Prompt 有很多网站已经收录了,比如:aimappro

有些直接抄上述网站的作业即可,不过也来看看,
有一些日常提问大概的咒语该怎么写。
1 三种微调下的提示写法
chatgpt时代的创新:LLM的应用模式比较
实际案例说明AI时代大语言模型三种微调技术的区别——Prompt-Tuning、Instruction-Tuning和Chain-of-Thought
三类:
- In-context Learning(上下文学习)
- Instruction Tuning(指令微调)
- Chain of Thought(思维链)
1.1 In-context Learning(上下文学习)
In-context Learning接近小样本学习
举一个实际咒语的例子:
给你一个例子:
给出的句子是:值得去的地方,石头很奇特,景色优美,环境宜人,适合与朋友家人一起游玩!
你应该判断该句子的情感是什么,情感从['正面的', '负面的', '中性的']里选择。
输出列表:["正面的"]
如果不存在,回答:没有。
返回结果为输出列表。
现在,我给你一个句子,如"散热很好、低噪音、做工扎实、键盘舒适",你应该判断句子的情感倾向,并以列表的形式返回结果,如果不存在,则回答:没有。
{'sentence': '散热很好、低噪音、做工扎实、键盘舒适', 'type': '', 'access': '', 'task': 'SA', 'lang': 'chinese', 'result': ['正面的'], 'mess': [{'role': 'system', 'content': 'You are a helpful assistant.'}, {'role': 'user', 'content': '给你 一个例子:\n给出的句子是:值得去的地方,石头很奇特,景色优美,环境宜人,适合与朋友家人一起游玩!\n你应该判断该句子的情感是什么,情感从[\'正面的\', \'负面的\', \'中性的\']里选择。\n输出列表:["正面的"]\n如果不存在,回答:没有。\n返回结果为输出列表。\n\n现在,我给你一个句子,如"散热很好、低噪音、做工扎实、键盘舒适",你应该该句子的情感倾向,并以列表的形式返回结果,如果不存在,则回答:没有。'}]}
1.2 Instruction Tuning(指令微调)
Instruction通常是一种更详细的文本,用于指导模型执行特定操作或完成任务。Instruction可以是计算机程序或脚本,也可以是人类编写的指导性文本。Instruction的目的是告诉模型如何处理数据或执行某个操作,而不是简单地提供上下文或任务相关信息。
