HDFS 写流程源码分析
- 一、客户端
- (一)文件创建及Pipeline构建阶段
- (二)数据写入
- (三)输出流关闭
- 二、服务端
环境为hadoop 3.1.3
一、客户端
以下代码创建并写入文件。
public void create() throws URISyntaxException, IOException, InterruptedException {
// 配置文件
Configuration conf = new Configuration();
// 获取文件系统
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.157.128:9000"), conf, "root");
// 创建文件并写入数据
FSDataOutputStream out = fs.create(new Path("/root/test3.txt"));
out.write("Hello, HDFS".getBytes());
out.flush();
// 关闭流
fs.close();
}
Configuration加载了hadoop的配置信息,下为其静态代码块,可以看到眼熟的配置文件名称。
static{
//print deprecation warning if hadoop-site.xml is found in classpath
ClassLoader cL = Thread.currentThread().getContextClassLoader();
if (cL == null) {
cL = Configuration.class.getClassLoader();
}
if(cL.getResource("hadoop-site.xml")!=null) {
LOG.warn("DEPRECATED: hadoop-site.xml found in the classpath. " +
"Usage of hadoop-site.xml is deprecated. Instead use core-site.xml, "
+ "mapred-site.xml and hdfs-site.xml to override properties of " +
"core-default.xml, mapred-default.xml and hdfs-default.xml " +
"respectively");
}
addDefaultResource("core-default.xml");
addDefaultResource("core-site.xml");
}
FileSystem是Hadoop文件系统的抽象类,有许多实现(如下图),hdfs便是其分布式文件系统的具体实现。
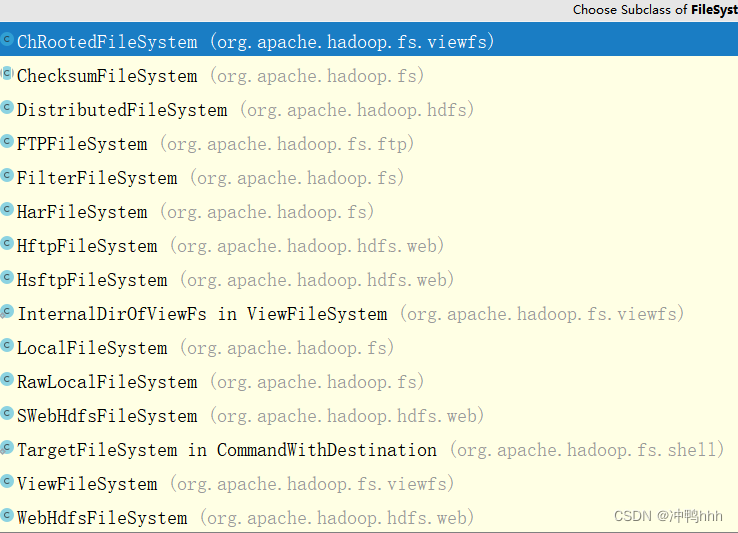
这里我们关注的为DistributedFileSystem。
(一)文件创建及Pipeline构建阶段
FSDataOutputStream out = fs.create(new Path("/root/test3.txt"));
上面一行代码用于创建/root/test3.txt文件,并获取该文件的输出流。经过多次跳转,定向到DistributedFileSystem的create方法。
public FSDataOutputStream create(final Path f, final FsPermission permission,
final EnumSet<CreateFlag> cflags, final int bufferSize,
final short replication, final long blockSize, final Progressable progress,
final ChecksumOpt checksumOpt) throws IOException {
statistics.incrementWriteOps(1); // metric
Path absF = fixRelativePart(f); // 获取绝对路径
return new FileSystemLinkResolver<FSDataOutputStream>() {
@Override
public FSDataOutputStream doCall(final Path p)
throws IOException, UnresolvedLinkException {
/*
* 主要工作:
* 1、向NameNode进行create方法的rpc调用,创建文件
* 2、启动DataStreamer,用于后续的数据传输
*/
final DFSOutputStream dfsos = dfs.create(getPathName(p), permission,
cflags, replication, blockSize, progress, bufferSize,
checksumOpt);
return dfs.createWrappedOutputStream(dfsos, statistics); // 封装返回HdfsDataOutputStream
}
// 异常重试
@Override
public FSDataOutputStream next(final FileSystem fs, final Path p)
throws IOException {
return fs.create(p, permission, cflags, bufferSize,
replication, blockSize, progress, checksumOpt);
}
}.resolve(this, absF);
}
DFSClient的create方法主要做了两件事,一是向NameNode进行create方法的rpc调用,创建文件,二是启动DataStreamer,用于后续的数据传输。
public DFSOutputStream create(String src,
FsPermission permission,
EnumSet<CreateFlag> flag,
boolean createParent,
short replication,
long blockSize,
Progressable progress,
int buffersize,
ChecksumOpt checksumOpt,
InetSocketAddress[] favoredNodes) throws IOException {
// 检查客户端状态
checkOpen();
// 封装权限信息(rw-r--r--)
if (permission == null) {
permission = FsPermission.getFileDefault();
}
FsPermission masked = permission.applyUMask(dfsClientConf.uMask);
if(LOG.isDebugEnabled()) {
LOG.debug(src + ": masked=" + masked);
}
// 更优先选择作为DataNode的节点
String[] favoredNodeStrs = null;
if (favoredNodes != null) {
