Flink 学习八 Flink 容错机制 & checkpoint & savepoint
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/stateful-stream-processing/
1.容错基础概念
上一节讲述状态后端;Flink是一个 带状态stateful 的数据处理系统,在处理数据的过程中,各个算子的记录的状态会随着算子处理的状态而改变 ;状态后端负责将状态保存在内存或外部持久化存储中 (内存方式,Rocks,DB 方式),以便 Flink 可以在流处理任务中进行快速和可靠的状态访问。
本章checkpoint 则是 Flink 用于实现容错机制的组件,它定期生成任务的状态快照(比如source算子读取数据偏移量,计算算子中间存储的状态数据等数据),以便在任务发生故障或异常时能够从最近的 checkpoint 恢复任务的状态并继续处理数据流。checkpoint 中会保存所有状态数据和元数据,以确保任务状态的完整性和一致性。
checkpoint 可以存储在多种介质上,例如内存、文件系统、分布式存储系统(如 HDFS、S3 等),可以根据需求选择不同的 checkpoint 存储介质。checkpoint 会定期生成,并且在生成时会将当前的状态数据和元数据全部保存下来
状态后端和checkpoint 是密切相关的概念,但它们的功能是不同的;
2.Flink的端到端一致EOS
2.1 基本概念
Exactly-Once 语义(Exactly-Once Semantics):指的是端到端的数据一致,从数据读取,引擎计算,数据写出的整个过程中,即使机器崩溃,重启.都保证数据处理一次,不会重复,也不会丢失;
对于Flink程序来说,端到端EOS语义则包含source ,state , sink 三个环节的相互配合

2.2EOS 关键点
一批数据或者一条数据,从系统处理开始每个环节,要不全部成功,要不全部失败(回滚)
2.2.1 source 端保证EOS语义保证
Flink 很多source 算子为EOS 提供保障,如kafak source
- 可以记录偏移量
- 能够数据重放
- 将数据偏移量记录在state 中,与下游的算子的state 一起,经由checkpoint 机制实现了 状态数据的快照统一
2.2.2 Flink 内部的EOS语义保证
基于分布式快照算法 Chandy-Lamport ,Flink 实现了整个数据流中各算子的状态数据快照统一:
一次checkpoint 后持久化的各算子的状态数据,是经过相同数据的影响
- 一条/一批数据是经过完整的处理
- 一条/一批在处理中间失败了,重启恢复后,所有的恢复到没有处理这条数据的状态,在重新处理
2.2.3 Sink 端的保证
一批数据若处理失败,但是一部分数据已经写入的目标存储,重启后数据重放可能会对目标存储里面数据重复,破坏EOS,对此,flink设计相应的机制来处理
- 幂等
- 两阶段写入机制 2PC two phase
- 预习日志的方式
3.Flink checkpoint机制
3.1 checkpoint问题
如何保证一条数据只影响一次
示例
下面是source算子读取数据,经过两个累加算子处理数据, 正常的情况下处理了1,2,3 数据记录
如果在第二部 累计算子到累加算子之间程序失败,此刻系统如果已经checkpoint (数据还是2,3,1 ) 然后第三个算子处理数据失败
重启后数据3 开始 ,处理数据,最后数据不一致

原因:
第三个算子没有处理数据2 ,处理数据2 的状态没有记录
结论:
次中简单的快照机制在各个算子之间 处理的数据是不统一的
3.2 flink checkpoint
3.2.1 快照checkpoint 时机
Flink 容错机制的核心部分是对分布式数据流和算子状态绘制一致的快照。(可以理解为算子处理了相同的数据)
Flink 分布式快照的核心元素是流屏障(barrier ), 这些屏障被注入到数据流中,并作为数据流的一部分和数据记录一起流动.屏障不会超过记录严格,按照顺序流动。屏障将数据流中的记录分为进入当前快照的记录集和进入下一个快照的记录,每个障碍都带有快照的 ID(单调递增),快照的记录被推送到它前面。屏障不会中断流的流动,因此非常轻量级。来自不同快照的多个障碍可以同时在流中,这意味着各种快照可能同时发生
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XBtQZJN9-1687272936398)(flink8手绘/stream_barriers.svg)]](https://img-blog.csdnimg.cn/1c1eac06de9947cd9f866a7121de3124.png)
流屏障被注入到流源的并行数据流中。注入快照n的屏障的点(我们称之为 S n)是源流中快照覆盖数据的位置。例如,在 Apache Kafka 中,此位置将是分区中最后一条记录的偏移量。这个位置Sn 被报告给 checkpoint 协调器 (Flink 的JobMananger);然后屏障向下游流动。当中间运算符从其所有输入流中接收到快照n的屏障时,它会将快照n的屏障发射到其所有输出流中。一旦接收器运算符(流式 DAG 的末端)从其所有输入流中接收到屏障n ,它就会向检查点协调器确认快照n 。在所有接收器都确认快照后,它被认为已完成 ;
简单的来说就是检测点事所有算子都完成n 的checkpoint之后, n 点的checkpoint才算完成,若部分完成,部分没有完成,者程序崩溃后恢复的就是n之前所有算子都完成的checkpoint ;
