系列文章目录
第一章 AlexNet网络详解
第二章 VGG网络详解
第三章 GoogLeNet网络详解
第四章 ResNet网络详解
第五章 ResNeXt网络详解
第六章 MobileNetv1网络详解
第七章 MobileNetv2网络详解
第八章 MobileNetv3网络详解
第九章 ShuffleNetv1网络详解
第十章 ShuffleNetv2网络详解
第十一章 EfficientNetv1网络详解
第十二章 EfficientNetv2网络详解
第十三章 Transformer注意力机制
第十四章 Vision Transformer网络详解
第十五章 Swin-Transformer网络详解
第十六章 ConvNeXt网络详解
第十七章 RepVGG网络详解
第十八章 MobileViT网络详解
文章目录
- MobileNetv3网络详解
- 0. 前言
- 1. 摘要
- 2. MobileNetv3网络详解网络架构
- 1. MobileNetv3_Model.py(pytorch实现)
- 2.
- 总结
0、前言
1、摘要
本文介绍了基于互补的搜索技术和新颖的架构设计的MobileNets的下一代。MobileNetV3通过硬件感知网络架构搜索(NAS)和NetAdapt算法相结合,针对移动电话CPU进行优化,随后通过新颖的架构改进技术进行了进一步提高。本文开始探索自动化搜索算法和网络设计如何相互协作,以利用互补的方法改进整体技术水平。通过此过程,我们创建了两个新的MobileNet模型:MobileNetV3-Large和MobileNetV3-Small,分别针对高资源和低资源使用情况。然后将这些模型应用于物体检测和语义分割任务。对于语义分割任务(或任何密集像素预测),我们提出了一种新的高效分割解码器Lite Reduced Atrous Spatial Pyramid Pooling(LR-ASPP)。在移动分类、检测和分割方面,我们取得了新的技术水平。MobileNetV3-Large在ImageNet分类上的准确性提高了3.2%,同时将延迟降低了20%,相比MobileNetV2。MobileNetV3-Small的准确性比具有可比延迟的MobileNetV2模型提高了6.6%。MobileNetV3-Large的检测速度比COCO检测上的MobileNetV2快25%左右,准确率大致相同。MobileNetV3-Large LR ASPP在Cityscapes分割上的速度比MobileNetV2 R-ASPP快34%,准确性相似。
2、MobileNetv3网络结构
MobileNetV3是由Google在2019年提出的一种轻量级卷积神经网络结构,旨在提高在移动设备上的速度和准确性。它的网络结构主要包括以下几个部分:
1.基础卷积模块:该模块使用轻量级深度可分离卷积(depthwise separable convolution),将一个标准卷积操作分解成两个步骤:先进行通道的分离,再通过逐通道卷积实现。这样做能够显著减少计算和参数数量。
2.倒残差模块:这是MobileNetV3中的一个新模块,它可以增加网络的深度和非线性,同时保持计算代价不变。该模块通过将两个基础卷积模块连接起来,再使用shortcut进行跨层连接,实现信息的跨层传递。
3.Squeeze-and-Excitation模块:该模块通过引入一个全局平均池化层,进一步降低计算复杂度,并使用一对全连接层来对通道的重要性进行建模,从而增强了网络对重要特征的感知能力。
4.Hard-swish激活函数:这是一个快速轻量级的激活函数,它是在ReLU激活函数的基础上进行改进的,通过增加一定的非线性特性和使用更少的计算代价来提高模型的表现。
通过以上四个模块的组合,MobileNetV3实现了很好的权衡:同时保持了网络轻量和准确,是非常适合移动端部署的一种卷积神经网络结构。
高效神经网络正在移动应用程序中变得普遍,可以实现全新的设备体验。它们也是个人隐私的关键,用户可以获得神经网络的好处,而无需将其数据发送到服务器进行评估。神经网络效率的提高不仅可以通过更高的准确性和更低的延迟改善用户体验,还可以通过降低功耗来延长电池寿命。本文描述了我们采取的方法,以开发MobileNetV3大型和小型模型,为实现动作视觉驱动下一代高准确性的高效神经网络模型提供支持。新的网络推动了最前沿的技术并展示了如何结合自动化搜索和新的架构进步来构建有效的模型。本文的目标是在移动设备上优化准确性和延迟的权衡,以开发最佳移动动作视觉构架。为此,我们引入了(1)补充搜索技术,(2)适用于移动设置的新非线性版本,(3)新的高效网络设计,(4)新的有效分割解码器。我们展示了广泛的实验,评估了不同用例和移动电话上每种技术的功效和价值。本文的组织如下。我们从第2节讨论相关工作开始。第3节回顾了用于移动模型的高效构建块。第4节回顾了建构搜索和MnasNet和NetAdapt算法的互补性。第5节描述了新的架构设计,改善了通过联合搜索找到的模型的效率。第6节介绍了广泛的分类、检测和分割实验,以展示功效并了解不同元素的贡献。第7节包含结论和未来工作。
