文章目录
- 一、背景
- 二、方法
- 2.1 对比学习(字典查表)
- 2.2 动量对比函数
- 2.3 Pretext Task
- 三、效果
- 3.1 数据集
- 3.2 训练细节
- 3.3 实验
论文:Momentum Contrast for Unsupervised Visual Representation Learning
代码:https://github.com/facebookresearch/moco
出处:FAIR | 何凯明 | CVPR2020
时间:2020.03
一、背景
无监督表达学习在自然语言处理方面已经有了很成功的应用,如 GPT 和 BERT,但当时(2020年左右)在计算机视觉中还是监督学习占主流。其主要原因在于两者的特征信号不同,语言任务的数据是在离散数字空间(如单词),但视觉任务的数据是在连续的高维空间。
当时的主流方法是怎么做的:
- 很多方法使用对比学习 loss 来解决,也就是最小化 contrastive loss
- 相当于构建一个动态字典,key(token)是从数据(image/patch)中采样的,使用 encoder 提取特征
- 目标是让编码后的 query 和与其匹配的 key 最为相近,和其他没匹配的 key 都距离很远
作者提出了 MoCo(Momentum Contrast),来构建一个大且连续的字典,用于支持使用 contrastive loss 训练的无监督学习,如图 1 所示
如何建立字典:
- 将字典看做数据样本的队列
- 当前 batch 的编码特征入队
- 最老的 batch 的编码特征出队
- 这样就将字典的大小和 batch size 的大小解耦了,可以扩大字典的大小
为什么是 momentum contrast:
- 因为字典的 key 是从前面的 batch 得到的,而非只有当前的 batch 的信息
- 能够使用对 query emcoder 进行动量移动平均来得到(momentum-based moving average),能够保持连贯性
MOCO 的主要特点:
- 能够为对比学习建立动态的字典

二、方法
2.1 对比学习(字典查表)
什么是对比学习:
- 对比学习的输入是对每张图进行两种不同的变换,即经过不同的数据增强,会得到两种不同的数据 q 和 k,k 不需要使用梯度反传更新参数(是使用 q encoder 参数和历史的 k encoder 参数的加权和来更新的),q 需要使用梯度反传更新参数
- 对特征 q 来说,总有一个特征 k + k_+ k+ 是其正样本,这个两个特征就是同一张原始图像的两种不同特征而已
- 对特征 q 来说,同一个 batch 中的其他图像提取到的特征就是负样本
- 从原理上说,提高对比学习的效果就是提供足够大的 batch 、研究更加有效的预处理方式,使得变换后的两个图像既能保留本质信息,又能尽可能的不一致、增加模型 encoder 的能力
对比学习可以被看做为了字典查表任务训练一个 encoder 的任务:
-
假设一个 encoded query q q q 和一系列 encoded samples { k 0 , k 1 , k 2 , . . . } \{k_0, k_1, k_2, ...\} {k0,k1,k2,...}(即字典的 key)