3.2.2 单个算子 本地checkpoint 过程
对齐检查点checkpoints机制
这叫做aligned checkpoints
算子接受多个流,每个流里面都有barrier ,需要等所有相同的barrier 到达之后在checkpoint ;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-krQVTDKI-1687272936399)(flink8手绘/stream_aligning.svg)]](https://img-blog.csdnimg.cn/663ae4a490e84a4f938a363535f41c2b.png)
- Begin alignment : Operator算子 在收到
654321在1处的checkpoint 快照屏障n 后,它就无法处理来自这个流的其他数据(但是会继续接受数据,数据会被缓存但不会被处理逻辑处理),直到Operator算子的其他输入流也也有 checkpoint 快照屏障n 到达 - End alignment :Operator算子 的所有输入流的 快照屏障n 到达后(最后一个输入流的快照屏障n 到达后) ,Operator算子就会发出所有待处理的传出记录,然后自己发出快照n屏障。
- checkpoint :快照自己当前状态,并恢复处理来自输入流记录,把快照状态,异写入状态后端
非对齐检查点checkpoints机制
不能保证EOS 语义

barrier 不对齐,当算子有多个channel,单其中一个收到barrier ,其他channel 的barrier还没有到的时候,就checkpoint ; 把缓存的数据,即将要发送的数据都checkpoint ,等到重启后,这些飞行的数据自己在重放
飞行中的数据: barrier 还没有处理的数据
321 输入缓存中
cba 输入缓存 中, d 在上一个算子的状态中中
输出缓存zyx 缓存中 可以作为下一个算子的状态
-
on first barrier:算子对存储在其输入缓冲区中的第一个障碍做出反应。
-
Tag buffer and forward barrier :它通过将屏障添加到输出缓冲区的末尾来立即将屏障转发给下游运算符
-
checkpoint : 存储快照和飞行中的数据
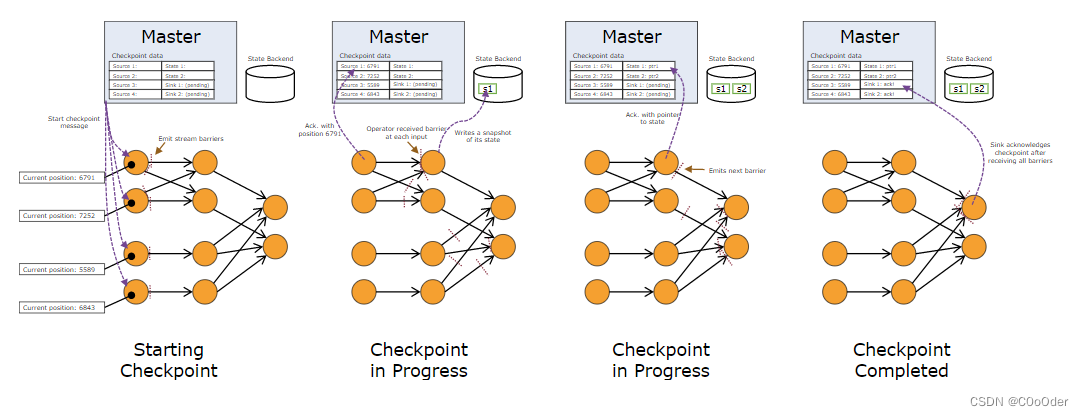
3.2.3 整个job checkpoint过程
- job Manager(CheckpointCoordinator ) 会定期 ( env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);)向每个向 **Source算子(source task) ** 发送 start checkpoint命令
- Source算子(source task) ** 收到 start checkpoint命令后,产生barrier 并广播的方式发送到下游,所有task收到 barrier-n 后会本地执行checkpoint-n,本地执行完成后,发送ack-n 到Job Manager**
- 当所有的算子都完成checkpoint-n后,Job Manager 收到了所有节点的 ack-n ,就会向所有算子广播checkpoint-n 全部完成的通知消息;

其实整个过程是一个二阶段提交过程
协调者:JobManager
执行者(参与者):Source ,Opeartor ,Sink
Pre-cmmmit( prepare ) :ack n
commit : callback
3.3 快照的数据
- 对于每个并行流数据源,快照开始时流中的偏移量/位置
- 对于每个算子,指向作为快照一部分存储的状态的指针
4.Flink checkpoint API
代码中常用的一些checkpoint 的配置解释
//开启 checkpoint 并设置Checkpoint 的周期
env.enableCheckpointing(3000);
//指定 checkpoint 数据存储位置
env.getCheckpointConfig().setCheckpointStorage(new Path("hdfs://hadoop01:8082/flink-checkpoints/"));
//允许 checkpoint 失败次数
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(10);
//checkpoint 算法模式是否对齐checkpoint (一般使用这个,可能会使得算子背压)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//设置 对齐checkpoint 的超时时间 超时会checkpoint 失败
env.getCheckpointConfig().setAlignedCheckpointTimeout(Duration.ofMillis(2000));
//job 取消的是否保留 checkpoint 数据 //保留.后续job 重启需要
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//并设置Checkpoint 的最小间隔
env.getCheckpointConfig().setCheckpointInterval(2000);
//最大 checkpoint 的最大并行数 没有完成的(进行中的)checkpoint 最大是3个
