文章目录
- 一、初步实现
- 二、警告信息的解决
一、初步实现
要遍历文件夹中的图像并将其尺寸调整为28x28,并将结果输出到Excel中,可以按照以下步骤进行操作:
首先,确保您已经安装了Pandas库,用于处理Excel文件。可以使用以下命令安装它:
pip install pandas
然后,使用以下代码来遍历文件夹中的图像、调整尺寸并输出到Excel中:
import os
import torch
import clip
from PIL import Image
import pandas as pd
# 加载预训练的CLIP模型
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# 图像文件夹路径
folder_path = '/path/to/folder' # 将此路径替换为图像文件夹的实际路径
# 创建空DataFrame用于存储图像特征
df = pd.DataFrame()
# 遍历图像文件夹
for filename in os.listdir(folder_path):
if filename.endswith('.jpg') or filename.endswith('.png'): # 仅处理.jpg和.png格式的图像文件
image_path = os.path.join(folder_path, filename)
# 加载和预处理图像
image = Image.open(image_path).convert('RGB')
image_resized = image.resize((28, 28))
image_input = preprocess(image_resized).unsqueeze(0).to(device)
# 图像编码
with torch.no_grad():
image_features = model.encode_image(image_input)
# 将图像特征添加到DataFrame中
image_features_list = image_features.squeeze().tolist()
df[filename] = image_features_list
# 在DataFrame的最后一列添加全为0的标记列
df['label'] = 0
# 将DataFrame保存到Excel文件
output_path = '/path/to/output.xlsx' # 将此路径替换为输出Excel文件的实际路径
df.to_excel(output_path, index=False)
请将代码中的/path/to/folder替换为包含图像文件的文件夹的实际路径,并将/path/to/output.xlsx替换为您想要保存输出Excel文件的实际路径。
这段代码会遍历指定的图像文件夹中的图像文件(仅处理.jpg和.png格式的文件),将图像尺寸调整为28x28,然后使用CLIP模型对图像进行编码,并将结果存储在一个DataFrame中。最后,将DataFrame保存为Excel文件,其中最后一列的值都标记为0。
但是代码运行过程中,频繁报错:
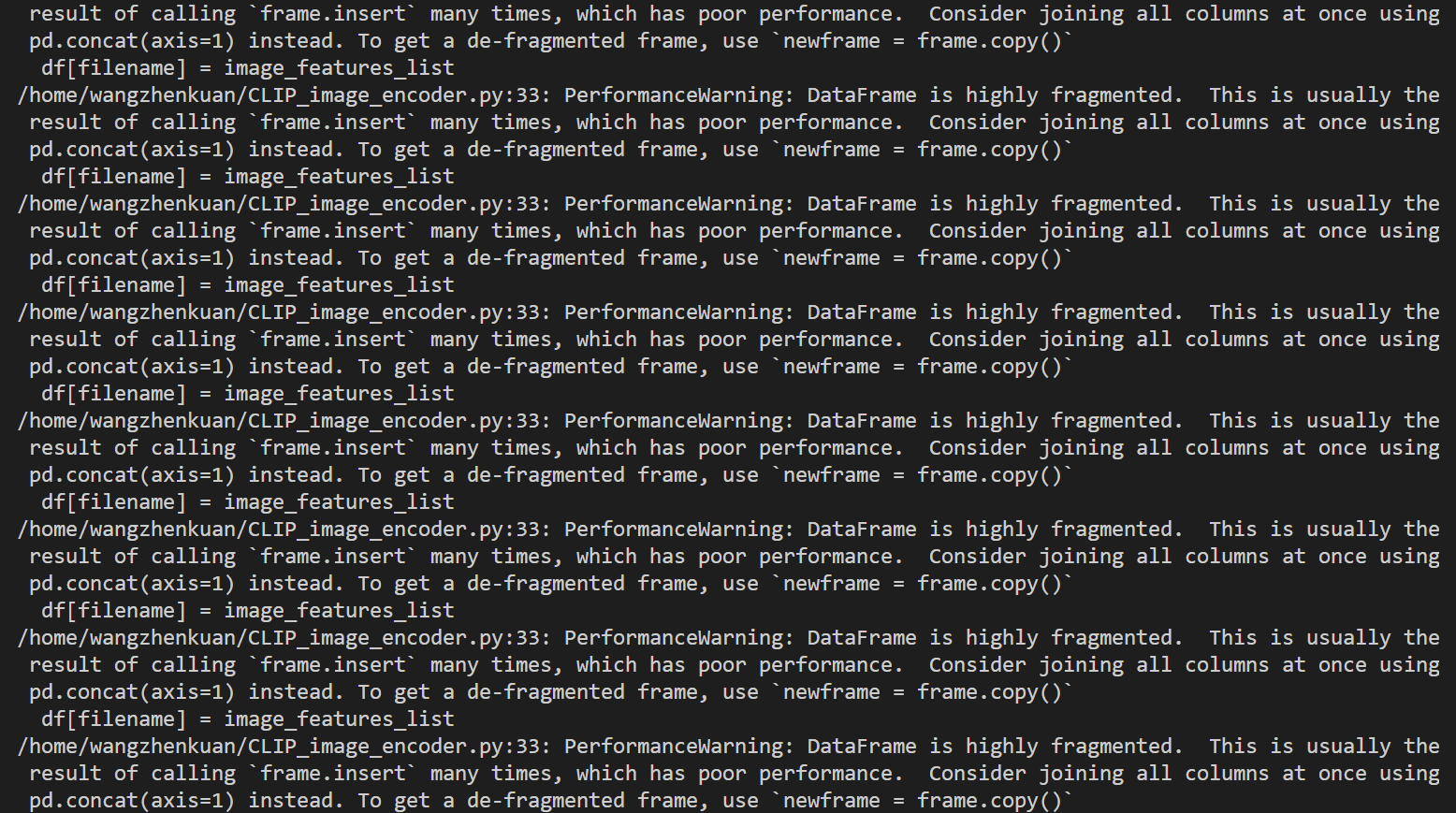
报错的错误类型为:
/home/wangzhenkuan/CLIP_image_encoder.py:33: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
df[filename] = image_features_list
/home/wangzhenkuan/CLIP_image_encoder.py:33: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
df[filename] = image_features_list
/home/wangzhenkuan/CLIP_image_encoder.py:33: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
df[filename] = image_features_list
/home/wangzhenkuan/CLIP_image_encoder.py:33: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
df[filename] = image_features_list
二、警告信息的解决
警告信息表明DataFrame的性能受到了碎片化的影响,这是由于多次调用frame.insert导致的。为了避免这个性能问题,可以使用pd.concat(axis=1)一次性将所有列连接起来。
以下是修改后的代码,使用pd.concat来连接所有特征列:
import os
import torch
import clip
from PIL import Image
import pandas as pd
# 加载预训练的CLIP模型
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# 图像文件夹路径
folder_path = 'segment-anything-main/notebooks/output/' # 将此路径替换为图像文件夹的实际路径
# 创建空DataFrame用于存储图像特征
df = pd.DataFrame()
# 创建空列表用于存储图像特征
feature_list = []
# 遍历图像文件夹
for filename in os.listdir(folder_path):
if filename.endswith('.jpg') or filename.endswith('.png'): # 仅处理.jpg和.png格式的图像文件
image_path = os.path.join(folder_path, filename)
# 加载和预处理图像
image = Image.open(image_path).convert('RGB')
image_resized = image.resize((28, 28))
image_input = preprocess(image_resized).unsqueeze(0).to(device)
# 图像编码
with torch.no_grad():
image_features = model.encode_image(image_input)
# 将图像特征添加到列表中
image_features_list = image_features.squeeze().tolist()
feature_list.append(image_features_list)
# 使用pd.concat(axis=1)将所有特征列连接起来
df = pd.DataFrame(feature_list).T
# 在DataFrame的最后一列添加全为0的标记列
df['label'] = 0
# 将DataFrame保存到Excel文件
output_path = 'output_negtive.xlsx' # 将此路径替换为输出Excel文件的实际路径
df.to_excel(output_path, index=False)
这样修改后的代码将避免性能警告,并使用pd.concat(axis=1)一次性将所有特征列添加到DataFrame中。