favoredNodeStrs = new String[favoredNodes.length];
for (int i = 0; i < favoredNodes.length; i++) {
favoredNodeStrs[i] =
favoredNodes[i].getHostName() + ":"
+ favoredNodes[i].getPort();
}
}
/*
* 1、create的rpc调用
* 2、DataStreamer启动
*/
final DFSOutputStream result = DFSOutputStream.newStreamForCreate(this,
src, masked, flag, createParent, replication, blockSize, progress,
buffersize, dfsClientConf.createChecksum(checksumOpt),
favoredNodeStrs);
// lease
beginFileLease(result.getFileId(), result);
return result;
}
这里我们着重关注DFSOutputStream.newStreamForCreate()方法。
static DFSOutputStream newStreamForCreate(DFSClient dfsClient, String src,
FsPermission masked, EnumSet<CreateFlag> flag, boolean createParent,
short replication, long blockSize, Progressable progress, int buffersize,
DataChecksum checksum, String[] favoredNodes) throws IOException {
HdfsFileStatus stat = null;
// Retry the create if we get a RetryStartFileException up to a maximum
// number of times
boolean shouldRetry = true;
int retryCount = CREATE_RETRY_COUNT;
while (shouldRetry) {
shouldRetry = false;
try {
// rpc调用
stat = dfsClient.namenode.create(src, masked, dfsClient.clientName,
new EnumSetWritable<CreateFlag>(flag), createParent, replication,
blockSize, SUPPORTED_CRYPTO_VERSIONS);
break;
} catch (RemoteException re) {
IOException e = re.unwrapRemoteException(
AccessControlException.class,
DSQuotaExceededException.class,
FileAlreadyExistsException.class,
FileNotFoundException.class,
ParentNotDirectoryException.class,
NSQuotaExceededException.class,
RetryStartFileException.class,
SafeModeException.class,
UnresolvedPathException.class,
SnapshotAccessControlException.class,
UnknownCryptoProtocolVersionException.class);
if (e instanceof RetryStartFileException) {
if (retryCount > 0) {
shouldRetry = true;
retryCount--;
} else {
throw new IOException("Too many retries because of encryption" +
" zone operations", e);
}
} else {
throw e;
}
}
}
Preconditions.checkNotNull(stat, "HdfsFileStatus should not be null!");
final DFSOutputStream out = new DFSOutputStream(dfsClient, src, stat,
flag, progress, checksum, favoredNodes);
// 启动DataStreamer
out.start();
return out;
}
首先进行了create方法的rpc调用。然后我们着重关注DFSOutputStream.start()。
private synchronized void start() {
streamer.start();
}
开启了DataStreamer线程用于向DataNode发送数据,所以我们着重关注DataStreamer.run()。
public void run() {
long lastPacket = Time.now();
TraceScope traceScope = null;
if (traceSpan != null) {
traceScope = Trace.continueSpan(traceSpan);
}
while (!streamerClosed && dfsClient.clientRunning) {
// if the Responder encountered an error, shutdown Responder
if (hasError && response != null) {
try {
// ResponseProcessor,用于处理下游DataNode的响应
response.close();
response.join();
response = null;
} catch (InterruptedException e) {
DFSClient.LOG.warn("Caught exception ", e);
}
}
Packet one;
try {
// process datanode IO errors if any
boolean doSleep = false;
if (hasError && (errorIndex >= 0 || restartingNodeIndex >= 0)) {
doSleep = processDatanodeError();
}
// dataQueue中装的是Packet(Block(128MB) -> Packet(64KB) -> Chunk(512B数据 + 4B校验))
// Block:数据存储单元; Packet:数据传输单元; Chunk:校验单元
synchronized (dataQueue) {
// wait for a packet to be sent.
