目录
一、进位计数制
二、信息编码
三、定点数的表示
四、校验码
五、浮点数的表示
一、进位计数制
整数部分:
- 二进制、八进制、十六进制 ---> 十进制:加权求和
- 二进制 ---> 八进制:每三位分为一组,转为八进制数
- 二进制 ---> 十六进制:每四位分为一组,转为十六进制数
- 十进制 ---> 二进制:除2取余,先得到低位
- 十进制 ---> 八进制、十六进制:先转为二进制,再转为八进制数或十六进制数
小数部分:
- 十进制转换为任意进制:乘积取整法,结果不能得到准确值,则取精度值
- 二进制 ---> 八进制、十六进制:与整数部分类似
- 二进制 ---> 十进制:加权求和
- 八进制、十六进制 ---> 十进制:先转为二进制,再转为十进制
真值:符合人类习惯的数字
机器数:数字实际存在机器里的形式
二、信息编码
BCD码:Binary Coded Decimal,二-十进制码,即用二进制数表示十进制数。
BCD码分为有权码和无权码。常见的有权码有8421码、2421码、84-2-1码,常见的无权码有格雷码、余三码。
有权码的共性:都是自补码,即任意两个和为9的编码,互为补码。
格雷码:任何相邻的两个编码之间只有一位二进制位不同。
余三码:每个编码都是其8421码加上0011所得。
汉字编码
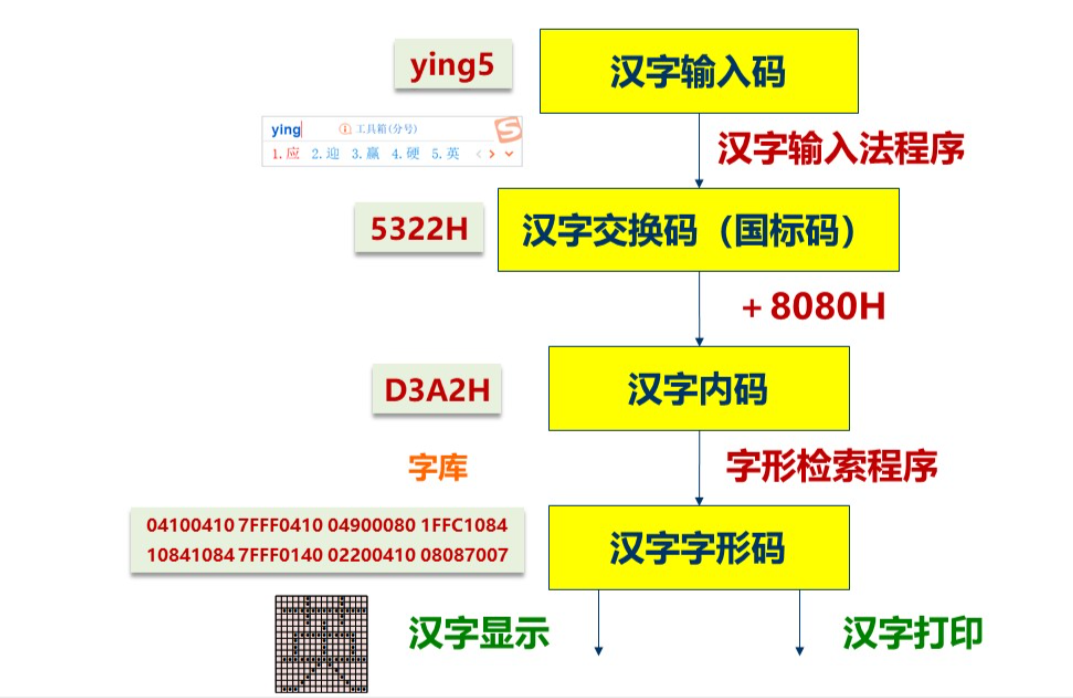
- 汉字输入码:也称外码,是为了将汉字输入计算机而编制的代码,代表某一汉字的键盘符号
- 汉字交换码:不同的具有汉字处理功能的计算机之间在交换汉字信息时所使用的标准代码
- 汉字内码:用于汉字信息的存储、交换、索检等操作的机内代码,一般用两个字节表示
- 汉字字形码:将汉字字形经过点阵数字化之后形成的一串二进制数,用于汉字的显示和打印
国内标准信息处理交换码:国标码
国标码采用两个字节对汉字进行编码,第一版的6763个汉字分为94个区,每个区94位,每个汉字在分区中的位置就是区位码,如“中”字位于54区48位,“中”字的区位码就是5448。
