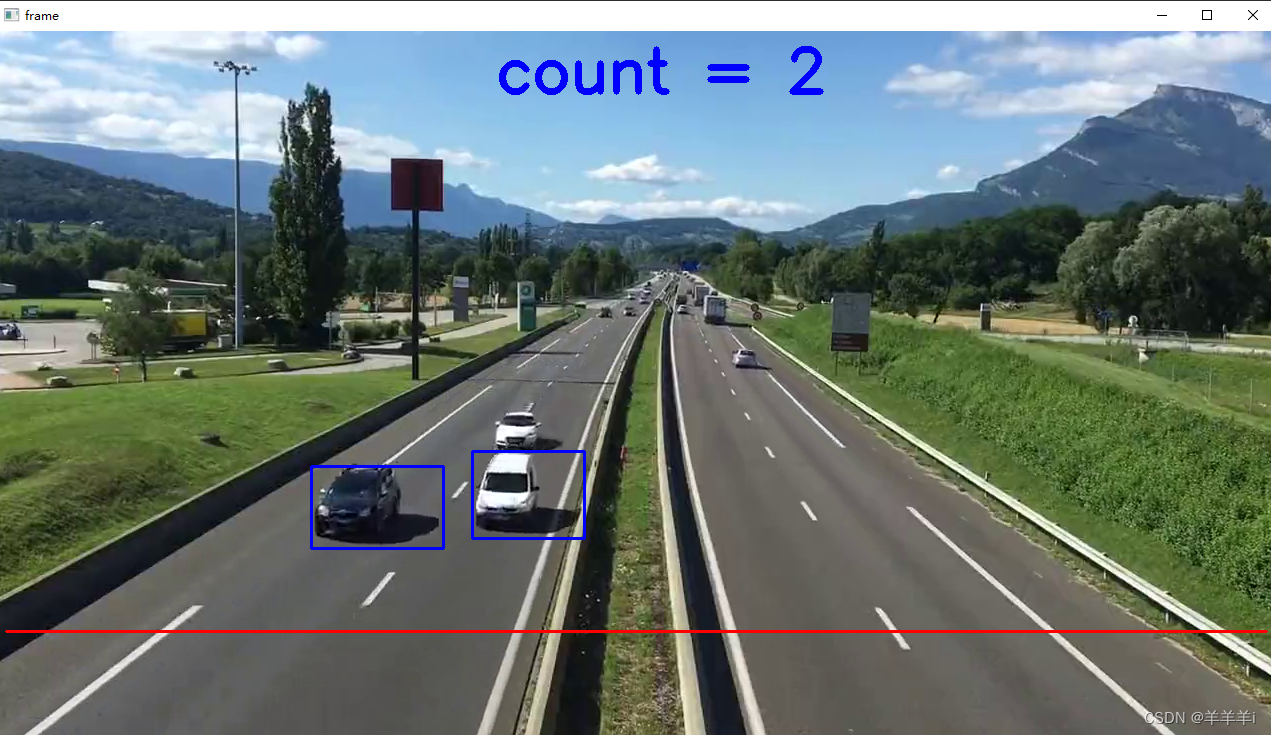
随着LLM(Large language models )的发展,不仅仅出现了很多新的应用,一些开发框架也发展很快,典型的就是本文介绍的项目——LangChain,目前LangChain几乎一天一个版本,几个月时间Star数目已经49k+。
LangChain是一个开源框架,能够把LLM的能力做为一个模块与其他能力组合,创造新的功能更强大的应用。
本文先阐述了LangChain解决的问题与背景,然后介绍LangChain中的基本概念,第三部分使用LangChain的python框架,用100行代码实现了一个简单的答疑机器人,通过此示例,能对LangChain的应用场景有个快速的认知。
1. 什么是LangChain
官方的表述:“Building applications with LLMs through composability”,LangChain的目的是为了开发应用,通过模块组合的方式使用LLM,并与其他模块组合的方式来创造应用。
使用LangChain的目的是Building applications ,下面从两个方面分析下在开发应用过程中LangChain能解决的问题,一是从一个框架的角度,也就是“连接”的角度,二是从对于目前LLM模型能力补充的角度,LangChain中不少设计也是针对于此。
1.1 LangChain让LLM这个大脑有了身体,并且能使用工具
LLM取得了快速发展,能够基于LLM实现新的功能更强大的应用,但如果只使用LLM的能力,能做的事情是非常有限的,典型的是看到的对话交互。LangChain能够连接LLM的能力与目前已有的其他能力,创造能力更强大的应用。有些类似于ChatGPT支持插件,但LangChain作为一个框架,把LLM抽象为一个模块,也就是说这个LLM的模式是可以替换的,比如集成公司自研的模型。
1.2 目前的LLM模型使用有不少限制,LangChain能力可以看作对LLM的补充
- 获取实时信息
- 获取私域信息
- 具备执行动作

训练的数据只到2021年,一些新的信息无法纳入。OpenAI不同模型的数据可以参考:OpenAI Models。解决这个问题,LangChain能够集成搜索引擎模块,在处理问题时,如果是最新的事件,通过搜索引擎来获取数据并分析。
context的token数量有限制
