1、Java Bean 的命名规范
JavaBean 类必须是一个公共类,并将其访问属性设置为 public
JavaBean 类必须有一个空的构造函数:类中必须有一个不带参数的公用构造器,此构造器也应该通过调用各个特性的设置方法来设置特性的缺省值。
一个 JavaBean 类不应有公共实例变量,类变量都为 private 持有值应该通过一组存取方法 (getXxx 和 setXxx) 来访问:对于每个特性,应该有一个带匹配公用 getter 和 setter 方法的专用实例变量。
属性为布尔类型,可以使用 isXxx() 方法代替 getXxx() 方法。
通常属性名是要和 包名、类名、方法名、字段名、常量名作出区别的:
首先:必须用英文,不要用汉语拼音
① 包 (package)
用于将完成不同功能的类分门别类,放在不同的目录(包)下,包的命名规则:将公司域名反转作为包名。比如www.sohu.com 对于包名:每个字母都需要小写。比如:com.sohu.test,该包下的 Test 类的全名是:com.sohu.Test.Java
如果定义类的时候没有使用 package,那么Java 就认为我们所定义的类位于默认包里面 (default package)。
② 类
首字母大写,如果一个类由多个单词构成,那么每个单词的首字母都大写,而且中间不使用任何的连接符。尽量使用英文。如 ConnectionFactory
③ 方法
首单词全部小写,如果一个方法由多个单词构成,那么从第二个单词开始首字母大写,不使用连接符。addPerson
④ 字段
与方法相同。如 ageOfPerson
⑤ 常量
所有单词的字母都是大写,如果有多个单词,那么使用下划线链接即可。
如:
public static final int AGE_OF_PERSON = 20; //通常加上static
2. 什么是 Java 的内存模型?
在了解什么是 Java 内存模型之前,先了解一下为什么要提出 Java 内存模型。
之前提到过并发编程有三大问题
- CPU 缓存,在多核 CPU 的情况下,带来了可见性问题
- 操作系统对当前执行线程的切换,带来了原子性问题
- 编译器指令重排优化,带来了有序性问题
为了解决并发编程的三大问题,提出了 JSR-133,新的 Java 内存模型,JDK 5 开始使用。
简单总结下
-
Java 内存模型是 JVM 的一种规范
-
定义了共享内存在多线程程序中读写操作行为的规范
-
屏蔽了各种硬件和操作系统的访问差异,保证了 Java 程序在各种平台下对内存的访问效果一致
-
解决并发问题采用的方式:限制处理器优化和使用内存屏障
-
增强了三个同步原语 (synchronized、volatile、final) 的内存语义
-
定义了 happens-before 规则
3、在 Java 中,什么时候用重载,什么时候用重写?
重载是多态的集中体现,在类中,要以统一的方式处理不同类型数据的时候,可以用重载。
重写的使用是建立在继承关系上的,子类在继承父类的基础上,增加新的功能,可以用重写。
简单总结:重载是多样性,重写是增强剂;
目的是提高程序的多样性和健壮性,以适配不同场景使用时,使用重载进行扩展。
目的是在不修改原方法及源代码的基础上对方法进行扩展或增强时,使用重写。
在里氏替换原则中,子类对父类的方法尽量不要重写和重载。(我们可以采用 final 的手段强制来遵循)
4、举例说明什么情况下会更倾向于使用抽象类而不是接口?