long now = Time.now();
while ((!streamerClosed && !hasError && dfsClient.clientRunning
&& dataQueue.size() == 0 &&
(stage != BlockConstructionStage.DATA_STREAMING || // 状态为DATA_STREAMING表示链接已建立,正在传输数据
stage == BlockConstructionStage.DATA_STREAMING &&
now - lastPacket < dfsClient.getConf().socketTimeout/2)) || doSleep ) {
long timeout = dfsClient.getConf().socketTimeout/2 - (now-lastPacket);
timeout = timeout <= 0 ? 1000 : timeout;
timeout = (stage == BlockConstructionStage.DATA_STREAMING)?
timeout : 1000;
try {
dataQueue.wait(timeout); // 等待唤醒(Packet填充完毕,dataQueue不为空了)
} catch (InterruptedException e) {
DFSClient.LOG.warn("Caught exception ", e);
}
doSleep = false;
now = Time.now();
}
if (streamerClosed || hasError || !dfsClient.clientRunning) {
continue;
}
// get packet to be sent.
if (dataQueue.isEmpty()) {
// 心跳包
one = createHeartbeatPacket();
} else {
one = dataQueue.getFirst(); // regular data packet
}
}
assert one != null;
// get new block from namenode.
if (stage == BlockConstructionStage.PIPELINE_SETUP_CREATE) {
if(DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("Allocating new block");
}
/*
* 主要工作:
* nextBlockOutputStream()
* 1、向NameNode发送addBlock的rpc请求,新建block加入文件,分配并返回存储该block的DataNode
* 2、向第一个DataNode建立连接(链式复制)
* setPipeline()
* 3、记录参与链式复制的节点及相关信息
*/
setPipeline(nextBlockOutputStream());
// 启动ResponseProcessor(接收Pipeline中第一个DataNode的ack),更改输出流状态为DATA_STREAMING
initDataStreaming();
} else if (stage == BlockConstructionStage.PIPELINE_SETUP_APPEND) {
if(DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("Append to block " + block);
}
setupPipelineForAppendOrRecovery();
initDataStreaming();
}
// 最后一个Packet超出了Block限制
long lastByteOffsetInBlock = one.getLastByteOffsetBlock();
if (lastByteOffsetInBlock > blockSize) {
throw new IOException("BlockSize " + blockSize +
" is smaller than data size. " +
" Offset of packet in block " +
lastByteOffsetInBlock +
" Aborting file " + src);
}
// 发送Block的最后一个Packet之前,先等待其它Packet都已经被DataNode接收
// 保证一个block被完整地接收(然后调用complete()方法的rpc),防止跨block的Packet同时等待ack
if (one.lastPacketInBlock) {
// wait for all data packets have been successfully acked
synchronized (dataQueue) {
while (!streamerClosed && !hasError &&
ackQueue.size() != 0 && dfsClient.clientRunning) {
try {
// wait for acks to arrive from datanodes
dataQueue.wait(1000);
} catch (InterruptedException e) {
DFSClient.LOG.warn("Caught exception ", e);
}
}
}
if (streamerClosed || hasError || !dfsClient.clientRunning) {
continue;
}
//
// 输出流置为关闭状态
// 因为后续block所存储的DataNode可能与这个block不同,所以pipeline也没啥用了,直接关闭就行
stage = BlockConstructionStage.PIPELINE_CLOSE;
}
// send the packet
synchronized (dataQueue) {
// move packet from dataQueue to ackQueue
// 如果不是心跳包,就将该包从待发送队列(dataQueue)移到待响应队列(ackQueue),等待DataNode响应
if (!one.isHeartbeatPacket()) {
dataQueue.removeFirst();
ackQueue.addLast(one);
dataQueue.notifyAll();
}
}
if (DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("DataStreamer block " + block +
" sending packet " + one);
}
// write out data to remote datanode
try {
// 向DataNode发送Packet
one.writeTo(blockStream);
blockStream.flush();
} catch (IOException e) {
// HDFS-3398 treat primary DN is down since client is unable to
// write to primary DN. If a failed or restarting node has already
// been recorded by the responder, the following call will have no
// effect. Pipeline recovery can handle only one node error at a
// time. If the primary node fails again during the recovery, it
// will be taken out then.
tryMarkPrimaryDatanodeFailed();
throw e;
}
lastPacket = Time.now();
// update bytesSent
// 更新已发送的数据在block中的偏移量
long tmpBytesSent = one.getLastByteOffsetBlock();
if (bytesSent < tmpBytesSent) {
bytesSent = tmpBytesSent;
}
if (streamerClosed || hasError || !dfsClient.clientRunning) {
continue;
}
// Is this block full?
