RCNN不用保存本地磁盘)即region proposal。传入Input image,把整张图送进CNN得到feature map,此时将region proposa映射到feature map中,经过一个RoI pooling later后进行分类和框回归(同RCNN)。
将region proposa映射到feature map,这样就不用把每个region proposal都传入CNN了。这是Fast RCNN相比于RCNN的一个改进点。
二、模型设计
1.改进点

1.更高的mAP
2.训练是单阶段取消了SVM(注意区别one stage的检测器),使用了多任务损失
3.整个网络可以同步更新因为2
4.不需要保存本地磁盘
2.RoI pooling layer
RoI(region of interest)就是感兴趣区域也就是可能有物体的proposal。RoI是由一个长度为4的元组表示(r,c,h,w),(r,c)表示其左上角的坐标,(h,w)分别是高宽。
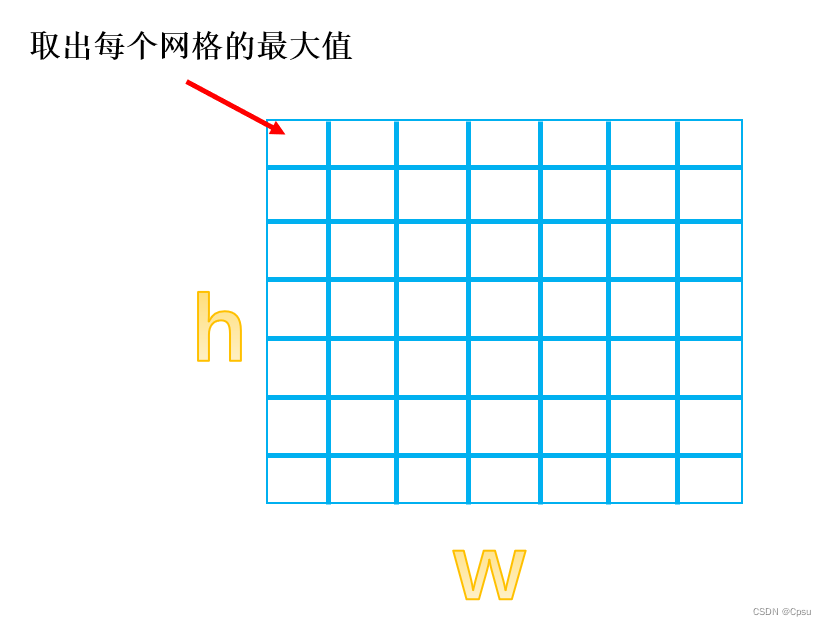
RoI pooling layer其实就是一个最大池化层。普通的池化是有步长的,但是RoI pooling是把任何一个feature map池化成固定大小H * W(比如 7*7)。原理就是将h*w 大小的RoI划分为7* 7个网格,那么每个网格的大小就是h/7 * w/7(出现小数取整)。
不管RoI原来是多大的特征图都会划分为一个7*7大小的网格,每个网格取出最大值跟最大池化层是一样的。这样就可以统一大小可以输入进后面的全连接层,不然2000多个RoI大小肯定是不一样的,如果不统一就无法输入进全连接层。
3.Backbone初始化
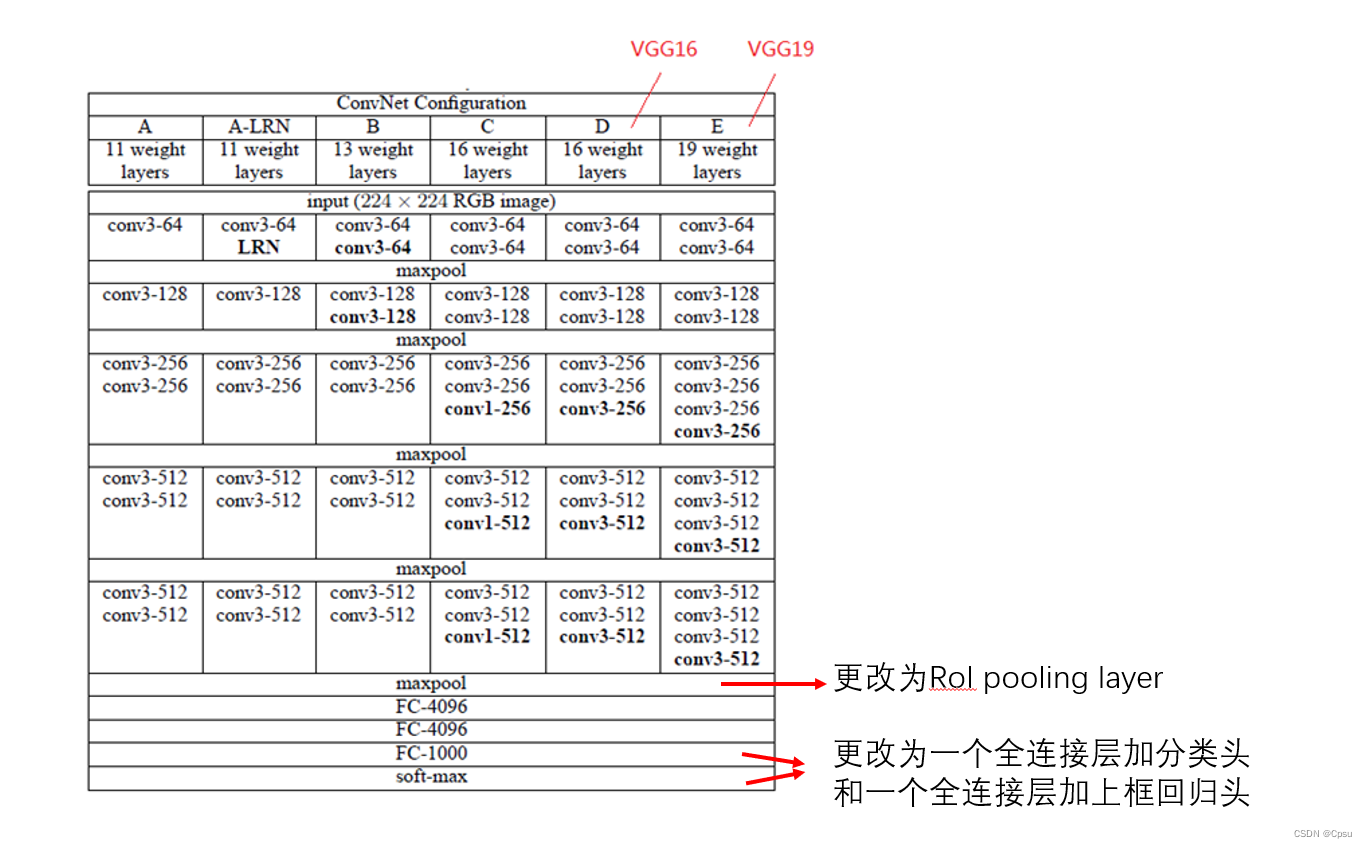
Fast RCNN的backbone是VGG,这里以VGG16为例。
1.把VGG16的最后一个池化层换成RoI pooling
2.把最后一层全连接层和softmax去掉换成两个兄弟层
3.网络的输入是input imgae和一系列的RoI
4.采样策略
Fast RCNN 的一个batch是每次输入N张图片,从每个图像中都采样R/N个RoI。比如,N=2,R=128,也就是说每次输入两张图片,然后从每张图片中采样68个RoI输入backbone。因为之前RCNN是从每张图片中采样一个RoI,也就是一个bactch是由128张图片个采样1个RoI组成,这样反向传播效率很低。
效率低的原因作者是这样解释的:

按照我理解:如果是128张图片各选一个RoI,那么就要同时计算和存储128个不同的Feature map,结合作者说的每个RoI都可能由很大的感受野,就导致每个batch的前向传播的输入会很大,所以反向传播效率低。而如果采取Fast RCNN的策略只需要N个Feature map,R/N 个RoI是共享Feature map的,每个RoI可以直接映射到Feature map上。
再来谈正负样本的选取,每次输入两张图片,然后从每张图片中采样68个RoI输入backbone。作者从与GT框的IoU大于0.5的RoI中抽取出25%(16个正样本),这些RoI被视为正样本即前景,而剩下的RoI从 IoU [0.1,0.5] 中挑选出最大的48个。IoU阈值的设定和RCNN其实是类似的
5.损失函数

6.其他小细节
1.作者也使用了多尺度训练方法,但是受GPU限制只能在小backbone上使用
2.因为Fast RCNN的全连接层很多,作者使用了奇异值分解来加速运算。
三、总结
Fast RCNN相较于RCNN的改进还是挺多的,backbone用了更深的VGG,loss用了多任务损失,pipeline也变简单了,最大的改进是得益于RoI pooling的设计(任意大小的RoI feature map可以进行最大池化),可以将region proposa映射到feature map,这样就不用把每个region proposal都传入CNN了。