在近年来,为了在准确性和效率之间寻找最优平衡的深度神经网络架构设计一直是一个活跃的研究领域。新颖的手工结构和算法神经网络架构搜索都在推进这一领域方面发挥了重要作用。SqueezeNet[22]广泛使用1x1的卷积与挤压和扩展模块,主要侧重于减少参数数量。更近期的工作则将注意力从减少参数数量转移到了减少操作数量(MAdds)和实际测量延迟。MobileNetV1[19]采用深度可分离卷积显著提高了计算效率。MobileNetV2[39]在此基础上引入了一种资源高效的块,即倒置残差和线性瓶颈。ShuffleNet[49]利用分组卷积和通道混洗操作进一步减少MAdds。CondenseNet[21]在训练阶段学习组卷积以保持层之间的有用密集连接以供特征复用。ShiftNet[46]提出了移动操作与点卷积交替使用以替换昂贵的空间卷积。为了自动化架构设计过程,强化学习(RL)首先被引入以搜索具有竞争性准确性的高效架构[53,54,3,27,35]。可完全配置的搜索空间可能会增长成指数级,难以处理。因此,早期的架构搜索工作主要集中在单元级结构搜索,并且相同的单元在所有层中都会被重用。最近,[43]探索了块级分层搜索空间,允许在网络的不同分辨率块中使用不同的层结构。为了减少搜索的计算成本,[28,5,45]使用了可微分的架构搜索框架进行梯度优化。重点关注将现有网络适应于受限移动平台的[48,15,12]提出了更高效的自动化网络简化算法。量化[23,25,47,41,51,52,37]是另一个重要的辅助实现高效计算的技术。
移动端机型的建模越来越高效。MobileNetV1 通过深度可分离卷积有效替代传统卷积层,将空间过滤与特征生成机制分离。深度可分离卷积由两个分离的层构成:轻量级深度卷积层用于空间过滤,较重的 1x1 点卷积层用于特征生成。MobileNetV2 引入了线性瓶颈和反转残差结构,利用低秩性质设计更高效的层结构,即由 1x1 扩张卷积、深度卷积和 1x1 投影层构成,仅在输入输出通道一致时才进行残差连接,从而在输入和输出端维持紧凑表示,内部则通过扩展到高维特征空间来增加非线性分通道变换表达能力。MnasNet 在 MobileNetV2 结构上引入基于压缩和激励的轻量级注意力模块,并将其放置在扩张中的深度卷积层后面,以便在最大表示上应用注意力。MobileNetV3 则将这些层组合作为构建最有效模型的基本块,同时使用修改后的 Swish 非线性性提升层的效果。值得注意的是,注意力和 Swish 非线性性均使用 Sigmoid,这在计算效率和固定点算术方面都存在挑战,也可能影响准确性。
网络搜索已经证明是一种非常强大的工具,可以用于发现和优化网络架构。对于MobileNetV3,我们使用平台感知型NAS来搜索全局网络结构,通过优化每个网络块。接着,我们使用NetAdapt算法来搜索每层的滤波器数量。这些技术是互补的,可以结合使用,有效地找到给定硬件平台的优化模型。
与[43]类似,我们采用平台感知的神经架构方法来寻找全局网络结构。由于我们使用相同的基于 RNN 的控制器和分解的分层搜索空间,因此对于目标延迟约为80ms的大型移动模型,我们得到了类似于[43]的结果。因此,我们简单地重用同样的MnasNet-A1 [43]作为我们的初始大型移动模型,然后在其基础上应用NetAdapt [48]和其他优化措施。但是,我们观察到原始奖励设计并非针对小型移动模型进行优化。具体来说,它使用一种多目标奖励ACC(m)×[LAT(m)=TAR]w来近似帕累托最优解,通过在基于目标延迟TAR的每个模型m的模型准确性ACC(m)和延迟LAT(m)之间平衡来平衡。我们观察到,对于小模型,准确性的变化随延迟的变化更加剧烈。因此,我们需要一个更小的权重因子w=-0.15(与[43]中原始w=-0.07相比),以补偿不同延迟下更大的准确性变化。增强了这个新的权重因子w,我们从零开始进行新的架构搜索,找到初始种子模型,然后应用NetAdapt和其他优化措施,以获得最终的MobileNetV3-Small模型。
