✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。
🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
本文目录
- 核心概念
- 进程
- 进程的状态
- 进程的内存空间布局
- 进程控制块和上下文切换
- 案例分析:Linux 的进程操作
- 进程的创建:fork
- 进程的执行:exec
- 进程管理
- 进程间的关系与进程树
- 进程间监控:wait
- 进程组和会话
- 讨论:fork 过时了么
- fork 的优点
- fork 的局限性
- 合二为一: posix_spawn
- 限定场景: vfork
- 精密控制: rfork/clone
- 线程
- 进程的缺陷
- 多线程的地址空间布局
- 用户态线程和内核态线程
- 线程控制块与线程本地存储
- 线程接口:POSIX 线程库 pthreads
- 创建线程
- 线程退出
- 出让资源
- 合并操作
- 挂起与唤醒
- Chcore 的线程上下文
- 线程的上下文和 TCB
- Chcore 上下文切换的实现
核心概念
- 进程(process):对程序的创建、运行到终止全过程的抽象。
- 上下文切换(context switch):通过保存和恢复进程在运行过程中的状态(即上下文), 使进程可以暂停、切换和 恢复, 从而实现了 CPU 资源的共享。
- 线程(thread):针对进程间数据不易共享、通信开销高等问题, 操作系统在进程内部引入了更加轻量级的执行单元。
- 迁程(fiber):由千上下文切换需要进入内核, 开销较大, 引入了纤程 (fiber)这一抽象, 允许上下文直接在用户态切换。
进程
进程的状态
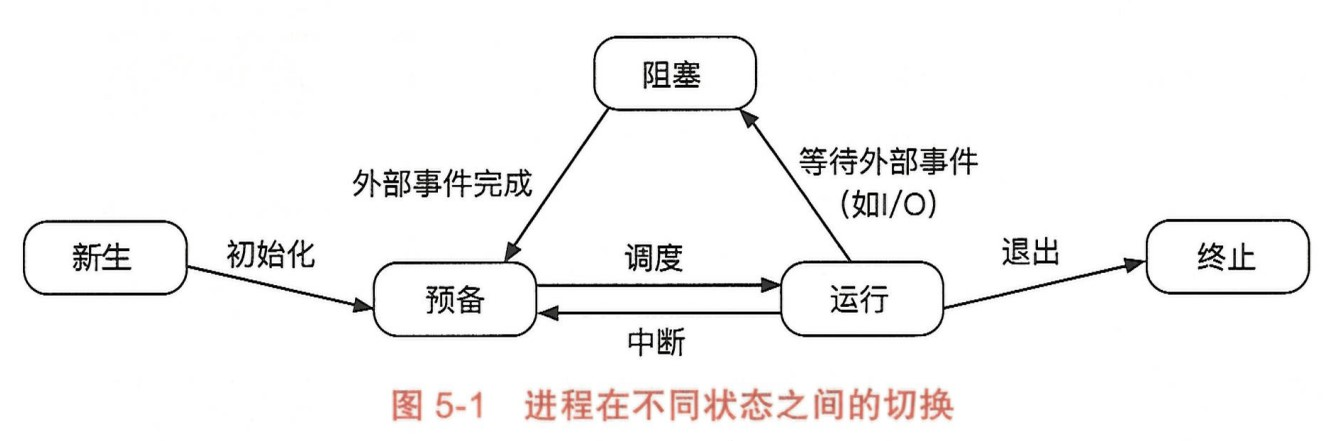
进程一般可以分为 5 个状态:
- 新生状态(new):进程刚刚被创建出来,还未完成初始化,不能被调度执行。
- 预备状态(ready):该状态表示进程可以被调度执行, 但还未被调度器选择。由于 CPU 数量可能少于进程数量, 在某一时刻只有部分进程能被调度到 CPU 上执行。在被调度器选择执行后,进程迁移至运行状态。
- 运行状态(running):进程正在 CPU 上运行。 当一个进程执行一段时间后,调度器可以选择中断它的执行并重新将其放回调度队列,它就迁移至预备状态。当进程运行结束,它会迁移至终止状态。如果一个进程需要等待某些外部事件, 它可以放弃 CPU 并迁移至阻塞状态。
- 阻塞状态(blocked):该状态表示进程需要等待外部事件(如某个 I/O 请求的完成),暂时无法被调度。当进程等待的外部事件完成后,它会迁移至预备状态。
- 终止状态(terminated):该状态表示进程已经完成了执行,且不会再被调度。
执行如下代码 ./hello-name:
#include <stdio.h>
#define LEN 10
int main() {
char name[LEN] = {0};
fgets(name, LEN, stdin);
printf("Hello, %s\n", name);
return 0;
}
运行过程中,该进程的状态发生变化如下:
- 按下回车,内核创建进程,但未初始化,处于新生状态;
- 初始化完成,等待调度,进入预备状态;
- 被调度器调度至 CPU 中执行,处于运行状态;
- 等待用户输入,进入阻塞状态;