接口和抽象类都遵循”面向接口而不是实现编码”设计原则,它可以增加代码的灵活性,可以适应不断变化的需求。下面有几个点可以帮助你回答这个问题:在 Java 中,你只能继承一个类,但可以实现多个接口。所以一旦你继承了一个类,你就失去了继承其他类的机会了。
接口通常被用来表示附属描述或行为如: Runnable 、 Clonable 、 Serializable 等等,因此当你使用抽象类来表示行为时,你的类就不能同时是 Runnable 和 Clonable ( 注:这里的意思是指如果把 Runnable 等实现为抽象类的情况 ) ,因为在 Java 中你不能继承两个类,但当你使用接口时,你的类就可以同时拥有多个不同的行为。
在一些对时间要求比较高的应用中,倾向于使用抽象类,它会比接口稍快一点。如果希望把一系列行为都规范在类继承层次内,并且可以更好地在同一个地方进行编码,那么抽象类是一个更好的选择。有时,接口和抽象类可以一起使用,接口中定义函数,而在抽象类中定义默认的实现。
5、实例化对象有哪几种方式
- new
- clone()
- 通过反射机制创建
//用 Class.forName方法获取类,在调用类的newinstance()方法
Class<?> cls = Class.forName("com.dao.User");
User u = (User)cls.newInstance();
- 序列化反序列化
//将一个对象实例化后,进行序列化,再反序列化,也可以获得一个对象(远程通信的场景下使用)
ObjectOutputStream out = new ObjectOutputStream (new FileOutputStream("D:/data.txt"));
//序列化对象
out.writeObject(user1);
out.close();
//反序列化对象
ObjectInputStream in = new ObjectInputStream(new FileInputStream("D:/data.txt"));
User user2 = (User) in.readObject();
System.out.println("反序列化user:" + user2);
in.close();
6、Java 容器都有哪些?
Collection:
① set:HashSet、TreeSet
② list:ArrayList、LinkedList、Vector
Map:HashMap、HashTable、TreeMap
7、Collection 和 Collections 有什么区别?
Collection 是最基本的集合接口,Collection派生了两个子接口list和set,分别定义了两种不同的存储方式。
Collections是一个包装类,它包含各种有关集合操作的静态方法(对集合的搜索、排序、线程安全化等)。
此类不能实例化,就像一个工具类,服务于 Collection 框架。
8、HashMap 和 Hashtable 有什么区别?
HashMap是线程不安全的,HashTable是线程安全的;
HashMap中允许键和值为null,HashTable不允许;
HashMap的默认容器是16,为2倍扩容,HashTable默认是11,为2倍+1扩容;
9、说一下 HashMap 的实现原理?
① 简介
HashMap基于map接口,元素以键值对方式存储,允许有null值,HashMap是线程不安全的。
② 基本属性
- 初始化大小,默认16,2倍扩容
- 负载因子0.75
- 初始化的默认数组
- size
- threshold。判断是否需要调整hashmap容量
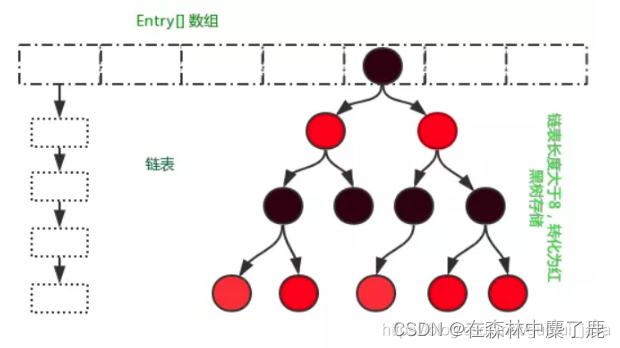
③ HashMap的存储结构
JDK1.7中采用数组+链表的存储形式。
HashMap 采取 Entry 数组来存储 key-value,每一个键值对组成了一个 Entry 实体,Entry 类时机上是一个单向的链表结构,它具有 next 指针,指向下一个Entry实体,以此来解决 Hash 冲突的问题。
HashMap实现一个内部类 Entry,重要的属性有hash、key、value、next。

JDK1.8中采用数据+链表+红黑树的存储形式。当链表长度超过阈值(8)时,将链表转换为红黑树。在性能上进一步得到提升。
10、说一下 HashSet 的实现原理?
HashSet 实际上是一个 HashMap 实例,数据存储结构都是数组+链表。
HashSet 是基于 HashMap 实现的,HashSet 中的元素都存放在 HashMap 的 key 上面,而 value 都是一个统一的对象PRESENT。
private static final Object PRESENT = new Object();
HashSet 中 add 方法调用的是底层 HashMap 中的 put 方法,put 方法要判断插入值是否存在,而 HashSet 的 add 方法,首先判断元素是否存在,如果存在则插入,如果不存在则不插入,这样就保证了 HashSet 中不存在重复值。
通过对象的 hashCode 和 equals 方法保证对象的唯一性。
11、ArrayList 和 LinkedList 的区别是什么?
