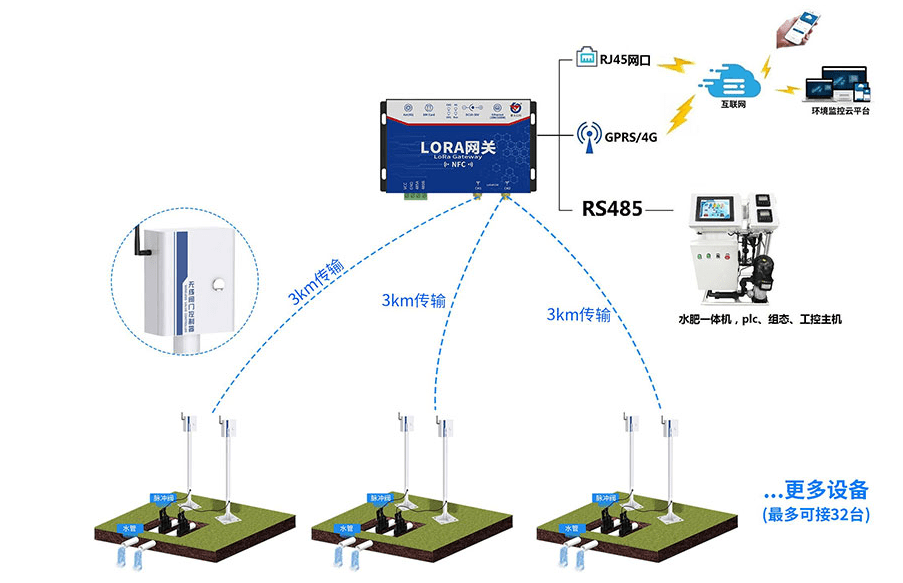
自监督学习中,有一个常用的方法是对比学习;
2. 时间序列的表示学习
1.1 采用对比学习的方式
Time-series representation learning via temporal and contextual contrasting(IJCAI’21)
本文采用对比学习的方式进行时间序列表示学习。首先对于同一个时间序列,使用strong和weak两种数据增强方法生成原始序列的两个view。
Strong Augmentation指的是将原始序列划分成多个片段后打乱顺序,再加入一些随机扰动;
Weak Augmentation指的是对原始序列进行缩放或平移。
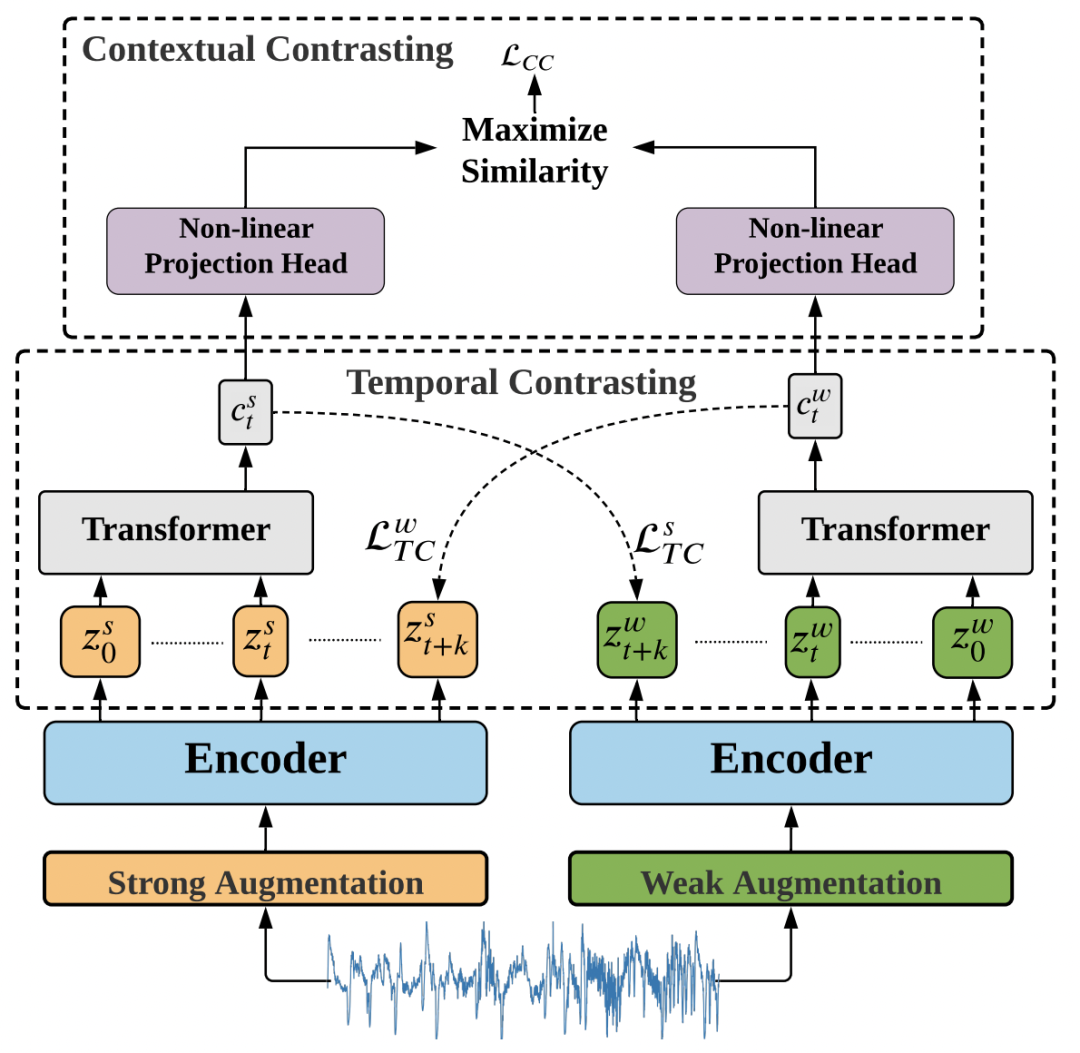
接下来,将strong和weak两个增强的序列输入到一个卷积时序网络中,得到每个序列在每个时刻的表示。文中使用了Temporal Contrasting和Contextual Contrasting两种对比学习方式。