// 如果刚才发送的Packet是block中的最后一个,持续等待,直到该Packet已被ack,
// 此时该block的所有Packet都已经被ack了(因为只有前面所有的包都被ack了,最后一个包才会发出去)
if (one.lastPacketInBlock) {
// wait for the close packet has been acked
synchronized (dataQueue) {
while (!streamerClosed && !hasError &&
ackQueue.size() != 0 && dfsClient.clientRunning) {
dataQueue.wait(1000);// wait for acks to arrive from datanodes
}
}
if (streamerClosed || hasError || !dfsClient.clientRunning) {
continue;
}
/*
* 1、停止ResponseProcessor
* 2、关闭输出流
* 3、pipeline重置
* 4、输出流状态置为PIPELINE_SETUP_CREATE,等待下一个block传输时再次建立连接
*/
endBlock();
}
if (progress != null) { progress.progress(); }
// This is used by unit test to trigger race conditions.
if (artificialSlowdown != 0 && dfsClient.clientRunning) {
Thread.sleep(artificialSlowdown);
}
} catch (Throwable e) {
// Log warning if there was a real error.
if (restartingNodeIndex == -1) {
DFSClient.LOG.warn("DataStreamer Exception", e);
}
if (e instanceof IOException) {
setLastException((IOException)e);
} else {
setLastException(new IOException("DataStreamer Exception: ",e));
}
hasError = true;
if (errorIndex == -1 && restartingNodeIndex == -1) {
// Not a datanode issue
streamerClosed = true;
}
}
}
if (traceScope != null) {
traceScope.close();
}
// 释放先前没能释放成功的资源
closeInternal();
}
这里我们主要关注建立连接的nextBlockOutputStream()方法和启动ResponseProcessor的initDataStreaming()方法。
private LocatedBlock nextBlockOutputStream() throws IOException {
LocatedBlock lb = null;
DatanodeInfo[] nodes = null;
StorageType[] storageTypes = null;
int count = dfsClient.getConf().nBlockWriteRetry;
boolean success = false;
ExtendedBlock oldBlock = block;
do {
hasError = false;
lastException.set(null);
errorIndex = -1;
success = false;
long startTime = Time.now();
// 不会被选作用于存储该block的DataNode
DatanodeInfo[] excluded =
excludedNodes.getAllPresent(excludedNodes.asMap().keySet())
.keySet()
.toArray(new DatanodeInfo[0]);
block = oldBlock;
/* 发送addBlock方法的rpc请求给NameNode,以:
* 1、创建block并加入该文件
* 2、选择存储该block的DataNode并排序,返回(lb)
*/
lb = locateFollowingBlock(startTime,
excluded.length > 0 ? excluded : null);
block = lb.getBlock();
block.setNumBytes(0);
bytesSent = 0;
accessToken = lb.getBlockToken();
nodes = lb.getLocations();
storageTypes = lb.getStorageTypes();
//
// Connect to first DataNode in the list.
//
// 连接链中第一个DataNode
success = createBlockOutputStream(nodes, storageTypes, 0L, false);
if (!success) {
DFSClient.LOG.info("Abandoning " + block);
dfsClient.namenode.abandonBlock(block, fileId, src,
dfsClient.clientName);
block = null;
DFSClient.LOG.info("Excluding datanode " + nodes[errorIndex]);
/*
* 这里需要注意一下,如果建立连接失败,会将连接不上的DataNode加到excludedNodes中,
* 下次调用addBlock时附带,以避免分配客户端连接不上的DataNode给该块
*/
excludedNodes.put(nodes[errorIndex], nodes[errorIndex]);
}
} while (!success && --count >= 0);
if (!success) {
throw new IOException("Unable to create new block.");
}
return lb;
}
nextBlockOutputStream()方法向NameNode申请了新块,并获取该块的存储节点链,并与链中第一个DataNode建立连接。这里我们关注createBlockOutputStream()方法。
private boolean createBlockOutputStream(DatanodeInfo[] nodes,
StorageType[] nodeStorageTypes, long newGS, boolean recoveryFlag) {
if (nodes.length == 0) {
DFSClient.LOG.info("nodes are empty for write pipeline of block "
+ block);
return false;
}
Status pipelineStatus = SUCCESS;
String firstBadLink = "";
boolean checkRestart = false;
if (DFSClient.LOG.isDebugEnabled()) {
for (int i = 0; i < nodes.length; i++) {
DFSClient.LOG.debug("pipeline = " + nodes[i]);
}
}
// persist blocks on namenode on next flush
persistBlocks.set(true);
int refetchEncryptionKey = 1;
while (true) {
boolean result = false;
DataOutputStream out = null;
try {
assert null == s : "Previous socket unclosed";
assert null == blockReplyStream : "Previous blockReplyStream unclosed";
// 建立socket连接
s = createSocketForPipeline(nodes[0], nodes.length, dfsClient);
long writeTimeout = dfsClient.getDatanodeWriteTimeout(nodes.length);
OutputStream unbufOut = NetUtils.getOutputStream(s, writeTimeout);
InputStream unbufIn = NetUtils.getInputStream(s);
IOStreamPair saslStreams = dfsClient.saslClient.socketSend(s,
unbufOut, unbufIn, dfsClient, accessToken, nodes[0]);
unbufOut = saslStreams.out;
unbufIn = saslStreams.in;
out = new DataOutputStream(new BufferedOutputStream(unbufOut,
HdfsConstants.SMALL_BUFFER_SIZE));
blockReplyStream = new DataInputStream(unbufIn);
//
// Xmit header info to datanode
//
BlockConstructionStage bcs = recoveryFlag? stage.getRecoveryStage(): stage;
// We cannot change the block length in 'block' as it counts the number
// of bytes ack'ed.