env.getCheckpointConfig().setMaxConcurrentCheckpoints(3);
//指定 checkpoint 的状态后端 默认时HashMapStateBackend
env.setStateBackend(new EmbeddedRocksDBStateBackend());
5.Sink 端容错机制
5.1.幂等数据写入
Sink 是Flink引擎计算的最后一步; 当作业失败重启后,数据重放可能会造成目标存储的数据重复或者是数据不一致;
如果目标存储数据库支持数据幂等写入,且输出数据中有合适的主键key ,则flink 的sin可以达到数据的最终一致;
幂等写入,只能保证后面写入数据覆盖前面数据,达到数据的最终一致,不能处理第一次写入后数据的问题,只能保证第二次写入数据和正常情况下是一致的;也就是最终一致
5.2.两阶段事务写入
特点:
- 需要外部系统支持事务
- 数据提交依赖外部系统,数据存在外部系统,没有提交前,外部数据可以读取未提交的数据(根据隔离级别)
5.2.1 执行流程
flink 的两阶段数据提交,利用上一节介绍的checkpoint 的两阶段提交 和 目标存储系统的事务支持
- Sink 算子在处理一批数据,先积攒数据,做预提交
- 这个一批出数据处理完成 ,会想job manager 的checkpoint coordinator 上报自身的checkpoint 完成信息
- checkpoint coordinator 收到算子完成的checkpoint ack 信号后,直到该ck号的所有checkpoint 完成.开始先所有算子广播全局checkpoint 完成的信号
- Sink 收到checkpoint coordinator 全局的checkpoint 完成后,正式提交事务
5.2.2 2pc接口实现
需要实现接口 TwoPhaseCommitSinkFunction
https://github.com/streaming-with-flink/examples-scala/blob/master/src/main/scala/io/github/streamingwithflink/chapter8/TransactionalSinkExample.scala
5.3 预写日志形式
特点:
- 外部系统可以不支持事务
- 数据存在flink 的算子状态中
5.3.1 执行流程
- 把结果数据存储在状态中,然后收到全局的checkpoint 完成后,一次性写入目标存储
( 相当于模拟外部系统的事务机制)
5.3.2 预写日志接口实现
需要实现接口 GenericWriteAheadSink
https://github.com/streaming-with-flink/examples-scala/blob/master/src/main/scala/io/github/streamingwithflink/chapter8/WriteAheadSinkExample.scala
5.4 总结
两个其实都不能在真正意义上实现Exactly once
预写日志从思想上也是一个两阶段提交过程
6.Flink 容错配置
6.1 Task 级别失败
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/ops/state/task_failure_recovery/
6.1.1 Restart Strategy
主要是重启task 的时间设置
// 10 次重启 每次间隔2000ms
restartStrategyConfiguration = RestartStrategies.fixedDelayRestart(10,2000);
//不重启 task 失败
restartStrategyConfiguration = RestartStrategies.noRestart();
//重启间隔惩罚初始值
// 重启间隔惩罚最大值
// 惩罚倍数(故障一次 比上一次重启间隔惩罚停留值大多数倍) ,
// 平稳运行多数次后惩罚时间恢复初始值,随机数
// 抖动值 : 真正间隔停留时间 = 两次重启间隔时间 * 抖动值
restartStrategyConfiguration = RestartStrategies.exponentialDelayRestart(Time.seconds(1),Time.seconds(60),1,Time.hours(1),1.1);
//失败次数
//运行时间段内
//两次重启时间间隔
restartStrategyConfiguration = RestartStrategies.failureRateRestart(5,Time.hours(1),Time.seconds(5));
//自定义设置 自定义重启策略 配置文件存储:flink-conf.yaml
restartStrategyConfiguration = RestartStrategies.fallBackRestart();
6.1.2 Failover Strategies
task 失败,需要重启那些Task
Restart All Failover Strategy : 重启所有Task
Restart Pipelined Region Failover Strategy:策略计算重启的最小region ; (默认使用)
6.2 Cluster 级别失败
6.2.1 基础概念
整个任务失败,恢复策略