我们在架构搜索中使用的第二种技术是NetAdapt [48]。该方法与平台感知NAS相互补充:它允许依次微调每个层,而不是试图推断粗糙但全局的架构。具体细节请参阅原始论文。简而言之,技术的步骤如下:
1.从平台感知NAS找到一个种子网络架构。
2.每个步骤如下:
(a)生成一组新的建议。每个建议都代表一个架构的修改,相对于先前的步骤至少产生了δ减少的延迟。
(b)对于每个建议,我们使用前一步的预训练模型,填充新的建议架构,截断和随机初始化适当的缺失权重。对每个建议进行T步的微调,以获取粗略的准确度估计。
(c)根据某个指标选择最佳建议。
3.重复上一步,直到达到目标延迟。在[48]中,这个度量是最小化准确度变化。我们修改了这个算法,并最小化延迟变化和准确变化之间的比率。也就是说,在每个NetAdapt步骤生成的所有建议中,我们会选择一个最大化斜率的建议。这个过程会重复,直到延迟达到目标,然后我们从头开始重新训练新的架构。我们在MobilenetV2中使用了与[48]相同的建议生成器。具体而言,我们允许以下两种类型的建议:1.减少任何扩展层的大小;2.在所有共享瓶颈大小的块中减少瓶颈-以维持残差连接。在我们的实验中,我们使用了T = 10000,发现虽然它增加了建议的初始微调的准确度,但在从头训练时,它并不改变最终的准确度。我们将δ设置为0.01|L|。
除了网络搜索外,我们还引入了几个新组成部分来进一步改进最终模型。我们重新设计了网络的计算密集层,包括开头和结尾。我们还引入了一种新的非线性函数h-swish,这是最近swish非线性函数的修改版本,它的计算速度更快,更适合量化。
一旦通过架构搜索找到模型,我们观察到一些最后一层和一些早期层比其他层更昂贵。我们提出一些修改架构的方法,以减少这些低速层的延迟,同时保持准确性。这些修改不在当前搜索空间的范围内。第一种修改重新设计了网络的最后几层的交互方式,以更高效地生成最终特征。基于MobileNetV2的倒置瓶颈结构和变种的当前模型使用1x1卷积作为最后一层,以扩展到更高维度的特征空间。这一层对于预测具有丰富的特征至关重要。然而,这是会带来额外的延迟的。为了减少延迟并保留高维度的特征,我们把这一层放在最终平均池化之后。现在,这一组最终特征的计算是在1x1的空间分辨率上完成的,而不是7x7的空间分辨率。这种设计选择的结果是,在计算和延迟方面,特征计算变得几乎是免费的。一旦减轻了这个特征生成层的代价,先前的瓶颈投影层就不再需要用来减少计算。这一观察结果使我们能够削减先前瓶颈层中的投影和过滤层,进一步减少计算复杂度。图5中可以看到原始和优化的最后阶段。高效的最后阶段将延迟降低了7毫秒,这相当于运行时间的11%,并将操作数量减少了3000万,而几乎不损失准确性。另一个昂贵的层是初始的过滤器集。当前的移动模型往往使用32个过滤器进行完整的3x3卷积,以构建用于边缘检测的初始过滤器组。这些过滤器通常是彼此的镜像。我们尝试减少过滤器的数量。
本文介绍了一种非线性函数Swish,在神经网络中用于ReLU的替代品,可以显著提高准确性。Swish函数定义为Swish(x)= x·σ(x)。然而,由于移动设备上计算sigmoid函数很昂贵,因此我们采用两种方法来解决此问题。
第一,我们将sigmoid函数替换为其分段线性硬模拟函数:ReLU6(6 x + 3),这与以前的工作类似。Swish函数的硬版本称为h-swish [x] = xReLU6(x + 3)。我们发现,这些函数的硬版本在精度上与其软版本没有明显区别,但在部署方面具有多种优势。其次,优化的ReLU6实现在几乎所有软件和硬件框架上都可用。
第二,在实践中,h-swish可以实现为分段函数,以减少驱动延迟成本的内存访问次数。其次,我们发现,随着网络的深入,应用非线性函数的成本会降低,因为每个层激活内存通常会在分辨率下降时减半。因此,在我们的架构中,我们只在模型的后半部分使用h-swish。即使进行了这些优化,h-swish仍会引入一些延迟成本。但是,正如我们所展示的,这个成本是可以接受的,因为它仍然提供了更高的准确性。具体的布局请参见表1和表2。
在[43]中, squeeze-and-excite 瓶颈的大小相对于卷积瓶颈的大小是相关的。相反,我们将它们都替换为固定的,即为扩张层中通道数量的1/4。我们发现这样做可以在适度增加参数数量和没有明显的延迟成本的情况下增加精度。
MobileNetV3定义为两个模型:MobileNetV3-Large和MobileNetV3-Small。这些模型分别针对高和低资源使用情况。模型是通过应用平台感知NAS和NetAdapt进行网络搜索,并结合本节定义的网络改进来创建的。完整的网络规格请参见表1和2。