ExtendedBlock blockCopy = new ExtendedBlock(block);
blockCopy.setNumBytes(blockSize);
// send the request
// 发送请求,建立连接(WRITE_BLOCK类型)
new Sender(out).writeBlock(blockCopy, nodeStorageTypes[0], accessToken,
dfsClient.clientName, nodes, nodeStorageTypes, null, bcs,
nodes.length, block.getNumBytes(), bytesSent, newGS,
checksum4WriteBlock, cachingStrategy.get(), isLazyPersistFile);
// receive ack for connect
// 收到ack
BlockOpResponseProto resp = BlockOpResponseProto.parseFrom(
PBHelper.vintPrefixed(blockReplyStream));
pipelineStatus = resp.getStatus();
firstBadLink = resp.getFirstBadLink();
// Got an restart OOB ack.
// If a node is already restarting, this status is not likely from
// the same node. If it is from a different node, it is not
// from the local datanode. Thus it is safe to treat this as a
// regular node error.
if (PipelineAck.isRestartOOBStatus(pipelineStatus) &&
restartingNodeIndex == -1) {
checkRestart = true;
throw new IOException("A datanode is restarting.");
}
if (pipelineStatus != SUCCESS) {
if (pipelineStatus == Status.ERROR_ACCESS_TOKEN) {
throw new InvalidBlockTokenException(
"Got access token error for connect ack with firstBadLink as "
+ firstBadLink);
} else {
throw new IOException("Bad connect ack with firstBadLink as "
+ firstBadLink);
}
}
assert null == blockStream : "Previous blockStream unclosed";
blockStream = out;
result = true; // success
restartingNodeIndex = -1;
hasError = false;
} catch (IOException ie) {
if (restartingNodeIndex == -1) {
DFSClient.LOG.info("Exception in createBlockOutputStream", ie);
}
if (ie instanceof InvalidEncryptionKeyException && refetchEncryptionKey > 0) {
DFSClient.LOG.info("Will fetch a new encryption key and retry, "
+ "encryption key was invalid when connecting to "
+ nodes[0] + " : " + ie);
// The encryption key used is invalid.
refetchEncryptionKey--;
dfsClient.clearDataEncryptionKey();
// Don't close the socket/exclude this node just yet. Try again with
// a new encryption key.
continue;
}
// find the datanode that matches
if (firstBadLink.length() != 0) {
for (int i = 0; i < nodes.length; i++) {
// NB: Unconditionally using the xfer addr w/o hostname
if (firstBadLink.equals(nodes[i].getXferAddr())) {
errorIndex = i;
break;
}
}
} else {
assert checkRestart == false;
errorIndex = 0;
}
// Check whether there is a restart worth waiting for.
if (checkRestart && shouldWaitForRestart(errorIndex)) {
restartDeadline = dfsClient.getConf().datanodeRestartTimeout +
Time.now();
restartingNodeIndex = errorIndex;
errorIndex = -1;
DFSClient.LOG.info("Waiting for the datanode to be restarted: " +
nodes[restartingNodeIndex]);
}
hasError = true;
setLastException(ie);
result = false; // error
} finally {
if (!result) {
IOUtils.closeSocket(s);
s = null;
IOUtils.closeStream(out);
out = null;
IOUtils.closeStream(blockReplyStream);
blockReplyStream = null;
}
}
return result;
}
}
NameNode收到连接请求后,会为该block创建一个DataXceiver,这个后面到NameNode端会讲。然后回到initDataStreaming()方法。
private void initDataStreaming() {
this.setName("DataStreamer for file " + src +
" block " + block);
// 初始化ResponseProcessor(需要从哪些DataNode收取ack)
response = new ResponseProcessor(nodes);
// 启动ResponseProcessor
response.start();
// 将输出流状态置为DATA_STREAMING
stage = BlockConstructionStage.DATA_STREAMING;
}
该方法主要是启动ResponseProcessor线程用于收取DataNode的ack,所以我们主要关注ResponseProcessor.run()方法。
public void run() {
setName("ResponseProcessor for block " + block);
// 用于反序列化ack消息
PipelineAck ack = new PipelineAck();
while (!responderClosed && dfsClient.clientRunning && !isLastPacketInBlock) {
// process responses from datanodes.
try {
// read an ack from the pipeline
long begin = Time.monotonicNow();
// 反序列化ack消息
ack.readFields(blockReplyStream);
long duration = Time.monotonicNow() - begin;
if (duration > dfsclientSlowLogThresholdMs
&& ack.getSeqno() != Packet.HEART_BEAT_SEQNO) {
DFSClient.LOG
.warn("Slow ReadProcessor read fields took " + duration
+ "ms (threshold=" + dfsclientSlowLogThresholdMs + "ms); ack: "
+ ack + ", targets: " + Arrays.asList(targets));
} else if (DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("DFSClient " + ack);
}
// 获取请求序号
long seqno = ack.getSeqno();
// processes response status from datanodes.
// 由于hdfs采用链式复制,所以链中第一个节点的ack消息会聚合所有链中节点的ack
// 这里一一校验是否有DataNode复制失败
for (int i = ack.getNumOfReplies()-1; i >=0 && dfsClient.clientRunning; i--) {
final Status reply = ack.getReply(i);
// Restart will not be treated differently unless it is
// the local node or the only one in the pipeline.
if (PipelineAck.isRestartOOBStatus(reply) &&
shouldWaitForRestart(i)) {
restartDeadline = dfsClient.getConf().datanodeRestartTimeout +
Time.now();
setRestartingNodeIndex(i);
String message = "A datanode is restarting: " + targets[i];
DFSClient.LOG.info(message);
throw new IOException(message);
}
// node error
if (reply != SUCCESS) {
setErrorIndex(i); // first bad datanode
throw new IOException("Bad response " + reply +
" for block " + block +
" from datanode " +
targets[i]);
}
}
assert seqno != PipelineAck.UNKOWN_SEQNO :
"Ack for unknown seqno should be a failed ack: " + ack;
if (seqno == Packet.HEART_BEAT_SEQNO) { // a heartbeat ack
continue;
}
// a success ack for a data packet
Packet one;
synchronized (dataQueue) {
one = ackQueue.getFirst();
}
/*
* 每个block由单线程的DataStreamer负责传输,在DataNode中也由对应的单线程DataXceiver进行处理,
* 由于提供的通信链路能保证FIFO,所以序列号应该能对上,消息不会乱序到达
*/
if (one.seqno != seqno) {
throw new IOException("ResponseProcessor: Expecting seqno " +
" for block " + block +
one.seqno + " but received " + seqno);
}
isLastPacketInBlock = one.lastPacketInBlock;
// Fail the packet write for testing in order to force a
// pipeline recovery.
if (DFSClientFaultInjector.get().failPacket() &&
isLastPacketInBlock) {
failPacket = true;
throw new IOException(
"Failing the last packet for testing.");
}
// update bytesAcked
block.setNumBytes(one.getLastByteOffsetBlock());
// ack队列移除该Packet,唤醒dataQueue
synchronized (dataQueue) {
lastAckedSeqno = seqno;
ackQueue.removeFirst();
dataQueue.notifyAll();
one.releaseBuffer(byteArrayManager);
}
} catch (Exception e) {
if (!responderClosed) {
if (e instanceof IOException) {
setLastException((IOException)e);
}
hasError = true;
// If no explicit error report was received, mark the primary
// node as failed.