- savepoint (保存点) :每次checkpoint 生成的flink状态数据,叫做 savepoint ;可以基于savepoint 来在另一个集群或时间点上从保存的状态上恢复运行
- 使用场景: 应用升级,集群迁移,Flink 版本更新等,
- 保存点可以看做是savepoint ,保存每个算子的状态, k是算子 ,value 算子的state
配置
state.savepoint.dir: hdfs://hadoop/savepoints
每次checkpoint 会生成savepoint , 手动命令触发的checkpoint 也叫做savepoint
6.2.2 savepoint 命令
//触发savepoint
flink savepoint :jobId [:targetDir(目标存储的存储目录)]
//yarn 集群模式触发 savepoint
flink savepoint :jobId [:targetDir(目标存储的存储目录)] -yid :yarnAppId
//停止一个job 集群并触发savepoint
flink stop --savepointPath [:targetDir(目标存储的存储目录)] :jobId
//从一个指定的 savepoint 来恢复启动job的集群
flink run -s :savepointPath [:runargs]
//删除一个 savepoint
flink savepoint -d :savepointPath
注: IDEA 测试
/**
* flink 本地调试
*/
Configuration configuration = new Configuration();
configuration.setString("execution.savepoint.path", "file:///D:/flink/savepoints");
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
6.3 从savepoint 恢复注意点
Flink Job 从savepoint 的状态恢复,在作业变更,修改逻辑的情况下
- 算子的顺序改变
算子在运行的时候会有一个UID(Unique Identifier)是一个唯一的标识符,用于标识算子在不同版本或者不同的任务中的唯一性。UID 可以手动指定,也可以由 Flink 自动生成; 若uid没有改变,则可以恢复;uid 改变,恢复会失败
- 作业中添加了新的算子
无状态的算子,没有任何影响,如果是添加有状态的算子,就初始状态是空的
- 修改后的任务删除了一个有状态的算子
默认需要恢复savepoint 中记录的所有的算子的状态,如果是删除了一个有状态的算子,则在灰度的时候被删除的OpreratorId 找不到,就会报错 ,需要添加指定命令
-- allowNonReStoredSlale (short:n) 跳过无法恢复的算子
6.4 从savepoint 恢复 状态重新分配
Flink 程序,重启恢复时,修改程序的JobGraph (修改算子顺序,和算子的并行度),还是可以加载之前的savepoint ,但是数据会重新分配
6.4.1 Opeartor State
- UnionListState 广播模式从分配 (每个Task 有完整的State)
- ListState 使用 round-robin,轮训分配模式恢复
6.4.2 Keyed State
程序处理数据的规律中台分配是一一对应, subtask state 数据接受规律不会变,不会产生逻辑上的影响

6.4.3 task 恢复 savepoint 示例
从kafka 读取数据, 写入MySQL
package demo.sff.flink.eos;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Random;
import javax.sql.XADataSource;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.jdbc.JdbcExactlyOnceOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.apache.flink.util.function.SerializableSupplier;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.OffsetResetStrategy;
import com.mysql.cj.jdbc.MysqlXADataSource;
/**
* 生产环境
*/
public class _01_eos_o2 {
public static void main(String[] args) throws Exception {
// 获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//设置ck 时间和 eos 语义,必须开启ck
env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
// 设置checkpoint 路径
env.getCheckpointConfig().setCheckpointStorage("file:///D:/Resource/FrameMiddleware/FlinkNew/eos/");
//设置task 重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(10,1000));
