引言:
现在是北京时间2023年6月23日13点19分,度过了一个非常愉快的端午节。由于刚从学校回家,一下子伙食强度直升了个两三个档次。这也导致我的肠胃不堪重负,我也准备等会去健身房消耗一下盈余的热量。回到家陪伴爷爷走人生最后的阶段才是我这个暑假最重要的事情。自从爷爷病重后,起居都需要家人照顾,我不仅感慨岁月夺人呐。兴许五六十年后,子孙也能够在我人生最后的阶段陪伴我吧。

排序的概念
所谓排序,就是使一组数据,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。在日常生活中处处都有排序,比如学校的考试中会有对成绩进行排序、当我们购物时会有对销量或价格等进行排序。
合理对排序稳定性做一下介绍,假设在待排序的数据中,存在多个具有相同的关键字的数据,若经过排序,这些记录的相对顺序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排 序算法是稳定的;否则称为不稳定的。
插入排序
思想
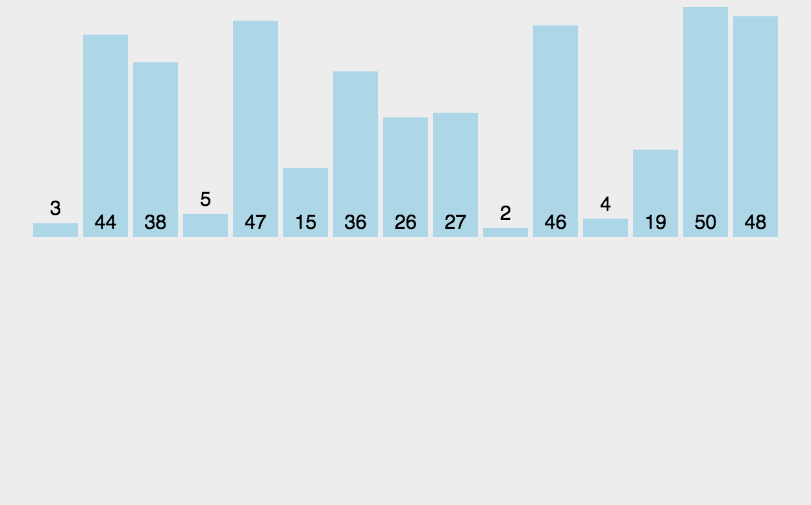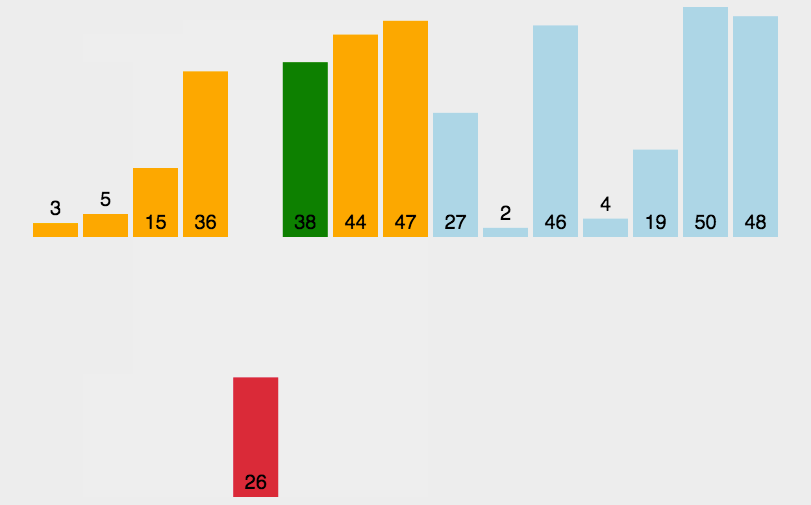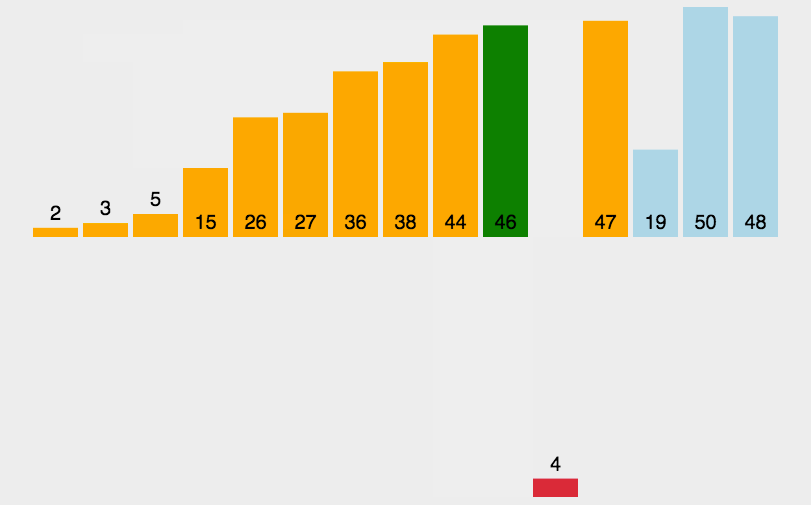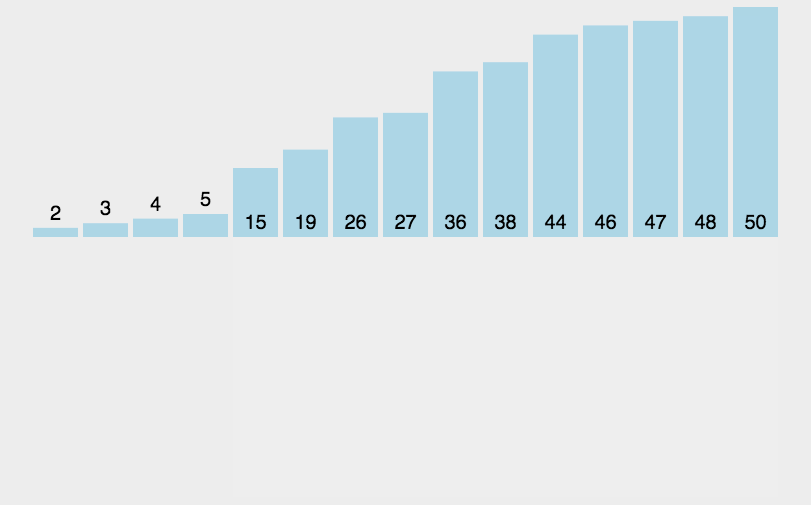
插入排序的思想其实类似我们玩扑克牌时,每次抓牌都会进行一次排序。这里就按升序来说,每一次插入排序都是将要排序的数据和它前面的数据作比较,当需要排序的数据比前面小就交换,并将它向前移,比它大的数据往后挪,直到前面的数据比它小或者排序的数据下标已经小于0就停止单趟排序。
单趟排序代码实现
根据插入排序的思想,我们从1下标位置开始插入数据进行排序,所以当前一个数据比后一个数据大的时候,我们就进行交换。直到插入的位置小于数组的有效范围就停止单趟排序。这样小的数就会往前移动,大的数整体往后挪动。
int end ;//用于表示当前数据的下标
int tmp ;//插入数据的值
while(end >= 0)
{
//前一个数比它小就覆盖
if(tmp < arr[end])
{
arr[end+1] = arr[end];
end--;
}
//否则就结束单趟排序
else
{
break;
}
}
完整代码实现