我们展示了实验结果,以证明新的MobileNetV3模型的有效性。我们报告了分类、检测和分割的结果,并报告了各种消融研究,以阐明各种设计决策的影响。
按照惯例,我们在所有分类实验中使用ImageNet[38],并比较准确度与各种资源使用指标,例如延迟和乘法加(MAdds)等。

(图1. 像素1延迟和top-1 ImageNet准确度之间的权衡。所有模型均使用输入分辨率为224。V3大型和V3小型使用乘数0.75、1和1.25来显示最佳前沿。所有延迟都是在使用 TFLite[1] 的同一设备的单个大核上测量得出的。MobileNetV3-Small和Large是我们提出的下一代移动模型。)

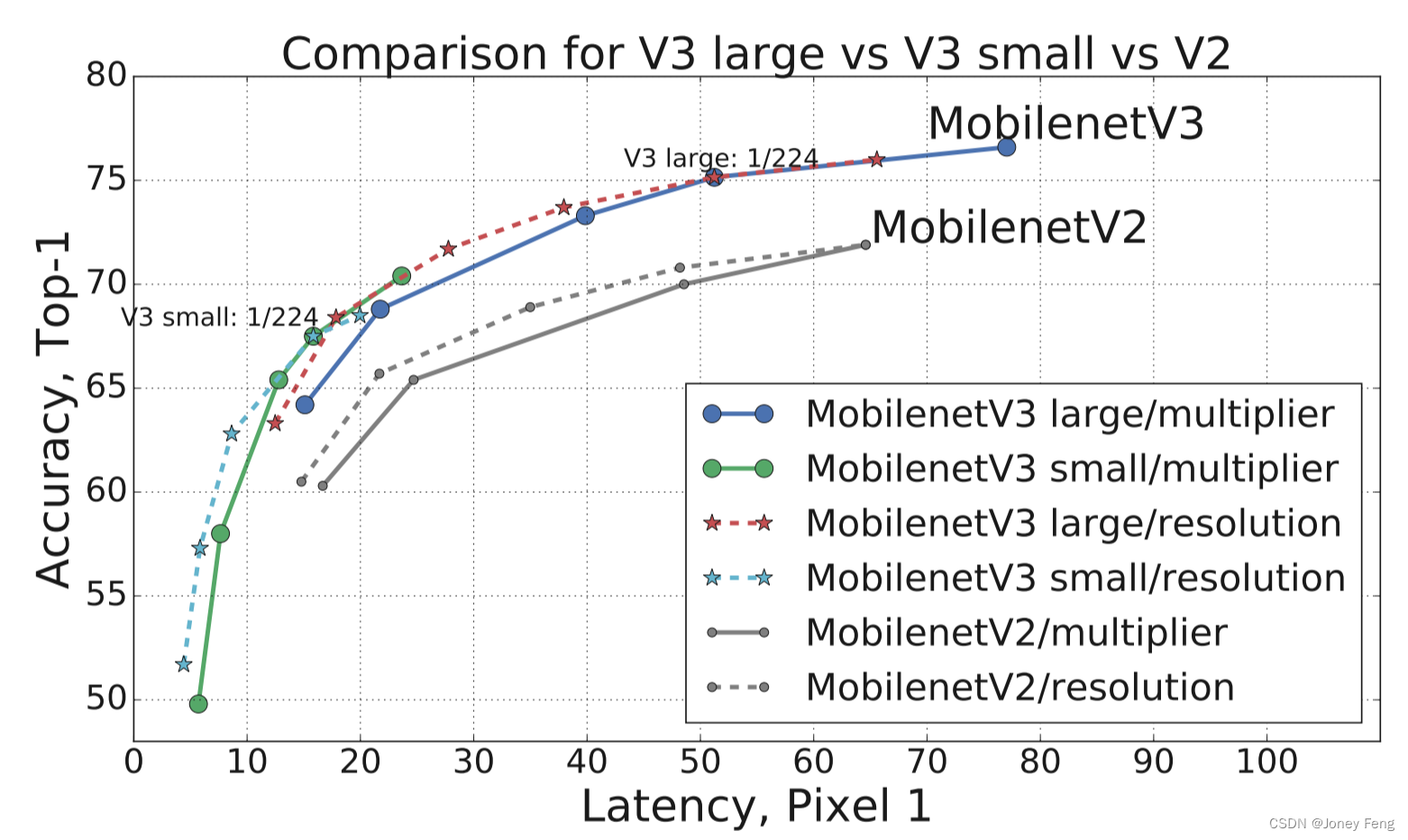
(图2. MAdds和top-1准确度之间的权衡。这允许比较针对不同硬件或软件框架的模型。所有MobileNetV3适用于输入分辨率224,并使用乘数0.35、0.5、0.75、1和1.25。其他分辨率请参见第6节。最好用彩色查看。)

(图3显示了MobileNetV2 [39]层(倒置残差和线性瓶颈)。每个块由窄输入和输出(bottleneck)组成,它们没有非线性,在扩展到一个更高维度空间和投影到输出之前,在瓶颈处连接残差(而不是扩展))

(图4展示了MobileNetV2和Squeeze-and-Excite的结合,与[20]不同的是,我们在残差层应用squeeze and excite。我们根据每一层使用不同的非线性函数,具体请参见第5.2节)
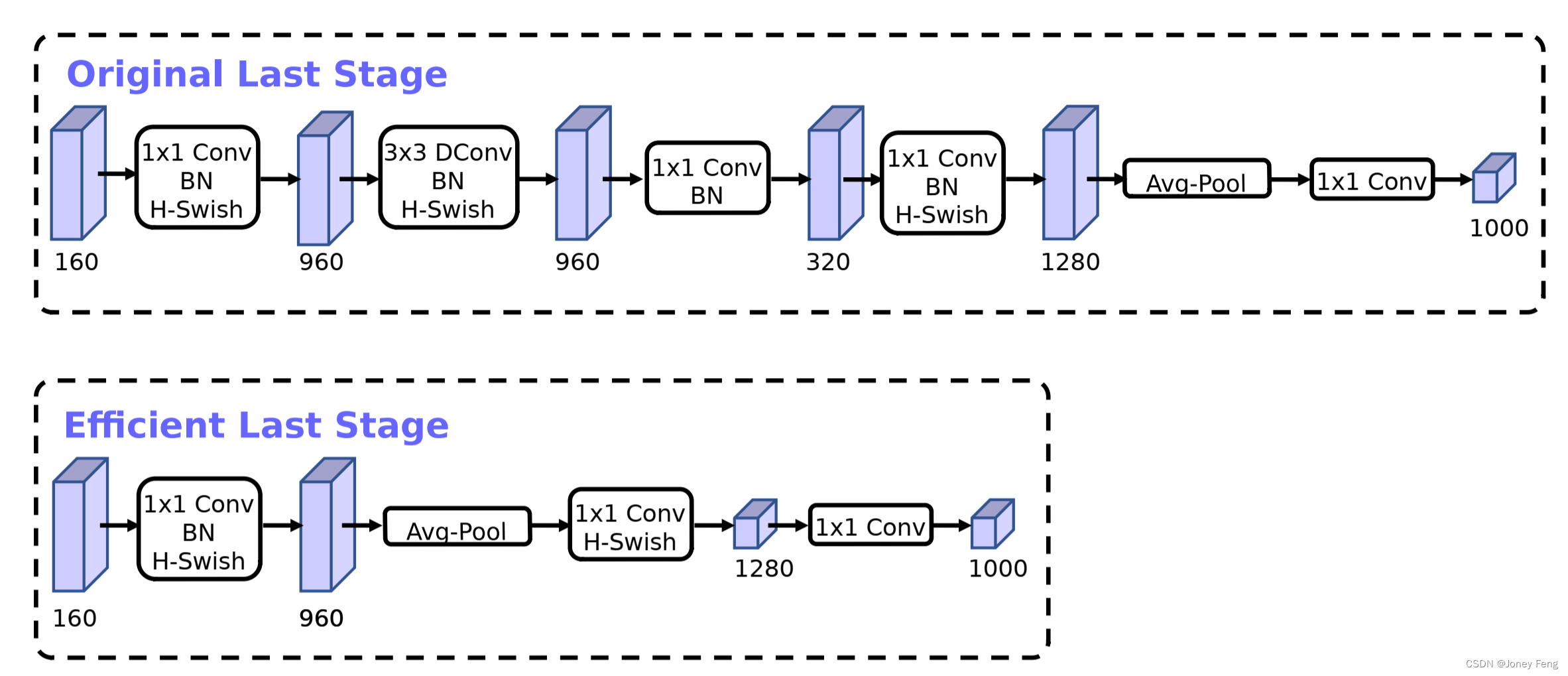
(图5. 原始最后一层与高效最后一层比较。这种更高效的最后一层能够在不影响准确性的情况下去掉网络结构末尾的三个昂贵的层。)
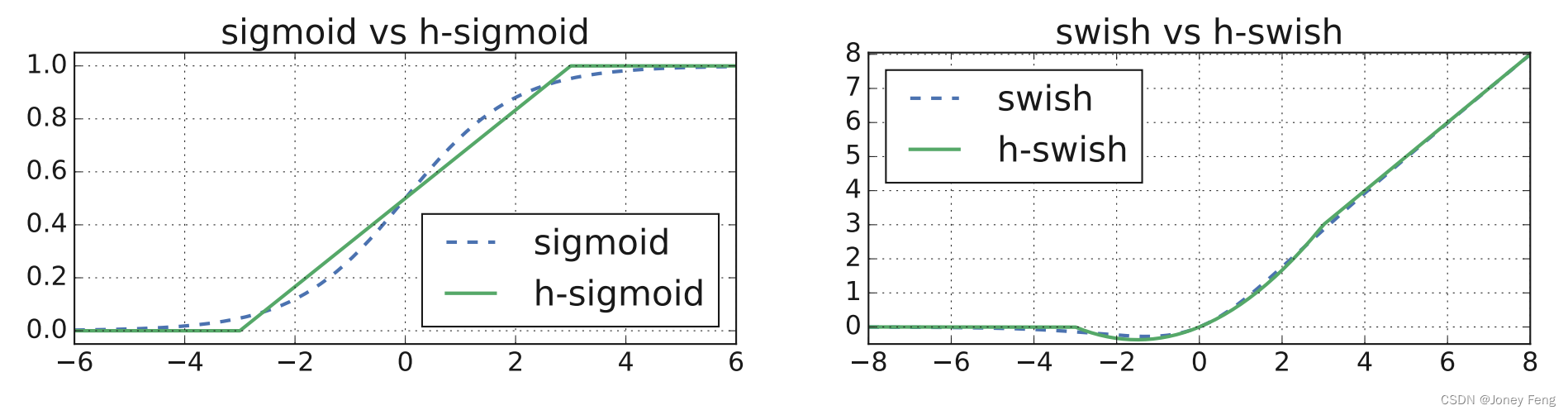
(图6. 逻辑和swish非线性函数及其“硬”对应函数。)
(图7.不同乘数和分辨率下MobileNetV3的表现。在我们的实验中,我们使用了乘数为0.35, 0.5, 0.75, 1.0和1.25,固定分辨率为224,以及分辨率为96、128、160、192、224和256,乘数为1.0。最佳效果在彩色下查看,ImageNet的Top-1精度,延迟以毫秒表示。)

(图8.使用深度乘法器对优化和非优化h-swish的延迟影响。曲线显示了深度乘法器的边界。请注意,在所有具有80个或更多通道(V3)的层中放置h-swish提供了最佳的优化和非优化h-swish的权衡。Top-1准确度在ImageNet中,延迟以毫秒为单位。)
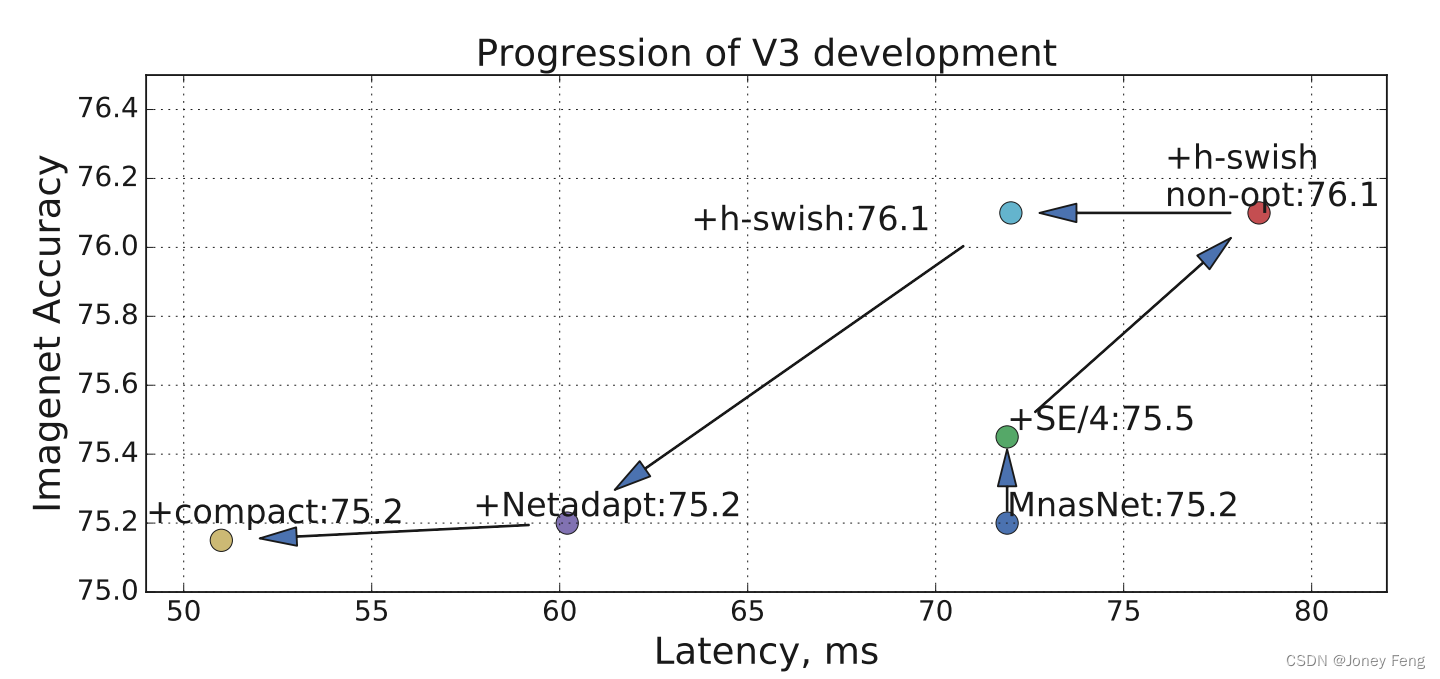
(图9. 移动网络V3发展中各个组件的影响。通过向上和向左移动来衡量进展。)
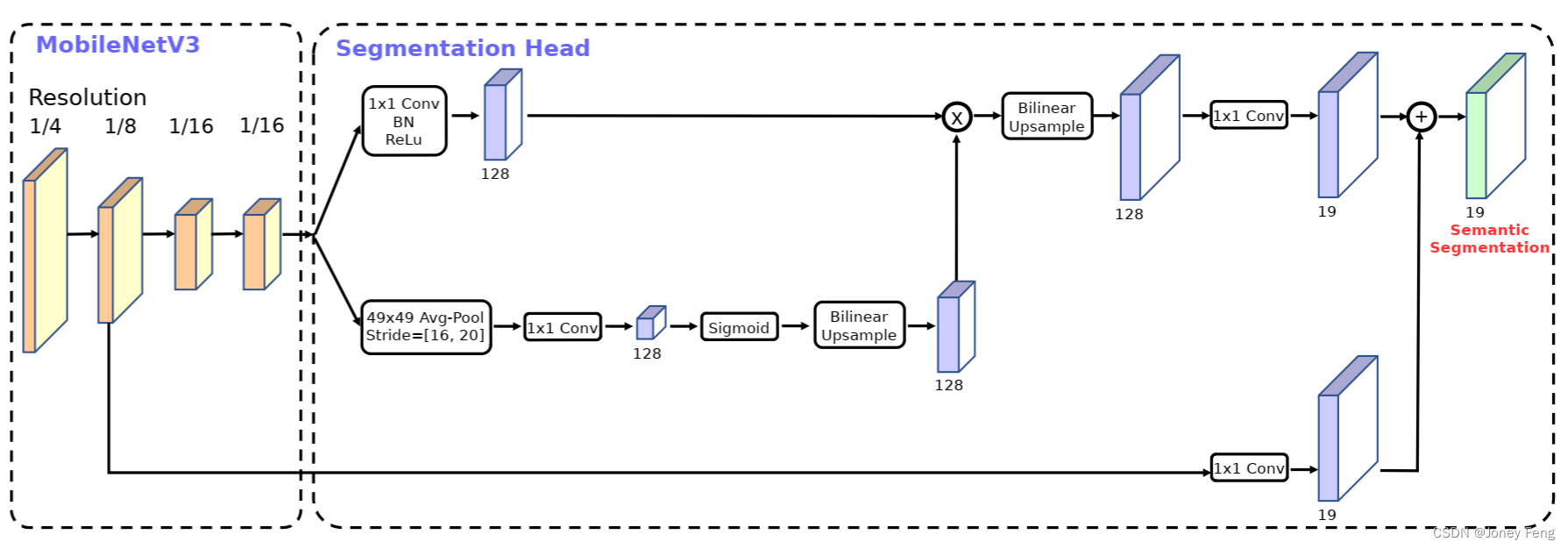
(图10。基于MobileNetV3,提出了分割头Lite R-ASPP,可以在混合多个分辨率的特征的同时,快速提供语义分割结果。)
亮点:
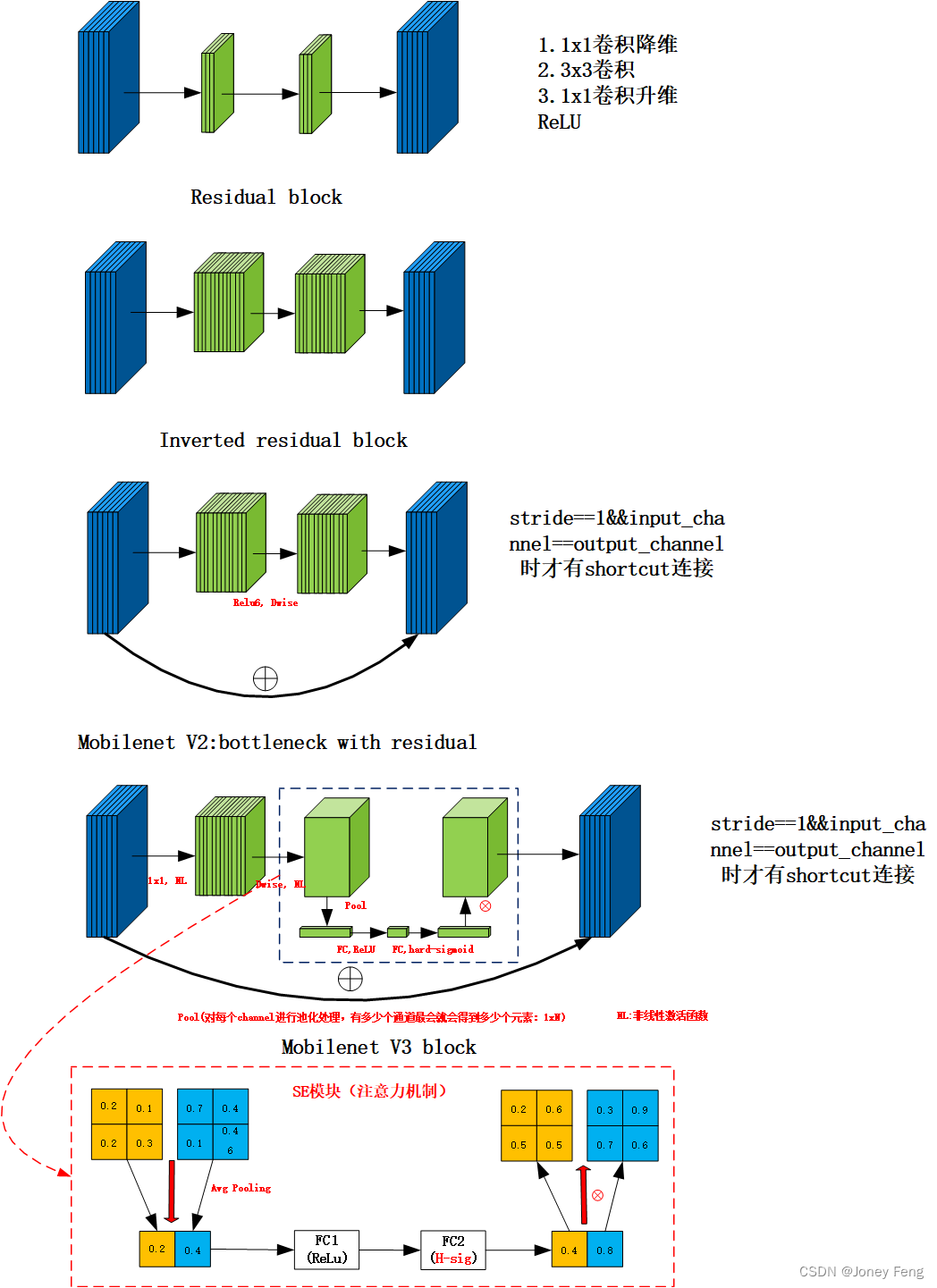
1.更新Block(bneck)
2.使用NAS搜索参数(Neural Architecture Search)
3.重新设计耗时层结构
更新Block(bneck)
1.加入SE模块
2.更新了激活函数ReLU6
NAS(Neural Architecture Search)是一种自动化机器学习领域的技术,用于自动搜索最优的神经网络结构。它使用强化学习、遗传算法或其他优化算法,探索可能的神经网络结构,并选择性能最好的结构。搜索参数是NAS中的一个重要步骤,它决定了搜索空间的大小和可行性。下面详细介绍NAS搜索参数的具体操作方法和过程。
1.定义搜索空间
首先,需要定义搜索空间,即神经网络结构的可变参数。搜索空间应包括网络层数、每个层的神经元数量、激活函数、池化方式、卷积核大小等可能影响神经网络性能的参数。例如,定义搜索空间如下:
(1)神经网络层数:从1到10层;
(2)每层神经元数量:从16到1024个;
(3)激活函数:ReLU、sigmoid等;
(4)池化方式:最大池化、平均池化等;
(5)卷积核大小:3x3、5x5、7x7等。
2.设计搜索算法
设计一个搜索算法,包括两大类方法:贪心算法和进化算法。其中,贪心算法是从空间里选用表现最优的结构,并在最优结构附近继续搜索;进化算法则是通过基因重组来产生新的结构,并评估其表现。
3.定义评估度量