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("CentOSA:9092,CentOSB:9092,CentOSC:9092")
.setTopics("eos")
.setGroupId("eosgroup")
.setValueOnlyDeserializer(new SimpleStringSchema())
//kafkaSource 的做状态 checkpoint 时,默认会向__consumer_offsets 提交一下状态中记录的偏移量
// 但是,flink 的容错并不优选依赖__consumer_offsets 中的记录,所以可以关闭该默认机制
.setProperty("commit.offsets.on.checkpoint","false")
.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false")
// kafkaSource 启动时,获取起始位移的策略设置,如果是 committedOffsets ,则是从之前所记录的偏移量开始
// 如果没有可用的之前记录的偏移量, 则用策略 OffsetResetStrategy.LATEST 来决定
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
.build();
DataStreamSource<String> streamSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "kafka_data");
SingleOutputStreamOperator<String> mapped = streamSource.keyBy(s -> "tooneKey")
.map(new RichMapFunction<String, String>() {
ValueState<String> valueState = null;
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor<String> string = new ValueStateDescriptor<>("preString", String.class);
valueState = getRuntimeContext().getState(string);
}
@Override
public String map(String value) throws Exception {
String value1 = valueState.value();
if (value1 == null) {
value1 = "";
}
valueState.update(value);
//随机模拟失败
if(value.indexOf("x")>-1&& new Random().nextInt(5)%3==0){
int a = 1/0;
}
return "pre:" + value1 + ";current:" + value.toUpperCase();
}
});
SingleOutputStreamOperator<String> mapped1 = mapped.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value + ":::map";
}
});
String sql = "INSERT INTO eos (testcol) VALUES (?) ";
SinkFunction<String> sinkFunction = JdbcSink.exactlyOnceSink(sql, new JdbcStatementBuilder<String>() {
@Override
public void accept(PreparedStatement preparedStatement, String string) throws SQLException {
preparedStatement.setString(1,string);
}
}, JdbcExecutionOptions.builder()
.withBatchSize(1) //两条数据一批插入
.withMaxRetries(3) //失败插入重试次数
.build(),
JdbcExactlyOnceOptions.builder()
//mysql 不支持一个连接上多个事务,必须要设置为true
.withTransactionPerConnection(true)
.build(),
//XADataSource 支持分布式事务的连接
new SerializableSupplier<XADataSource>() {
@Override
public XADataSource get() {
MysqlXADataSource mysqlXADataSource = new MysqlXADataSource();
mysqlXADataSource.setURL("jdbc:mysql://192.168.141.131:3306/flinkdemo");
mysqlXADataSource.setPassword("root");
mysqlXADataSource.setUser("root");
return mysqlXADataSource;
}
}
);
mapped1.addSink(sinkFunction);
env.execute();
}
}