分类目录:《深入理解深度学习》总目录
相关文章:
· GPT(Generative Pre-Trained Transformer):基础知识
· GPT(Generative Pre-Trained Transformer):在不同任务中使用GPT
· GPT(Generative Pre-Trained Transformer):GPT-2与Zero-shot Learning
· GPT(Generative Pre-Trained Transformer):GPT-3与Few-shot Learning
GPT-3曾经是最大、最让人惊艳也是最具争议的预训练语言模型。介绍GPT-3的论文长达72页,包括模型设计思路、理论推导、实验结果和实验设计等内容。GPT-3的模型实在过于庞大,参数量达到1750亿,即使开源,也因为过大的模型和算力需求,无法作为个人使用的预训练语言模型进行部署。
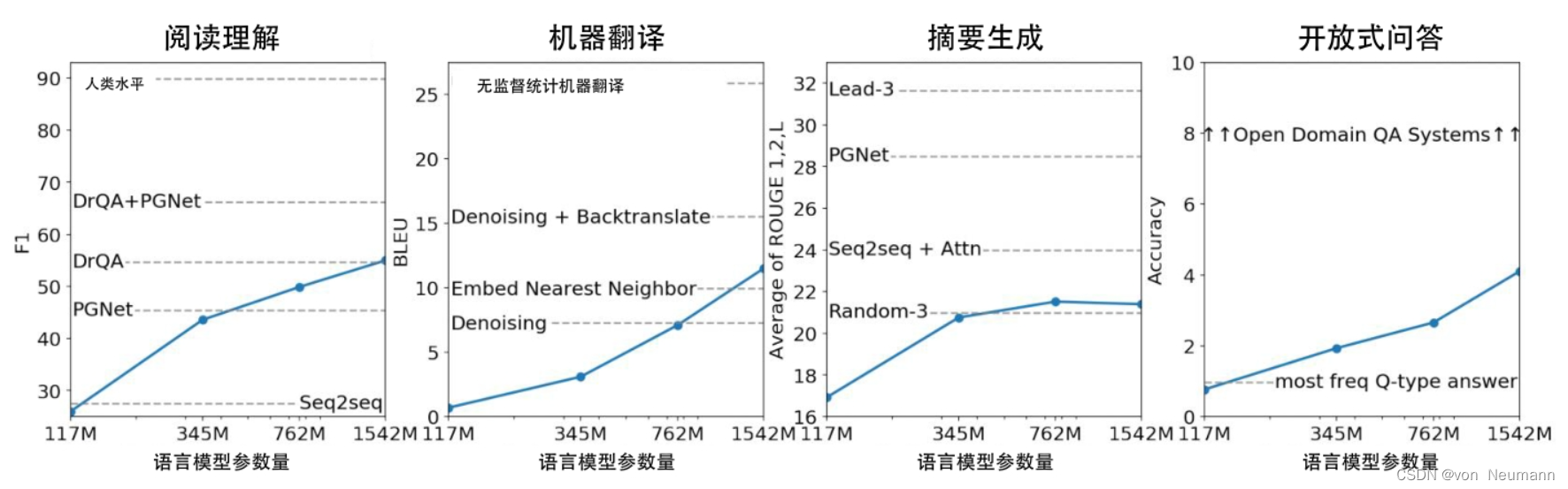
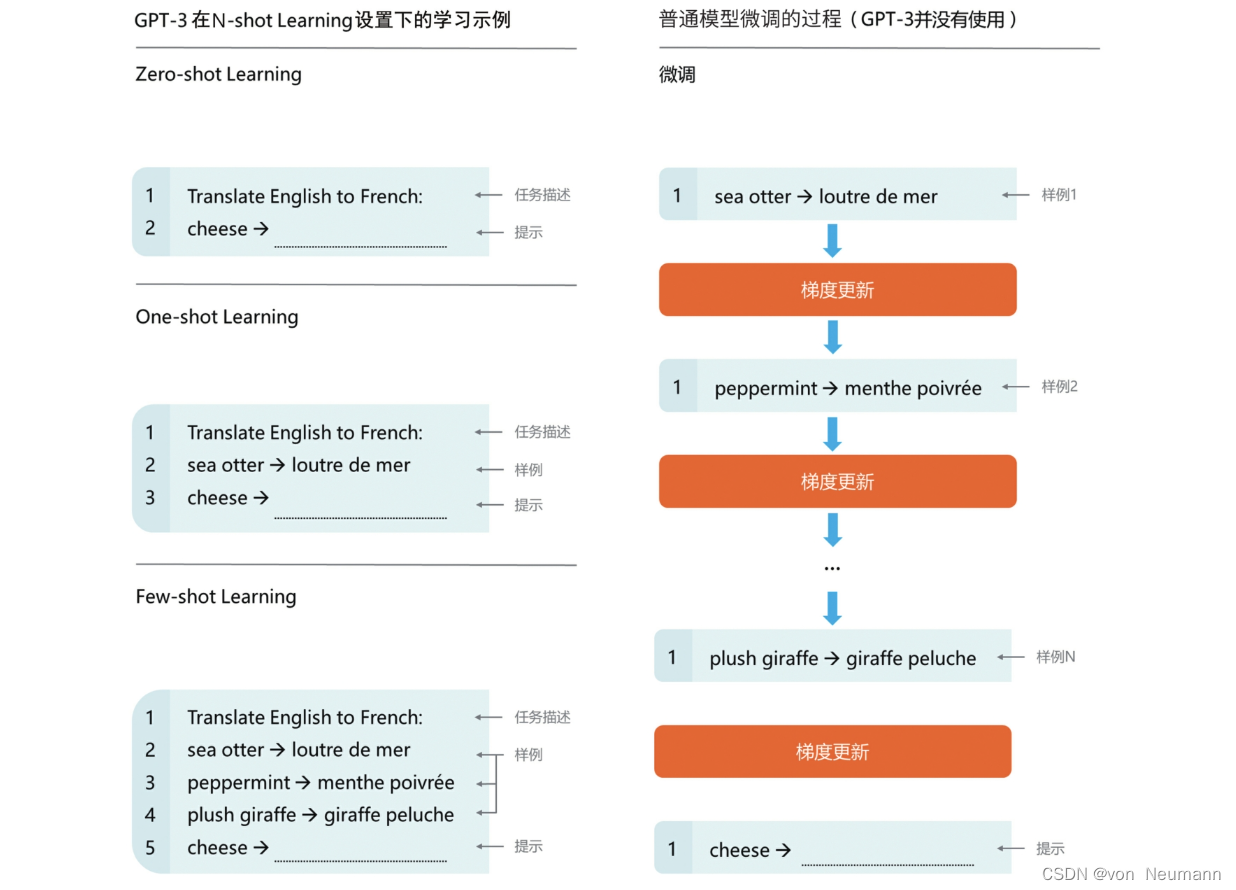
与文章《深入理解深度学习——GPT(Generative Pre-Trained Transformer):GPT-2与Zero-shot Learning》中介绍的GPT-2在Zero-shot Learning设置下的惊喜表现相比,GPT-3在Few-shot Learning设置下的性能足以震惊所有人。在自然语言处理下游任务性能评测中,GPT-2在Zero-shot Learning设置下的性能表现远不如SOTA模型,而GPT-3在Few-shot Learning设置下的性能表现与当时的SOTA模型持平,甚至超越了SOTA模型。下图所示的是GPT-3在少量样本下的机器翻译使用范例。下图右侧是普通模型微调的过程,模型通过大量训练语料进行训练,使用特定任务数据进行梯度迭代更新,训练至收敛后的模型才具备良好的翻译能力。而下图左侧是GPT-3在N-shot Learning设置下的学习示例,在Zero-shot Learning设置下,只需要给出任务描述,GPT-3就能实现翻译;在One-shot Learning设置下,除了要给出任务描述,还需要给出一个翻译样本,GPT-3才可以实现翻译;在Few-shot Learning设置下,除了要给出任务描述,还需要给出更多的训练数据(依旧是少量样本,远少于微调过程所需的训练数据,GPT-3却可以实现更优质的翻译)。通常,给出的样本数据越多,GPT-3在指定任务上的表现就越好。不仅如此,若在同一个任务上具有同样的表现,GPT-3所需的微调训练数据远少于SOTA模型。
GPT-3在许多自然语言处理数据集上都有出色的表现,包括问答及文本填空等常见的自然语言处理任务。GPT-3的文本生成能力足以达到以假乱真的境界,
看词造句
给出一个新单词及其释义,使用新单词造句。这是小学生学新词时常遇到的任务,通过造句可以判断学生是否掌握了词的真正含义。论文Language Models are Few-shot Learners给出了以下示例:
A “Burringo” is a car with very fast acceleration. An example of a sentence that uses the word Burringo is: In our garage we have a Burringo that my father drives to work every day.
GPT-3接收的输入原文:“Burringo”是一款加速很猛的车,用Burringo造句。
GPT-3给出的造句结果:我家车库有一台Burringo,父亲每天开着它去上班。
虽然没能体现加速很快的特点,但是GPT-3准确地把握了“Burringo”一词最主要的特性,即它代表车的意思。
下面通过虚构一个动词词性的新单词,看看GPT-3能否很好地把握新单词的含义:
To “screeg” something is to swing a sword at it. An example of a sentence that uses the word screeg is: We screeghed at each other for several minutes and then we went outside and ate ice cream.
GPT-3接收的输入原文:“screeg”指的是击剑,用screeg造句。
GPT-3给出的造句结果:我们击了一会儿剑,然后出去吃了冰淇淋。
对于动词,GPT-3也把握得很好,句子十分流畅。
语法纠错
GPT-3不仅能凭空生成文本,还可以给句子纠错。给出一句带语法错误的句子,让GPT-3修改:
Poor English input: The patient was died.
Good English output: The patient died.
原句的动词使用错误,多了一个was,GPT-3自动删除了该词,将其修改成语法正确、语义通顺的句子。再来看一个更难的例子:
Poor English input: Today I have went to the store to buys some many bottle of water.
Good English output:Today I went to the store to buy some bottles of water.
这里原句有两类错误:第一类是时态错误,GPT-3删除了句子中的have;第二类是单复数的错误,通过将buys改成buy、将some many bottle改为some bottles来纠正。GPT-3的纠错效果与基于专家规则的自动纠错系统相当,在句式复杂、时态混乱的语境下甚至可能有更好的表现。
除了原始论文中的例子,在OpenAI开放限量的GPT-3接口后,网友也纷纷尝试了其他有趣的任务,如让GPT-3写代码、设计网页UI,甚至有网友教会了GPT-3下棋、生成财务报表。而GPT-3在各个任务中均有可圈可点的表现,大大超乎了人们的想象,配合其巨大的模型和高昂的训练费用,GPT-3可谓是当时生成式预训练语言模型的天花板模型。
GPT-3的争议
树大招风的GPT-3在博得一片赞美的同时,也受到了来自国内外众多学者的质疑,他们理性地分析了GPT-3的缺陷。下文整理并总结了部分公认的观点,以便读者更全面地了解GPT-3。
- GPT-3不具备真正的逻辑推理能力:在问答任务中,若GPT-3收到的问题是“太阳有几只眼睛”,GPT-3会回答“太阳有一只眼睛”,即GPT-3并不会判断问题是否有意义,其回答是建立在大规模的语料训练基础上的,而不是经过逻辑推导得出的,无法给出超出训练语料范围的答案。
- GPT-3存在生成不良内容的风险:在生成文本时,由于训练语料来自互联网,含有种族歧视或性别歧视的语料无法被完全过滤,导致GPT-3生成的文本有一定概率会表达歧视和偏见,甚至在道德评判和专业法律方面也会犯错。
- GPT-3在高度程序化问题上表现不佳:GPT-3在STEM学科(Science、Technology、Engineering、Mathematics)上的问答表现较差,这是因为GPT-3更容易获得并记住陈述性知识,而不是理解知识。纽约大学副教授、游戏AI研究者Julian Togelius这样评价GPT-3:它就像一名没有认真复习的聪明学生,试图胡言乱语,以期在考试中蒙混过关。它会将一些已知事实和谎言进行串联,使其看起来像是流畅的叙述。
在GPT-3的输出可信度遭受质疑的同时,其庞大的参数量和高昂的训练费用也使它不能被广泛应用。即使如此,GPT-3曾经是最大、最好的预训练语言模型,它真正的意义在于揭开了通用人工智能面纱的一角。深度学习之父Geoffrey Hinton对GPT-3的评价如下:如果以GPT-3的优异性能推算未来,那么生命及世界万物只不过是4.398万亿个参数。随着深度学习的发展,若出现取代Transformer的模型结构,或者模型参数量级再扩大1000倍,也许真会出现能学会逻辑推理、学会思考的通用人工智能模型。
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.
[3] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[4] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[5] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[6] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[7] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.