动动发财的小手,点个赞吧!

由于所有模块都需要大量参数和设置,因此管理深度学习模型可能很困难。训练模块可能需要诸如 batch_size 或 num_epochs 之类的参数或学习率调度程序的参数。同样,数据预处理模块可能需要 train_test_split 或图像增强参数。
管理这些参数或将这些参数引入管道的一种简单方法是在运行脚本时将它们用作 CLI 参数。命令行参数可能难以输入,并且可能无法在单个文件中管理所有参数。 TOML 文件提供了一种更简洁的配置管理方式,脚本可以以 Python 字典的形式加载配置的必要部分,而无需样板代码来读取/解析命令行参数。
在这篇博客[1]中,我们将探讨 TOML 在配置文件中的使用,以及我们如何在训练/部署脚本中有效地使用它们。
什么是 TOML 文件?
TOML,代表 Tom's Obvious Minimal Language,是专门为配置文件设计的文件格式。 TOML 文件的概念与 YAML/YML 文件非常相似,后者能够在树状层次结构中存储键值对。 TOML 优于 YAML 的一个优点是它的可读性,这在有多个嵌套级别时变得很重要。

为什么我们需要在 TOML 中进行配置?
使用 TOML 存储 ML 模型的模型/数据/部署配置有两个优点:
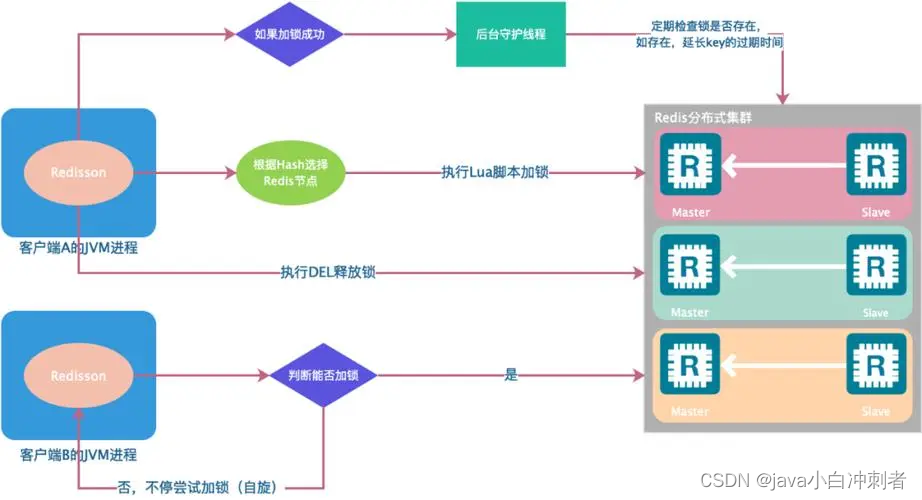
在单个文件中管理所有配置:使用 TOML 文件,我们可以创建不同模块所需的多组设置。例如,在图 1 中,与模型训练过程相关的设置嵌套在 [train] 属性下,类似地,部署模型所需的端口和主机存储在 deploy 下。我们不需要在 train.py 或 deploy.py 之间跳转来更改它们的参数,相反,我们可以从单个 TOML 配置文件中全局化所有设置。
❝如果我们在虚拟机上训练模型,而代码编辑器或 IDE 不可用于编辑文件,这可能会非常有用。使用大多数 VM 上可用的 vim 或 nano 可以轻松编辑单个配置文件。
❞
我们如何从 TOML 读取配置?
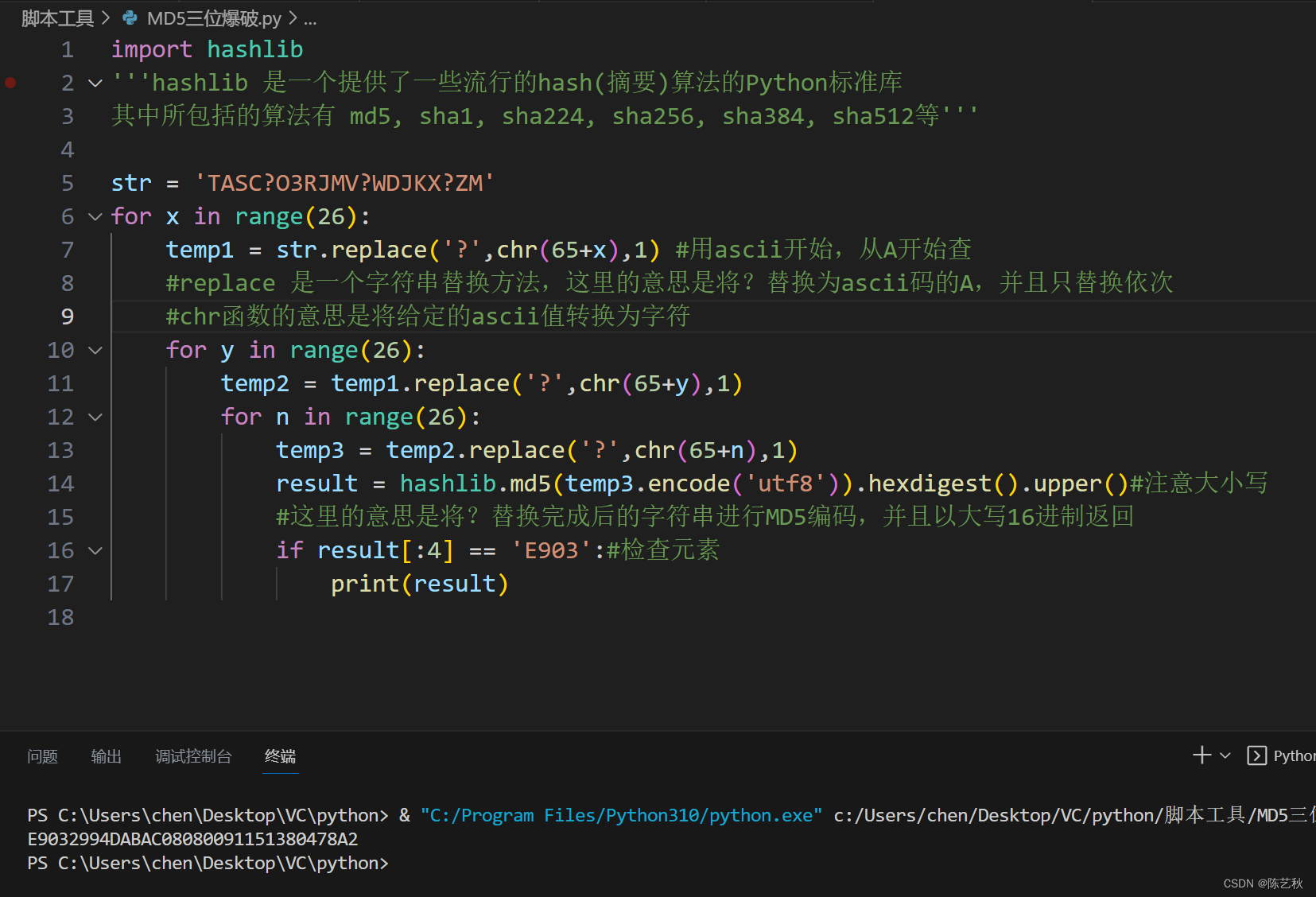
要从 TOML 文件中读取配置,可以使用两个 Python 包,toml 和 munch。 toml 将帮助我们读取 TOML 文件并将文件的内容作为 Python dict 返回。 munch 将转换 dict 的内容以启用元素的属性样式访问。例如,我们可以不写 config[ "training" ][ "num_epochs" ] ,而是写 config.training.num_epochs 以提高可读性。
考虑以下文件结构,
- config.py
- train.py
- project_config.toml
project_config.toml 包含我们 ML 项目的配置,例如,
[data]
vocab_size = 5589
seq_length = 10
test_split = 0.3
data_path = "dataset/"
data_tensors_path = "data_tensors/"
[model]
embedding_dim = 256
num_blocks = 5
num_heads_in_block = 3
[train]
num_epochs = 10
batch_size = 32
learning_rate = 0.001