-
假设字典中只有一个 key k + k_+ k+ 是和 q q q 匹配的
-
当 q q q 和 k + k_+ k+ 非常近似且和其他 key (即 negative key)远离时,contrastive loss 就会很小。
当使用内积来衡量相似程度时,contrastive loss 函数的形式如下,也叫 InfoNCE[46]:
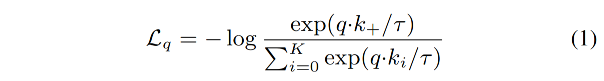
- τ \tau τ:温度超参
- K K K:negative samples 的数量
- 1 1 1:positive samples 的数量
- 该函数是一个 log loss
2.2 动量对比函数
作者之所以提出动量对比是因为作者认为使用大的字典能够引入更丰富的负样本,但大的字典中不同 batch 提取特征的模型参数是一直在更新的,这样就难以使用梯度反传的方式来更新 key encoder,之前有些方法使用 query encoder 的参数来当做 key encoder 的参数,但这样就会导致特征不连续。
1、Dictionary as a queue
本文思想的核心在于将字典当做数据的队列,这样就能够对前面 batch 的编码特征进行重复使用,可以将字典大小和 batch 大小解耦开来,字典的大小可以远远大于 batch 的大小,且大小可以设置为可调节的超参数。
字典中的样本可以被逐步的替代,当前 batch 的特征入队,最老的 batch 的特征出队
2、momentum update
使用队列可以使得字典变大,但不同 batch 提取特征的模型参数是一直在更新的,这样就难以使用梯度反传的方式来更新 key encoder,因为需要给队列中的所有 samples 传递梯度。
一个简单的做法是直接从 query encoder 来复制得到 key encoder,但效果不好
作者猜测这不好的效果来源于 encoder 剧烈的变化会降低 key 表达特征的连续性,所以提出了动量更新的方法。
所以,动量 encoder 更新 θ k \theta_k θk 的公式如下:
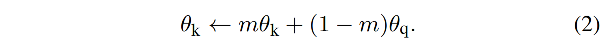
- f k f_k fk:key encoder,参数为 θ k \theta_k θk
- f q f_q fq:query encoder,参数为 θ q \theta_q θq
- m ∈ [ 0 , 1 ) m \in [0, 1) m∈[0,1) 是动量系数
- 只对 θ q \theta_q θq 使用梯度反传来更新参数
- 对 θ k \theta_k θk 使用公式 2 进行更新,会使得其更新的更加平滑,尽管 queue 中的 key 是使用不同的 encoder 来编码的(因为是在不同的 batch 中得到的),这些 encoder 的差异也可以变得很小
- 在实验中,作者使用大的动量(m=0.999)就比小的动量(m=0.9)表现更好,这也说明使用好 queue 的核心就在于 encoder 的变化要缓慢
3、Relations to previous mechanisms
MoCo 和之前两种方法的对比见图 2,主要的差别就在于字典的尺寸和参数更新的一致性。