- 输入内容并回车,回到运行状态;
- 执行完 main 函数,回到内核中,变为终止状态。
进程的内存空间布局
- 用户栈:栈保存了进程需要使用的各种临时数据(如临时变量的值)。
- 代码库:进程的执行依赖的共享代码库(比如 libc),这些代码库会被映射到用户栈下方的虚拟地址处,并被标记为只读。
- 用户堆:堆管理的是进程动态分配的内存。与栈相反,堆的扩展方向是自底向上,堆顶在高地址上,当进程需要更多内存时,堆顶会向高地址扩展。
- 数据与代码段:处于较低地址的是数据段与代码段,保存在进程需要执行的二进制文件中,在进程执行前,操作系统会将它们载入虚拟地址空间中。其中,数据段主要保存的是全局变量的值,而代码段保存的是进程执行所需的代码。
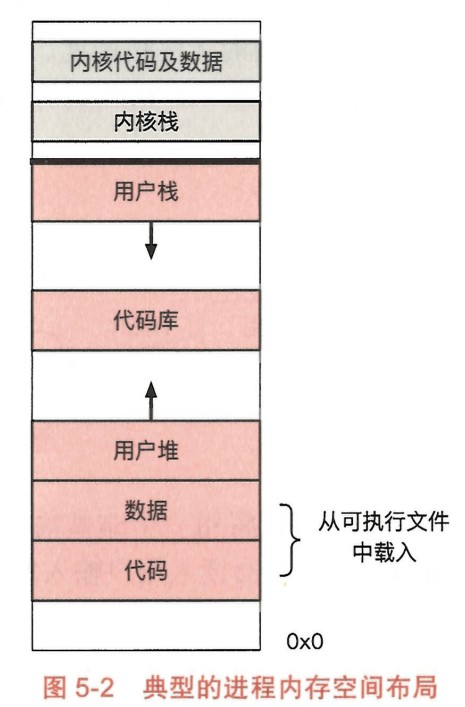
- 内核部分:处于进程地址空间最顶端的是内核内存。每个进程的虚拟地址空间里都映射了相同的内核内存。当进程在用户态运行时,内核内存对其不可见;只有当进程进入内核态时,才能访问内核内存。与用户态相似,内核部分也有内核需要的代码和数据段,当进程由千中断或系统调用进入内核后,会使用内核的栈。
通过 cat /proc/PID/maps 查看进程的内存空间布局:
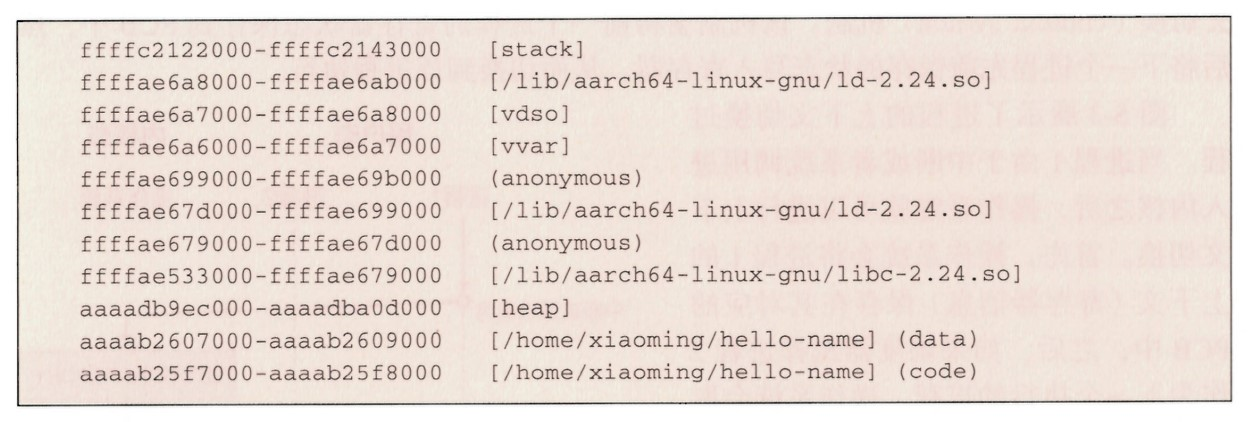
maps 内容没有包含内核部分的映射。 vdso 和 vvar 是与系统调用相关的内存区域。另外,进程也会映射一些匿名的内存区域用于完成缓存、共享内存等工作。
进程控制块和上下文切换
每个进程通过一个数据结构来保存它的相关状态, 如进程标识符(Process IDentifier, PID)、 进程状态、 虚拟内存状态、 打开的文件等。 这个数据结构称为进程控制块(Process Control Block, PCB)。
Linux 中的 PCB(task_struct) 中的部分重要字段如下:
struct task_struct
{
// 进程状态
volatile long state;
// 虚拟内存状态
struct mm_struct *mm;
// 进程标识符
pid_t pid;
// 进程组标识符(详见 fork 部分)
pid_t tgid;
// 进程间关系(详见 fork 部分)
struct task_struct __rcu *parent;
struct list_head children;
// 打开的文件
struct files_struct *files;
// 其他状态(如上下文)
···
}
进程的上下文(context):包括进程运行时的寄存器状态, 其能够用于保存和恢复一个进程在处理器上运行的状态。
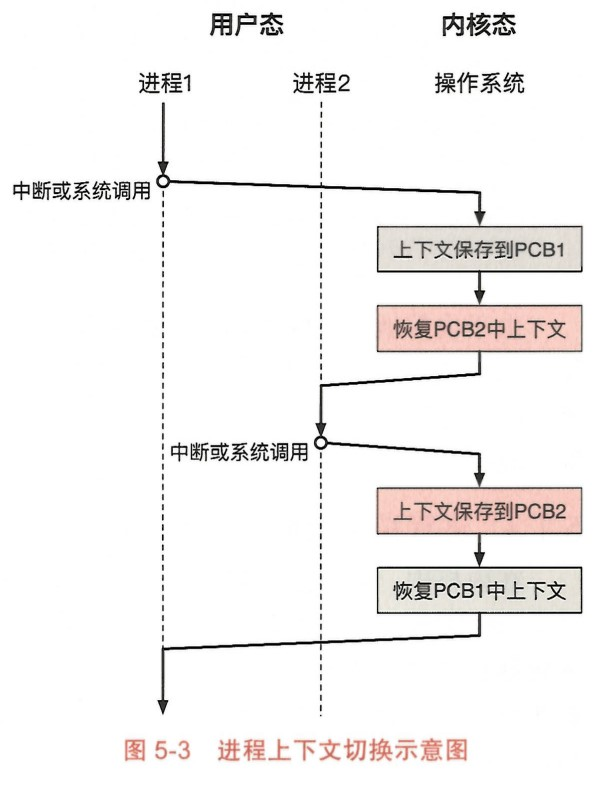
当操作系统需要切换当前执行的进程时, 就会使用上下文切换 (context switch) 机制。 该机制会将前一个进程的寄存器状态保存到 PCB 中, 然后将下一个进程先前保存的状态写入寄存器,从而切换到该进程执行。
案例分析:Linux 的进程操作
进程的创建:fork
调用 fork 时,OS 会创建一个几乎一模一样的新进程。我们将调用 fork 的进程称为父进程,将新创建的进程称为子进程。
当 fork 刚刚完成时,两个进程的内存、寄存器、程序计数器等状态都完全一致。
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