国标码 = 区位码 + 2020H,如“中”字的区位码是5448,转换为十六进制为3630H,则“中”字的国标码为 3630H + 2020H = 5650H
汉字内码 = 国标码 + 8080H,最高位皆为“1”,区别于英文字符的最高位为“0”
汉字字库:将所有汉字的字,字模点阵代码按内码顺序集中起来,构成了汉字库。
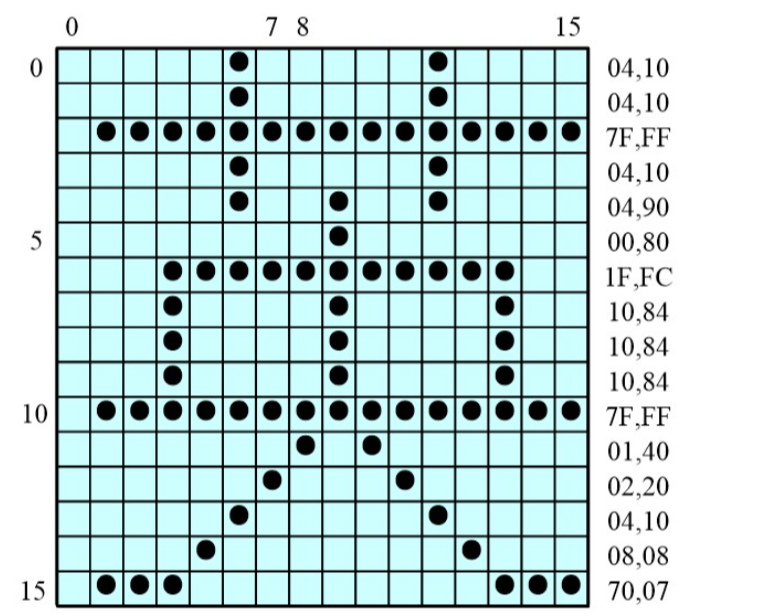
如上图字模码:16 × 16 点阵,每个汉字所占空间 = 16 × 16bit = 32B
三、定点数的表示
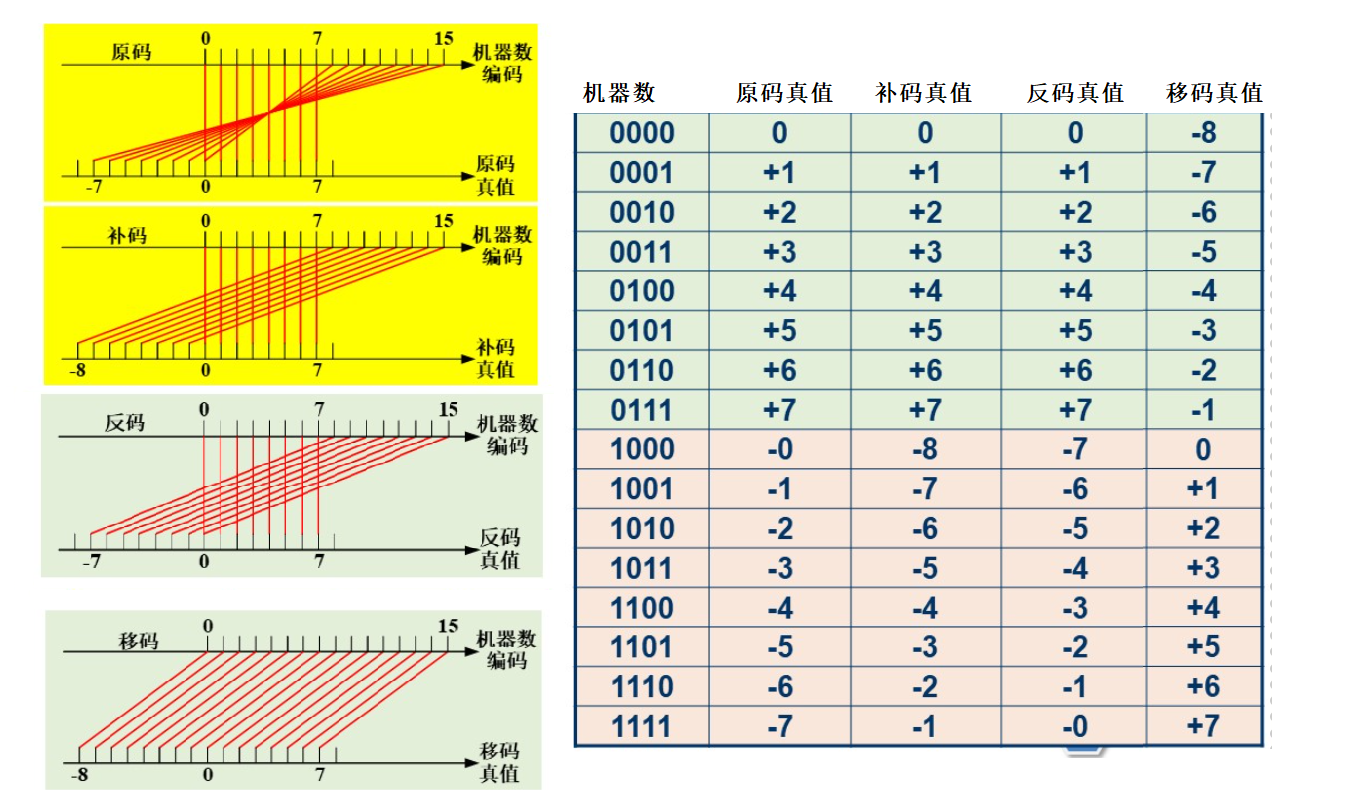
原码
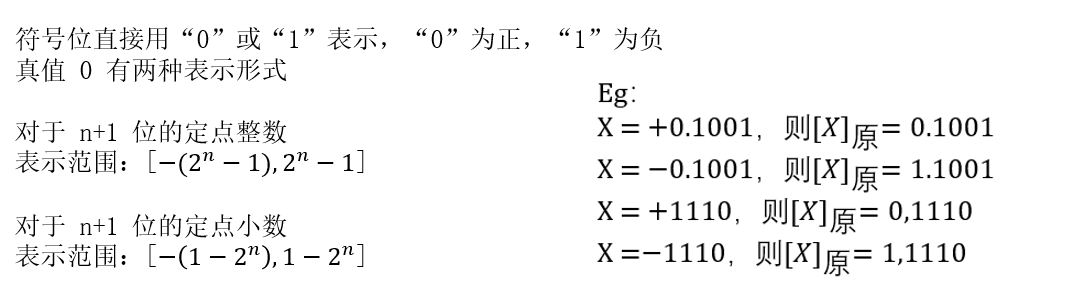
反码

补码

移码
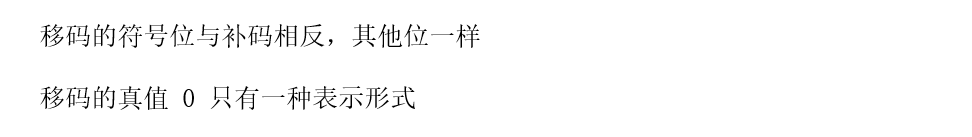
四、校验码
校验码定义:是一种具有发现某些错误或自动改正错误能力的一种数据编码方法。