评估度量是为了度量神经网络结构的性能,评估度量应能准确衡量网络的精度、时间和资源消耗等指标。例如,评估度量可以是模型精度、模型大小、模型训练时间、验证集的损失函数等。
4.搜索最优结构
启动搜索算法,对于所定义的搜索空间中的每个结构,都使用评估度量对其进行评估。搜索过程中,会生成许多随机的结构,并尝试对每个结构进行评估。评估过程通常会花费大量时间和资源。5.调整结构
在搜索过程中,可能会遇到一些结构无法达到预期性能的情况。此时,可以尝试对结构进行调整,例如增加或减少网络层数、减少或增加每层神经元数量等,并重复上述步骤,以期获得最佳性能。6.导出最终模型
在搜索过程结束后,NAS会将最终的的最优结构导出为模型,进行训练和部署,以获得所需的预测结果。模型可以利用深度学习框架重新实现,如Tensorflow、Keras和PyTorch等。
以上就是NAS搜索参数的具体操作方法和过程。NAS近几年来迅速发展,具有很大的潜力和应用前景。
重新设计耗时层结构
1.减少第一个卷积层的卷积核个数(32->16)
2.精简Last Stage
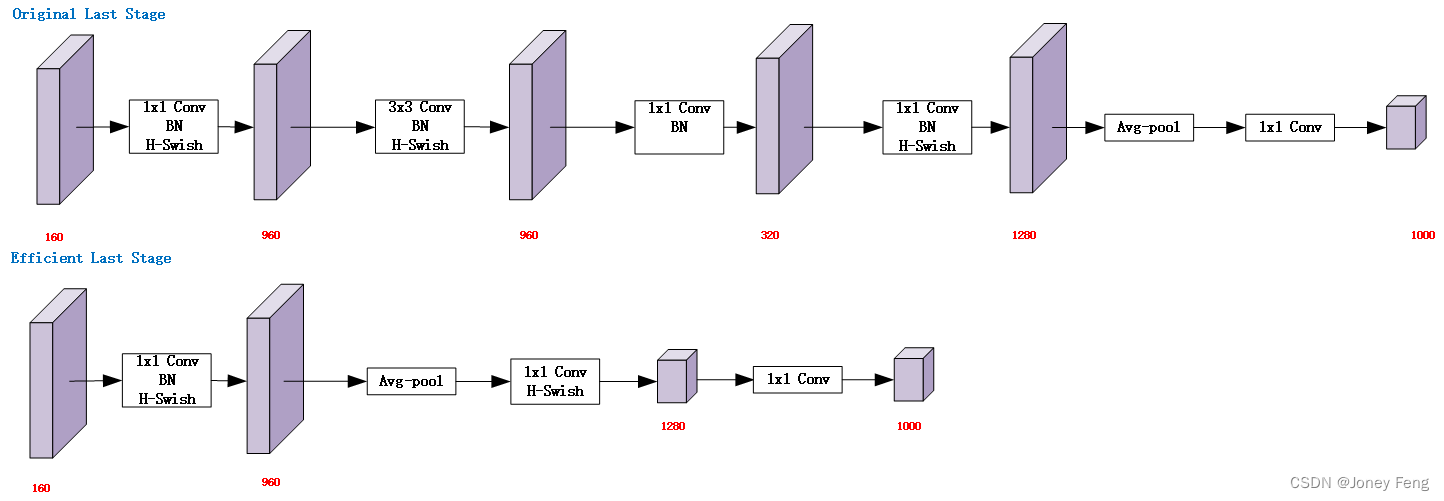
表1. MobileNetV3-Large规格表。SE表示该块中是否有Squeeze-And-Excite。NL表示使用的非线性类型。这里,HS表示h-swish,RE表示ReLU。NBN表示无批量归一化。s表示步长。
Table 1.Specification for MobileNetV3-Large.SE denotes whether there is a Squeeze-And-Excite in that block.NL denotes the type of nonlinearity used.Here,HS denotes h-swish and RE denotes ReLU.NBN denotes no batch normalization.s denotes stride.
| 输入 | 操作 | 扩展层的输出通道数 | 输出通道数 | 注意力机制 | 非线性激活函数 | 步长 |
| 224×224×3 | conv2d | - | 16 | - | HS | 2 |
| 112×112×16 | bneck,3×3 | 16 | 16 | - | RE | 1 |
| 112×112×16 | bneck,3×3 | 64 | 24 | - | RE | 2 |
| 56×56×24 | bneck,3×3 | 72 | 24 | - | RE | 1 |
| 56×56×24 | bneck,5×5 | 72 | 40 | √ | RE | 2 |
| 28×28×40 | bneck,5×5 | 120 | 40 | √ | RE | 1 |
| 28×28×40 | bneck,5×5 | 120 | 40 | √ | RE | 1 |
| 28×28×40 | bneck,3×3 | 240 | 80 | - | HS | 2 |
| 14×14×80 | bneck,3×3 | 200 | 80 | - | HS | 1 |
| 14×14×80 | bneck,3×3 | 184 | 80 | - | HS | 1 |
| 14×14×80 | bneck,3×3 | 184 | 80 | - | HS | 1 |
| 14×14×80 | bneck,3×3 | 480 | 112 | √ | HS | 1 |
| 14×14×112 | bneck,3×3 | 672 | 112 | √ | HS | 1 |
| 14×14×112 | bneck,5×5 | 672 | 160 | √ | HS | 2 |
| 7×7×160 | bneck,5×5 | 960 | 160 | √ | HS | 1 |
| 7×7×160 | bneck,5×5 | 960 | 160 | - | HS | 1 |
| 7×7×160 | conv2d,1×1 | - | 960 | - | HS | 1 |
| 7×7×960 | pool, 7×7 | - | - | - | - | 1 |
| 1×1×960 | conv2d,1×1,NBN | - | 1280 | - | HS | 1 |
| 1×1×1280 | conv2d,1×1,NBN | - | k | - | - | 1 |
表2. MobileNetV3-Small规格说明。请参见表1的注释。
Table 2.Specification for MobileNetV3-Small.See table 1 for notation.