tryMarkPrimaryDatanodeFailed();
synchronized (dataQueue) {
dataQueue.notifyAll();
}
if (restartingNodeIndex == -1) {
DFSClient.LOG.warn("DFSOutputStream ResponseProcessor exception "
+ " for block " + block, e);
}
responderClosed = true;
}
}
}
}
(二)数据写入
out.write("Hello, HDFS".getBytes());
首先进入FilterOutputStream.write()。
public void write(byte b[]) throws IOException {
write(b, 0, b.length);
}
然后进入DataOutputStream.write()。
public synchronized void write(byte b[], int off, int len)
throws IOException
{
out.write(b, off, len);
incCount(len);
}
进入FSDataOutputStream.write()。
public void write(byte b[], int off, int len) throws IOException {
out.write(b, off, len);
position += len; // update position
if (statistics != null) {
statistics.incrementBytesWritten(len);
}
}
进入FSOutputSummer.write()。
public synchronized void write(byte b[], int off, int len)
throws IOException {
checkClosed();
if (off < 0 || len < 0 || off > b.length - len) {
throw new ArrayIndexOutOfBoundsException();
}
for (int n=0;n<len;n+=write1(b, off+n, len-n)) { // 注意这个write1()
}
}
进入FSOutputSummer.write1()。
private int write1(byte b[], int off, int len) throws IOException {
if(count==0 && len>=buf.length) {
// local buffer is empty and user buffer size >= local buffer size, so
// simply checksum the user buffer and send it directly to the underlying
// stream
// 如果buffer是空的,而且待写入数据大小大于buffer大小,直接生成校验和并写chunk
final int length = buf.length;
writeChecksumChunks(b, off, length);
return length;
}
// copy user data to local buffer
// 如果buffer不为空,首先计算buffer剩余大小,
// 并填充对应长度的数据进入buffer
int bytesToCopy = buf.length-count;
bytesToCopy = (len<bytesToCopy) ? len : bytesToCopy;
System.arraycopy(b, off, buf, count, bytesToCopy);
count += bytesToCopy;
if (count == buf.length) {
// local buffer is full
// buffer满了,flush
flushBuffer();
}
return bytesToCopy;
}
该方法用于写chunk,关键方法是writeChecksumChunks(),flushBuffer()中该方法也为关键方法。
private void writeChecksumChunks(byte b[], int off, int len)
throws IOException {
// 计算校验和
sum.calculateChunkedSums(b, off, len, checksum, 0);
// sum.getBytesPerChecksum()一般为512B
for (int i = 0; i < len; i += sum.getBytesPerChecksum()) {
// 该chunk的长度
int chunkLen = Math.min(sum.getBytesPerChecksum(), len - i);
// 校验和的偏移量,CRC32C中,校验和的长度为4B
// 校验和和chunk数据在Packet中是分开存的,所以可以靠此偏移量找到校验和应填充的位置
int ckOffset = i / sum.getBytesPerChecksum() * getChecksumSize();
// 写chunk
writeChunk(b, off + i, chunkLen, checksum, ckOffset, getChecksumSize());
}
}
关键关注writeChunk()。
protected synchronized void writeChunk(byte[] b, int offset, int len,
byte[] checksum, int ckoff, int cklen) throws IOException {
dfsClient.checkOpen();
checkClosed();
if (len > bytesPerChecksum) {
throw new IOException("writeChunk() buffer size is " + len +
" is larger than supported bytesPerChecksum " +
bytesPerChecksum);
}
if (cklen != 0 && cklen != getChecksumSize()) {
throw new IOException("writeChunk() checksum size is supposed to be " +
getChecksumSize() + " but found to be " + cklen);
}
// 如果当前Packet为空,就创建Packet
if (currentPacket == null) {
// packetSize为65532(64K),chunksPerPacket为127(一个Packet有127个chunk)
currentPacket = createPacket(packetSize, chunksPerPacket,
bytesCurBlock, currentSeqno++);
if (DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("DFSClient writeChunk allocating new packet seqno=" +
currentPacket.seqno +
", src=" + src +
", packetSize=" + packetSize +
", chunksPerPacket=" + chunksPerPacket +
", bytesCurBlock=" + bytesCurBlock);
}
}
// 写校验和(checksum的范围是33 ~ 33 + 4 * 127),4 * 127为校验和大小 * chunk数量
currentPacket.writeChecksum(checksum, ckoff, cklen);
// 写chunk数据(chunk数据的范围是33 + 4 * 127 ~ 65532)
currentPacket.writeData(b, offset, len);
currentPacket.numChunks++;
bytesCurBlock += len;
// If packet is full, enqueue it for transmission
// 如果Packet或者block满了,将现在的Packet加入dataQueue
if (currentPacket.numChunks == currentPacket.maxChunks ||
bytesCurBlock == blockSize) {
if (DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("DFSClient writeChunk packet full seqno=" +
currentPacket.seqno +
", src=" + src +
", bytesCurBlock=" + bytesCurBlock +
", blockSize=" + blockSize +
", appendChunk=" + appendChunk);
}
// 将Packet加入dataQueue
waitAndQueueCurrentPacket();
// If the reopened file did not end at chunk boundary and the above
// write filled up its partial chunk. Tell the summer to generate full
// crc chunks from now on.
if (appendChunk && bytesCurBlock%bytesPerChecksum == 0) {
appendChunk = false;
resetChecksumBufSize();
}
if (!appendChunk) {
int psize = Math.min((int)(blockSize-bytesCurBlock), dfsClient.getConf().writePacketSize);
computePacketChunkSize(psize, bytesPerChecksum);
}
//
// if encountering a block boundary, send an empty packet to
// indicate the end of block and reset bytesCurBlock.
