【openGauss高级数据管理】--略有小成
- 🔻 一、openGauss高级数据管理
- 🔰 1.1 约束
- ⛳ 1.1.1 NOT NULL约束
- ⛳ 1.1.2 UNIQUE约束
- ⛳ 1.1.3 PRIMARY KEY
- ⛳ 1.1.4 FOREIGN KEY
- ⛳ 1.1.5 CHECK约束
- 🔰 1.2 JOIN
- ⛳ 2.3.1 CROSS JOIN---交叉连接
- ⛳ 1.2.1 INNER JOIN---内连接
- ⛳ 1.2.2 LEFT OUTER JOIN---左外连接
- ⛳ 1.2.3 RIGHT OUTER JOIN---右外连接
- ⛳ 1.2.4 FULL OUTER JOIN---全外连接
- 🔰 1.3 NULL值
- 🔰 1.4 UNION与UNION ALL
- 🔰 1.5 别名
- 🔰 1.6 索引
- 🔰 1.7 批处理模式
- 🔰 1.8 视图
- 🔰 1.9 SCHEMA
- 🔰 1.10 TRUNCATE TABLE语句
- 🔰 1.11 事务
- 🔰 1.12 游标
- 🔰 1.13 分区表
- 🔰 1.14 锁
- 🔰 1.15 匿名块
- 🔰 1.16 触发器
- 🔰 1.17 存储过程
- 🔰 1.18 物化视图
- 🔰 1.19 权限
- ⛳ 1.19.1 GRANT授权
- ⛳ 1.19.2 REVOKE回收权限
- 🔻 二、总结—温故知新

| 👈【上一篇】 |
💖The Begin💖 点点关注,收藏不迷路💖
| 【下一篇】👉 |
🔻 一、openGauss高级数据管理
🔰 1.1 约束
约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)。
约束可以是列级或表级。列级约束仅适用于列,表级约束被应用到整个表。
⛳ 1.1.1 NOT NULL约束
创建表时,如果不指定约束,默认值为NULL,即允许列插入空值。
在列上定义NOT NULL约束,则不能插入NULL值。
NULL----代表着未知的数据,与没有数据是不一样的。
⛳ 1.1.2 UNIQUE约束
UNIQUE约束表示表里的一个字段或多个字段的组合必须在全表范围内唯一,不能插入两条一样的数据。
对于唯一约束,NULL被认为是互不相等的。
⛳ 1.1.3 PRIMARY KEY
PRIMARY KEY为主键,是数据表中每一条记录的唯一标识。
主键约束声明表中的一个或者多个字段只能包含唯一的非NULL值。
主键是非空约束和唯一约束的组合。一个表只能声明一个主键。
⛳ 1.1.4 FOREIGN KEY
FOREIGN KEY即外键约束,指定列(或一组列)中的值必须匹配另一个表的某一行中出现的值。
一个表中的FOREIGN KEY指向另一个表中的 UNIQUE KEY(唯一约束的键),即维护了两个相关表之间的引用完整性。
⛳ 1.1.5 CHECK约束
CHECK约束声明一个布尔表达式,每次要插入的新行或者要更新的行的新值必须使表达式结果为真或未知才能成功,否则会抛出一个异常并且不会修改数据库。
检查约束只引用该字段的数值。
🔰 1.2 JOIN
⛳ 2.3.1 CROSS JOIN—交叉连接
交叉连接即笛卡儿乘积,是指两个关系中所有元组的任意组合。
###🍀将表t_user 和表t_dept进行交叉连接🍀###
SELECT * FROM t_user CROSS JOIN t_dept;
⛳ 1.2.1 INNER JOIN—内连接
内连接是一种最常用的连接类型,也是默认的连接类型。
如果两个表的相关字段满足连接条件,只有满足条件的元组才能出现在结果关系中。
###🍀将表t_user 和表t_dept进行内连接🍀###
SELECT * FROM t_user a INNER JOIN t_dept b ON a.dept_id = b.id;
⛳ 1.2.2 LEFT OUTER JOIN—左外连接
左外连接是指在连接查询中,将关键字左端表中所有的元组都列出来,如果能在右端的表中找到匹配的元组,显示匹配元组内容。如果在右端的表中,不能找到匹配的元组,那么对应的元组是空值(NULL)。
###🍀将表t_user 和表t_dept进行左外连接🍀###
SELECT * FROM t_user a LEFT OUTER JOIN t_dept b ON a.dept_id = b.id;
⛳ 1.2.3 RIGHT OUTER JOIN—右外连接