ArrayList是动态数组的数据结构实现,查找和遍历的效率较高;
LinkedList 是双向链表的数据结构,增加和删除的效率较高。
12、哪些集合类是线程安全的
Vector :就比Arraylist多了个同步化机制 (线程安全) 。
Stack:栈,也是线程安全的,继承于Vector。
Hashtable:就比Hashmap多了个线程安全。
ConcurrentHashMap:是一种高效但是线程安全的集合。
13、怎么确保一个集合不能被修改?
我们很容易想到用 final 关键字进行修饰,如果说修饰的这个成员变量是引用类型,则表示这个引用的地址值是不能改变的,但是这个引用所指向的对象里面的内容还是可以改变的。
我们可以采用 Collections 包下的 unmodifiableMap 方法,通过这个方法返回的map,是不可以修改的。他会报 java.lang.UnsupportedOperationException错。
14、Java8 开始 ConcurrentHashMap , 为什么舍弃分段锁?
ConcurrentHashMap 的原理是引用了内部的 Segment ( ReentrantLock ) 分段锁,保证在操作不同段 map 的时候, 可以并发执行, 操作同段 map 的时候,进行锁的竞争和等待。从而达到线程安全, 且效率大于 synchronized。
但是在 Java 8 之后, JDK 却弃用了这个策略,重新使用了 synchronized+CAS。
弃用原因:
通过 JDK 的源码和官方文档看来, 他们认为的弃用分段锁的原因由以下几点:
- 加入多个分段锁浪费内存空间。
- 生产环境中, map 在放入时竞争同一个锁的概率非常小,分段锁反而会造成更新等操作的长时间等待。
- 为了提高 GC 的效率
- 新的同步方案
15、ConcurrentHashMap (JDK1.8) 为什么要使用 synchronized 而不是如ReentranLock 这样的可重入锁?
我想从下面几个角度讨论这个问题:
① 锁的粒度
首先锁的粒度并没有变粗,甚至变得更细了。每当扩容一次,ConcurrentHashMap的并发度就扩大一倍。
② Hash冲突
JDK1.7中,ConcurrentHashMap 从过二次 hash 的方式(Segment ->HashEntry)能够快速的找到查找的元素。在1.8中通过链表加红黑树的形式弥补了put、get时的性能差距。
JDK1.8中,在ConcurrentHashmap进行扩容时,其他线程可以通过检测数组中的节点决定是否对这条链表(红黑树)进行扩容,减小了扩容的粒度,提高了扩容的效率。
下面是我对面试中的那个问题的一下看法。
① 减少内存开销
假设使用可重入锁来获得同步支持,那么每个节点都需要通过继承AQS来获得同步支持。但并不是每个节点都需要获得同步支持的,只有链表的头节点(红黑树的根节点)需要同步,这无疑带来了巨大内存浪费。
② 获得 JVM 的支持
可重入锁毕竟是 API 这个级别的,后续的性能优化空间很小。synchronized则是JVM直接支持的,JVM能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。这就使得 synchronized 能够随着 JDK 版本的升级而不改动代码的前提下获得性能上的提升。
16、ConcurrentHashMap 和 HashTable 有什么区别
ConcurrentHashMap 融合了HashMap和 HashTable 的优势,HashMap是不同步的,但是单线程情况下效率高,HashTable是同步的同步情况下保证程序执行的正确性。
ConcurrentHashMap 锁的方式是细粒度的。ConcurrentHashMap 将 hash 分为16个桶 (默认值) ,诸如 get、put、remove 等常用操作只锁住当前需要用到的桶。
ConcurrentHashMap 的读取并发,因为读取的大多数时候都没有锁定,所以读取操作几乎是完全的并发操作,只是在求 size 时才需要锁定整个 hash。