有了单趟排序的实现,我们根据整体的思想就可以写出外循环。即外循环从1开始到n-1结束。当单趟排序结束时,需要对超出数组范围的数重新写回数组内。例如当end == -1 时就要将它写会0下标处。
//插入排序——升序
void InsertSort(int* arr, int n)
{
for(int i = 1; i < n;i++)
{
int end = i - 1 ;
int tmp = arr[i];
while(end >= 0)
{
if(tmp < arr[end])
{
arr[end+1] = arr[end];
end--;
}
else
{
break;
}
}
arr[end+1] = tmp;
}
}
特性总结
一、当数据越接近有序插入排序的效率越高,排升序时,当数据为升序(最好情况),插入排序的时间复杂度为O(N)。因为最好情况只需要遍历n-1次数据并进行判断即可。
二、最坏情况下,插入排序的时间复杂度为O(N^2)。即排升序时,当数据为降序。因为每次单趟排序挪动数据的时间复杂度为O(N),整体要走N-1趟排序,所以时间复杂度为O(N ^ 2)。
三、插入排序的时间复杂度为O(N^2),空间复杂度为O(1)。
四、插入排序是一种稳定的排序。排序稳定性的定义为排序前后数组内相同元素的相对位置不变。
希尔排序
思想
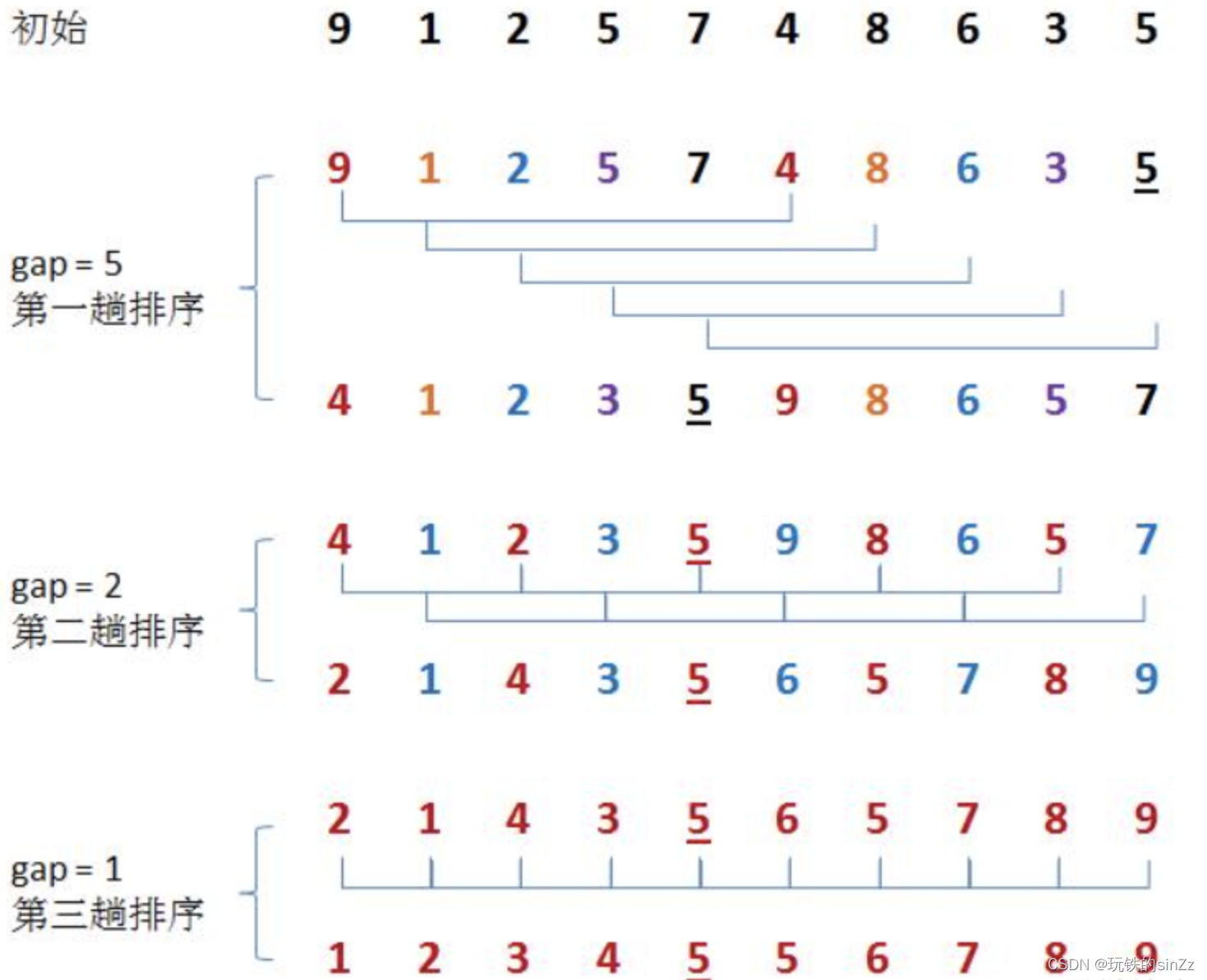
希尔排序也称缩小增量排序,思想为取一个整数位分组的标识,这里我就用gap来表示这个值,将待排的数据按照gap步的差距分成多组。并对这个多组数据进行直接插入排序以让它们越来越接近有序,一开始gap值比较大,大的数就会快速往后挪,小的数就会被往前推。随着gap逐渐变小,数据越来越接近有序,最后当gap=1时,数据已经接近有序,此时就会进行直接插入排序。

单趟排序代码实现
单趟排序的实现思路同插入排序,不同的是,单趟排序这里因为要分组,所以是以组间隔gap来分组进行单趟排序,最后一趟当gap==1时,就是插入排序了。
int end;
int tmp;
while(end >= 0)
{
if(tmp < arr[end])
{
arr[end+gap] = arr[end];
end-= gap;
}
else
{
break;
}
}
代码实现
这里gap的取法有很多种,大部分都是/2或者/3+1取gap值。我这里就以/2为例写。外循环的控制的逻辑大体来说就是控制gap使区间局部有序,最后当gap==1时,直接在接近有序的数组上进行插入排序。下面代码可以参考,具体的写法看个人喜好,思想上基本都是大差不差的。