父子进程是完全独立的两个进程,拥有不同的 PID 与虚拟内存空间,在 fork 完成后它们会各自独立地执行,互不干扰。
fork 会创建出一个新的进程,并在父进程和子进程中分别返回。对于父进程,fork 的返回值是子进程的 PID。对于子进程,fork的返回值是 0。
使用 fork 的代码示例:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
int x = 42;
int rc = fork();
if (rc < 0)
{
// fork 失败
fprintf(stderr, "Fork failed\n");
}
else if (rc == 0)
{
// 子进程
printf("Child process: rc is: %d; The value of x is: %d\n", rc, x);
}
else
{
// 父进程
printf("Parent process: rc is: %d; The value of x is: %d\n", rc, x);
}
}
结果如下:
Parent process: rc is: 8283; The value of x is: 42
Child process: rc is: 0; The value of x is: 42
父进程和子进程的执行顺序是不确定的,完全取决于调度器的决策。
由于对文件的打开,下列代码的父子进程无法输出完全一样的结果:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
char str[11];
int main()
{
str[10] = 0;
int fd = open("test.txt", O_RDWR);
if (fork() == 0)
{
ssize_t cnt = read(fd, str, 10);
printf("Child process: %s\n", (char *)str);
}
else
{
ssize_t cnt = read(fd, str, 10);
printf("Parent process: %s\n",(char *)str);
return 0;
}
}
ssize_t 是有符号整型,在 32 位机器上等同于 int,在 64 位机器上等同于 long int。
O_RDWR 定义在 fcntl.h 中,表示可读可写。
假设 test.txt 内容为 abcdefghijklmnopqrst,可能结果为:
Parent process: abcdefghij
Child process: klmnopqrst
如图,每个进程在运行过程中都会维护一张己打开文件的文件描述符(File Descriptor,fd)表。
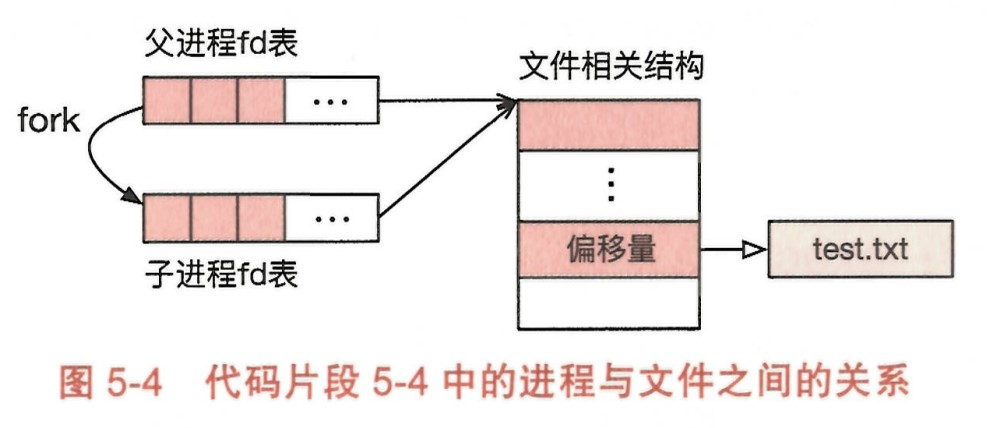
FD 是 OS 提供的对于某一文件引用的抽象。比如,FD 会使用偏移量记录当前进程读取到某一文件的某个位置。
在 fork 过程中,由于 fd 表是 PCB 的一部分(对应于 LinuxPCB 中的 files 字段),子进程会获得与父进程一模一样的 fd 表, 因此父子进程共用同一个偏移量。
Linux 在实现 read 操作时会对文件抽象加锁,因此父子进程不可能读到完全一样的字符串。
Linux 系统中的第一个进程是如何产生的?
第一个进程是操作系统创建的,该进程是特定且唯一的, 操作系统中所有的进程都由该进程产生。
Windows 系统采用 CreateProcess 函数系列创建进程,相对于 Linux 中的 fork 接口非常复杂。
进程的执行:exec
如果子进程执行的任务和父进程完全不同的任务,采用什么接口?
exec 由一系列接口构成,例如:
#include <unistd.h>
int execve(const char *pathname, char *const argv[],
char *const envp[]);
pathname: 执行文件路径argv: 执行参数envp: 环境变量(通常以键值对形式设置)
execve 被调用的大致过程:
- 根据 pathname,将可执行文件的数据段和代码段载入当前进程的地址空间中。
- 重新初始化堆和栈。在这里,操作系统可以进行地址空间随机化(Address Space Layout Randomization, ASLR)操作,改变堆和栈的起始地址,增强进程的安全性。
- 将 PC 寄存器设置到可执行文件代码段定义的入口点,该入口点会最终调用 main 函数。
在 execve 被调用后,操作系统会计算出 argv 的数量 argc, 并将 argc 与 argv 传给可执行文件的 main 函数作为参数执行。在需要设定环境变量时,main 函数也可以扩写为 int main (int argc, char * argv [], char * envp [])
进程管理
进程间的关系与进程树
每个进程的 task_struct 都会记录自己的父进程和子进程,进程之间因此构成了进程树结构。
假设小红在 Linux 操作系统的机器上打开一个终端,并使用自己的账号和密码登录,那么此时的进程树结构应该如图所示:
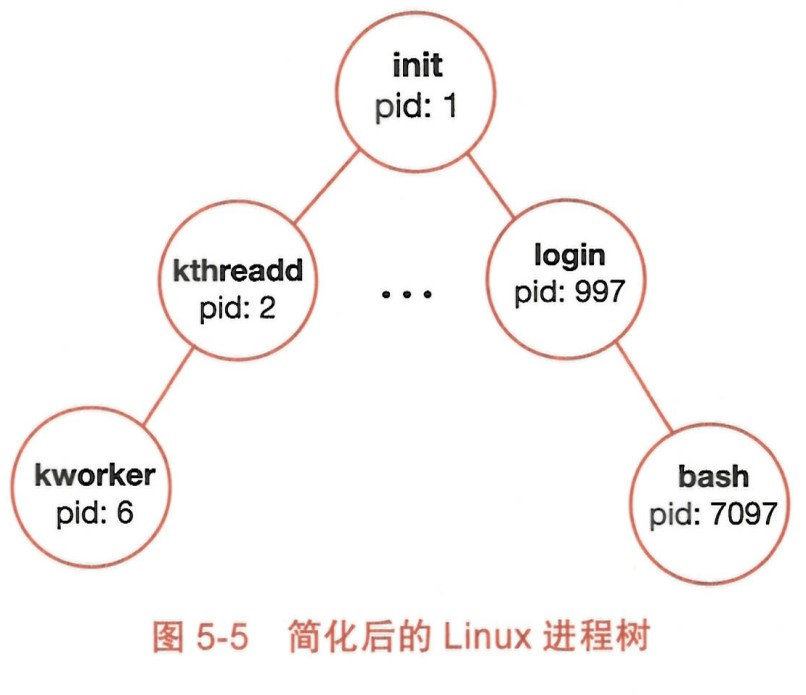
init 进程是 OS 的第一个进程。
kthreadd 进程是第二个进程,所有由内核创建和管理的进程都是由它 fork 出来的。
init 进程会创建出一个 login 进程来要求用户登录。
验证通过后,会从 login 中 fork 出 bash 进程, 即与小红交互的终端。
进程间监控:wait
wait 函数有多个版本,其中的 waitpid 如下:
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *status, int options);
pid: 需要等待的子进程 idwstatus: 保存子进程的状态options: 其它选项
父进程调用 waitpid 对子进程进行监控。如果子进程已经退出,那么 waitpid 会立即返回,并设置 status 变量的值;如果子进程还没有退出,那么 waitpid 会阻塞,并等待子进程退出。
在 waitpid 退出后,父进程可以访问 status 变量来获取子进程的状态。
除了判断子进程是否退出以外,waitpid 还允许父进程监控子进程是否被暂停或重启。
在 Linux 中,wait 操作不仅起到监控的作用,还起到回收已经运行结束的子进程和释放资源的作用。
如果父进程没有调用 wait 操作,或者还没来得及调用 wait 操作,就算子进程已经终止了,它所占用的资源也不会完全释放,我们将这种进程称为僵尸进程 (zombie)。
内核会为僵尸进程保留其进程描述符(PID) 和终止时的信息(waitpid 中的 status),以便父进程在调用 wait 时可以监控子进程的状态。
内核会设定最大可用 PID 的限制,如果一个进程创建了大量子进程却从不调用 wait,那么僵尸进程会迅速占据可用的 PID,使得后续的 fork 因为内核资源不足而失败。
如果父进程退出了,由父进程创建的僵尸进程都会被内核的第一 个进程 init 通过调用 wait 的方式回收。
进程组和会话
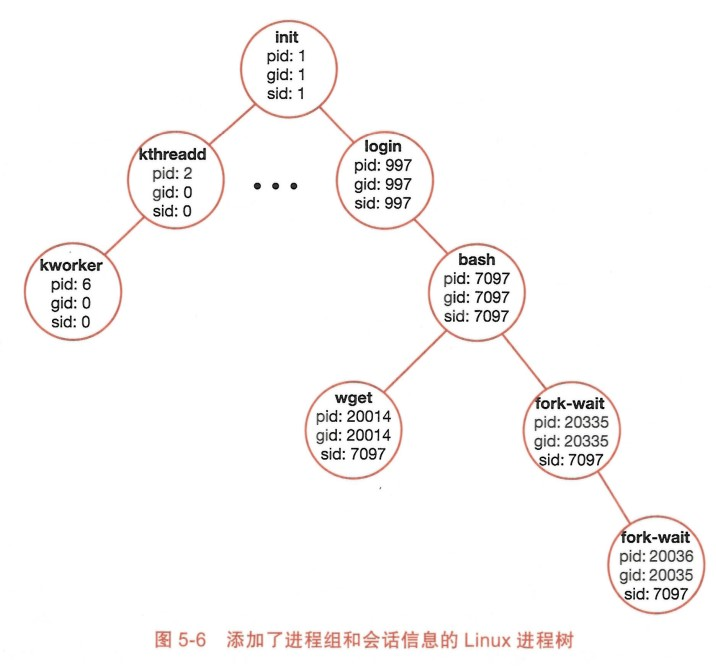
- 进程组(process group):多个进程的集合。默认父子进程属于同一个进程组。
在 Linux 中,task_struct 记录的 tgid 即为进程对应的进程组标识符。如果子进程想要脱离当前进程组,可以通过调 setpgid 创建一个新的进程组或者移入已有的进程组。
进程组的作用:对进程的分组管理。例如 killpg 表示向指定进程组发送信号。
- 会话(session):由一个或多个进程组构成的集合。根据状态可分为前台进程组和后台进程组。
控制终端进程是会话与外界进行交互的“窗口”,负责接收从用户发来的输入。当小红启动一个 Shell 时, 这个终端就对应于一个会话。输入 Ctrl+C,终端进程就会收到一个 SIGINT 信号,并将其发送给前台进程组处理。
讨论:fork 过时了么
今日,fork 广泛地应用于 Shell、Web 服务器、数据库等应用中。
fork 的优点
- 十分简洁:不需要任何参数,使用简单
- fork 和 exec 的组合:fork 为进程搭建“骨架”,而 exec 则为进程添加“血肉”。程序可以在 fork 调用后,在 exec 调用前,对子进程进行各种设定,比如对文件进行重定向。
- fork 强调了进程与进程之间的联系:在 Shell 中,同一个 Shell 创建的进程的功能虽然不同,但它们都来自同一个用户,因此可以共享很多状态。在 Web 服务中,服务器为每个请求单独创建一个进程,这些进程的程序逻辑相似,可以通过 fork 的方式创建。这些场景中,父进程和子进程之间存在强关联,适合使用 fork。
fork 的局限性
- fork 实现过于复杂
- fork 使得父子进程共享大量状态,可能会使进程表现出违反直觉的行为。
- 当 OS 为进程的结构添加功能时,必须考虑到对 fork 的实现和修改,fork 在实现中需要考虑的特殊情况越来越多,代码越来越复杂。
- fork 的实现与进程、 内存管理等模块的耦合程度过高, 不利于内核的代码维护。
- fork 的性能太差
- 原进程的状态越多,fork 的性能就越差。今天,大内存应用已经十分普遍,通过 fork 建立内存映射需要耗费大量时间。
- fork 的安全漏洞
- fork 建立的父子进程的联系会成为攻击者的切入点。
- 例如 BROP 攻击利用了 fork 的特点:子进程与父进程的地址空间和内存数据完全相同。通过 fork 的特点,BROP 多次向 Web 服务器发起请求,促使服务器调用 fork 创建每次都相同的地址空间和内存数据,通过反复尝试完成攻击。
- fork 的其它缺点
- 扩展性差、与异质硬件不兼容、线程不安全等。
- Linux 也提出了针对 fork 的多种替代方案,包括 spawn、vfork、clone 等。
合二为一: posix_spawn
posix_spawn 被认为是 fork 和 exec 的结合:它使用类似 fork 的方法(或直接调用 fork)获得进程拷贝,然后调用 exec 执行。
#include <spawn.h>
int posix_spawn(pid_t *pid, const char *path,
const posix_spawn_file_actions_t *file_actions,
const posix_spawnattr_t *attrp,
char *const argv[], char *const envp[]);
六个参数:其中 path、argv、envp 分别与 exec 的参数对应,参数 pid 会在 posix_spawn 返回时写入新进程的 PID。posix_spawn 提供了两个参数 file_actions 和 attrp。在 posix_spawn 调用中,在 exec 执行前(称为 pre-exec 阶段)根据应用程序对这两个参数的配置完成一系列操作。
posix_spawn 的性能明显优于 fork + exec,执行时间与原进程的内存无关。
限定场景: vfork
从接口来看,vfork 与 fork 完全一致。vfork 的相当于 fork 的裁剪版:它会从父进程中创建出子进程,但是不会为子进程单独创建地址空间,而是让子进程与父进程共享同一地址空间。
