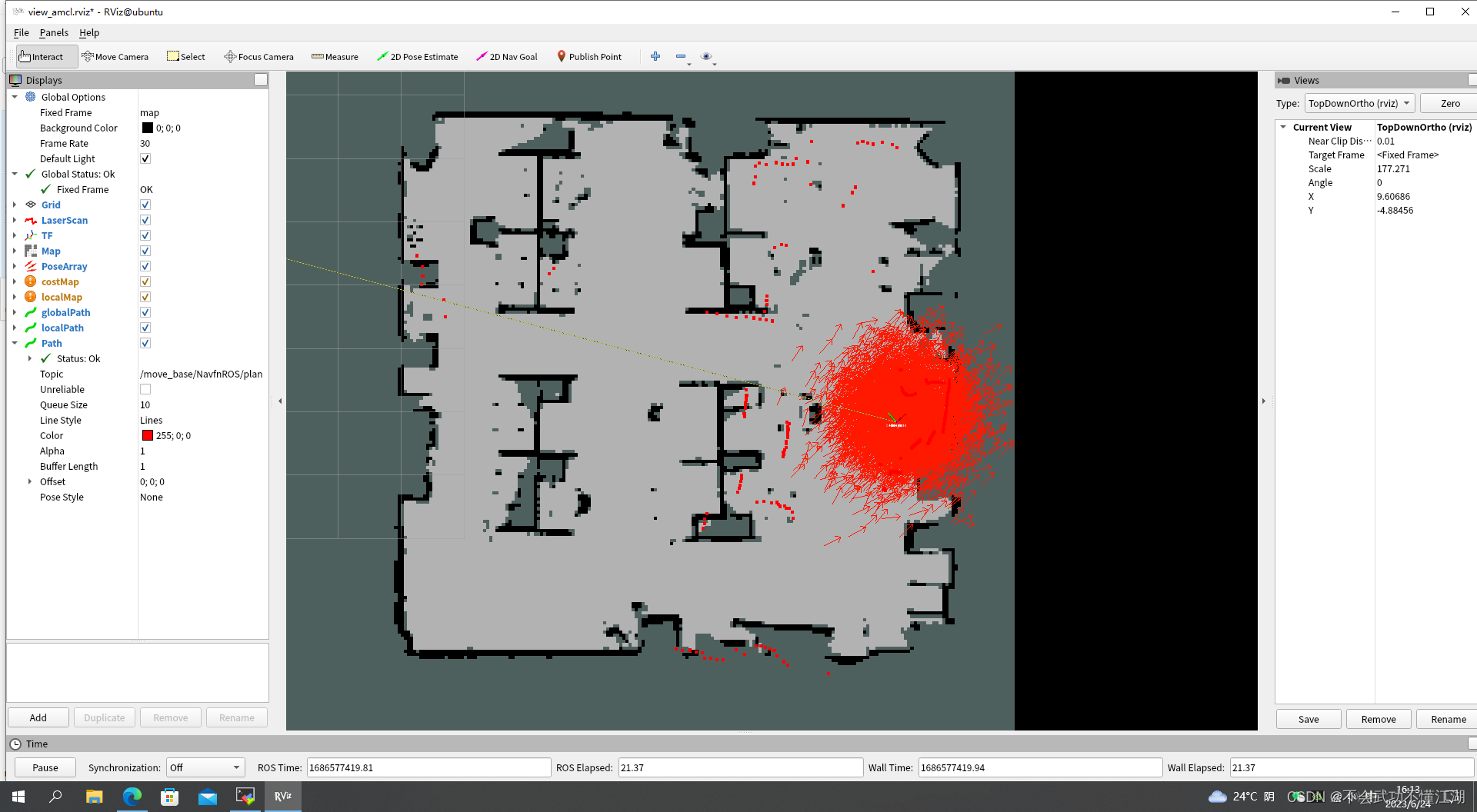
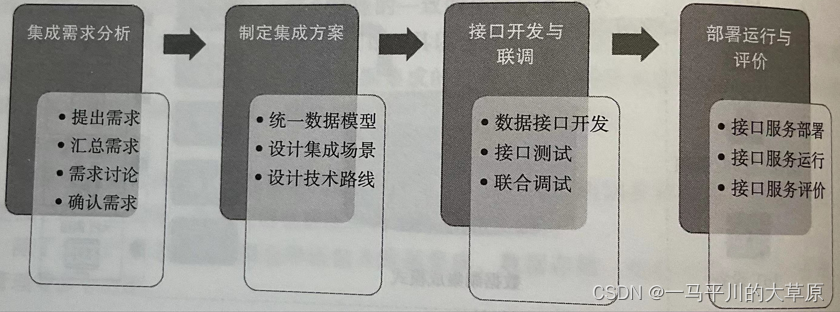
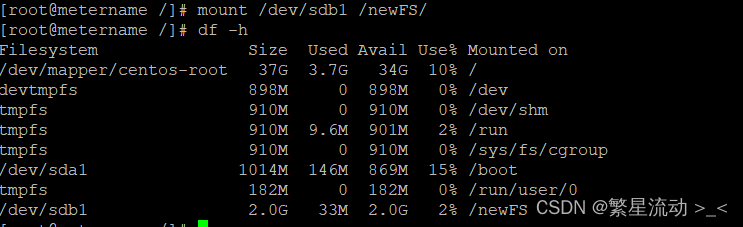
目录
一、概述
二、缺失值
1、检测缺失值
使用isna() 方法检测na_df中是否存在缺失值
使用natna() 方法
2、缺失值的处理
(1) 删除缺失值
使用删除dropna() 方法删除na_df 对象中缺失值所在的一行数据
删除全为缺失值的行
删除有缺失值的行
(2) 填充缺失值
使用fillna()方法将na_df对象中的缺失值填充为缺失值所在列的平均值
(3) 插补缺失值
使用interpolate()方法结合线性插值法对na_df对象中的缺失值进行插补
三、重复值
1、重复值的检测
使用duplicate() 方法检测重复值
2、重复值的处理
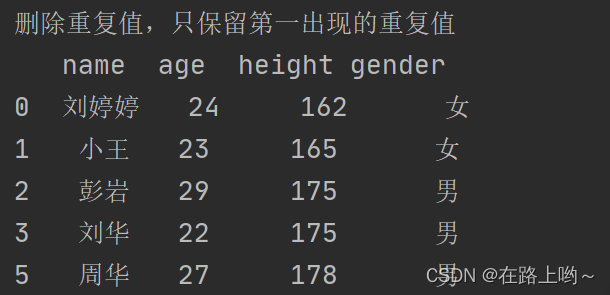
使用drop_duplicates()方法 删除重复值,只保留person_into对象中第一出现的重复值
一、概述
在数据清洗过程中,主要处理的是缺失值、异常值和重复值。
所谓清洗,是对数据集通过丢弃、填充、替换、去重等操作。达到去除异常、纠正错误、补足缺失的目的。
二、缺失值
1、检测缺失值
检测缺失值的常用方法有 :isnull() , notnull() , isna() , notna()
import pandas as pd
import numpy as np
na_df = pd.DataFrame({'A': [1, 2, np.NaN, 4],
'B': [3, 4, 4, 5],
'C': [5, 6, 7, 8],
'D': [7, 5, np.NaN, np.NaN]})
print(na_df)

使用isna() 方法检测na_df中是否存在缺失值
print('isna()方法 Ture对应着NaN所在的值')
print(na_df.isna())
使用natna() 方法
print('notna() 方法 缺失值返回False')
print(na_df.notna())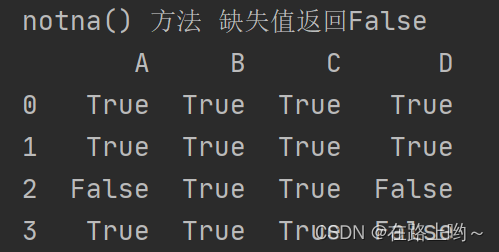
2、缺失值的处理
(1) 删除缺失值
pandas 中删除缺失值的方法dropna()
dropna()方法的语法格式
data.Frame.dropna(axis=0,how='any',thresh=None,subset=None,inplace=False)
axis:维度,axis=0表示index行,axis=1表示columns列,默认为0
how:"all"表示这一行或列中的元素全部缺失(为nan)才删除这一行或列,"any"表示这一行或列中只要有元素缺失,就删除这一行或列
thresh:保留至少出现了N个非NaN值的行或列。
subset:删除指定列的缺失值
inplace:刷选过缺失值得新数据是存为副本还是直接在原数据上进行修改。
使用删除dropna() 方法删除na_df 对象中缺失值所在的一行数据
# 默认为删除行,只要有空值就会删除,不替换
print('删除有空值的行\n',na_df.dropna())
# 保留至少3个非NaN值的行
print('保留至少3个非NaN值的行\n',na_df.dropna(thresh=3))
删除全为缺失值的行
print('删除全为缺失值的行\n',na_df.dropna(how='all'))
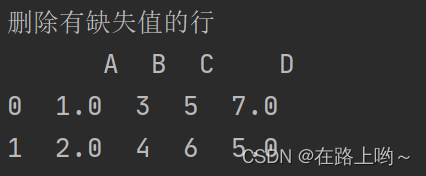
删除有缺失值的行
print('删除有缺失值的行\n',na_df.dropna(how='any'))
(2) 填充缺失值
填充缺失值的方法fillna()
函数形式: fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
value:用于填充的空值的值。
method: {'backfill', 'bfill', 'pad', 'ffill', None}, default None。定义了填充空值的方法,pad / ffill表示用前面行/列的值,填充当前行/列的空值, backfill / bfill表示用后面行/列的值,填充当前行/列的空值。
axis:轴。0或'index',表示按行删除;1或'columns',表示按列删除。
inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
limit:连续填充的最大数量
downcast:dict, default is None,字典中的项为,为类型向下转换规则。或者为字符串“infer”,此时会在合适的等价类型之间进行向下转换,比如float64 to int64 if possible。
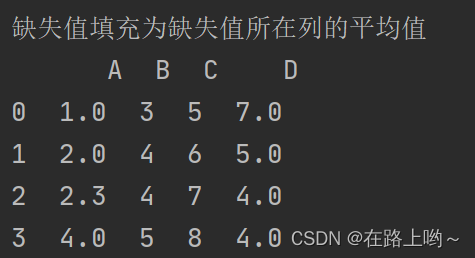
使用fillna()方法将na_df对象中的缺失值填充为缺失值所在列的平均值
# 计算A列的平均数,并保留一位小数
col_a = np.around(np.mean(na_df['A']),1)
# 计算D列的平均数,并保留一位小数
col_d =np.around(np.mean(na_df['B']),1)
# 将计算的平均值填充到指定的列
print('缺失值填充为缺失值所在列的平均值\n',na_df.fillna({'A':col_a,'D':col_d}))
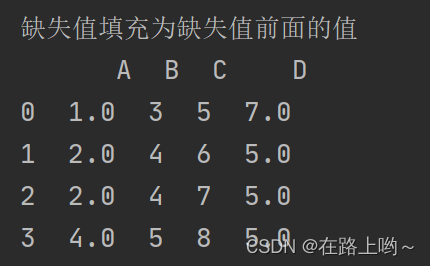
print('缺失值填充为缺失值前面的值\n',na_df.fillna(method='ffill'))
(3) 插补缺失值
插补缺失值的方法 interpolate()
DataFrame.interpolate(method='linear',axis=0,limit=None,inplase=False,limit_direction=None,limit_area=None,**kwargs) """
1、method:表示使用的插值方法。 该参数支持 'linear'( 默认值 )、'time'、'index'、'values'、 'nearest'、'barycentric'共 6 种取值,
其中 'linear'代表采用线性插值法进行填充;'time代表根据时间长短进行填充,适用于索引为日期时间的对象;'index'和'values'代表采用索引的实际数值进行填充;'nearest'代表采用最邻近插值法进行填充;'barycentric'代表采用重心坐标插值法进行填充。
2、limit:表示连续填充的最大数量。
3、limit_direction:表示按照指定方向对连续的 NaN 值进行填充。该参数常用的取值为"forward'、'backforward' 和 'both',其中' forward'代表向前填充;'backforward'代表向后填充:'both'代表同时向前、向后填充。
使用interpolate()方法结合线性插值法对na_df对象中的缺失值进行插补
print('\n使用interpolate()方法结合线性插值法对缺失值进行插补\n',na_df.interpolate(method='linear'))

三、重复值
import pandas as pd
person_info=pd.DataFrame({'name':['刘婷婷','小王','彭岩','刘华','刘华','周华'],
'age':[24,23,29,22,22,27],
'height':[162,165,175,175,175,178],
'gender':['女','女','男','男','男','男']})
print(person_info)
1、重复值的检测
duplicated()方法
DataFrame.dulicated(subset=None,keep='first')
subset 表示采用重复项的列索引或列索引的序列,默认标识所有的列索引
keep 表示哪种方式保留重复项。 ‘first’(默认值)删除重复值,只留第一个, ‘last’ 只留最后 ,‘False’ 重复项全删
使用duplicate() 方法检测重复值
print('检测重复值\n',person_info.duplicated())
2、重复值的处理
drop_duplicates()方法
DataFrame.dulicated(subset=None,keep='first',inplace=False,ignore_index=False)
subset 同上
keep 同上
ignore_index 表示是否对删除重复值后的对象的行索引重新排序,默认为False
使用drop_duplicates()方法 删除重复值,只保留person_into对象中第一出现的重复值
print('删除重复值,只保留第一出现的重复值\n',person_info.drop_duplicates())