//希尔排序——升序
void ShellSort(int* arr, int n)
{
int gap = n;
while(gap > 1)
{
gap/=2;
for(int i = 0; i < n-gap;i++)
{
int end = i ;
int tmp = arr[i+gap];
while(end >= 0)
{
if(tmp < arr[end])
{
arr[end+gap] = arr[end];
end-= gap;
}
else
{
break;
}
}
arr[end+gap] = tmp;
}
}
}
特性总结
一、希尔排序其实就是对直接插入排序的优化。通过根据gap分组先预排序极大程度的优化了直接插入排序最坏情况时的窘迫状况,可以快速让大的数后挪,小的数前移。
二、当gap大于1时,都是预排序,目的是让数组更加接近有序,优化直接插入排序的次数。这对于直接插入排序思想是个极大程度的优化,效率较高。
三、由于gap取值方面并没有一个比较官方统一的数值,但是必须保证gap最后一次必须是1。所以时间复杂度方面并没有办法进行一个标准的定义。这里就引用一下严老师的内容来对此进行一个比较好的解释。

希尔排序的时间复杂度O(N^1.3),由此也可以把希尔排序纳入O(NLogN)这个时间复杂度量级的排序当中。当N越来越大时,N ^1.3次方比起NLogN还是又不小的差距

四、希尔排序是不稳定的排序,因为可能在gap分组预排序顺序可能会受到影响。
选择排序
思想
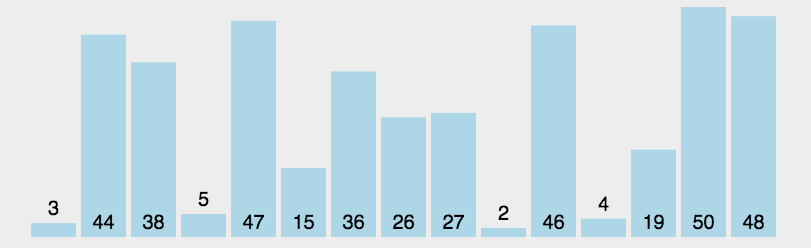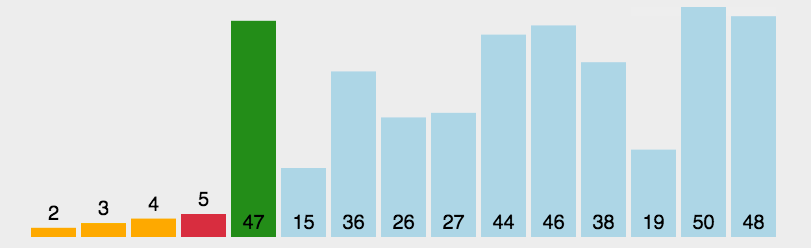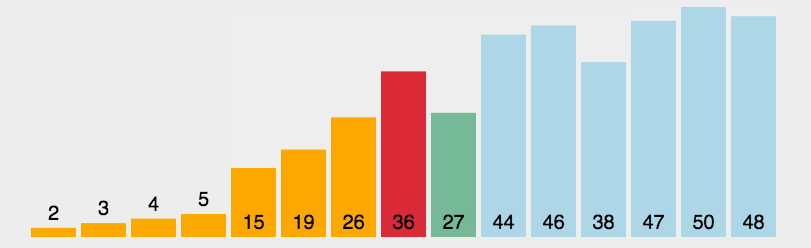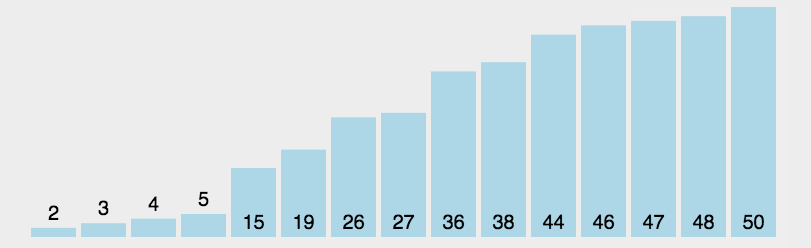
就是每一次遍历整个数组,求出整个数组的最大值/最小值并把它放到合适的位置就完成单趟排序。根据每一次遍历数组都可以求出最大值和最小值,也可以将选择排序优化为一次将最大值和最小值放到合适的位置。不过需要进行特殊判断避免left和max重叠问题,导致交换后,无法让max到合适的位置。然后冲复上述步骤直到区间内只有一个数据,则排序结束。
单趟排序代码实现
遍历数组,找出最大和最小值并把它们挪到对应的下标位置处。需要注意的是由于同时找大和找小,所以要避免重叠特殊判断,否则会有覆盖数据的情况出现。