数据格式:
instruction: 指令
input: 输入(本数据集均为空)
output: 输出
就是指令,输入,输出,来看一个例子,加深提问的印象:
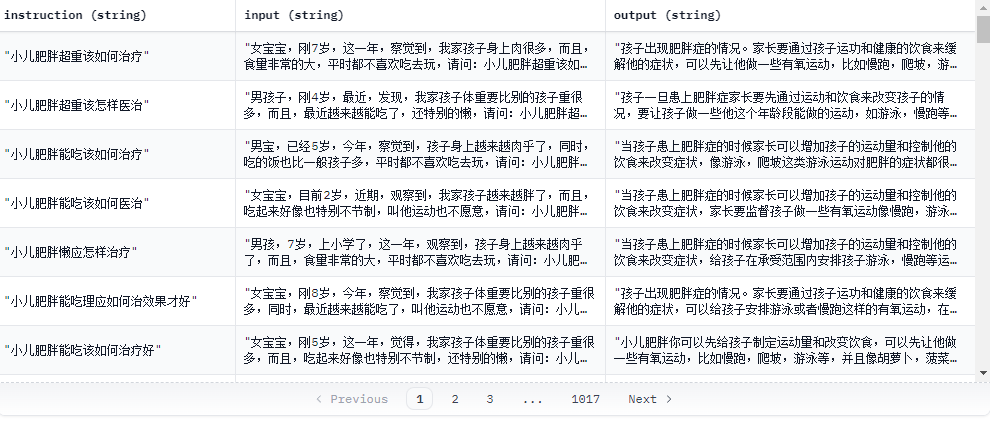
1.3 Chain of Thought(思维链)
使用 chain-of-thought,我们可以将问题分解成以下步骤:
将问题输入模型:“计算 3 * (4 + 5)”
模型输出第一步的结果:“计算 4 + 5”
将上一步的结果作为输入,再次输入模型:“计算 3 * 9”
模型输出最终结果:“结果是 27”
在这个例子中,我们可以看到模型是如何通过一系列连贯的思考链(步骤)来逐步解决问题的。
在Chain-of-thought训练中,将数据集中的输入分解为一系列任务是非常关键的一步。一般来说,这个过程需要根据特定的任务和数据集来进行定制。
一个例子:
在提示的时候,加上"Let’s think step by step" (让我们一步一步思考)或者类似的句子,会促使LLM花更多的token把“思考”的过程都表达出来。而更多的token -> 更多的“思考努力" -> 更好的结果。
2 提示词模版的要素拆解
参考:如何向ChatGPT问问题才能获得更高质量的答案?
一个好的提示词模版的要素:
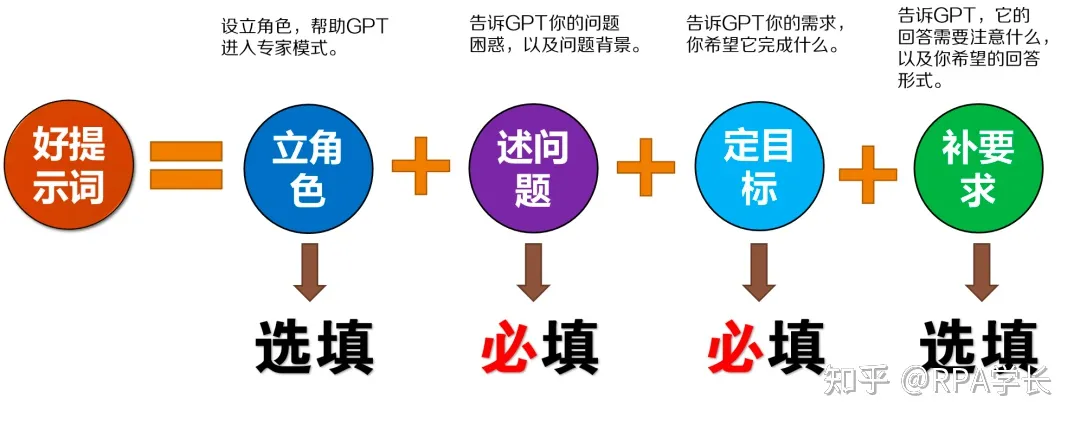
看一个大概的例子:
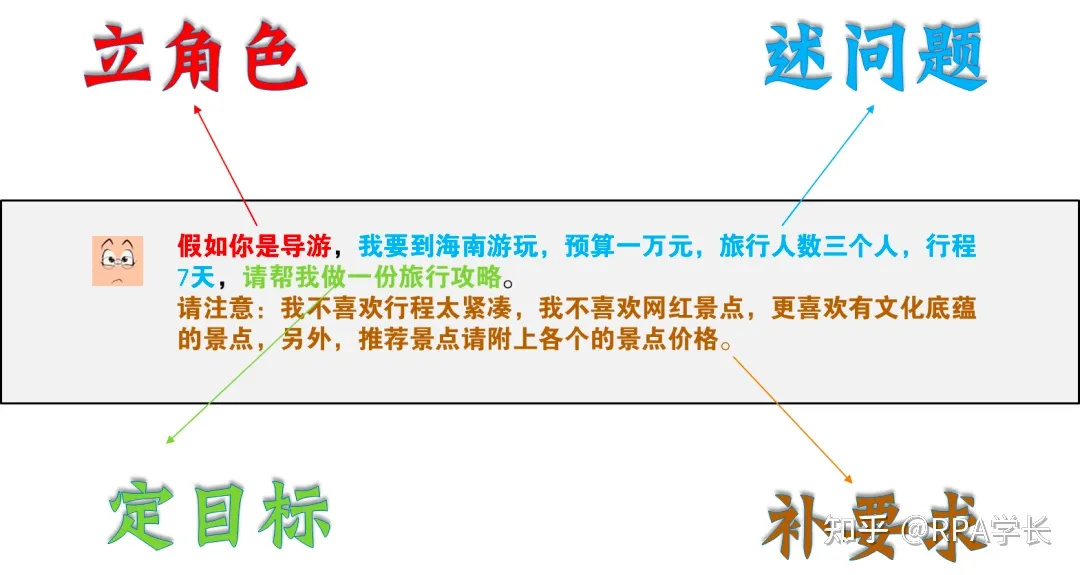
其中,有没有【立角色】在有一些prompt过程中,会差异蛮大,最好都加上。
再来看一个例子:

生成效果:

3 GPT 保存对话框,保留历史信息
如果你有一类问题,可以一直在一个对话框询问,同时进行保存,这样就会记住历史消息,相当于一次【In-context Learning(上下文学习)】

4 其他Prompt一些小技巧
4.1 通过Prompt让llm反思
来自 “State of GPT” 理解+观后感
在LLM给出答案后,你可以给它一个反思的机会(比如说,问它一句“你确定吗”),这样如果它之前犯了错误,它就有一个纠正的机会。
4.2 明确告诉LLM你需要正确的答案
来自 “State of GPT” 理解+观后感

在提示里加上"Let’s make sure we have the right answer",否则LLM可能并不认为给出错误的答案是不好的。