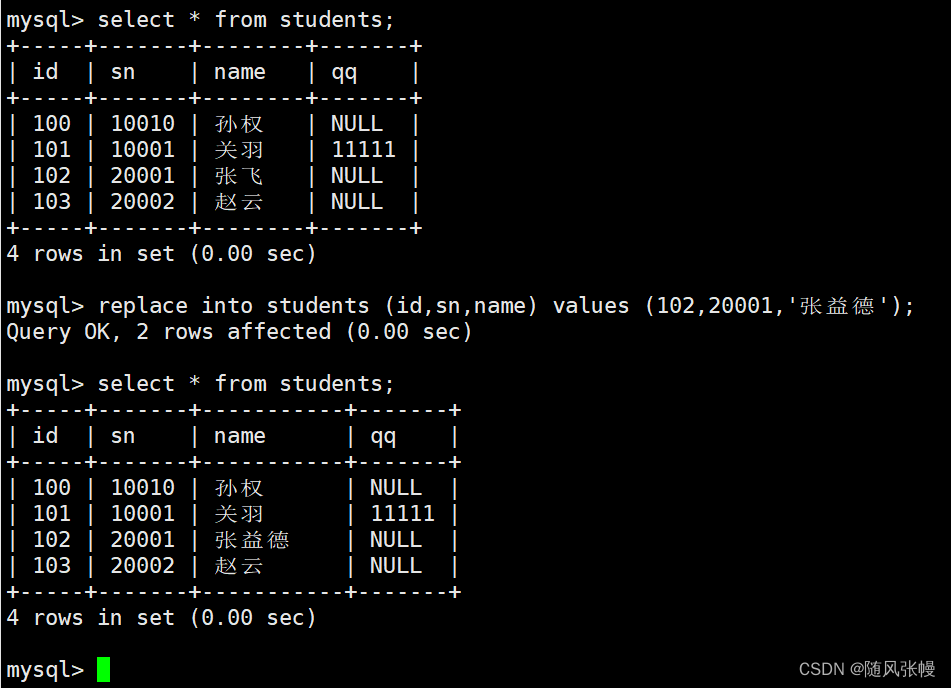
版本情况
kubenetes版本: v1.19.10
docker版本: v20.10.6一、问题经过
早上发现 kubectl delete ns时, 删除namespace一直处于Terminating状态
尝试加上--force参数,执行kubectl delete ns --force,也是一样Terminating当时Terminating截图