//每一次找出区间内最大和最小的数
int mini;
int maxi;
for(int i = left + 1; i <= right; i++)
{
if(arr[mini] > arr[i])
mini = i;
if(arr[maxi] < arr[i])
maxi = i;
}
//由于同时找大和找小,所以要避免重叠特殊判断
Swap(&arr[left],&arr[mini]);
if(maxi == left)
maxi = mini;
Swap(&arr[right],&arr[maxi]);
代码实现
整体就是从0到n-1区间逐步往中间缩。当left >= right时,表示没有有效区间了。
//选择排序
void SelectSort(int* arr, int n)
{
int left = 0;
int right = n - 1;
while(left < right)
{
//每一次找出区间内最大和最小的数
int mini = left;
int maxi = left;
for(int i = left + 1; i <= right; i++)
{
if(arr[mini] > arr[i])
mini = i;
if(arr[maxi] < arr[i])
maxi = i;
}
//避免重叠特殊判断
Swap(&arr[left],&arr[mini]);
if(maxi == left)
maxi = mini;
Swap(&arr[right],&arr[maxi]);
left++;
right--;
}
}
特性总结
一、选择排序比较容易理解,但是效率实在太过低效。通常也不会用到它来进行排序。
二、它的时间复杂度一如既往的稳定在O(N^2),空间复杂度为O(1)。
三、它是一个不稳定的排序。举一个样例,如果出现最大值重复的情况,那么本该在前面的最大值会因为先被交换到最后,而导致相同值的顺序错乱。
堆排序
点击这里跳转到堆排序介绍,由于前面已经介绍过了这里就不多做赘述。根据上面介绍的直接选择排序的介绍不难发现,其实堆排序就是对于直接选择排序的一种优化。不过这是一种凭借堆这种完全二叉树的结构来建堆提升选大根/小根的效率来进行排序。
代码实现
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
// 选出左右孩子中大的那一个