Temporal Contrasting指的是用一种view的context预测另一种view在未来时刻的表示,目标是让该表示和另一种view对应的真实表示更接近,这里使用了Transformer作为时序预测的主体模型,公式如下,其中c表示strong view的Transformer输出,Wk是一个映射函数,用于将c映射到对未来的预测,z是weak view未来时刻的表示:
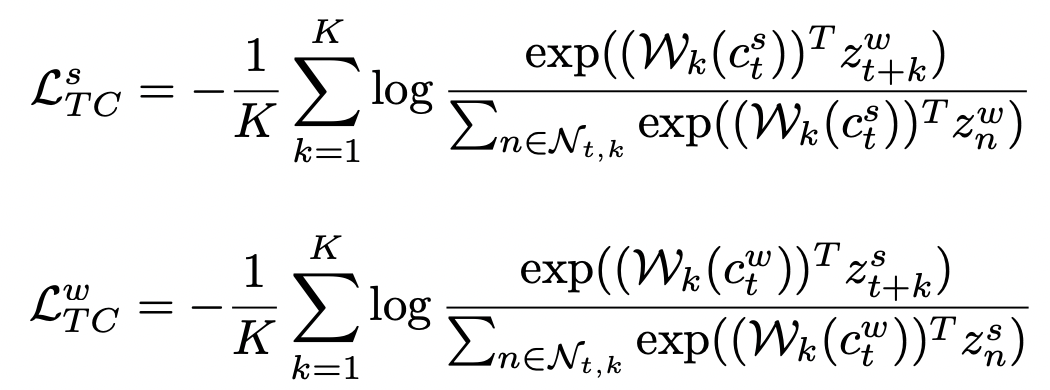
Contextual Contrasting则是序列整体的对比学习,拉近相同序列生成的两个view的距离,让不同序列生成的view距离更远,公式如下,这里和图像对比学习的方式类似:
1.2 采用无监督表示学习
TS2Vec: Towards Universal Representation of Time Series(AAAI’22)
TS2Vec核心思路也是无监督表示学习,通过数据增强的方式构造正样本对,通过对比学习的优化目标让正样本对之间距离,负样本之间距离远。本文的核心点主要在两个方面,第一个是针对时间序列特点的正样本对构造和对比学习优化目标的设计,第二个是结合时间序列特点提出的层次对比学习。
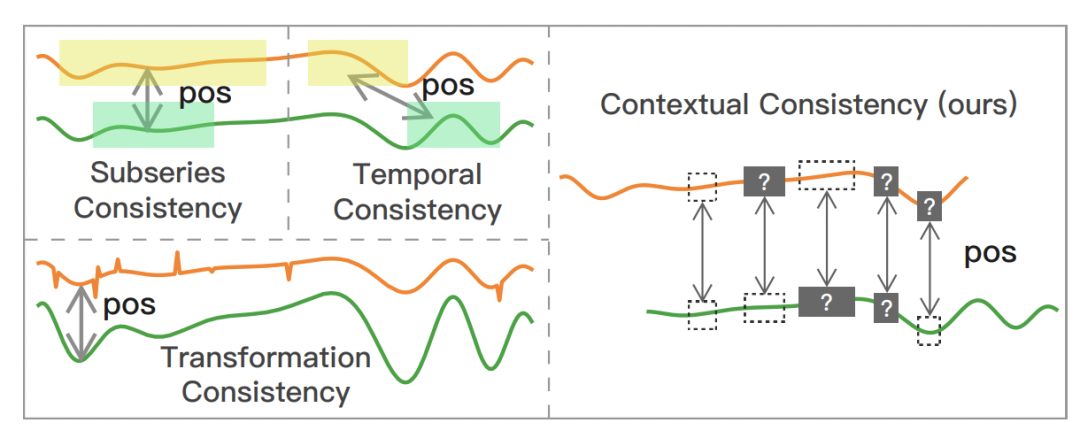
