ChatGLM Efficient Tuning
基于

PEFT 的高效 ChatGLM-6B 微调。

[ English | 中文 ]
更新日志
[23/06/05] 现在我们实现了 4 比特的 LoRA 训练(也称 QLoRA)。请尝试使用 --quantization_bit 4 参数进行 4 比特量化微调。(实验性功能)
[23/06/01] 我们开源了支持 LLaMA 和 BLOOM 系列模型的高效微调框架,如果您感兴趣请关注我们的 LLaMA-Efficient-Tuning 项目。
[23/06/01] 我们新增了一个使用监督微调和 RLHF 训练医疗问答模型的例子,请移步 covid_doctor.md 查阅。
[23/05/19] 现在我们支持了在模型训练时使用验证集评估性能。请尝试使用 --dev_ratio 参数指定验证集大小。
[23/04/29] 现在我们实现了 RLHF(基于人类反馈的强化学习) 训练!我们提供了几个运行 RLHF 的例子,具体内容请移步 examples 文件夹。
[23/04/25] 我们新增了一个使用自定义数据集分布式训练的例子,请移步 ads_generation.md 查阅。
[23/04/20] 我们的项目在 12 天内获得了 100 个 Star!祝贺!
[23/04/20] 我们新增了一个修改模型自我认知的例子,请移步 alter_self_cognition.md 查阅。
[23/04/19] 现在我们实现了模型融合!请尝试使用 --checkpoint_dir checkpoint1,checkpoint2 参数训练融合 LoRA 权重后的模型。
[23/04/18] 现在可以微调量化模型了!请尝试使用 quantization_bit 参数进行 4 比特或 8 比特量化微调。
[23/04/12] 现在我们加入了断点训练支持!请尝试给定 --checkpoint_dir 参数加载指定的模型断点。
[23/04/11] 现在我们实现了数据集组合训练!请尝试使用 --dataset dataset1,dataset2 参数进行组合训练。
数据集
目前我们实现了针对以下数据集的支持:
- Stanford Alpaca
- Stanford Alpaca (Chinese)
- GPT-4 Generated Data
- BELLE 2M
- BELLE 1M
- BELLE 0.5M
- BELLE Dialogue 0.4M
- BELLE School Math 0.25M
- BELLE Multiturn Chat 0.8M
- Guanaco Dataset
- Firefly 1.1M
- CodeAlpaca 20k
- Alpaca CoT
- Web QA (Chinese)
- UltraChat
使用方法请参考 data/README.md 文件。
部分数据集的使用需要确认,我们推荐使用下述命令登录您的 HuggingFace 账户。
pip install --upgrade huggingface_hub huggingface-cli login
微调方法
目前我们实现了针对以下高效微调方法的支持:
- LoRA
- 仅微调低秩适应器。
- P-Tuning V2
- 仅微调前缀编码器。
- Freeze
- 仅微调后几层的全连接层。
软件依赖
- Python 3.8+, PyTorch 1.13.1
-
Transformers, Datasets, Accelerate, PEFT, TRL
- protobuf, cpm_kernels, sentencepiece
- jieba, rouge_chinese, nltk(用于评估)
- gradio, mdtex2html(用于网页端交互)
以及 强而有力的 GPU!
如何使用
数据准备(可跳过)
关于数据集文件的格式,请参考 data/example_dataset 文件夹的内容。构建自定义数据集时,既可以使用单个 .json 文件,也可以使用一个数据加载脚本和多个文件。
注意:使用自定义数据集时,请更新 data/dataset_info.json 文件,该文件的格式请参考 data/README.md。
环境搭建(可跳过)
git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git conda create -n chatglm_etuning python=3.10 conda activate chatglm_etuning cd ChatGLM-Efficient-Tuning pip install -r requirements.txt
对于 Windows 用户,若要启用 LoRA 或 Freeze 的量化微调,请下载预构建的 bitsandbytes 包,目前仅支持 CUDA 11.6 和 11.7。
pip install https://github.com/acpopescu/bitsandbytes/releases/download/v0.37.2-win.1/bitsandbytes-0.37.2-py3-none-any.whl
单 GPU 微调训练