| 输入 | 操作 | 扩展层的输出通道数 | 输出通道数 | 注意力机制 | 非线性激活函数 | 步长 |
| 224×224×3 | conv2d,3×3 | - | 16 | - | HS | 2 |
| 112×112×16 | bneck,3×3 | 16 | 16 | √ | RE | 2 |
| 56×56×16 | bneck,3×3 | 72 | 24 | - | RE | 2 |
| 28×28×24 | bneck,3×3 | 88 | 24 | - | RE | 1 |
| 28×28×24 | bneck,5×5 | 96 | 40 | √ | HS | 2 |
| 14×14×40 | bneck,5×5 | 240 | 40 | √ | HS | 1 |
| 14×14×40 | bneck,5×5 | 240 | 40 | √ | HS | 1 |
| 14×14×40 | bneck,5×5 | 120 | 48 | √ | HS | 1 |
| 14×14×48 | bneck,5×5 | 144 | 48 | √ | HS | 1 |
| 14×14×48 | bneck,5×5 | 288 | 96 | √ | HS | 2 |
| 7×7×96 | bneck,5×5 | 576 | 96 | √ | HS | 1 |
| 7×7×96 | bneck,5×5 | 576 | 96 | √ | HS | 1 |
| 7×7×96 | conv2d,1×1 | - | 576 | √ | HS | 1 |
| 7×7×576 | pool,7×7 | - | - | - | - | 1 |
| 1×1×576 | conv2d,1×1,NBN | - | 1024 | - | HS | 1 |
| 1×1×1024 | conv2d,1×1,NBN | - | k | - | - | 1 |
我们使用标准的TensorFlow RMSPropOptimizer和0.9的动量,在4x4的TPU Pod [24]上使用同步训练设置来训练我们的模型。我们使用初始学习率为0.1,批量大小为4096(每个芯片128张图片),学习率衰减率为每3个时期0.01。我们使用0.8的丢失率和l2权重衰减1e-5以及与Inception [42]相同的图像预处理。最后,我们使用衰减0.9999的指数移动平均值。我们所有的卷积层都使用平均衰减率为0.99的批量标准化层。
表3. Pixel系列手机上的浮点性能(P-n表示Pixel-n手机)。所有延迟时间以毫秒为单位,使用一个大内核和批处理大小为1进行测量。Top-1准确度是在ImageNet上的。
Table 3.Floating point performance on the Pixel family of phones (P-n denotes a Pixel-n phone).All latencies are in ms and are measured using a single large core with a batch size of one.Top-1 accuracy is on ImageNet.
| 网络 | Top-1准确率 | 模型的乘加操作数量(Million) | 参数数量 |
P-1: 在Pixel 1上的延迟时间 |
P-2: 在Pixel 2上的延迟时间 |
P-3: 在Pixel 3上的延迟时间 |
| V3-Large 1.0 | 75.2 | 219 | 5.4M | 51 | 61 | 44 |
| V3-Large 0.75 | 73.3 | 155 | 4.0M | 39 | 46 | 40 |
| MansNet-AI | 75.2 | 315 | 3.9M | 71 | 86 | 61 |
| Proxyless | 74.6 | 320 | 4.0M | 72 | 84 | 60 |
| V2 1.0 | 72.0 | 300 | 3.4M | 64 | 76 | 56 |
| V3-Samll 1.0 | 67.4 | 56 | 2.5M | 15.8 | 19.4 | 14.4 |
| V3-Samll 0.75 | 65.4 | 44 | 2.0M | 12.8 | 15.6 | 11.7 |
| Mnas-small | 64.9 | 65.1 | 1.9M | 20.3 | 24.2 | 17.2 |
| V2 0.35 | 60.8 | 59.2 | 1.6M | 16.6 | 19.6 | 13.9 |
测量延迟我们使用标准的Google Pixel手机,并通过标准的TFLite基准测试工具运行所有网络。在所有测量中,我们都使用单线程大内核。我们不报告多核推理时间,因为我们发现这种设置对于移动应用程序不太实用。我们为TensorFlow Lite贡献了一个原子h-swish运算符,它现在是最新版本的默认值。我们在第9图中展示了优化h-swish的影响。
如图1所示,我们的模型表现优于当前最先进的模型,如MnasNet [43]、ProxylessNas [5]和MobileNetV2 [39]。我们在表3中报告了不同Pixel手机的浮点性能。我们在表4中列出量化结果。在图7中,我们展示了MobileNetV3性能权衡的函数,作为乘数和分辨率的函数。请注意,MobileNetV3-Small的表现优于MobileNetV3-Large,乘数按比例缩放以匹配表现近3%。另一方面,分辨率提供了更好的权衡。但是,应该注意到,分辨率通常由问题确定(例如,分割和检测问题通常需要更高的分辨率),因此不能总是用作可调参数。
在表格5中,我们研究了插入h-swish非线性的选择以及使用优化实现与朴素实现相比的改进。可以看出,使用经过优化的h-swish可以节省6毫秒(超过运行时间的10%)。优化的h-swish仅比传统的ReLU多增加1毫秒。图8显示了基于非线性选择和网络宽度的有效前沿。MobileNetV3在网络中间使用h-swish并明显优于ReLU。有趣的是,将h-swish添加到整个网络比扩展网络的插值前沿略好。在图9中,我们展示了各种组件的引入如何沿着延迟/准确性曲线移动。
表格4. 量化表现。所有的延迟都以毫秒为单位。推理延迟是使用相应的Pixel 1/2/3设备上的单个大内核进行测量的。
Table 4.Quantized performance.All latencies are in ms.The inference latency is measured using a single large core on the re spective Pixel 1/2/3 device
| 网络模型 | Top-1 | P-1 | P-2 | P-3 |
| V3-Large 1.0 | 73.8 | 44 | 42.5 | 31.7 |
| V2 1.0 | 70.9 | 52 | 48.3 | 37.0 |
| V3-Small | 64.9 | 64.9 | 15.5 | 10.7 |
| V2 0.35 | 57.2 | 57.2 | 16.7 | 11.9 |
表5.非线性对MobileNetV3-Large的影响。在h-swish @ N,N表示启用h-swish的第一层中的通道数。第三列显示了未经优化的h-swish运行时间。Top-1精度在ImageNet上,延迟以毫秒为单位。
Table 5.Effect of non-linearities on MobileNetV3-Large.In h-swish @N,N denotes the number of channels,in the first layer that has h-swish enabled.The third column shows the runtime without optimized h-swish.Top-1 accuracy is on ImageNet and latency is in ms.
| Top-1 | P-1 | P-1(no-opt) | |
| V3-Large 1.0 | 75.2 | 51.4 | 57.5 |
| ReLU | 74.5(-.7%) | 50.5(-.1%) | 50.5 |
| h-swish @16 | 75.4(+.2%) | 53.5(+4%) | 68.9 |
| h-swish @112 | 75.0(-.3%) | 51(-.5%) | 54.4 |
表6. 在COCO测试集上,SSDLite使用不同的主干网络进行目标检测的结果。y:在C4和C5之间的块中的通道数减少了一半。
Table 6.Object detection results of SSDLite with different back bones on COCO test set.y:Channels in the blocks between C4 and C5 are reduced by a factor of 2.