checkpoint_path = "auto"
在 config.py 中,我们使用 toml 和 munch 创建了一个返回此配置的 munchified 版本的函数,
pip install toml munch
import toml
import munch
def load_global_config( filepath : str = "project_config.toml" ):
return munch.munchify( toml.load( filepath ) )
def save_global_config( new_config , filepath : str = "project_config.toml" ):
with open( filepath , "w" ) as file:
toml.dump( new_config , file )
现在,现在在我们的任何项目文件中,比如 train.py 或 predict.py ,我们可以加载这个配置,
from config import load_global_config
config = load_global_config()
batch_size = config.train.batch_size
lr = config.train.learning_rate
if config.train.checkpoint_path == "auto":
# Make a directory with name as current timestamp
pass
print( toml.load( filepath ) ) ) 的输出是,
{'data': {'data_path': 'dataset/',
'data_tensors_path': 'data_tensors/',
'seq_length': 10,
'test_split': 0.3,
'vocab_size': 5589},
'model': {'embedding_dim': 256, 'num_blocks': 5, 'num_heads_in_block': 3},
'train': {'batch_size': 32,
'checkpoint_path': 'auto',
'learning_rate': 0.001,
'num_epochs': 10}}
如果您正在使用 W&B Tracking 或 MLFlow 等 MLOps 工具,将配置维护为字典可能会有所帮助,因为我们可以直接将其作为参数传递。
总结
希望您会考虑在下一个 ML 项目中使用 TOML 配置!这是一种管理训练/部署或推理脚本全局或本地设置的简洁方法。
脚本可以直接从 TOML 文件加载配置,而不是编写长 CLI 参数。如果我们希望训练具有不同超参数的模型的两个版本,我们只需要更改 config.py 中的 TOML 文件。我已经开始在我最近的项目中使用 TOML 文件并且实验变得更快。 MLOps 工具还可以管理模型的版本及其配置,但上述方法的简单性是独一无二的,并且需要对现有项目进行最少的更改。
Reference
Source: https://towardsdatascience.com/managing-deep-learning-models-easily-with-toml-configurations-fb680b9deabe
本文由 mdnice 多平台发布