CUDA_VISIBLE_DEVICES=0 python src/train_sft.py \
--do_train \
--dataset alpaca_gpt4_zh \
--finetuning_type lora \
--output_dir path_to_sft_checkpoint \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--fp16
关于参数信息,请查阅我们的维基。
多 GPU 分布式微调
accelerate config # 首先配置分布式环境 accelerate launch src/train_sft.py # 参数同上
注意:若您使用 LoRA 方法进行微调,请指定以下参数 --ddp_find_unused_parameters False 来避免报错。
奖励模型训练
CUDA_VISIBLE_DEVICES=0 python src/train_rm.py \
--do_train \
--dataset comparison_gpt4_zh \
--finetuning_type lora \
--output_dir path_to_rm_checkpoint \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 1e-5 \
--num_train_epochs 1.0 \
--fp16
RLHF 训练
CUDA_VISIBLE_DEVICES=0 python src/train_ppo.py \
--do_train \
--dataset alpaca_gpt4_zh \
--finetuning_type lora \
--checkpoint_dir path_to_sft_checkpoint \
--reward_model path_to_rm_checkpoint \
--output_dir path_to_ppo_checkpoint \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 1e-5 \
--num_train_epochs 1.0 \
--fp16
指标评估(BLEU分数和汉语ROUGE分数)
CUDA_VISIBLE_DEVICES=0 python src/train_sft.py \
--do_eval \
--dataset alpaca_gpt4_zh \
--checkpoint_dir path_to_checkpoint \
--output_dir path_to_eval_result \
--per_device_eval_batch_size 8 \
--max_samples 50 \
--predict_with_generate
模型预测
CUDA_VISIBLE_DEVICES=0 python src/train_sft.py \
--do_predict \
--dataset alpaca_gpt4_zh \
--checkpoint_dir path_to_checkpoint \
--output_dir path_to_predict_result \
--per_device_eval_batch_size 8 \
--max_samples 50 \
--predict_with_generate
命令行测试
python src/cli_demo.py \
--checkpoint_dir path_to_checkpoint
浏览器测试
python src/web_demo.py \
--checkpoint_dir path_to_checkpoint
导出微调模型
python src/export_model.py \
--checkpoint_dir path_to_checkpoint \
--output_dir path_to_export
硬件需求
| 微调方法 | 批处理大小 | 模式 | GPU显存 | 速度 |
|---|---|---|---|---|
| LoRA (r=8) | 16 | FP16 | 28GB | 8ex/s |
| LoRA (r=8) | 8 | FP16 | 24GB | 8ex/s |
| LoRA (r=8) | 4 | FP16 | 20GB | 8ex/s |
| LoRA (r=8) | 4 | INT8 | 10GB | 8ex/s |
| LoRA (r=8) | 4 | INT4 | 8GB | 8ex/s |
| P-Tuning (p=16) | 4 | FP16 | 20GB | 8ex/s |
| P-Tuning (p=16) | 4 | INT8 | 16GB | 8ex/s |
| P-Tuning (p=16) | 4 | INT4 | 12GB | 8ex/s |
| Freeze (l=3) | 4 | FP16 | 24GB | 8ex/s |
| Freeze (l=3) | 4 | INT8 | 12GB | 8ex/s |
| 奖励模型训练方法 | 批处理大小 | 模式 | GPU显存 | 速度 |