校验码目的:用于检查或纠正正在存取、读写和传送数据的过程中可能出现的错误。
校验码基本思想:“冗余校验”,即通过在有效信息编码的基础上,添加一些冗余位来构成整个校验码。校验码 = 有效信息 + 校验位。
校验过程
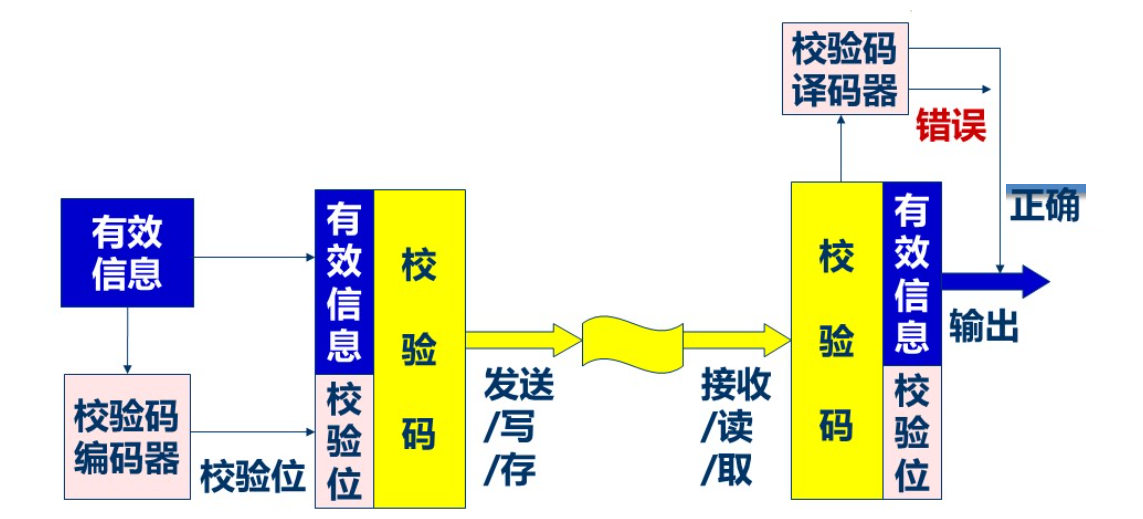

奇偶校验码:奇校验位的取值应该使整个奇校验码中“1”的个数为奇数,偶校验码的取值应该使整个偶校验码中“1”的个数为偶数
奇偶校验码的码距为2,具有检查一位错误或奇数位错误的能力。
五、浮点数的表示
浮点数的格式
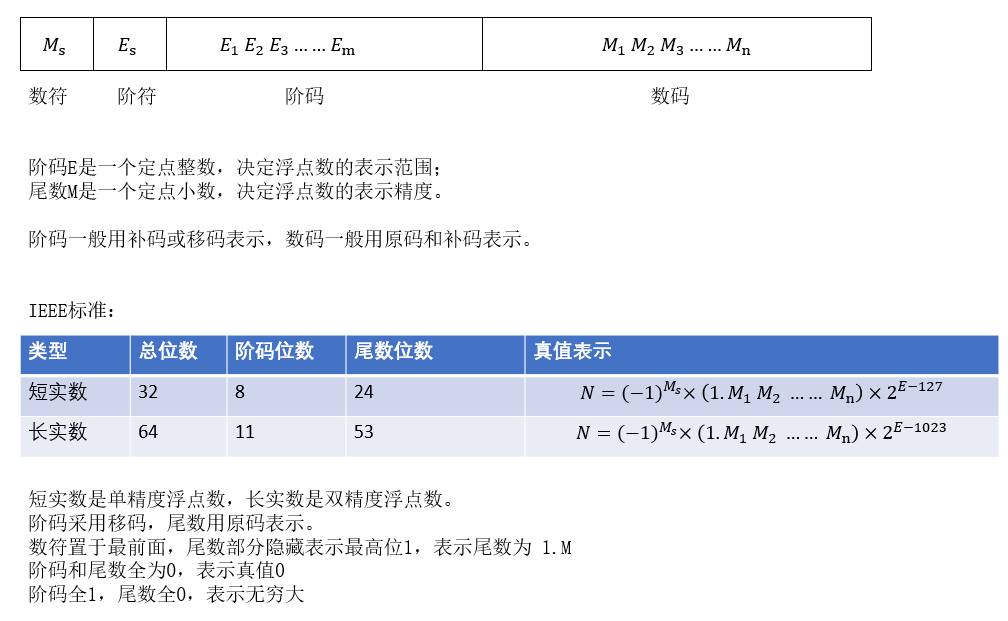
浮点数规格化

浮点数的溢出
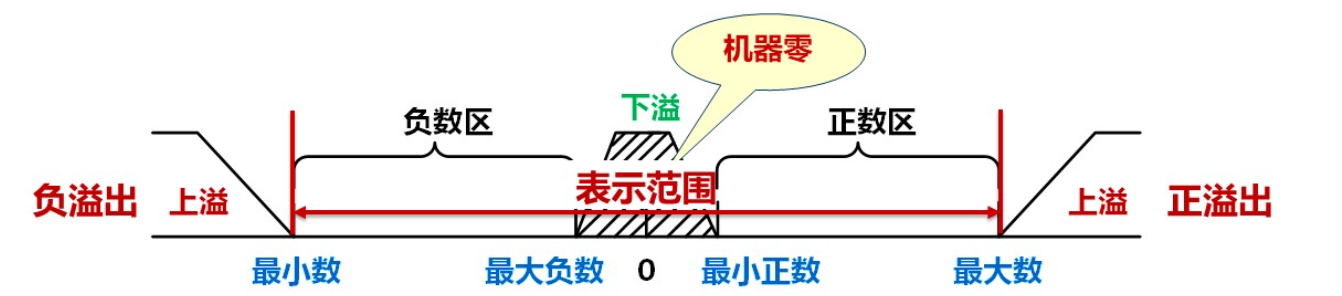
- 出现上溢:系统中断
- 出现下溢:当作机器0处理
- 当浮点数尾数为0:当作机器0处理,无视阶码
真值与浮点数格式的转换

十进制数与单精度浮点数的转换