if (child + 1 < n && a[child + 1] > a[child])
{
++child;
}
//判断父子关系
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
//迭代
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//堆排序
void HeapSort(int* arr, int n)
{
//向下调整建堆
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(arr, n, i);
}
//排序:大数往下沉,然后堆顶向下调整堆
int end = n - 1;
while (end > 0)
{
Swap(&arr[end], &arr[0]);
AdjustDown(arr, end, 0);
--end;
}
}
特性总结
一、使用堆这个数据结构进行选树,大大提升了效率。
二、堆排序的时间复杂度为O(N*LogN),空间复杂度为O(1)。
三、堆排序是一种不稳定的排序。
冒泡排序
思想
冒泡排序的思想是从第0个位置开始依次和后面的数据进行比较和交换。以升序为例,当前一个数比后一个数大的时候,交换两个数位置,直到单趟结束,最终最大的数会出现在它应该出现的位置。最坏的情况下需要走n-1趟冒泡排序。
单趟排序代码实现
两两比较,直到找到单趟内最大的值,并让它到它合适的位置。
for (int i = 1; i < n; i++)
{
if (arr[i - 1] > arr[i])
{
Swap(&arr[i - 1], &arr[i]);
}
}
代码实现
//冒泡排序
void BubbleSort(int* arr, int n)
{
for (int j = 0; j < n - 1; j++)
{
//若有序就跳出循环
//优化后,最好情况时间复杂度为O(N)
int flag = 0;
for (int i = 1; i < n-j; i++)
{
if (arr[i - 1] > arr[i])
{
Swap(&arr[i - 1], &arr[i]);
flag = 1;
}
}
if (flag == 0)
{
break;
}
}
}
特性总结
一、冒泡排序是一个就有教学意义的排序算法。
二、冒泡排序的时间复杂度为O(N^2),空间复杂度为O(1)。
三、冒泡排序是一种稳定的排序.