1、猜测原因:master节点资源不足
前段时间pod的数量增加,怀疑是master节点机器资源不足导致处理效率问题
目前运行的pod数量

查看Prometheus监控,可以看到master节点的使用率都很低,排除资源不足问题
2、猜测原因:有依赖资源没有释放,如pvc、pod等
执行查看资源情况, 没有发现依赖资源未释放情况,排查依赖资源没有释放问题
kubectl get all -n test
3、猜测原因:k8s本身存在bug,查验源码和官方issue,分析delete namespace过程
查看ns状态,也没有异常情况
kubectl describe ns test使用json查看ns详情
kubectl get ns test -o json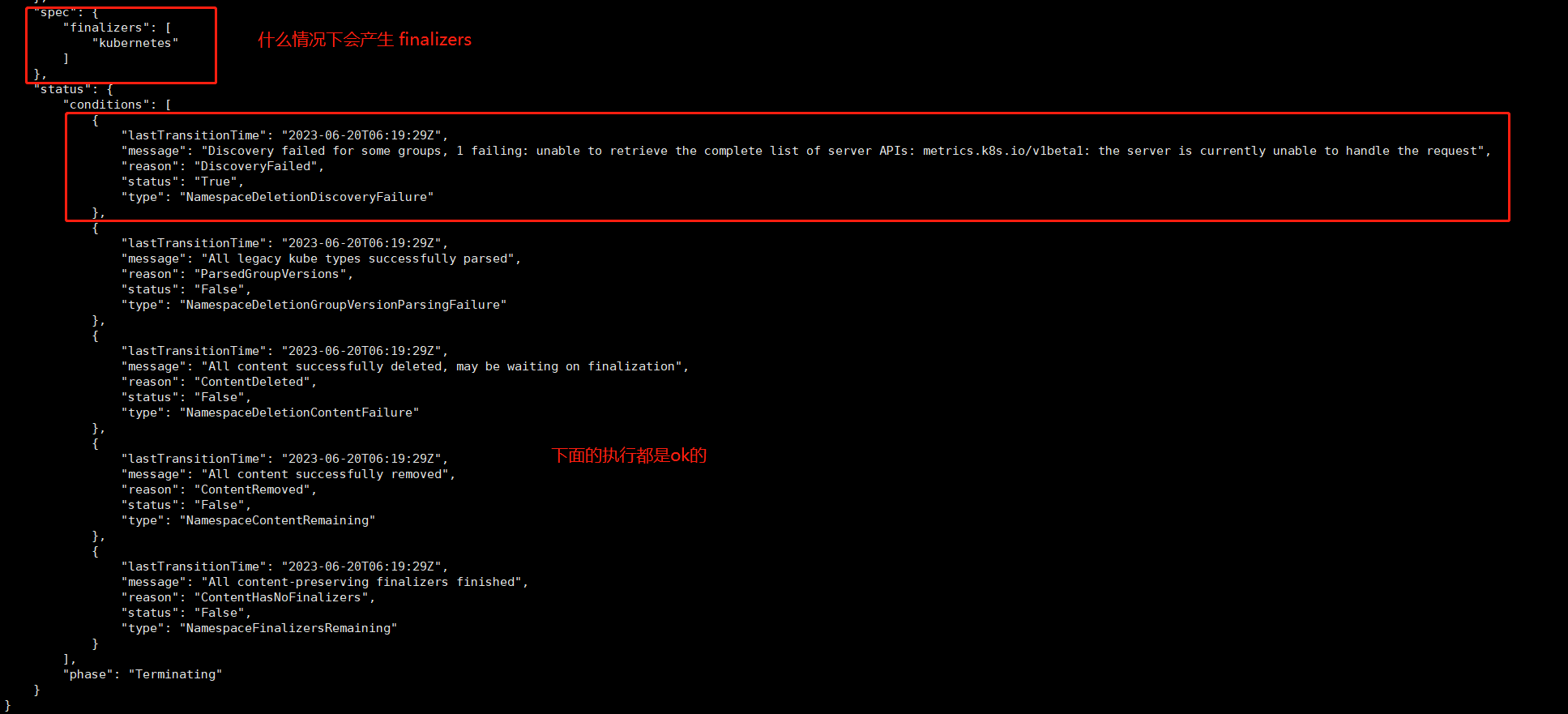
{
"lastTransitionTime": "2023-06-20T06:19:29Z",
"message": "Discovery failed for some groups, 1 failing: unable to retrieve the complete list of server APIs: metrics.k8s.io/v1beta1: the server is currently unable to handle the request",
"reason": "DiscoveryFailed",
"status": "True",
"type": "NamespaceDeletionDiscoveryFailure"
},参考:kubernetes -- 删除namespace的过程以及遇到的bug解决_LanVv的博客-CSDN博客
二、治标不治本删除方法
了解完源码,还是没得到彻底解决方法
网上很多介绍使用api去解决 使用/api/v1/namespaces/${ns}/finalize 去删除namespace, 只能治标不治本,顺便贴上curl的解决方法
# 注意修改ip地址和生成k8s证书
for ns in `kubectl get ns | grep Terminating | awk '{print $1}'`
do
# 获取ns的json
kubectl get namespace ${ns} -o json > /tmp/${ns}.json
# 将spec内容清空, 剔除finalizers
cat ${ns}.json | jq 'del(.spec.finalizers)' > /tmp/del_${ns}.json
# 用api去删除ns
curl --cert /tmp/client.pem --key /tmp/client-key.pem --cacert /tmp/ca.pem -H "Content-Type: application/json" -X PUT --data-binary @/tmp/del_${ns}.json https://master_IP:6443/api/v1/namespaces/${ns}/finalize
# 删除残留文件
rm -f /tmp/del_${ns}.json /tmp/${ns}.json
done参考:k8s删除Terminating状态的命名空间_LanVv的博客-CSDN博客
三、kubeernetes组件日志分析
查看kube-apiserver 503

controller.go:116] loading OpenAPI spec for "v1beta1.metrics.k8s.io" failed with: failed to retrieve openAPI spec, http error: ResponseCode: 503, Body: service unavailable
v1beta1.metrics.k8s.io
http error: ResponseCode: 503, Body: service unavailable 简单明了查看kube-controller-manager

namespace_controller.go:162] deletion of namespace test failed: unable to retrieve the complete list of server APIs: metrics.k8s.io/v1beta1: the server is currently unable to handle the request
也是metrics.k8s.io/v1beta1四、问题解决
具体根因,kube-prometheus项目 的prometheus-adapter服务未Running
kube-prometheus项目地址
https://github.com/prometheus-operator/kube-prometheus
根据kube-apiserver和kube-controller-manager的错误日志定位,metrics.k8s.io/v1beta1这个apiservice有问题
kubectl get apiserver | grep False
metrics.k8s.io/v1beta1是monitoring/prometheus-adapter生成出来的
kubectl -n monitoring get pods | grep prometheus-adapter
查看服务发现,该pod异常了
Back-off pulling image "directxman12/k8s-prometheus-adapter:v0.8.4"
因node not ready 将pod驱逐了,而公司内网在做防火墙升级,禁止了一部分网络,导致pull失败问题解决,解决问题的方式很简单,但可收获了一些排查思路
把服务拉起即可,尽量使用国内镜像仓库/公司级镜像仓库,使用dockerhub,可能发生网络问题
服务起来后

已经变成True状态

再次删除namespace,成功

其他参考:unable to retrieve the complete list of server APIs
- 【k8s错误处理】——unable to retrieve the complete list of server APIs_unable to retrieve connectors_Teingi的博客-CSDN博客
- https://github.com/prometheus-operator/kube-prometheus/issues/275