对于正样本对构造方法,本文提出了适合时间序列的正样本对构造方法:Contextual Consistency。Contextual Consistency的核心思路是,两个不同增强视图的时间序列,在相同时间步的表示距离更接近。文中提出两种构造Contextual Consistency正样本对的方法。第一种是Timestamp Masking,在经过全连接后,随机mask一些时间步的向量表示,再通过CNN提取每个时间步的表示。第二种是Random Cropping,选取有公共部分的两个子序列互为正样本对。这两种方法都是让相同时间步的向量表示更近,如上图所示。
TS2Vec的另一个核心点是层次对比学习。时间序列和图像、自然语言的一个重要差异在于,通过不同频率的聚合,可以得到不同粒度的时间序列。例如,天粒度的时间序列,按周聚合可以得到周粒度的序列,按照月聚合可以得到月粒度的序列。为了将时间序列这种层次性融入对比学习中,TS2Vec提出了层次对比学习,算法流程如下。
对于两个互为正样本对的时间序列,最开始通过CNN生成每个时间步向量表示,然后循环使用maxpooling在时间维度上进行聚合,文中使用的聚合窗口为2。每次聚合后,都计算对应时间步聚合向量的距离,让相同时间步距离近。聚合的粒度不断变粗,最终聚合成整个时间序列粒度,逐渐实现instance-level的表示学习。
1.3 多元时间序列表示