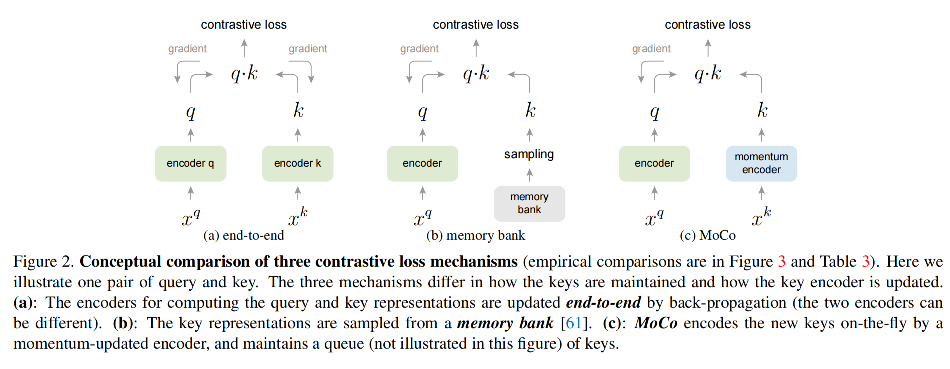
- 图 2a 是端到端的梯度反传方法,使用当前 batch 的特征作为字典的内容,则字典的大小和 batch 的大小是耦合的,会被 GPU 显存限制
- 图 2b 是 memory bank 方法,memory bank 包括所有 数据集中 sample 的特征表达,每个 batch 的字典是随机采样的,且没有梯度反传,故能支持很大的字典尺寸。但 memory bank 中的样本特征会被更新,也会缺少平稳性
2.3 Pretext Task
pretext task 也叫前置任务或代理任务,也就是该任务不是目标任务,但执行该目标可以更好的执行目标任务,本质就是迁移学习。
参考论文 [61],作者也将来源于同一张图像的 query 和 key 当做一组 positive pair,其他都是 negative pair
query 和 key 都被其各自的 encoder 进行编码 f q f_q fq 和 f k f_k fk,编码器可以是卷积神经网络。
Algorithm 1 展示了 MoCo 的伪代码

三、效果
3.1 数据集
1、ImageNet-1M(IN-1M)
约有 1.28 million 数据,共 1000 个类别
2、Instagram-1B (IG-1B)
约有 1 billion 数据,来源于 Instagram
3.2 训练细节
优化器:SGD
- weight decay:0.0001
- momentum:0.9
IN-1M :
- batch: IN-1M 使用 256(8 卡训练)
- 初始学习率:0.03
- epoch:200,在 120 和 160 时分别乘以 0.1
- 训练时间:ResNet50 训练时间大约为 53 小时
IG-1B:
- batch:1024(64卡训练)
- 学习率:0.12(每 62.5k iter 时降低到 0.9)
- iter:1.25M
- 训练时间:ResNet50 训练时间约为 6天
3.3 实验
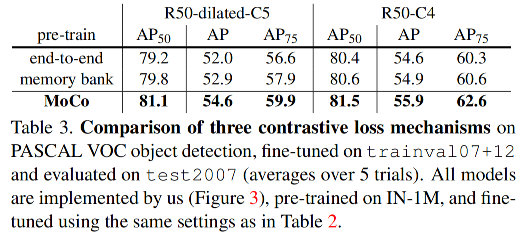
1、不同 loss 的对比
作者冻结训练好的特征(在 IN-1M 上无监督预训练),在后面接了一个 linear classification,只训练这个分类器,也表现的较好。表明 MOCO 可以很好的迁移到下游任务,有效的弥补了有监督和无监督的鸿沟。
对比不同对比学习 loss 的结果见图 3,这三个 loss 都得益于大的 K

2、Momentum 的效果
K=4096
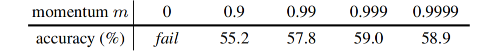
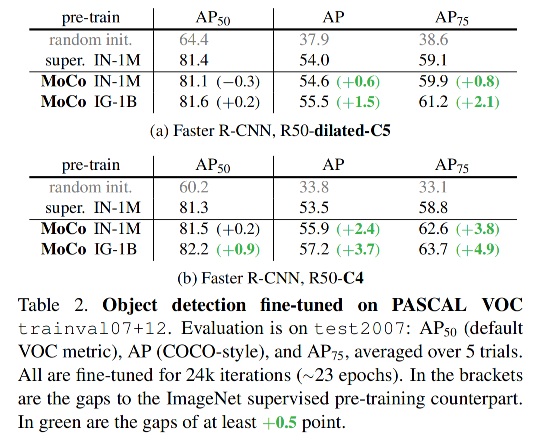
3、在 PASCAL VOC 上的目标检测效果
检测器:Faster RCNN
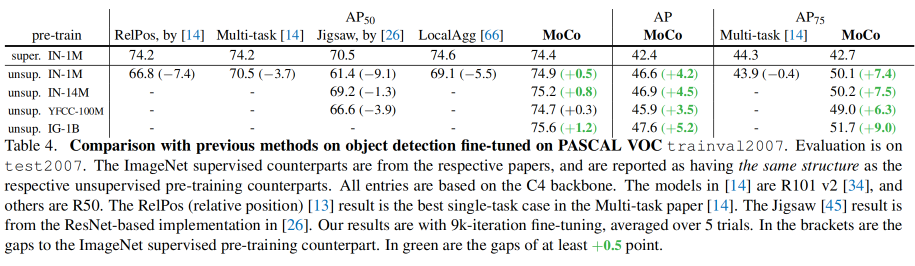
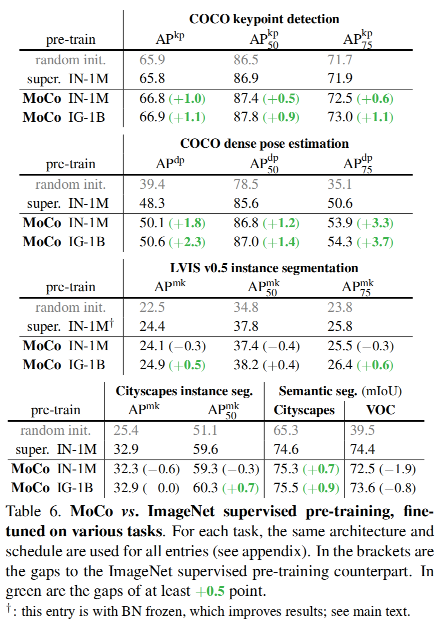
4、在 COCO 上的检测和分割
模型:Mask RCNN(with FPN)
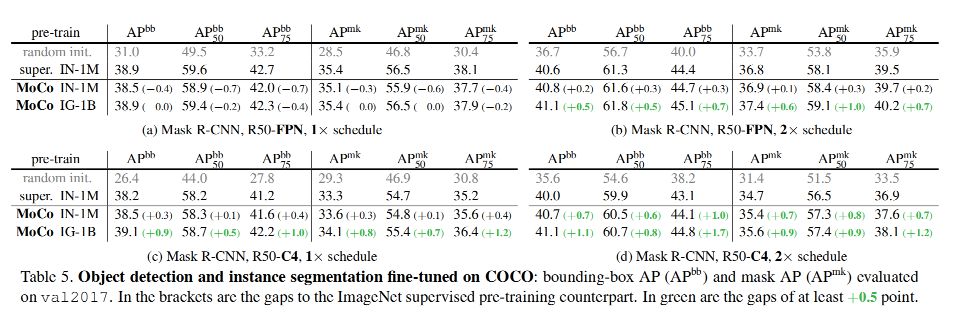
下游任务: