TDEngine 调优 - 高速查询及插入
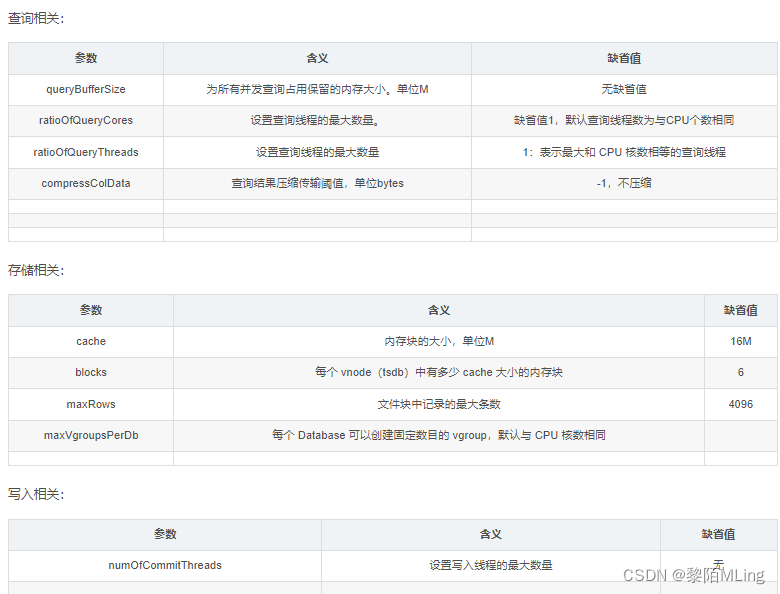
- 一、基本参数
- 二、TDEngine大数据核心
- 2.1 vnode分片
- 2.1.1 表分布不均匀
- 2.1.2 vnode分布不均匀
- 2.2 时间段分区
- 三、数据库性能优化
- 3.1 数据文件
- 3.1.1 maxrows 和 minrows
- 3.1.2 数据的保留策略duration\days
- 3.2 磁盘IO - vgroups
- 3.3 性能优化实战
- 3.3.1 示例 - 场景描述
- 3.3.2 示例场景现有情况
- 3.3.3 场景分析
- 3.3.4 场景升级
- 3.3.4.1 升级操作
- 3.3.4.2 查询效率分析
- 四、写入优化

回到目录 回到末尾
参考文档:
1、【TDEngine 数据库实现解析】
2、【官网- TDengine架构设计与存储结构】
3、【TDEngine知识体系】
一、基本参数
回到目录 回到末尾
二、TDEngine大数据核心
TDengine是通过vnode分片以及时间段分区两个维度,对大数据进行切分,便于并行高效的管理,实现水平扩展。
2.1 vnode分片
详情可参考:这几个神秘参数,教你TDengine集群的正确使用方式
建议先到官网查看:TDEngine官网-数据模型和整体架构
每个 vnode 都是一个相对独立的工作单元,是存储时序数据(表)的基本单元,具有独立的运行线程、内存空间与持久化存储的路径。
通常来说,数据分配不均匀有两种:表分布不均匀和vnode分布不均匀。
2.1.1 表分布不均匀
示例 - 场景一:
需要测试表数量很少的数据库性能时比较容易发生这个现象:你建了1200张表,但是却发现有1000张表都在同一个vnode里面,只有200张表在另一个vnode里面。这种场景的坏处是,大部分表都进入了同一个vnode数据分布不均匀。此外还会导致只有两个线程在为TDengine工作,因此无法利用计算机的多核(假设你的服务器CPU是双核以上),从而浪费了TDengine的横向扩展性。
在持续的建表过程中,TDengine就是靠maxVgroupsPerDb、minTablesPerVnode、tablelncStepPerVnode这三个参数来控制表的分布的。
- maxVgroupsPerDb: 每个数据库中能够使用的最大vnode个数(单个副本),默认为0(自动配置);
- minTablesPerVnode: 每个vnode中必须创建的最小表数,即是说这是第一轮建表用的步长(就是满多少表写下一个vnode),默认1000;
- tablelncStepPerVnode:每个vnode中超过最小表数后的递增步长(即是后续满多少表写下一个vnode),默认1000。
大家可以在使用taosdemo批量建表的时候观察一下:打开另一个taos窗口,在建表的时候一直输入show vgroups命令,就能看到上述参数所控制的建表过程了:在第一个vnode中,表数量从0开始逐渐递增,随着数量达到minTablesPerVnode后,开始创建下一个vnode并继续在其中建表。之后,重复该过程直到vnode数量达到maxVgroupsPerDb。之后,TDengine将回到第一个vnode继续创建新表,在补充每个vnode的表数达到tablelncStepPerVnode数量后,后续以tablelncStepPerVnode为步长继续在vnode中依次创建表,直到建完全部表。
在taos.cfg中maxVgroupsPerDb这个参数的值默认是0,根据参数描述,0代表的是自动配置。自动配置的详情为:“每个 Database 可以创建固定数目的 vgroup,默认与 CPU 核数相同,可通过 maxVgroupsPerDb 配置”。
假设我们是4核服务器,那么默认的最大vgroups就是为4个。进入场景一当中,每个vnode只要存储300个表就好了。这时候只需要调整minTablesPerVnode值为300,这样就可以做到表均匀分布在数据节点中了。
场景一属于相对特殊的情况,而默认配置却只能针对最通用的一个场景。对于大部分用户来说,只要你的测试场景是创建万表级别,都是可以看到表在vnode中按序且平均分配的。比如你有一台4核CPU的机器,计划创建4万个表。那么使用默认配置就会生成4个vnode,最终的结果就是每个vnode存储1万张表,就不会出现数据不均的现象了。

回到目录 回到末尾
2.1.2 vnode分布不均匀
示例 - 场景二:
在批量创建完很多表后,有时候你可能会发现:“咦?为什么这个数据节点上有6个vnode,另外一个节点只有2个vnode。”
这种情况需要了解管理节点(mnode)。mnode和vnode一样,都是以master-slave的模式分布在节点中的。

因此,在做数据的负载均衡的时候,mnode也会是被计算在内的,而具体的计算方式就是,一个mnode等价于n个vnode,这个n就是由下面这个参数控制的。

回到目录 回到末尾
2.2 时间段分区
详情可参考:TDengine时序数据的保留策略
TDEngine3.x后,days改为了duration
TDengine除vnode分片之外,还对时序数据按照时间段进行分区。每个数据文件只包含一个时间段的时序数据,时间段的长度由DB的配置参数days(\duration )决定。这种按时间段分区的方法还便于高效实现数据的保留策略,只要数据文件超过规定的天数(系统配置参数keep),将被自动删除。而且不同的时间段可以存放于不同的路径和存储介质,以便于大数据的冷热管理,实现多级存储。
TDengine是从1970年1月1日0时0分0秒起(EpochTime)开始,每3天划一个分区。因此,对任何一个时间戳都是“划到哪一片就算到哪一片”。
时序数据的保留策略是由keep和days(\duration )这两个参数牢牢把控的。
- keep:数据库中数据保留的天数,单位为天,默认值:3650
- days\duration :一个数据文件存储数据的时间跨度,单位为天,默认值:10
TDengine通过keep和days严格控制可写入数据的时间范围(now-keep到now+days),给定了数据切分的时间范围(days\duration),因此一个vnode总的数据文件数目最多为:keep/days+2”。
示例说明:
假设某数据库的keep参数为7,days参数为3,当前时间为某月9日的0点0分。
由于keep为7,所以2日(9-7)之前的数据一定是不可以写入的。再加上限制未来时间数据的插入,12日(9+3)之后的数据也是不可以插入的。通过这样的方式,就有了TDengine当前可处理数据的时间范围time range(彩色范围),当你试图写入位于灰色时间区域的数据时——就会看到“timestamp out of time range”的提示了。
这组图代表了随着当前时间轴的移动,数据文件的分布情况和可写入数据范围的变化。
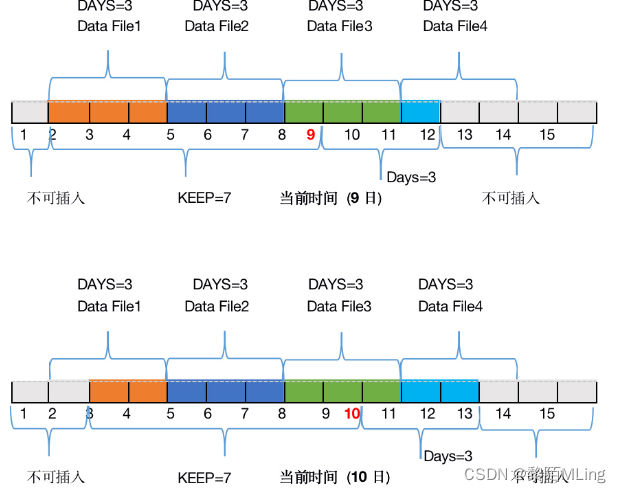
随着时间的推移,数据的时间戳会与系统时间做计算,一旦超过keep天数,就会被识别为过期数据,等到这个数据文件内的所有数据都过期后,这个数据文件才会被从计算机上清除。
回到目录 回到末尾
三、数据库性能优化
3.1 数据文件
.head 类文件存储了 .data 文件中的数据块的索引信息。在.data文件中的每个数据块的 BRIN 索引信息在 .head 类文件中以表为分组,按照时间顺序递增,形成索引块组。(注:硬盘上的数据用的是 BRIN 索引,在落盘之前的内存数据用的是 skiplist 索引。)在查询的时候,会先加载这个 .head 文件中的索引信息,从而找到 .data 文件中的时序数据返回给用户。
(注:BRIN 索引指的是 Block Range Index,主要适用于有着天然顺序的数据集,由于不需要再做排序,所以资源耗费少,十分契合时序数据的查询,也是 TDengine 和关系型数据库的核心区别之一。)
索引的作用是帮助我们快速定位数据的位置,但当你操作索引的时间变得特别长的时候,索引的价值无形之中就会变低了。所以,在 .head 文件较大的时候就可能会出现影响查询性能的瓶颈。
影响 .head 文件大小的因素有两个:
(1) maxrows 和 minrows 这两个参数
(2) duration\days 参数设置.
3.1.1 maxrows 和 minrows
(1)minRows:数据块中记录的最小条数,单位为条,默认值为100。
(2)maxRows:数据块中记录的最大条数,单位为条,默认值为4096。
数据块,是每个.data数据文件里存储数据的单位,每一个数据块都只能存储一个表的数据。也就是说形成一个数据块默认的最小行数是minRows行,最多就是maxRows行。表行数不足minRows时数据存放的位置.last文件;而大于maxRows行的表会生成一个新的数据块。最终在.data文件中,数据块的分布方式如下:

同样1000行数据,maxrows=200需要 5 个数据块,maxrows为 1000,只需要 1 块。每个数据块都需要一条索引信息存储在 .head 文件中。
用实例说明:
假设创建库时使用的参数为 maxrows=1000,minrows=100。某库中有两张表A和B,我们向其中分别插入1000行和99行数据。然后,我们重启taosd服务,以上数据就会从内存中落盘到存储上。这个时候.data文件中会生成1个数据块,它就是表A的数据块1,里面拥有1000条数据。而表B的99条数据因为不足minrows所以就进入了.last文件。
接下来,继续向它们分别插入1000行和99行,然后重启taosd服务落盘。这个时候表A总共拥有2000条数据,新写入的1000行数据会被写入进表A的数据块2。而表B的数据量现在已经有了198行,大于了100行。于是它们也会被写入.data文件里面,成为表B的数据块1。
值得注意的是,当.last文件小于32k的时候,所有数据都只会追加进来。但是当.last文件大于32k的时候,每次落盘.last文件都是重写生成的了——这个的32k限制是为了防止数据的移动过于频繁。
以上场景只针对两个表,但其实放大到100个表,1000个表都是一样的逻辑。尽管每个vnode内存里存储的大量数据分属于不同的表,但是每次落盘只要这些表的行数保证大于minrows,它们都会落入到.data文件的数据块中。不满足上述条件的表数据被写入.last文件后,继续等待新数据的写入,直到该表满足了行数minrows的大小后,.last文件中该表的数据会被读入到内存,之后一起写入到.data文件中。
即:
- .data类文件存储的是真正的时序数据,为多个数据块构成。一个数据块只属于一张表,且数据块的顺序只与落盘的先后顺序有关。
- .last文件与.data文件一样,也是存储时序数据的,只不过.last文件存储的块中的数据条数小于minRows。
回到目录 回到末尾
3.1.2 数据的保留策略duration\days
duration\days 是控制单个数据文件存储数据天数的参数。所以假如 duration 很大的话,单个数据文件存储的数据量就一定也很大,数据块就会很多。
3.2 磁盘IO - vgroups
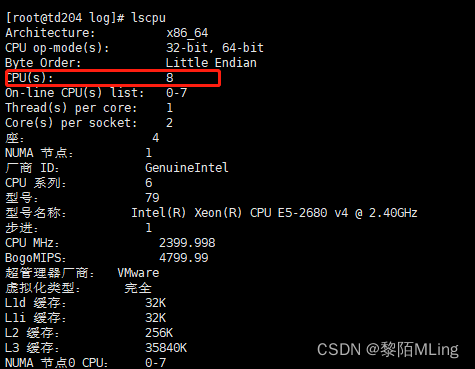
从服务端配置的角度,要根据系统中磁盘的数量,磁盘的 I/O 能力,以及处理器能力在创建数据库时设置适当的 vgroups 数量以充分发挥系统性能。如果 vgroups 过少,则系统性能无法发挥;如果 vgroups 过多,会造成无谓的资源竞争。常规推荐 vgroups 数量为 CPU 核数的 2 倍,但仍然要结合具体的系统资源配置进行调优。
#查看linux cpu核数命令:
lscpu
则 这里vgroups 设置常规为2*8=16
回到目录 回到末尾
3.3 性能优化实战
3.3.1 示例 - 场景描述
示例场景已知条件:
(1)超级表2张,每张超级表对应1688张子表,共有表 tbbleNum = 3376张
(2)要求表存储5年内的数据,即keep 5年,等于1825天
(3)数据采集入库频率:2秒,因此一个表一天的数据条目是:dayNum = 采集频率(秒) x 60 x 60x 24 = 172800(条)
(4)服务器cpu数目:8
3.3.2 示例场景现有情况
- 数据库版本:TDEngine3.0.4.2
- 配置参数全部按照默认配置
- 数据创建语句:
CREATE DATABASE IF NOT EXISTS db_name VGROUPS 8 KEEP 1825d CACHEMODEL 'last_value' DURATION 5d BUFFER 512; - 已有数据:2023.4.17 - 2023.6.19
- 查询效率:
(1)基于超级表的时间范围查询:
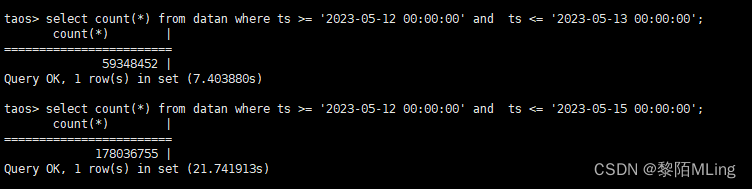
(2)基于子表的是时间范围查询:
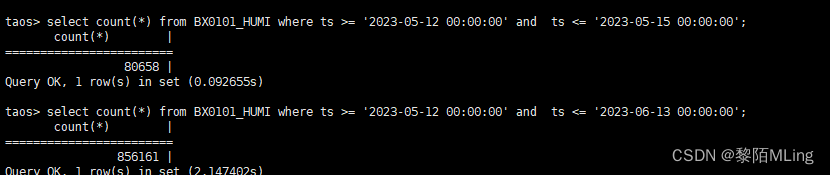
回到目录 回到末尾
3.3.3 场景分析
- keep:数据库中数据保留的天数,单位为天,默认值:3650天。
- days\duration :一个数据文件存储数据的时间跨度,单位为天,默认值为10天。也就是每10天产生一个表的.data文件。所以假如 duration 很大的话,单个数据文件存储的数据量就一定也很大,数据块就会很多。
- TDengine通过keep和days严格控制可写入数据的时间范围(now-keep到now+days),因此一个vnode总的数据文件数目最多为:keep/days+2
- 一个 vgroup 里虚拟节点个数就是数据的副本数。如果一个 DB 的副本数为 N,系统必须有至少 N 数据节点。副本数在创建DB时通过参数 replica 可以指定,缺省为 1。
- 在持续的建表过程中,TDengine是靠maxVgroupsPerDb、minTablesPerVnode、tablelncStepPerVnode这三个参数来控制表的分布的。
(1) maxVgroupsPerDb: 每个数据库中能够使用的最大vnode个数(单个副本),默认为0(自动配置),即每个 Database 可以创建固定数目的 vgroup,默认与 CPU 核数相同。
(2)minTablesPerVnode: 每个vnode中必须创建的最小表数,即是说这是第一轮建表用的步长(就是满多少表写下一个vnode),默认1000;
(3)tablelncStepPerVnode:每个vnode中超过最小表数后的递增步长(即是后续满多少表写下一个vnode),默认1000。
- 如果:vgroups = cpu数目 = 8, replica = 1,则:maxVgroupsPerDb = 0
- minTablesPerVnode = tbbleNum / vgroups = 3376/8 = 422
- tablelncStepPerVnode = 10
查看数据库中表的vgroup分布:
show .vgroups;

- 在做数据的负载均衡的时候,mnode也会是被计算在内的,而具体的计算方式就是,一个mnode等价于n个vnode,这个n就是由参数modeEqualVnodeNum控制。
- 一个数据块只存储一个表数据,且数据块的大小由maxrows 和 minrows控制。即形成一个数据块默认的最小行数是minRows行,最多就是maxRows行。表行数不足minRows时数据存放的位置.last文件;而大于maxRows行的表会生成一个新的数据块。
- 所有的数据库存储在 .data 文件中。在.data文件中的每个数据块的 BRIN 索引信息在 .head 类文件中以表为分组,按照时间顺序递增,形成索引块组。
- 共产生 .data文件个数:datanNum = vnode数目 *(keep/days+2)= 8 x (1825/days+2)
- 一个.data文件中数据块的个数:blockNum = dayNum/maxrows 。这里dayNum 大于10万,如果设置为默认的话,一天一个表就会产生173个数据块,查询效率太低。
- 假设maxrows = 9216,则一天一个表有18个数据块,一共保留days = 10天,一个.data文件有180个数据块。
回到目录 回到末尾
3.3.4 场景升级
3.3.4.1 升级操作
- 建议tdengine server安装在根目录(root)下,然后数据和日志文件放到其他目录(如home目录)。我尝试过直接安装在/home目录下,导致整个数据库运行和查询都很慢,不知道是机器本身原因还是什么导致的。
- tdengine同样配置(默认配置)和数据量的情况下,tdengine3.0.3.2比tdengine2.4的查询速度慢很多,暂时没找到原因,可能3.x的使用需要更优的配置。
回到目录 回到末尾
3.3.4.2 查询效率分析
回到目录 回到末尾
四、写入优化
1、【TDEngine官网-高效率写入】
2、【TDengine 的用户如何优化数据的写入速度?】
回到目录 回到末尾