//
if (bytesCurBlock == blockSize) {
currentPacket = createPacket(0, 0, bytesCurBlock, currentSeqno++);
currentPacket.lastPacketInBlock = true;
currentPacket.syncBlock = shouldSyncBlock;
waitAndQueueCurrentPacket();
bytesCurBlock = 0;
lastFlushOffset = 0;
}
}
}
着重关注waitAndQueueCurrentPacket()。
private void waitAndQueueCurrentPacket() throws IOException {
synchronized (dataQueue) {
try {
// If queue is full, then wait till we have enough space
while (!closed && dataQueue.size() + ackQueue.size() > dfsClient.getConf().writeMaxPackets) {
try {
dataQueue.wait();
} catch (InterruptedException e) {
// If we get interrupted while waiting to queue data, we still need to get rid
// of the current packet. This is because we have an invariant that if
// currentPacket gets full, it will get queued before the next writeChunk.
//
// Rather than wait around for space in the queue, we should instead try to
// return to the caller as soon as possible, even though we slightly overrun
// the MAX_PACKETS length.
Thread.currentThread().interrupt();
break;
}
}
checkClosed();
// 将当前Packet加入dataQueue
queueCurrentPacket();
} catch (ClosedChannelException e) {
}
}
}
继续看queueCurrentPacket()。
private void queueCurrentPacket() {
synchronized (dataQueue) {
if (currentPacket == null) return;
// 当前Packet加入dataQueue
dataQueue.addLast(currentPacket);
lastQueuedSeqno = currentPacket.seqno;
if (DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("Queued packet " + currentPacket.seqno);
}
currentPacket = null;
dataQueue.notifyAll();
}
}
至此传输流程已通。
(三)输出流关闭
fs.close();
最后,在输出流关闭之后(DistributedFileSystem.close()中关闭输出流),会进行complete()远程调用,用于通知NameNode完成一个block。首先看DFSOutputStream.close()。
public synchronized void close() throws IOException {
if (closed) {
IOException e = lastException.getAndSet(null);
if (e == null)
return;
else
throw e;
}
try {
flushBuffer(); // flush from all upper layers
if (currentPacket != null) {
waitAndQueueCurrentPacket();
}
if (bytesCurBlock != 0) {
// send an empty packet to mark the end of the block
currentPacket = createPacket(0, 0, bytesCurBlock, currentSeqno++);
currentPacket.lastPacketInBlock = true;
currentPacket.syncBlock = shouldSyncBlock;
}
flushInternal(); // flush all data to Datanodes
// get last block before destroying the streamer
ExtendedBlock lastBlock = streamer.getBlock();
closeThreads(false);
// complete() rpc调用
completeFile(lastBlock);
dfsClient.endFileLease(fileId);
} catch (ClosedChannelException e) {
} finally {
closed = true;
}
}
该方法释放所有与该输出流关联的资源,比如把还没传输完的chunk传输完、停止DataStreamer和ResponseProcessor线程等。着重关注completeFile()。
private void completeFile(ExtendedBlock last) throws IOException {
long localstart = Time.now();
long localTimeout = 400;
boolean fileComplete = false;
int retries = dfsClient.getConf().nBlockWriteLocateFollowingRetry;
while (!fileComplete) {
// complete() rpc
fileComplete =
dfsClient.namenode.complete(src, dfsClient.clientName, last, fileId);
if (!fileComplete) {
final int hdfsTimeout = dfsClient.getHdfsTimeout();
if (!dfsClient.clientRunning ||
(hdfsTimeout > 0 && localstart + hdfsTimeout < Time.now())) {
String msg = "Unable to close file because dfsclient " +
" was unable to contact the HDFS servers." +
" clientRunning " + dfsClient.clientRunning +
" hdfsTimeout " + hdfsTimeout;
DFSClient.LOG.info(msg);
throw new IOException(msg);
}
try {
if (retries == 0) {
throw new IOException("Unable to close file because the last block"
+ " does not have enough number of replicas.");
}
retries--;
Thread.sleep(localTimeout);
localTimeout *= 2;
if (Time.now() - localstart > 5000) {
DFSClient.LOG.info("Could not complete " + src + " retrying...");
}
} catch (InterruptedException ie) {
DFSClient.LOG.warn("Caught exception ", ie);
}
}
}
}
需要注意,这里只需要对文件的最后一个block进行complete(),因为在addBlock的时候,会尝试complete该文件之前未complete的block,由于block是顺序提交的,既然已经申请了下一个block,那之前的block应该都已经完成了最小副本数的存储。
二、服务端
HDFS写流程源码分析(二)-服务端