A transformer-based framework for multivariate time series representation learning(KDD’22)
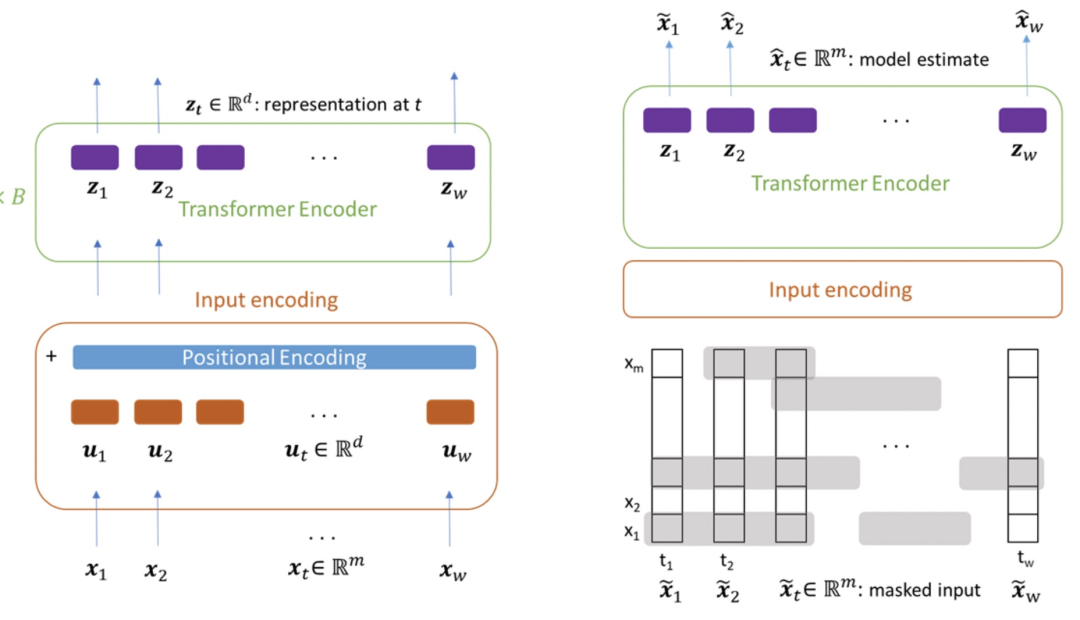
这篇文章借鉴了预训练语言模型Transformer的思路,希望能够在多元时间序列上通过无监督的方法,借助Transformer模型结构,学习良好的多元时间序列表示。本文重点在于针对多元时间序列设计的无监督预训练任务。如下图右侧,对于输入的多元时间序列,会mask掉一定比例的子序列(不能太短),并且每个变量分别mask,而不是mask掉同一段时间的所有变量。预训练的优化目标为还原整个多元时间序列。通过这种方式,让模型在预测被mask掉的部分时,既能考虑前面、后面的序列,也能考虑同一时间段没有被mask的序列。
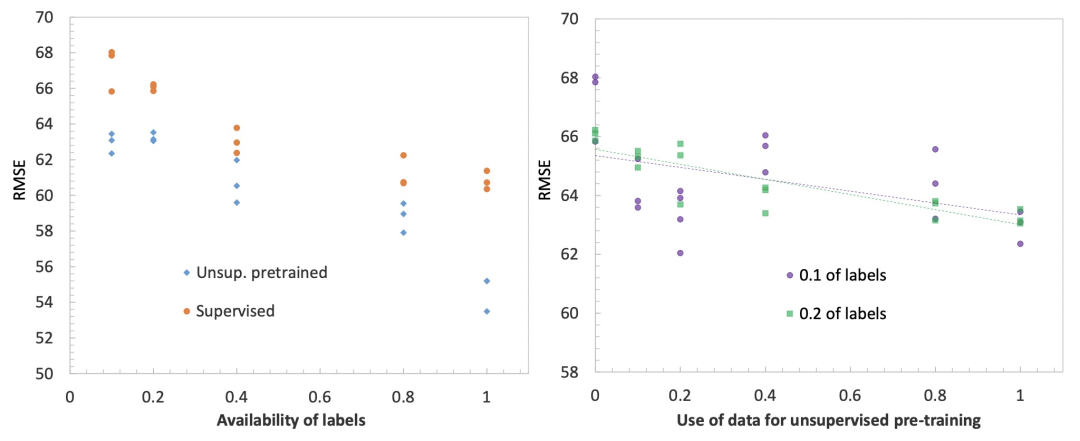
下图展示了无监督预训练时间序列模型对时间序列预测任务带来的效果提升。左侧的图表示,不同有label数据量下,是否使用无监督预训练的RMSE效果对比。可以看到,无论有label数据量有多少,增加无监督预训练都可以提升预测效果。右侧图表示使用的无监督预训练数据量越大,最终的时间序列预测拟合效果越好。