|---|---|---|---|---|
| LoRA (r=8) + rm | 4 | FP16 | 22GB | - |
| LoRA (r=8) + rm | 1 | INT8 | 11GB | - |
| RLHF 训练方法 | 批处理大小 | 模式 | GPU显存 | 速度 |
|---|---|---|---|---|
| LoRA (r=8) + ppo | 4 | FP16 | 23GB | - |
| LoRA (r=8) + ppo | 1 | INT8 | 12GB | - |
注:
r为LoRA 维数大小,p为前缀词表大小,l为微调层数,ex/s为每秒训练的样本数。gradient_accumulation_steps参数设置为1。上述结果均来自于单个 Tesla V100 GPU,仅供参考。
微调 ChatGLM 的例子
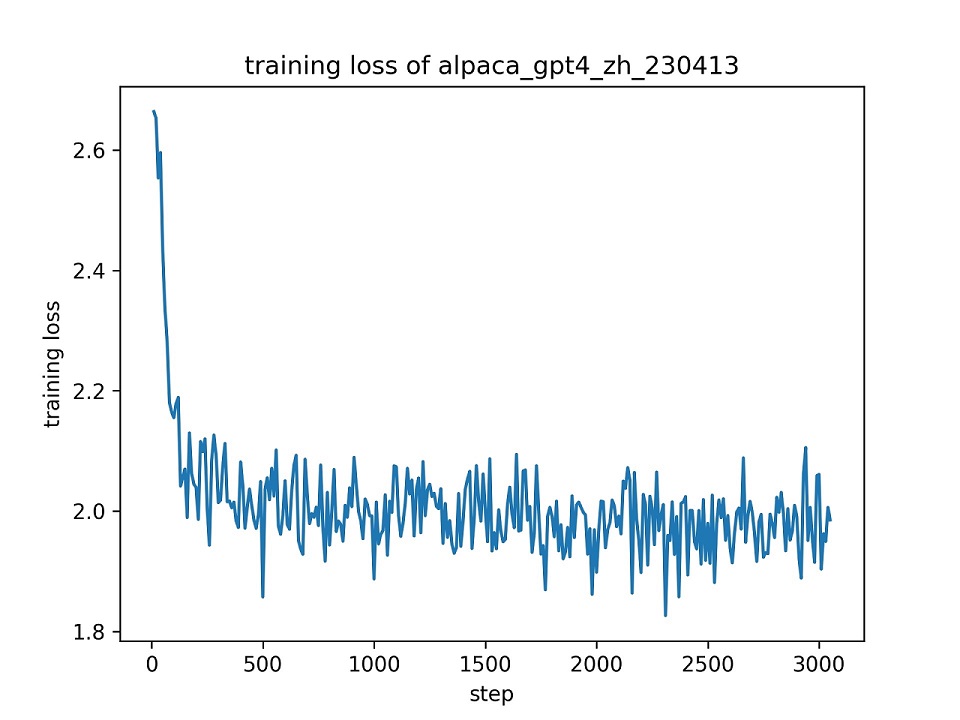
训练结果
我们使用整个 alpaca_gpt4_zh 数据集微调 ChatGLM 模型,使用秩为 8 的 LoRA 方法,使用默认超参数进行单轮训练。下图为训练损失变化曲线。
评估结果
我们选择 alpaca_gpt4_zh 数据集中的前一百条数据来评估微调后的 ChatGLM 模型,并计算 BLEU 和中文 ROUGE 分数。下表为评估结果。
| 分数 | 原版模型 | FZ (l=2) | PT (p=16) | LoRA (r=8) |
|---|---|---|---|---|
| BLEU-4 | 15.75 | 16.85 | 16.06 | 17.01 (+1.26) |
| Rouge-1 | 34.51 | 36.62 | 34.80 | 36.77 (+2.26) |
| Rouge-2 | 15.11 | 17.04 | 15.32 | 16.83 (+1.72) |
| Rouge-l | 26.18 | 28.17 | 26.35 | 28.86 (+2.68) |
| 训练参数 | / | 4.35% | 0.06% | 0.06% |
FZ:Freeze 微调,PT:P-Tuning V2 微调(为了与 LoRA 公平比较,我们使用了
pre_seq_len=16),训练参数:可训练参数占全部参数的百分比。
和现有类似项目的比较
- THUDM/ChatGLM-6B
- ChatGLM 基于 P-Tuning v2 微调的官方实现,使用了 ADGEN 数据集。
- 本仓库的代码实现绝大部分参考该项目。我们进一步实现了 LoRA 微调方法。此外,我们动态地将每个批处理数据中的序列进行填充,而非将其填充到模型的最大长度,此改进可以加速模型训练。
- mymusise/ChatGLM-Tuning
- ChatGLM 基于 LoRA 微调的非官方实现,使用了 Stanford Alpaca 数据集。
- 我们借鉴了该项目的一些想法。我们的训练脚本将数据预处理部分集成至训练脚本中,以避免事先生成预处理后的数据。
- ssbuild/chatglm_finetuning
- ChatGLM 基于多种微调方法的非官方实现,使用了 Stanford Alpaca 数据集。
- 我们的训练脚本全部基于 Huggingface transformers 框架实现,不依赖于额外的 deep_training 框架。
- lich99/ChatGLM-finetune-LoRA
- ChatGLM 基于 LoRA 微调的非官方实现,使用了 Stanford Alpaca 数据集。
- 我们利用 Huggingface PEFT 框架来引入最先进的微调方法。
- liucongg/ChatGLM-Finetuning
- ChatGLM 基于参数冻结、LoRA 和 P-Tuning 微调的非官方实现,使用了汽车工业数据集。
- 我们旨在引入更多指令遵循数据集用于微调 ChatGLM 模型。
- yanqiangmiffy/InstructGLM
- ChatGLM 微调的非官方实现,旨在探索 ChatGLM 在指令遵循数据集上的潜力。
- 我们将数据预处理部分集成到训练脚本中。
TODO
- 利用 LangChain 实现能够利用外部知识的基于 ChatGLM 微调模型应用的轻松构建。
- 实现对齐算法使模型对齐人类意图。
- RLHF
- RRHF
- RAFT
- 加入更多中文数据集。
- BELLE
- pCLUE
- CLUECorpus
- GuanacoDataset
- FireflyDataset
- 加入基于 ChatGPT 和 GPT-4 产生的数据集。
- Baize
- GPT-4-LLM
- 实现参数冻结和 P-Tuning 微调方法。
- 支持多GPU训练。
- 加入模型评估脚本。
- 断点加载。
- 量化微调。
- 撰写基于该框架的 ChatGLM 模型微调指南手册。
- 结合模型编辑技术。(例如:MEND)
- 加入 OpenAssistant 对话数据集用于监督微调和意图对齐。
- 加入高质量中文开源指令数据集 COIG。
协议
本仓库的代码依照 Apache-2.0 协议开源。ChatGLM-6B 模型的使用请遵循模型协议。