| BackBone | mAP | 延时(ms) | Params(M) | Madds(B) |
| V1 | 22.2 | 228 | 5.1 | 1.3 |
| V2 | 22.1 | 162 | 4.3 | 0.80 |
| MnasNet | 23.0 | 174 | 4.88 | 0.84 |
| V3 | 22.0 | 137 | 4.97 | 0.62 |
| V3+ | 22.0 | 119 | 3.22 | 0.51 |
| V2 0.35 | 13.7 | 66 | 0.93 | 0.16 |
| V2 0.5 | 16.6 | 79 | 1.54 | 0.27 |
| MansNet 0.35 | 15.6 | 68 | 1.02 | 0.18 |
| MansNet 0.35 | 18.5 | 85 | 1.68 | 0.29 |
| V3-Small | 16.0 | 52 | 2.49 | 0.21 |
| V3-Small | 16.1 | 43 | 1.77 | 0.16 |
6.4.语义分割 在本小节中,我们使用 MobileNetV2 [39] 和提出的 MobileNetV3 作为移动端语义分割任务的网络骨干。此外,我们比较了两种分割头。第一种被称为 R-ASPP,是在 [39] 中提出的一个减少设计的空洞空间金字塔池化模块 [7,8,9],仅采用了由 1×1 卷积和全局平均池化操作 [29,50] 组成的两个分支。在本文中,我们提出了另一种轻量级分割头,称为 Lite R-ASPP(或 LR-ASPP),如图 10 所示。相对于 R-ASPP,Lite R-ASPP 在全局平均池化方面采用了一种类似于 Squeeze-and-Excitation 模块 [20] 的方式,其中我们使用一个大的池化内核和一个大的步长(以节省一些计算),并且在模块中仅采用一个 1×1 卷积。我们采用空洞卷积 [18,40,33,6] 来提取 MobileNetV3 的最后一个块的更密集特征,并进一步添加低级特征的跳跃连接 [30] 来捕捉更详细的信息。我们在 Cityscapes 数据集 [10] 上使用 mIOU [14] 度量,仅使用“fine”注释来进行实验。我们采用与 [8,39] 相同的训练协议。所有的模型都是从头开始训练,没有预先在 ImageNet [38] 上进行预训练,并且使用单一尺度的输入进行评估。与目标检测类似,我们观察到我们可以将网络骨干的最后一个块中的通道数减少一半,而不会显著降低性能。我们认为这是因为骨干是为 1000 类 ImageNet 图像分类 [38] 设计的,而在 Cityscapes 上只有 19 类,意味着骨干中存在一些通道冗余。我们在表 7 中报告了 Cityscapes 验证集的结果。如表所示,我们观察到:(1)将骨干网络最后一个块中的通道数减少一半显著提高了速度,同时保持了类似的性能(第一行与第二行,第五行与第六行),(2)“DNL” 模型的性能略优于 “DMV3-large” 模型,因为后者在通道数量减少的情况下忽略了全连接层。

表格7.在Cityscapes验证集上的语义分割结果。RF2:将最后一个块中的过滤器减少一半。V2 0.5和V2 0.35是MobileNetV2,深度倍增器分别为0.5和0.35。SH:分割头,其中×使用了R-ASPP,而X使用了提出的LR-ASPP。F:用于分割头的过滤器数量。CPU(f):对于全分辨率输入(即1024×2048),在Pixel 3的单个大内核上测量的CPU时间(浮点数)。CPU(h):相对于半分辨率输入(即512×1024)测量的CPU时间。第8行和第11行是我们的MobileNetV3分割候选者。
Table 7.Semantic segmentation results on Cityscapes val set.RF2:Reduce the Filters in the last block by a factor of 2.V2 0.5 and V2 0.35 are MobileNetV2 with depth multiplier =0.5 and 0.35,respectively.SH:Segmentation Head,where ×employs the R-ASPP while X employs the proposed LR-ASPP.F:Number of Filters used in the Segmentation Head.CPU (f):CPU time measured on a single large core of Pixel 3 (floating point)w.r.t.a full-resolution input (i.e.,1024 ×2048).CPU (h):CPU time measured w.r.t.a half-resolution input (i.e.,512 ×1024).Row 8,and 11 are our MobileNetV3 segmentation candidates.
| N | Backbone | RF2 | SH | F | mIOU | Params | MAdds | CPU(f) | CPU(h) |
| 1 | V2 | - | × | 256 | 72.84 | 2.11M | 21.29B | 3.90s | 1.02s |
| 2 | V2 | √ | × | 256 | 72.56 | 1.15M | 13.68B | 3.03s | 793ms |
| 3 | V2 | √ | √ | 256 | 72.97 | 1.02M | 12.83B | 2.98s | 789ms |
| 4 | V2 | √ | √ | 128 | 72.74 | 0.98M | 12.57B | 2.89s | 766ms |
| 5 | V3 | - | × | 256 | 72.64 | 3.60M | 18.43B | 3.55s | 906ms |
| 6 | V3 | √ | × | 256 | 71.94 | 1.76M | 11.24B | 2.60s | 668ms |
| 7 | V3 | √ | √ | 256 | 72.37 | 1.63M | 10.33B | 2.55s | 659ms |
| 8 | V3 | √ | √ | 128 | 72.36 | 1.51M | 9.47B | 2.47s | 657ms |
| 9 | V2 0.5 | √ | √ | 128 | 68.57 | 0.28M | 4.00B | 1.59s | 415ms |
| 10 | V2 0.35 | √ | √ | 128 | 66.83 | 0.16M | 2.54B | 1.27s | 354ms |
| 11 | V3-Small | √ | √ | 128 | 68.38 | 0.47M | 2.90B | 1.21s | 327ms |
表8:Cityscapes测试数据集上的语义分割结果。OS:输出步幅,即输入图像空间分辨率与骨干输出分辨率的比率。当OS=16时,在骨干网络的最后一个块中应用空洞卷积。当OS=32时,不使用空洞卷积。MAdds(f):相对于全分辨率输入(即1024×2048)测量的乘积-加法运算量。MAdds(h):相对于半分辨率输入(即512×1024)测量的乘积-加法运算量。CPU(f):相对于全分辨率输入(即1024×2048),在Pixel 3的单个大核心上测量的CPU时间(浮点运算)。CPU(h):相对于半分辨率输入(即512×1024)测量的CPU时间。ESPNet [31、32]和CCC2 [34]采用半分辨率输入,而我们的模型直接采用全分辨率输入。
Table 8.Semantic segmentation results on Cityscapes test set.OS:Output Stride,the ratio of input image spatial resolution to back bone output resolution.When OS =16,atrous convolution is ap plied in the last block of backbone.When OS =32,no atrous convolution is used.MAdds (f):Multiply-Adds measured w.r.t.a full-resolution input (i.e.,1024 ×2048).MAdds (h):Multiply Adds measured w.r.t.a half-resolution input (i.e.,512 ×1024).CPU (f):CPU time measured on a single large core of Pixel 3 (floating point)w.r.t.a full-resolution input (i.e.,1024 ×2048).CPU (h):CPU time measured w.r.t.a half-resolution input (i.e.,512×1024).ESPNet [31,32]and CCC2 [34]take half resolution inputs,while our models directly take full-resolution inputs.