token指的是 OpenAI 处理文本的基本单位。例如,“hamburger” 被分成 “ham”、“bur” 和 “ger” 三个 Token,而 “pear” 是一个 Token。1个 Token 大约相当于 4 个字符或者 0.75 个英文单词。而且中文相对英文,使用的token更多(“你好,世界” 11个token,"Hello World"只有两个token),可以使用OpenAi提供的token分析器来分析,地址:https://platform.openai.com/tokenizer。
GPT3.5不同模型token为4k到8k,GPT4模型有8k和32k的tokens模型。不同模型的token可以参考:OpenAI Models,OpenAi的官方说明:What are tokens and how to count them?。
LangChain在一些场景下能部分解决这个问题,比如检索分析本地资源场景,通过本地构建embedding的库,搜索结果后,让LLM组织语言来回答。embedding简单可以理解为文本的向量化,向量化后能够让机器来计算文本的相似程度。在对话场景下,如果需要记录聊天记录,LangChain有专门的Memory模块来实现此能力。
2. LangChain的基本概念
本章节主要目的不是系统介绍LangChain中的概念,主要目的是能让未接触过LangChain的同学能有个快速认知,主要关注于Chain与Agent组件。学习一门技术最好的方式是阅读官方文档,学习LangChain也是,需要要系统学习,可以参考文档,LangChain的文档地址:🦜️🔗 LangChain | 🦜️🔗 LangChain。文档很好读,LangChain也不复杂,看Twitter上分享,很多同学都按耐不住,学学python,自己动手造AI应用。
LangChain中主要的Components目前主要有:Schema、Models、Prompts、Indexes、Memory、Chain、Agent,参考:Components | 🦜️🔗 LangChain,其中核心的概念是Chain与Agent,本章节主要围绕着两个概念展开。
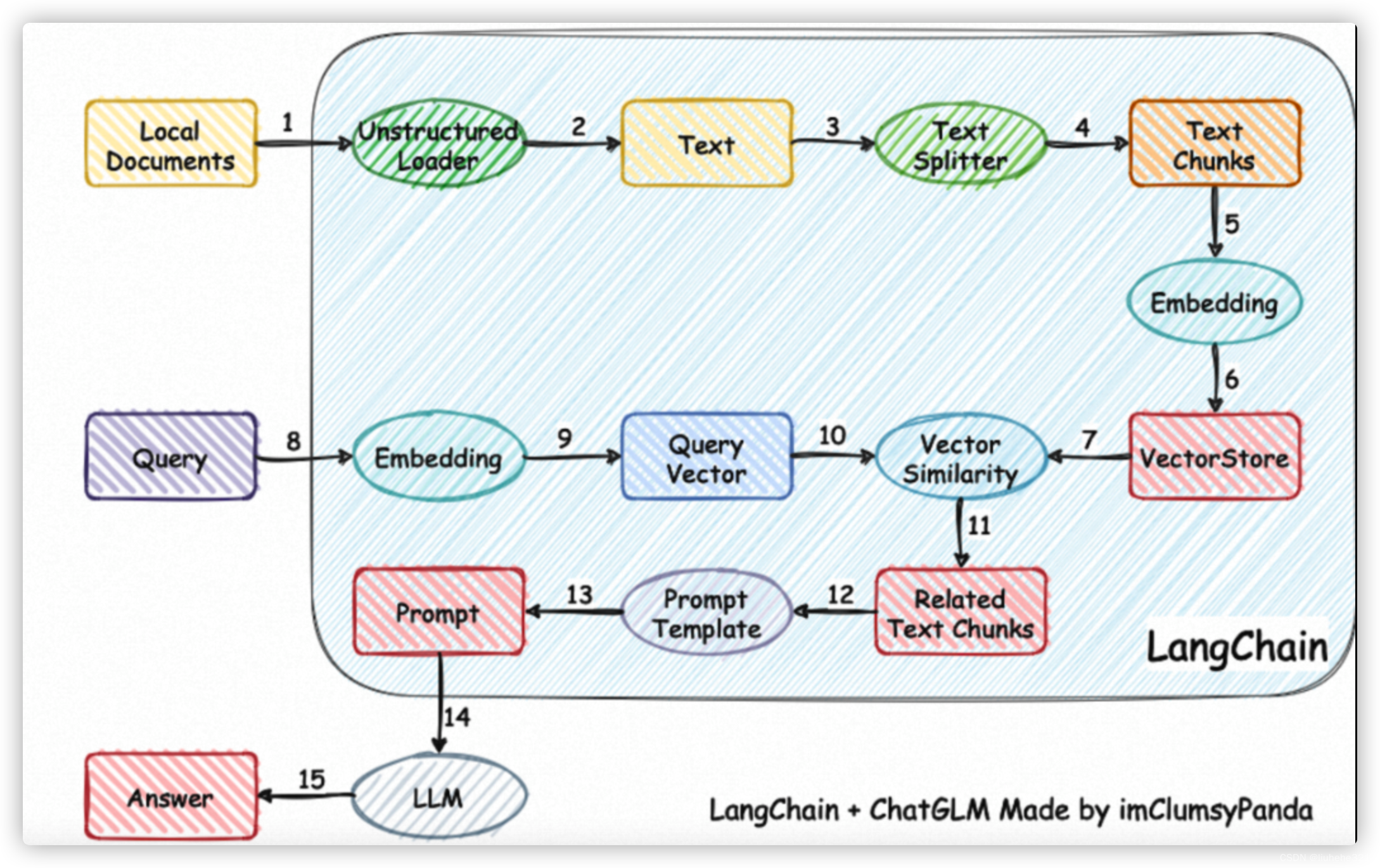
一种利用 ChatGLM-6B + langchain 实现的基于本地知识的 ChatGLM 应用。增加 clue-ai/ChatYuan 项目的模型 ClueAI/ChatYuan-large-v2 的支持。其整体流程如下图。








![[进阶]网络通信:TCP通信,一发一收,多发多收](https://img-blog.csdnimg.cn/51572d1a0f644d86929f02bfbd2f8de8.png)