右外连接与左外连接类似,只是关键字右端表中的所有元组都列出,右端表中的数据无论是否满足连接条件,均输出表中的内容。
###🍀将表t_user 和表t_dept进行右外连接🍀###
SELECT * FROM t_user a RIGHT OUTER JOIN t_dept b ON a.dept_id = b.id;
⛳ 1.2.4 FULL OUTER JOIN—全外连接
全外连接查询的特点是左、右两端表中的元组都输出,如果没能找到匹配的元组,就使用NULL来代替。
###🍀将表t_user 和表t_dept进行全外连接🍀###
SELECT * FROM t_user a FULL OUTER JOIN t_dept b ON a.dept_id = b.id;
🔰 1.3 NULL值
NULL值代表未知、不确定的数据,NULL和0、"NULL"是不等价的。
🔰 1.4 UNION与UNION ALL
UNION:结果中如果出现相同的值,仅保留一个。
UNION ALL:显示所有结果,包括重复的值。
🔰 1.5 别名
SQL可以重命名一张表或者一个字段的名称,这个名称为该表或该字段的别名。
创建别名是为了让表名或列名的可读性更强。SQL中使用AS来创建别名。
###🍀用u表示表t_user 的别名,查询表内数据。🍀###
SELECT u.id,u.username FROM t_user AS u;
🔰 1.6 索引
索引是一个指向表中数据的指针。一个数据库中的索引与一本书的索引目录是非常相似的。
索引可以用来提高数据库查询性能,但是不恰当的使用将导致数据库性能下降。建议仅在匹配如下某条原则时创建索引:
🎐 1、经常执行查询的字段。
🎐2、在连接条件上创建索引,对于存在多字段连接的查询,建议在这些字段上建立组合索引。例如,select * from t1 join t2 on t1.a=t2.a and t1.b=t2.b,可以在t1表上的a,b字段上建立组合索引。
🎐3、WHERE子句的过滤条件字段上(尤其是范围条件)。
🎐4、经常出现在ORDER BY、GROUP BY和DISTINCT后的字段。
###🍀1、单列索引---只基于表的一个列上创建的索引🍀###
###在表t_user上的id字段上创建名为t_user_index0 的单列索引
CREATE INDEX t_user_index0 ON t_user(id);
###🍀2、组合索引---基于表的多列上创建的索引🍀###
###在表t_user上的id,dept_id字段上创建名为t_user_index2 的组合索引
CREATE INDEX t_user_index2 ON t_user(id,dept_id);
###🍀3、唯一索引---指定唯一索引的字段不允许重复值插入🍀###
###在表t_user上的id字段上创建名为t_user_index3 的唯一索引
CREATE UNIQUE INDEX t_user_index3 ON t_user(id);
###🍀4、局部索引---在表的子集上构建索引,子集由一个条件表达式定义。🍀###
###在表t_user上的username字段上创建名为t_user_index4 的局部索引,SUBSTR(username,1 ,3)-----截取名字前三字符
CREATE INDEX t_user_index4 ON t_user(SUBSTR(username,1 ,3));
###🍀5、部分索引---部分索引是一个只包含表的一部分记录的索引,通常是该表中比其他部分数据更有用的部分🍀###
###在表t_user上的id字段上创建名为t_user_index5 的部分索引,---id大于10的数据
WHERE SM_SHIP_MODE_SK>10;
###🍀6、删除索引🍀###
DROP INDEX 索引名;
如,删除名称为t_user_index5的索引
DROP INDEX t_user_index5;
🔰 1.7 批处理模式
openGauss支持从文本文件执行SQL语句。openGauss提供了gsql工具实现SQL语句的批量处理。
###🍀语法格式🍀###
gsql -d 数据库名称 -p 端口号 -f 文件名
如:在t_user中批量插入数据
su - omm
[omm@klgdj ~]$ cd /home/
[omm@klgdj home]$ ll
总用量 4
drwx------ 10 omm dbgrp 216 6月 18 17:56 omm
-rw-r--r-- 1 root root 649 6月 21 23:37 t_user.txt
[omm@klgdj home]$ gsql -d db_test01 -p 15400 -f /home/t_user.txt
INSERT 0 1
INSERT 0 1
INSERT 0 1
INSERT 0 1
INSERT 0 1
INSERT 0 1
INSERT 0 1
total time: 6 ms
[omm@klgdj home]$
如:在/home路径下创建t_user.txt文件,
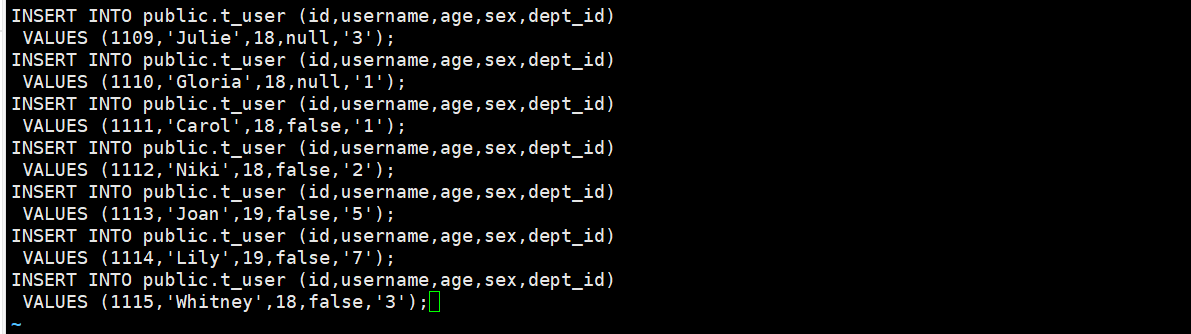
🔰 1.8 视图
视图与基本表不同,是一个虚拟的表。
数据库中仅存放视图的定义,而不存放视图对应的数据,这些数据仍存放在原来的基本表中。若基本表中的数据发生变化,从视图中查询出的数据也随之改变。
从这个意义上讲,视图就像一个窗口,透过它可以看到数据库中用户感兴趣的数据及变化。
###🍀创建视图🍀###
CREATE [ TEMP | TEMPORARY ] VIEW view_name [ ( column_name [, ...] ) ],其中TEMP | TEMPORARY ---为创建临时视图
AS query;
###在t_user表创建名为USER_VIEW 的视图,视图只从t_user表中选取id,name:
CREATE VIEW USER_VIEW AS SELECT id, username FROM t_user;
###🍀使用视图🍀###
###从上面USER_VIEW 视图中查询数据,与查询表的方式类似
SELECT * FROM USER_VIEW;
###🍀删除视图🍀###
DROP VIEW view_name ;
###删除刚才创建的USER_VIEW 视图
🔰 1.9 SCHEMA
SCHEMA又称作模式。通过管理SCHEMA,允许多个用户使用同一数据库而不相互干扰,可以将数据库对象组织成易于管理的逻辑组,同时便于将第三方应用添加到相应的SCHEMA下而不引起冲突。
每个数据库包含一个或多个SCHEMA。数据库中的每个SCHEMA包含表和其他类型的对象。数据库创建初始,默认具有一个名为PUBLIC的SCHEMA。
SCHEMA类似于操作系统目录,但SCHEMA不能嵌套。
通过CREATE USER创建用户的同时,系统会在执行该命令的数据库中,为该用户创建一个同名的SCHEMA。
###🍀创建SCHEMA🍀###
CREATE SCHEMA schema_name
[ AUTHORIZATION user_name ] ;
###创建一个zyl01用户
CREATE USER zyl01 IDENTIFIED BY 'zyl01#2023';
###根据用户名创建模式,指定模式的所有者。当不指定schema_name时,把user_name当作模式名,此时user_name只能是角色名。
CREATE SCHEMA test AUTHORIZATION zyl01;
###🍀修改模式名称🍀###
ALTER SCHEMA test RENAME TO test1;
###🍀修改模式的所有者🍀###
ALTER SCHEMA test1 OWNER TO zyl02;
###🍀查看当前搜索路径上的模式🍀###
db_test01=# SHOW SEARCH_PATH;
search_path
----------------
"$user",public
(1 row)
###🍀更改当前会话的默认Schema🍀###
SET SEARCH_PATH TO zyl02, public;
###🍀删除SCHEMA及其对象🍀###
DROP SCHEMA test1;
注意--关于openGauss数据的模式:
❗ 1、不要随意删除pg_temp或pg_toast_temp开头的模式,这些模式是系统内部使用的,如果删除,可能导致无法预知的结果。
❗ 2、模式名不能和当前数据库里其他的模式重名。 模式的名称不可以“pg_”开头。
🔰 1.10 TRUNCATE TABLE语句
TRUNCATE TABLE用于删除表的数据(慎用),但不删除表结构。也可以用DROP TABLE删除表(慎用),但是这个命令会连表的结构一起删除,如果想插入数据,需要重新建立这张表。