| Backbone | OS | mIOU | Madds(f) | Madds(h) | CPU(f) | CPU(h) |
| V3 | 16 | 72.6 | 9.74B | 2.48B | 2.47s | 657ms |
| V3 | 32 | 72.0 | 7.74B | 1.98B | 2.06s | 534ms |
| V3-Small | 16 | 69.4 | 2.90B | 0.74B | 1.21s | 327ms |
| V3-Small | 32 | 68.3 | 2.06B | 0.53B | 1.03s | 275ms |
| ESPNetv2 | - | 66.2 | - | 2.7B | - | - |
| CCC2 | - | 62.0 | - | 3.15B | - | - |
| ESPNetv1 | - | 60.3 | - | 4.5B | - | - |
该表格展示了在Cityscapes测试集上进行语义分割的结果。其中列举了Backbone、OS、mIOU、MAdds、CPU等指标。 Backbone代表了模型的主干网络,包括V3和V3-Small等。OS代表了输出步幅,即输入图像空间分辨率与主干网络输出分辨率之间的比率。当OS=16时,在主干网络的最后一个块中应用了空洞卷积;当OS=32时,则没有使用空洞卷积。 mIOU代表平均交并比,是评价语义分割模型性能的一项重要指标。MAdds (f)和MAdds (h)分别代表模型的计算量,测量了在完整输入(1024×2048)和半分辨率输入(512×1024)下的乘加操作数。CPU (f)和CPU (h)分别代表模型运行时间,测量了在完整输入和半分辨率输入下单个大型Pixe(浮点数)的CPU时间。 该表格还列出了ESPNetv2、CCC2和ESPNetv1等模型在Cityscapes测试集上的结果。其中,ESPNetv2和CCC2采用半分辨率输入,而本文提出的模型直接采用完整分辨率输入。
1.MobileNetv3.py(pytorch实现)
from typing import Callable, List, Optional
import torch
from torch import nn, Tensor
from torch.nn import functional as F
from functools import partial
def _make_divisible(ch, divisor=8, min_ch=None):
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor/2) // divisor * divisor)
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class ConvBNActivation(nn.Sequential):
def __init__(self,
in_planes: int,
out_planes: int,
kernel_size: int=3,
stride: int=1,
groups: int=1,
norm_layer: Optional[Callable[..., nn.Module]]=None,
activation_layer: Optional[Callable[..., nn.Module]]=None):
padding = (kernel_size - 1) // 2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.BatchNorm2d
super(ConvBNActivation, self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer(inplace=True))
class SqueezeExcitation(nn.Module):
def __init__(self, input_c:int, squeeze_factor:int=4):
super(SqueezeExcitation, self).__init__()
squeeze_c = _make_divisible(input_c // squeeze_factor, 8)
self.fc1 = nn.Conv2d(input_c, squeeze_c, 1)
self.fc2 = nn.Conv2d(squeeze_c, input_c, 1)
def forward(self, x:Tensor) -> Tensor:
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = F.relu(scale, inplace=True)
scale = self.fc2(scale)
scale = F.hardsigmoid(scale, inplace=True)
return scale * x
class InvertedResidualConfig:
def __init__(self,
input_c:int,
kernel:int,
expanded_c:int,
out_c:int,
use_se:bool,
activation:str,
stride:int,
width_multi:float):
self.input_c = self.adjust_channels(input_c, width_multi)
self.kernel = kernel
self.expanded_c = self.adjust_channels(expanded_c, width_multi)
self.out_c = self.adjust_channels(out_c, width_multi)
self.use_se = use_se
self.use_hs = activation == 'HS'
self.stride = stride
@staticmethod
def adjust_channels(channels:int, width_multi:float):
return _make_divisible(channels * width_multi, 8)
class InvertedResidual(nn.Module):
def __init__(self,
cnf: InvertedResidualConfig,
norm_layer: Callable[..., nn.Module]):
super(InvertedResidual, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)
layers: List[nn.Module] = []
activation_layer = nn.Hardswish if cnf.use_hs else nn.ReLU
if cnf.expanded_c != cnf.input_c:
layers.append(ConvBNActivation(cnf.input_c,
cnf.expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer))
layers.append(ConvBNActivation(cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=cnf.kernel,
groups=cnf.expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer))
if cnf.use_se:
layers.append(SqueezeExcitation(cnf.expanded_c))
layers.append(ConvBNActivation(cnf.expanded_c,
cnf.out_c,
kernel_size=1,norm_layer=norm_layer,
activation_layer=nn.Identity))
self.block = nn.Sequential(*layers)
self.out_channels = cnf.out_c
self.is_strides = cnf.stride > 1
def forward(self, x:Tensor) -> Tensor:
result = self.block(x)
if self.use_res_connect:
result += x
return result
class MobileNetV3(nn.Module):
def __init__(self,
inverted_residual_setting: List[InvertedResidualConfig],
last_channel:int,
num_classes:int=1000,
block:Optional[Callable[..., nn.Module]]=None,
norm_layer:Optional[Callable[...,nn.Module]]=None):
super(MobileNetV3, self).__init__()
if not inverted_residual_setting:
raise ValueError("The inverted_residual_setting should not be empty.")
elif not (isinstance(inverted_residual_setting, List) and
all([isinstance(s, InvertedResidualConfig) for s in inverted_residual_setting])):
raise TypeError("The inverted_residual_setting should be List[InvertedResidualConfig]")
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(nn.BatchNorm2d, eps=0.001, momentum=0.01)
layers: List[nn.Module] = []
firstconv_output_c = inverted_residual_setting[0].input_c
layers:List[nn.Module] = []
firstconv_output_c = inverted_residual_setting[0].input_c
layers.append(ConvBNActivation(3,
firstconv_output_c,
kernel_size=3,
stride=2,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
for cnf in inverted_residual_setting:
layers.append(block(cnf, norm_layer))
lastconv_input_c = inverted_residual_setting[-1].out_c
lastconv_output_c = 6 * lastconv_input_c
layers.append(ConvBNActivation(lastconv_input_c,
lastconv_output_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
self.features = nn.Sequential(*layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.classifier = nn.Sequential(nn.Linear(lastconv_output_c, last_channel),
nn.Hardswish(inplace=True),
nn.Dropout(p=0.2, inplace=True),
nn.Linear(last_channel, num_classes))
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0.01)
nn.init.zeros_(m.bias)
def _forward_impl(self, x:Tensor) -> Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def forward(self, x:Tensor) -> Tensor:
return self._forward_impl(x)
def mobilenet_v3_large(num_classes: int=1000,
reduced_tail: bool=False) -> MobileNetV3:
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduced_divider = 2 if reduced_tail else 1
Inverted_residual_setting = [
bneck_conf(16, 3, 16, 16, False, 'RE', 1),
bneck_conf(16, 3, 64, 24, False, "RE", 2),
bneck_conf(24, 3, 72, 24, False, 'RE', 1),
bneck_conf(24, 5, 72, 40, True, 'RE', 2),
bneck_conf(40, 5, 120, 40, True, 'RE', 1),
bneck_conf(40, 5, 120, 40, True, 'RE', 1),
bneck_conf(40, 3, 240, 80, False, 'HS', 2),
bneck_conf(80, 3, 200, 80, False, 'HS', 1),
bneck_conf(80, 3, 184, 80, False, 'HS', 1),
bneck_conf(80, 3, 184, 80, False, 'HS', 1),
bneck_conf(80, 3, 480, 112, True, 'HS', 1),
bneck_conf(112, 3, 672, 112, True, 'HS', 1),
bneck_conf(112, 5, 672, 160, True, 'HS', 2),
bneck_conf(160 // reduced_divider, 5, 960 // reduced_divider, 160 // reduced_divider, True, 'HS', 1),
bneck_conf(160 // reduced_divider, 5, 960 // reduced_divider, 160 // reduced_divider, True, 'HS', 1)
]
last_channel = adjust_channels(1280 // reduced_divider)
return MobileNetV3(Inverted_residual_setting=Inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
def mobilenet_v3_small(num_classes: int=1000,
reduced_tail: bool=False) -> MobileNetV3:
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduced_divider = 2 if reduced_tail else 1
Inverted_residual_setting = [
bneck_conf(16, 3, 16, 16, True, 'RE', 2),
bneck_conf(16, 3, 72, 24, False, 'RE', 2),
bneck_conf(24, 3, 88, 24, False, 'RE', 1),
bneck_conf(24, 5, 96, 40, True, 'HS', 2),
bneck_conf(40, 5, 240, 40, True, 'HS', 1),
bneck_conf(40, 5, 240, 40, True, 'HS', 1),
bneck_conf(40, 5, 120, 48, True, 'HS', 1),
bneck_conf(48, 5, 144, 48, True, 'HS', 1),
bneck_conf(48, 5, 288, 96 // reduced_divider, True, 'HS', 2),
bneck_conf(96 // reduced_divider, 5, 576 // reduced_divider, 96 // reduced_divider, True, 'HS', 1),
bneck_conf(96 // reduced_divider, 5, 576 // reduced_divider, 96 // reduced_divider, True, 'HS', 1),
]
last_channel = adjust_channels(1024 // reduced_divider)
return MobileNetV3(Inverted_residual_setting=Inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)总结
在本文中,我们介绍了MobileNetV3 Large和Small模型,展示了移动分类、检测和分割中新的最先进技术。我们描述了我们的多个网络架构搜索算法的努力以及网络设计的进步,以提供下一代移动模型。我们还展示了如何以量化友好和高效的方式调整Swish等非线性函数,并引入了“挤压和激活”技术,将它们作为移动模型领域的有效工具。我们还介绍了一种称为LR-ASPP的轻量级分割解码器的新形式。虽然如何最好地将自动搜索技术与人类直觉结合起来仍然是一个问题,但我们很高兴呈现这些第一批积极的结果,将继续完善方法。致谢:我们要感谢Andrey Zhmoginov、Dmitry Kalenichenko、Menglong Zhu、Jon Shlens、Xiao Zhang、Benoit Jacob、Alex Stark、Achille Brighton和Sergey Ioffe提供的有用反馈和讨论。