1.4 时序领域采样
本文提出的方法在正负样本的选择上和损失函数的设计上相比上一篇文章有一定区别。首先是正负样本的选择,对于一个以时刻t为中心的时间序列,文中采用一个高斯分布来划定其正样本的采样范围。高斯分布以t为中心,另一个参数是时间窗口的范围。对于时间窗口范围的选择,文中采用了ADF检验的方法选择最优的窗口跨度。如果时间窗口范围过长,可能导致采样的正样本和原样本不相关的情况;如果时间窗口过小,会导致采样的正样本和原样本重叠部分太多。ADF检验可以检测出时间序列在保持稳定的时间窗口,以此选择最合适的采样范围。
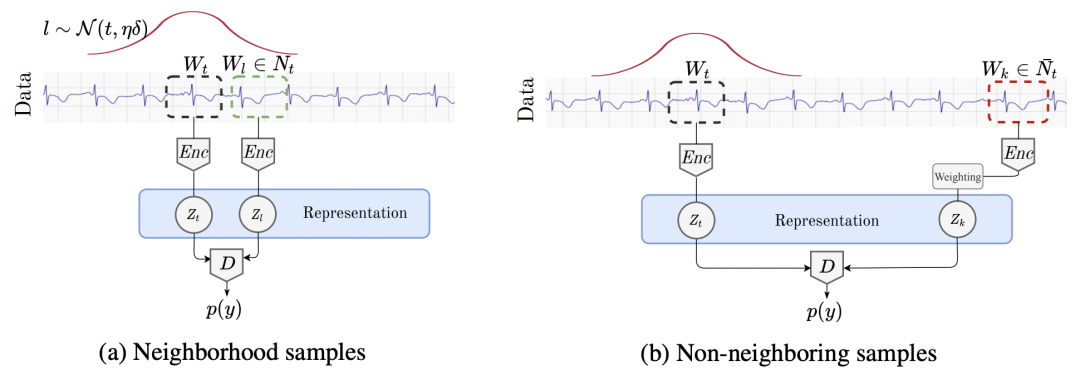
在损失函数方面,文中主要解决的是伪负样本的问题。如果将上面选定的窗口外的样本都视为负样本,很有可能会出现伪负样本的情况,即本来是和原样本相关的,但因为距离原样本比较远而被误认为是负样本。例如时间序列是以年为周期的,时间窗口选择的是1个月,可能会把去年同期的序列认为是负样本。这会影响模型训练,使模型收敛困难。为了解决这个问题,本文将窗口外的样本不视为负样本,而是视为没有无label样本。在损失函数中,给每个样本设定一个权重,这个权重表示该样本为正样本的概率。这种方法也被称为Positive-Unlabeled (PU) learning。最终的损失函数可以表示为如下形式:
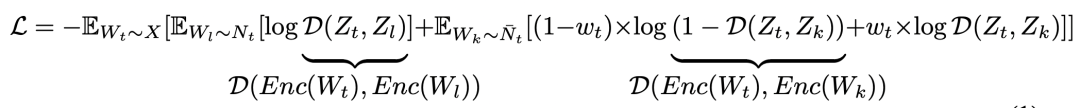
1.5 多变量时间序列
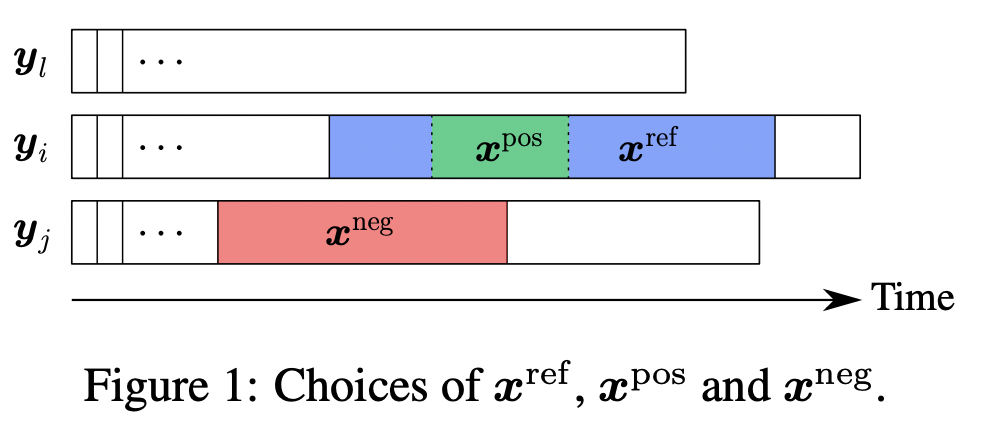
本文的时间序列表示学习方法思路来源于经典的词向量模型CBOW。CBOW中的假设是,一个单词的上下文表示应该和该单词的表示比较近,同时和其他随机采样的单词表示比较远。本文将这种思路应用到时间序列表示学习中,首先需要构造CBOW中的上下文(context)和随机负样本,构造方法如下图所示。首先选择一个时间序列xref,以及xref中的一个子序列xpos。,xref可以看成是xpos的context。同时,随机从其他时间序列,或者当前时间序列的其他时间片段中采样多个负样本xneg。这样就可以构造类似CBOW的损失函数了,让xref和xpos离得近,同时让xref和其他负样本xneg距离远。
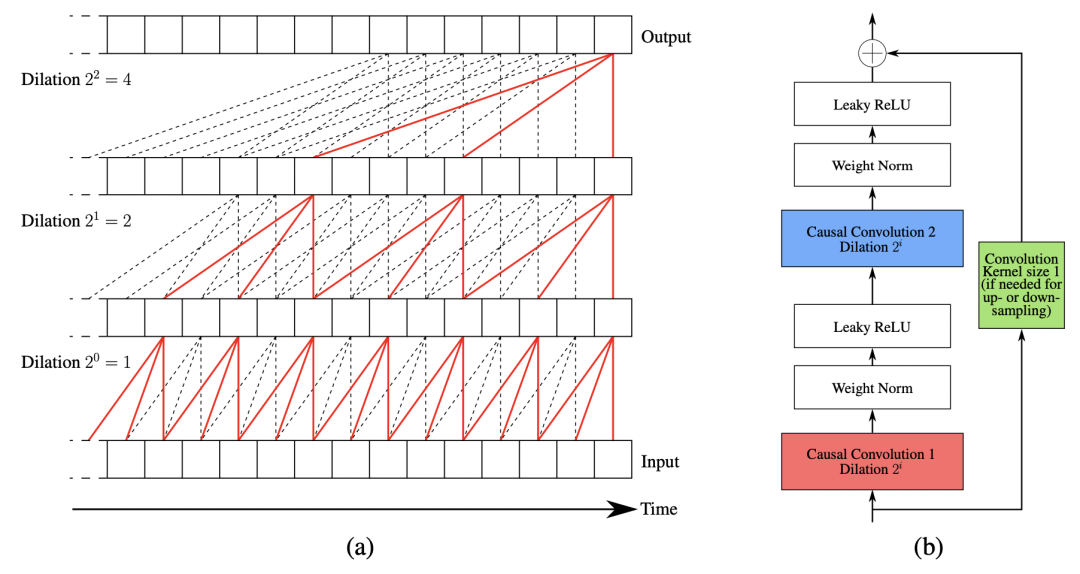
在模型结构上,本文采用了多层空洞卷积的结构,这部分模型结构在之前的文章中有过详细介绍,感兴趣的同学可以参考:12篇顶会论文,深度学习时间序列预测经典方案汇总。
reference
ref1