#include <sys/types.h>
#include <unistd.h>
pid_t vfork(void);
为保证正确性,vfork 会在结束后阻塞父进程,直到子进程调用 exec 或者退出为止。vfork 可以提升 fork 的性能表现,但仍无法完全避免 fork 本身带来的安全问题。
vfork 只适合用在进程创建后立即使用 exec 的场景中,由于 exec 本身会创建地址空间,vfork + exec 与 fork + exec 相比省去了一次地址空间的拷贝。随着应用程序内存需求的增大,就连建立地址空间映射也要消耗大量时间,在限定场景中,vfork 可以作为 fork 的优化版本代替 fork。
精密控制: rfork/clone
贝尔实验室提出的 rfork 接口支持父进程和子进程之间的细粒度资源共享。Linux 借鉴了 rfork,提出了类似的接口 clone。
#include <sched.h>
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg, ...);
clone 允许应用程序对 fork 的过程进行控制,clone 的第三个参数 flag 允许应用程序指定不需要复制的部分。例如设定 CLONE_VM 来避免复制内存,允许子父进程使用相同的地址空间,从而达到与 vfork 相似的效果。
clone 允许应用程序指定子 进程栈的位置(参数 stack)。参数 fn 和 arg 则是进程创建完成后将执行的函数和输入参数。
clone 既可以用在 fork + exec 的场景中(模拟 vfork),又可以用在使用 fork 的场景中。
在 Web 服务器的场景中,可以用 clone 代替 fork, 并通过 clone 提供的参数对进程创建的性能进行调优。
clone 具有极强的通用性,但是 clone 接口本身较复杂。
线程
进程的缺陷
- 创建进程开销大,需要完成创建独立的地址空间、载入数据和代码段、初始化堆等步骤。
- 进程拥有独立的虚拟地址空间,在进程间进行数据共享和同步比较麻烦,一般基于共享虚拟内存页(粒度粗)或者基于进程间通信(开销高)。
- 在进程内部添加可独立执行的单元,它们共享进程的地址空间,但又各自保存运行时所需的状态(即上下文),这就是线程。线程取代进程成为操作系统调度和管理的最小单位,线程也继承了操作系统为进程定义的部分概念(如状态和上下文切换)。
多线程的地址空间布局
分离的内核栈与用户栈:进程为每个线程都准备了不同的栈,供它们存放临时数据。在内核中,每个线程也有对应的内核栈。当线程切换到内核中执行时,它的栈指针就会切换到对应的内核栈。
共享的其他区域:进程除栈以外的其他区域由该进程的所有线程共享,包括堆、数据段、代码段等。当同一个进程的多个线程需要动态分配更多内存时(调用 malloc 实现),它们的内存分配操作都是在同一个堆上完成的。 因此 malloc 的实现需要使用同步原语,使每个线程能正确地获取到可用的内存空间。

用户态线程和内核态线程
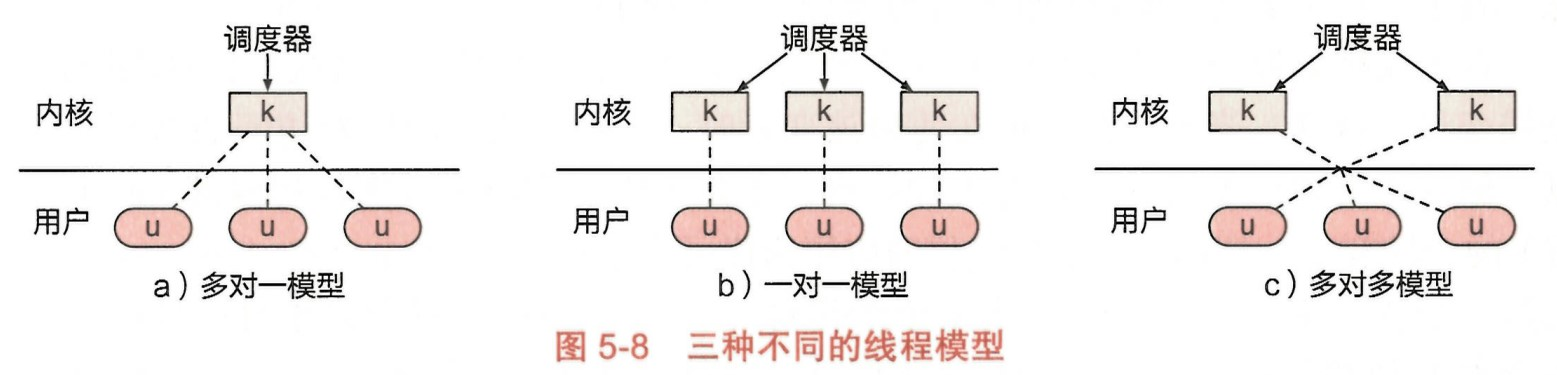
根据线程是由用户态应用还是由内核创建与管理, 可将线程分为两类:用户态线程 (user-level thread) 与内核态线程 (kernel-level thread)。
内核态线程由内核创建,受操作系统调度器直接管理。
用户态线程则是应用自己创建的,内核不可见,不直接受系统调度器管理。
用户态线程更加轻量级,创建开销更小,但功能也较为受限,与内核态相关的操作(如系统调用)需要内核态线程协助才能完成。
为了实现用户态线程与内核态线程的协作,操作系统会建立两类线程之间的关系,这种关系称为多线程模型 (multithreading model)。
线程控制块与线程本地存储
线程控制块(Thread Control Block, TCB):用于保存与自身相关的信息。
在一对一线程模型中,内核态线程和用户态线程会各自保存自己的 TCB。
内核态的 TCB 结构与 PCB 相似,存储线程的运行状态、内存映射、标识符等信息。