TRUNCATE不做表扫描,因而快得多。在大表上操作效果更明显。
TRUNCATE TABLE 可以立即释放表空间,而不需要后续 VACUUM 操作。
###🍀语法格式---清除表数据🍀###
TRUNCATE TABLE 需要删除数据的表名;
###🍀语法格式---删除表机构和数据🍀###
DROP TABLE 需要删除数据/结构的表名;
❗❗❗❗❗❗❗❗❗慎用这两个命令❗❗❗❗❗❗❗❗❗❗
🔰 1.11 事务
事务是用户定义的一个数据库操作序列,这些操作要么全做要么全不做,是一个不可分割的工作单位。
openGauss数据库支持的事务控制命令有启动、设置、提交、回滚事务。
openGauss数据库支持的事务隔离级别有读已提交(READ COMMITTED)和可重复读(REPEATABLE READ)。
###💯 开启一个事务,并从t_user表中删除id为1101的行,
最后使用ROLLBACK命令撤销所有的更改。
###1、开启一个事务
START TRANSACTION;
###2、删除t_user表中id为1101的行
DELETE FROM t_user WHERE id = 1101;
###3、回滚事务
ROLLBACK;
###4、查询id = 1101的数据,数据恢复
SELECT * FROM t_user WHERE id = 1101;
###💯 开启另一个事务,并从t_user表中删除id为1101的行,
最后使用COMMIT命令提交所有的更改。最后使用ROLLBACK命令撤销所有的更改。🍀###
###1、开启另一个事务
BEGIN;
###2、删除t_user表中id为1101的行
DELETE FROM t_user WHERE id = 1101;
###3、提交当前事务,让所有当前事务的更改为其他事务可见
COMMIT;
###4、回滚事务,不能恢复已提交的更改
ROLLBACK;
###5、查询id = 1101的数据,数据为空
SELECT * FROM t_user WHERE id = 1101;
🔰 1.12 游标
为了处理SQL语句,存储过程进程分配一段内存区域来保存上下文联系。
游标是指向上下文区域的句柄或指针。借助游标,存储过程可以控制上下文区域的变化。
###🍀定义游标语法格式🍀###
CURSOR cursor_name
[ BINARY ] [ NO SCROLL ] [ { WITH | WITHOUT } HOLD ]
FOR query ;
###🍀通过已经创建的游标检索数据🍀###
FETCH [ direction { FROM | IN } ] cursor_name;
###🍀关闭游标,释放和一个游标关联的所有资源🍀###
CLOSE { cursor_name | ALL } ;
###💯 用一个游标读取一个表
###1、开始一个事务
START TRANSACTION;
###2、建立一个名为cursor1的游标,从t_user查询数据
CURSOR cursor1 FOR SELECT * FROM t_user;
###3、抓取前3行到游标cursor1里
FETCH FORWARD 3 FROM cursor1;
###4、关闭游标并提交事务
CLOSE cursor1;
###5、结束事务
END;
###💯 用一个游标读取一个表
###1、开始一个事务
START TRANSACTION;
###2、建立一个名为cursor1的游标,从t_user查询数据
CURSOR cursor1 FOR SELECT * FROM t_user;
###3、抓取前3行到游标cursor1里
FETCH FORWARD 3 FROM cursor1;
###4、关闭游标并提交事务
CLOSE cursor1;
###5、结束事务
END;
🔰 1.13 分区表
一张表内的数据过多时,就会严重影响到数据的查询和操作效率。
openGauss支持把一张表从逻辑上分成多个小的分片,从而避免一次处理大量数据,提高处理效率。
🌴 1、
范围分区表:指定一个或多个列划分为多个范围,每个范围创建一个分区,用来存储相应的数据。例如可以采用日期划分范围,将销售数据按照月份进行分区。
🌴 2、列表分区表:直接按照一个列上的值来划分出分区。例如可以采用销售门店划分销售数据。
🌴 3、间隔分区表:是一种特殊的范围分区,新增了间隔值定义。当插入记录找不到匹配的分区时可以根据间隔值自动创建分区。
🌴 4、哈希分区表:根据表的一列,为每个分区指定模数和余数,将要插入表的记录划分到对应的分区中。
分区表的操作除了创建之外还有:
🌴 1、
查询分区表:按照分区名或者分区中的值查询数据。
导入数据:直接导入数据或从现有表格中导入。
🌴 2、修改分区表:包括增加分区、删除分区、切割分区、合并分区,以及修改分区名称等。
🌴 3、删除分区表:与删除普通表格相同
示例1:创建范围分区表sales_table,含有4个分区,分区键为DATE类型。分区的范围分别为:sales_date<2021-04-01,2021-04-01<= sales_date<2021-07-01,2021-07-01<=sales_date< 2021-10-01,2021-10-01 <= sales_date< MAXVALUE。
###💯 创建VALUES LESS THAN范围分区表示例
openGauss=# CREATE TABLE sales_table
(
order_no INTEGER NOT NULL,
goods_name CHAR(20) NOT NULL,
sales_date DATE NOT NULL,
sales_volume INTEGER,
sales_store CHAR(20)
)
PARTITION BY RANGE(sales_date)
(
PARTITION season1 VALUES LESS THAN('2021-04-01 00:00:00'),
PARTITION season2 VALUES LESS THAN('2021-07-01 00:00:00'),
PARTITION season3 VALUES LESS THAN('2021-10-01 00:00:00'),
PARTITION season4 VALUES LESS THAN(MAXVALUE)
);
###2、
-- 数据插入分区season1
openGauss=# INSERT INTO sales_table VALUES(1, 'jacket', '2021-01-10 00:00:00', 3,'Alaska');
-- 数据插入分区season2
openGauss=# INSERT INTO sales_table VALUES(2, 'hat', '2021-05-06 00:00:00', 5,'Clolorado');
-- 数据插入分区season3
openGauss=# INSERT INTO sales_table VALUES(3, 'shirt', '2021-09-17 00:00:00', 7,'Florida');
-- 数据插入分区season4
openGauss=# INSERT INTO sales_table VALUES(4, 'coat', '2021-10-21 00:00:00', 9,'Hawaii');
###3、查询分区表--查询sales_table的数据
SELECT * FROM sales_table;
关于openGauss分区表的具体用法-----openGauss分区表
🔰 1.14 锁
如果需要保持数据库数据的一致性,可以使用LOCK TABLE来阻止其他用户修改表。
例如,一个应用需要保证表中的数据在事务的运行过程中不被修改。为实现这个目的,则可以对表使用进行锁定。这样将防止数据不被并发修改。
LOCK TABLE只在一个事务块的内部有用,在事务结束时就会被释放。
锁的模式:
ACCESS EXCLUSIVE-------这个模式保证其所有者(事务)是可以访问该表的唯一事务。也是缺省锁模式。
ACCESS SHARE-------------只读取表而不修改的锁模式。
###🍀语法格式🍀###
LOCK [ TABLE ] name IN lock_mode MODE
###在执行删除操作时对db_test01 表进行ACCESS EXCLUSIVE锁
LOCK TABLE db_test01 IN ACCESS EXCLUSIVE MODE;
--启动进程。
openGauss=# START TRANSACTION;
--给示例表格。
openGauss=# LOCK TABLE graderecord IN ACCESS EXCLUSIVE MODE;
--删除示例表格。
openGauss=# DELETE FROM graderecord WHERE name ='Alan';
openGauss=# COMMIT; ----提交完,锁即释放
🔰 1.15 匿名块
==匿名块(Anonymous Block)==是存储过程的字块之一,没有名称。一般用于不频繁执行的脚本或不重复进行的活动。
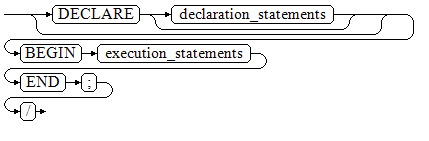
🌳1、匿名块程序实施部分,以BEGIN语句开始,以END语句停顿,以一个分号结束。输入“/”按回车执行它。
🌳 2、最后的结束符“/”必须独占一行,不能直接跟在END后面。
🌳3、声明部分包括变量定义、类型、游标定义等。
🌳4、最简单的匿名块不执行任何命令。但一定要在任意实施块里至少有一个语句,甚至是一个NULL语句。
###💯 匿名块
###1、空语句块
openGauss=# BEGIN
NULL;
END;
/
###2、用匿名块在t_user表中插入一行数据
openGauss=# BEGIN
insert into table1 values(1,2,3);
END;
/
🔰 1.16 触发器
触发器会在指定的数据库事件发生时自动执行函数。
###🍀创建触发器语法格式🍀###
CREATE TRIGGER trigger_name { BEFORE | AFTER | INSTEAD OF } { event [ OR ... ] }
ON table_name
[ FOR [ EACH ] { ROW | STATEMENT } ]
[ WHEN ( condition ) ]
EXECUTE PROCEDURE function_name ( arguments );
###🍀修改触发器语法格式🍀###
ALTER TRIGGER trigger_name ON table_name RENAME TO new_trigger_name;
###🍀删除触发器语法格式🍀###
DROP TRIGGER trigger_name ON table_name [ CASCADE | RESTRICT ];
###💯 使用触发器,在t_user表插入数据时,同时在t_user_02插入
###1、创建触发器函数
CREATE OR REPLACE FUNCTION tri_insert_func() RETURNS TRIGGER AS
$$
DECLARE
BEGIN
INSERT INTO t_user_02 VALUES(NEW.id, NEW.username, NEW.age,NEW.sex,NEW.dept_id);
RETURN NEW;
END
$$ LANGUAGE PLPGSQL;
###2、创建INSERT触发器
CREATE TRIGGER insert_trigger
BEFORE INSERT ON t_user
FOR EACH ROW
EXECUTE PROCEDURE tri_insert_func();
###3、执行INSERT触发事件并检查触发结果
1、在表t_user 插入一条数据,会自动在t_user_02 添加一条同样的数据
INSERT INTO t_user (id,username,age,sex,dept_id)
VALUES (111222,'Whitney',18,false,'3');
select * from t_user_02;
select * from t_user;
###🍀修改触发器🍀###
###将上面创建的insert_trigger 触发器改为insert_trigger_t_user
ALTER TRIGGER insert_trigger ON t_user RENAME TO insert_trigger_t_user;
###🍀删除触发器🍀###
DROP TRIGGER 触发器名 ON 表名;
###将上面更名过的的insert_trigger_t_user 触发器删除
DROP TRIGGER insert_trigger_t_user ON t_user;
🔰 1.17 存储过程
存储过程是能够完成特定功能的SQL语句集。用户可以进行反复调用,从而减少SQL语句的重复编写数量,提高工作效率。
###🍀语法格式--创建存储过程🍀###
CREATE PROCEDURE procedure_name
[ ( {[ argname ] [ argmode ] argtype [ = expression ]}[,...]) ]
{ IS | AS }
BRGIN
procedure_body
END
/
###🍀语法格式--调用存储过程🍀###
CALL procedure_name ( param_expr );
###🍀语法格式--删除存储过程🍀###
DROP PROCEDURE procedure_name ;
###💯 创建、调用一个t_user表的insert存储过程
###🍀1、定义存储过程🍀###
CREATE PROCEDURE insert_data (id INT, username VARCHAR(255),age INT,sex boolean,dept_id INT)
IS
BEGIN
INSERT INTO t_user VALUES(param1,param2,param3,param4);
END;
/
###🍀2、调用存储过程🍀###
CALL insert_data(id:=210101,username:='Alan',age:=19,sex:=NULL,dept_id:=3);
###🍀3、删除存储过程🍀###
DROP PROCEDURE insert_data;
🔰 1.18 物化视图
物化视图是相对普通视图而言的。普通视图是虚拟表,而物化视图实际上就是存储SQL执行语句的结果,可以直接使用数据而不用重复执行查询语句,从而提升性能。
🌳1、
全量物化视图:仅支持对已创建的物化视图进行全量更新,而不支持进行增量更新。创建全量物化视图语法和CREATE TABLE AS语法类似。
🌳2、增量物化视图:可以对物化视图增量刷新,需要用户手动执行语句完成对物化视图在一段时间内的增量数据刷新。与全量创建物化视图的不同在于目前增量物化视图所支持场景较小。目前物化视图创建语句仅支持基表扫描语句或者UNION ALL语句
全量物化视图:
###🍀创建全量物化视图🍀###
CREATE MATERIALIZED VIEW view_name AS query;
###🍀全量刷新物化视图🍀###
REFRESH MATERIALIZED VIEW [ view_name ];
###🍀删除物化视图🍀###
DROP MATERIALIZED VIEW [ view_name ];
###🍀查询物化视图🍀###
SELECT * FROM [ view_name ];
###💯 全量物化视图示例
###🍀创建表t_user全量物化视图🍀###
CREATE MATERIALIZED VIEW t_user_mv AS select count(*) from t_user;
###🍀查询物化视图结果---如结果返回15条🍀###
SELECT * FROM t_user_mv ;
###🍀向物化视图的基表中插入1条数据🍀###
INSERT INTO public.t_user (id,username,age,sex,dept_id)
VALUES (113344,'Whitney',18,false,'3');
###🍀对全量物化视图做全量刷新,如果不刷新,查询物化视图还是15条,刷新之后变为16条🍀###
REFRESH MATERIALIZED VIEW t_user_mv ;
###🍀查询物化视图结果----变为16条🍀###
SELECT * FROM t_user_mv ;
###🍀删除物化视图🍀###
DROP MATERIALIZED VIEW t_user_mv ;
增量物化视图
###🍀创建增量物化视图🍀###
CREATE INCREMENTAL MATERIALIZED VIEW view_name AS query ;
###🍀增量刷新物化视图🍀###
REFRESH INCREMENTAL MATERIALIZED VIEW [ view_name ];
###🍀删除物化视图🍀###
DROP MATERIALIZED VIEW [ view_name ];
###🍀查询物化视图🍀###
SELECT * FROM [ view_name ];
###💯 增量物化视图示例
###🍀创建表t_user增量物化视图🍀###
CREATE INCREMENTAL MATERIALIZED VIEW t_user_mv2 AS SELECT * from t_user;
###🍀查询物化视图结果---16条数据🍀###
SELECT count(*) FROM t_user_mv2 ;