用户态 TCB 的结构由线程库决定。例如,对于使用 pthread 线程库的应用来说,pthread 结构体就是用户态的 TCB。
用户态的 TCB 可以认为是内核态的扩展,可以用来存储更多与用户态相关的信息,其中一项重要的功能就是线程本地存储(Thread Local Storage, TLS)。
通过 TLS 可以实现 一个名字, 多份拷贝(与线程数相同)的全局变量。这样,当不同的线程在使用该变量时,虽然从代码层次看访问的是同一个变量,但实际上访问的是该变量的不同拷贝。
如下图,线程库会为每个线程创建结构完全相同的 TLS,保存在内存的不同地址上。在每个线程的 TLS 中,count 都处于相同的位置,即每份 count 的拷贝相对于 TLS 起始位置的偏移量都相等。
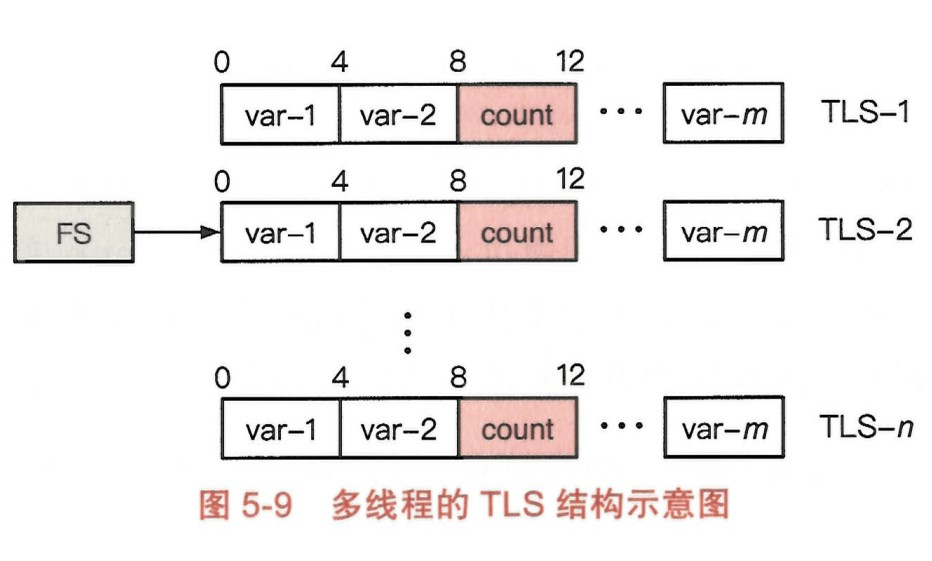
在 AArch64 中,TLS 的起始地址将被存放在寄存器 TPIDR_EL0 中。当需要访问 TLS 中的变量时,线程会首先读取 TPIDR_EL0 中的数值,再加上偏移量以获取变量的值。
X86-64 使用 FS 寄存器来实现 TLS 中变量的寻址。
线程接口:POSIX 线程库 pthreads
创建线程
pthread_create 是通过 clone 实现,可是 clone 本身是为进程创建提出的接口。clone 为了“精密控制”进程的创建过程而使用了各种标志。
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
const int clone_flags = (CLONE_VM | CLONE_FS
| CLONE_FILES | CLONE_SYSVSEM
| CLONE_SIGHAND | CLONE_THREAD
| CLONE_SETTLS | ···);
ARCH_CLONE (&start_thread, STACK_VARIABLES_ARGS, clone_flags, ···);
线程退出
phread_exit 的调用并不是必要的。当一个线程的主函数执行结束时,pthread_exit 将会隐式地被调用。
#include <pthread.h>
void pthread_exit(void *retval);
pthread_exit 提供了参数 retval 来表示线程的返回值,用户可以通过对 pthread_exit 的调用来设置返回值。
如果 pthread_exit 未被显式调用,那么线程的主函数的返回值会被设置为线程的返回值。返回值可以用在多个线程使用 pthread_join 操作进行协作的场景中。
出让资源
语义:线程主动地暂停,让出当前的 CPU,交给其他线程使用。
实现:调用 sched_yield 这一系统调用,放弃 CPU 资源。
#include <pthread.h>
int pthread_yield(void);
合并操作
语义:允许一个线程等待另一个线程的执行,并获取其执行结果。
参数:thread 为需要等待的线程,retval 接受被等待线程的返回值。
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);
挂起与唤醒
语义:当线程发现自己的执行需要等待某个外部事件时,它可以进入阻塞状态,让出计算资源给其他线程执行。线程的挂起一般有两种方式:一是等待固定的时间,二是等待具体的事件。
当 sleep 指定的时间走完后,内核会将该线程唤醒,重新将其状态改为预备状态。由于内核不能保证线程被唤醒后立即被调度,因此线程从挂起到再次执行的时间会长于其指定的需要挂起的时间。
pthread_cond_wait 使用条件变量进行同步,并使线程等待在第一个参数 cond 上。当其他线程使用 pthread_cond_signal 操作同一个条件变量 cond 时,内核会协助将挂起的线程唤醒,使其重新变为预备状态。
#include <unistd.h>
unsigned int sleep(unsigned int seconds);