###🍀向物化视图的基表中插入1条数据🍀###
INSERT INTO public.t_user (id,username,age,sex,dept_id)
VALUES (113355,'tony',18,false,'3');
###🍀增量刷新物化视图---17条数据🍀###
REFRESH INCREMENTAL MATERIALIZED VIEW t_user_mv2;
###🍀删除物化视图🍀###
DROP MATERIALIZED VIEW t_user_mv2;
🔰 1.19 权限
数据库对象创建后,进行对象创建的用户就是该对象的所有者。
默认只有对象所有者或者系统管理员可以查询、修改和销毁对象,以及通过GRANT将对象的权限授予其他用户。
⛳ 1.19.1 GRANT授权
只有系统管理员有权执行GRANT ALL PRIVILEGES。
GRANT命令进行用户授权的三种场景:
###🌳1、将系统权限(例如sysadmin、CREATEDB、CREATEROLE等)授权给角色或用户###
db_test01=# GRANT ALL PRIVILEGES TO zyl;
ALTER ROLE
db_test01=#
###🍀或者可以在创建用户时分配权限
CREATE USER zyl01 WITH CREATEDB PASSWORD "zyl01#123";
###🍀查看用户具有的权限
\du 用户名/角色
db_test01=# \du zyl
List of roles
Role name | Attributes | Member of
-----------+------------+-----------
zyl | Sysadmin | {}
db_test01=#
###🍀查看所有角色及角色权限
db_test01=# \dg
List of roles
Role name | Attributes | Member of
-----------+------------------------------------------------------------------------------------------------------------------+-----------
omm | Sysadmin, Create role, Create DB, Replication, Administer audit, Monitoradmin, Operatoradmin, Policyadmin, UseFT | {}
test | | {}
zyl | Sysadmin | {}
zyl01 | | {}
zyl02 | | {}
db_test01=#
###🌳2、将角色或用户的权限授权给其他角色或用户###---其中WITH ADMIN OPTION表示允许该角色将权限授权给其他人
db_test01=# GRANT zyl TO zyl02;
db_test01=# GRANT zyl TO zyl01 WITH ADMIN OPTION;
###🌳3、将数据库对象授权给角色或用户###将t_user表的增删改查权限授权给zyl用户,
##其中WITH GRANT OPTION表示拥有将这些权限授权给其他用户的权限。
GRANT select,update,insert,delete ON t_user TO zyl WITH GRANT OPTION;
⛳ 1.19.2 REVOKE回收权限
撤销角色或用户的系统权限(例如sysadmin、CREATEDB、CREATEROLE等)。
###🍀撤销zyl用户所有权限
db_test01=# REVOKE ALL PRIVILEGES FROM zyl;
###🍀把用户zyl对t_user 表的select,update,insert,delete权限收回
REVOKE select,update,insert,delete ON t_user from zyl CASCADE;
🔻 二、总结—温故知新
❓ openGauss数据库---有关约束了解及使用
❓ openGauss数据库---有关5个连接查询
❓ openGauss数据库---视图、模式、事务、游标、分区表、锁、触发器、存储过程等使用和了解
❓ openGauss数据库---用户、角色授权以及权限回收
| 👈【上一篇】 |
💖The End💖 点点关注,收藏不迷路💖
| 【下一篇】👉 |