#include <pthread.h>
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
sleep 和 yield 的关系:yield 可以理解为 sleep(0),yield 之后线程处于预备态,并可以被调度,sleep 之后进入阻塞态。
Chcore 的线程上下文
由于 CPU 的每个核心仅有一个程序计数器,同一时间仅能执行一个线程,上下文切换才能保证多线程的并发运行。
线程的上下文和 TCB
线程上下文主要是寄存器中的值(以 ARM64 为例,具体参考 ARM 手册):
- 程序计数器(PC)
- 通用计数器(X0-X30)
- 特殊计数器(SP_Elx, ELR_ELx, SPSR_Elx, TTBRn_ELx)x=0,1,2,3
- SP_ELx:栈指针
- ELR_ELx:异常链接
- SPSR_ELx:CPU状态
- TTBRn_ELx:线程页表
Chcore 采用 1-1 的线程模型,线程上下文保存在内核态的 TCB 中。
当线程进入内核态之后,会自动将栈指针从 SP_EL0 切换到 SP_ELl。
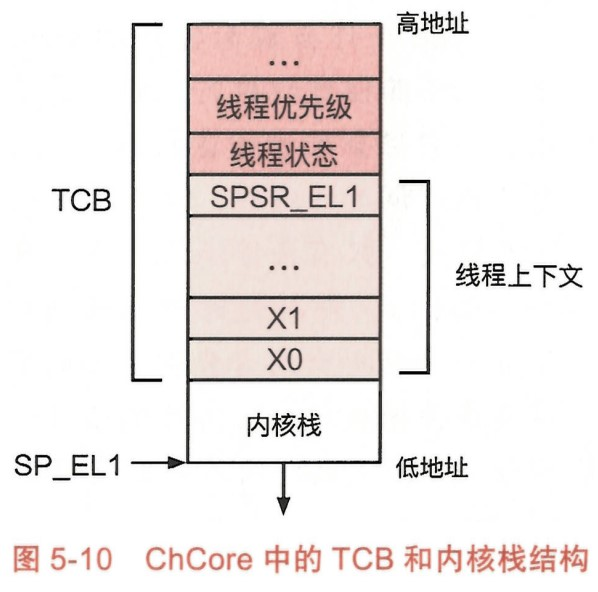
Chcore 上下文切换的实现
ChCore 中,线程的上下文切换通常由时钟中断所触发的。
上下文切换的基本过程:
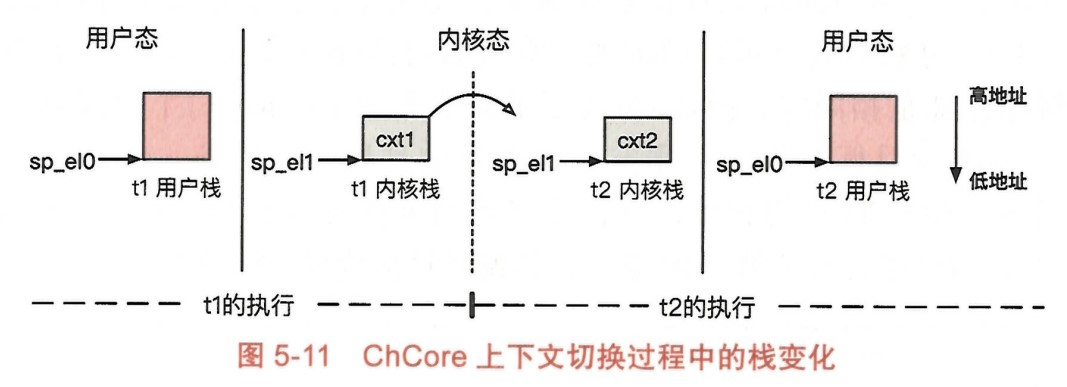
步骤1:进入内核与上下文保存
.macro exception_enter
sub sp, sp, #ARCH_EXEC_CONT_SIZE
// 保存通用寄存器(x0-x29)
stpx0, x1, [sp, #16 * 0]
stpx2, x3, [sp, #16 * 1]
stpx4, x5, [sp, #16 * 2]
...
stpx28, x29, [sp, #16 * 14]
// 保存 x30 和上文提到的三个特殊寄存器: sp_el0,elr_e1,spsr_el1
mrsx21, sp_el0
mrs x22, elr_el1
mrs x23, spsr_el1
stp x30, x21, [sp, #16 * 15]
stp x22, x23, [sp, #16 * 16]
.endm
步骤2:页表与内核栈的切换
由 switch_contet 和 eret_to_thread 共同实现的。switch_context 负责切换页表和找到目标线程的内核栈。
AArch64 在地址翻译时会使用两个页表基地址寄存器 TTBR0_EL1和 TTBR1_EL1,分别对应于进程虚拟地址空间的内核部分和应用部分。
由于每个线程映射的内核部分都是相同的 因此不需要改变TTBR0_EL1。
Switch_context 还会找到目标线程的 TCB 的起始地址,并将该地址作为目标线程的内核栈顶。
eret_to_thread 通过 mov 指令切换到目标线程的内核栈。
BEGIN_FUNC(eret_to_thread)
mov sp_el1, x0
···
END_FUNC(eret_to_thread)
步骤3:上下文恢复与返回用户态
内核使用 exception_enter 的反向操作 exception_exit 将目标线程的上下文从内核栈的栈顶依次弹出,恢复到寄存器中,并最终返回用户态。
在恢复了用户上下文后,ChCore 利用 AArch64 架构下的 eret 指令系列操作。
.macro exception_exit
ldp x22, x23, [sp, #16 * 16]
ldp x30, x21, [sp, #16 * 15]
// 恢复三个特殊寄存器
msr sp_el0, x21
msr elr_el1, x22
msr spsr_el1, x23
// 恢复通用寄存器X0-X29
ldp x0, x1, [sp, #16 * 0]
// ···
ldp x28, x29, [sp, #16 * 14]
add sp, sp, #ARCH_EXEC_CONT_SIZE
eret
.endm