在规划工作中有时候会收到一种带坐标点的txt文件:

上网查了一下资料,这是根据《勘测定界界址点坐标交换格式》制作的固定格式文件。
其中包含了坐标系、精度、地块编号、地块名称、坐标点等信息。
这个工具的目的就是将TXT格式坐标批量转换为数据库文件,并读取地块编号,地块名称,地块用途、3个属性,写到要素类的字段中。(其它信息感觉好像没什么用,就暂不写入了。)
一、要实现的功能
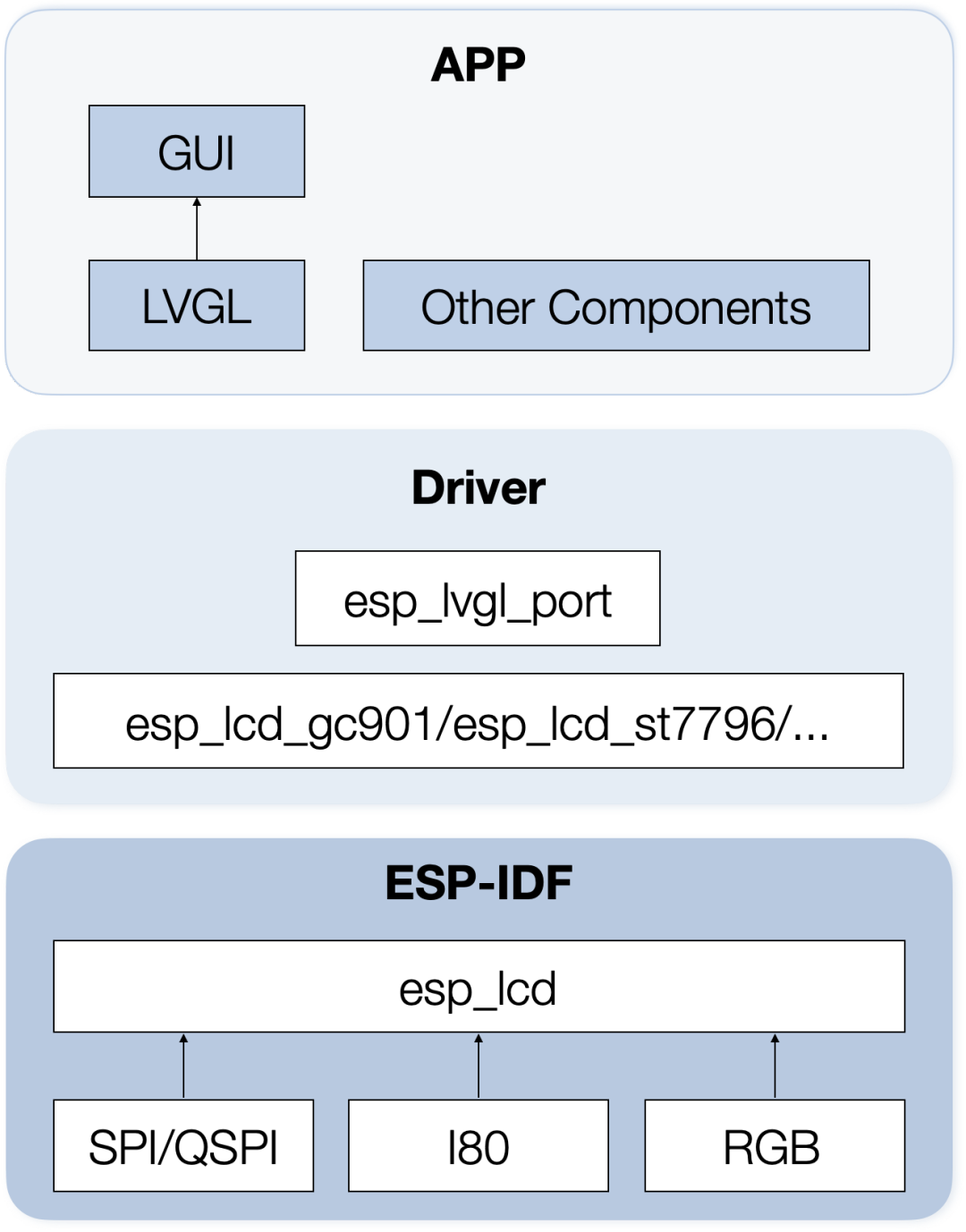
如上图所示,点击【TXT文件转要素类(批量)】按钮,在弹出的工具框中输入参数。
1、输入包含txt文件的文件夹:
2、输出gdb数据库的位置。
3、手动输入要生成的要素类的名字。
4、选择坐标系。这里已经预设了几种坐标系,可以下拉选择。如果没有你需要的,也可以手动输入。坐标系名字可以打开ArcGIS里查看:
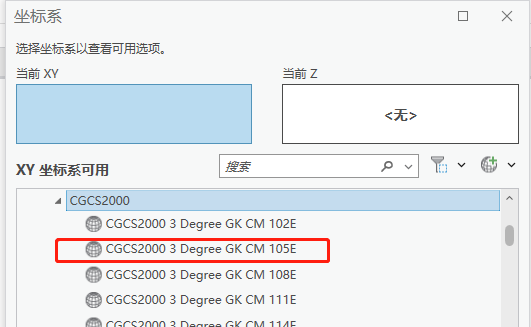
需要注意的是,上面显示空格的地方要换成英文输入状态下的“_”。
点击【执行】,生成结果如下:
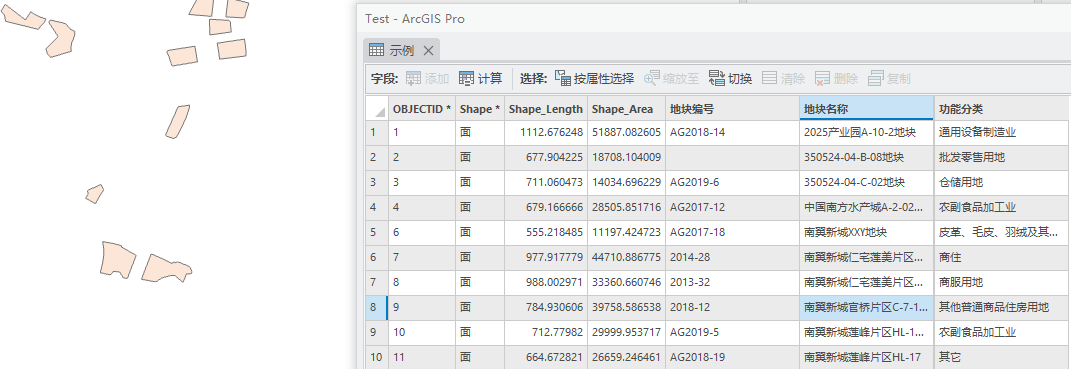
二、实现流程
1、创建一个空的面要素类,并新增3个字段
这部分比较简单,直接用GP工具即可:
// 创建一个空要素
Arcpy.CreateFeatureclass(gdb_path, fc_name, "POLYGON", spatial_reference);
// 新建字段
Arcpy.AddField(gdb_path + @"\" + fc_name, "地块编号", "TEXT");
Arcpy.AddField(gdb_path + @"\" + fc_name, "地块名称", "TEXT");
Arcpy.AddField(gdb_path + @"\" + fc_name, "功能分类", "TEXT");2、获取文件夹下的所有txt文件
这里写了一个通用方法,可以使用关键字,采取递归方式来获取:
// 获取输入文件夹下的所有文件
public static List<string> GetAllFiles(string folder_path, string key_word ="no match")
{
List<string> filePaths = new List<string>();
// 获取当前文件夹下的所有文件
string[] files = Directory.GetFiles(folder_path);
// 判断是否包含关键字
if (key_word == "no match")
{
filePaths.AddRange(files);
}
else
{
foreach (string file in files)
{
// 检查文件名是否包含指定扩展名
if (Path.GetExtension(file).Equals(key_word, StringComparison.OrdinalIgnoreCase))
{
filePaths.Add(file);
}
}
}
// 获取当前文件夹下的所有子文件夹
string[] subDirectories = Directory.GetDirectories(folder_path);
// 递归遍历子文件夹下的文件
foreach (string subDirectory in subDirectories)
{
filePaths.AddRange(GetAllFiles(subDirectory, key_word));
}
return filePaths;
}调用方法:
var files = GetAllFiles(folder_path, ".txt");3、解析txt文件内容
解析txt文件的时候遇到一个问题,文件采取的编码方式不同,如下图:
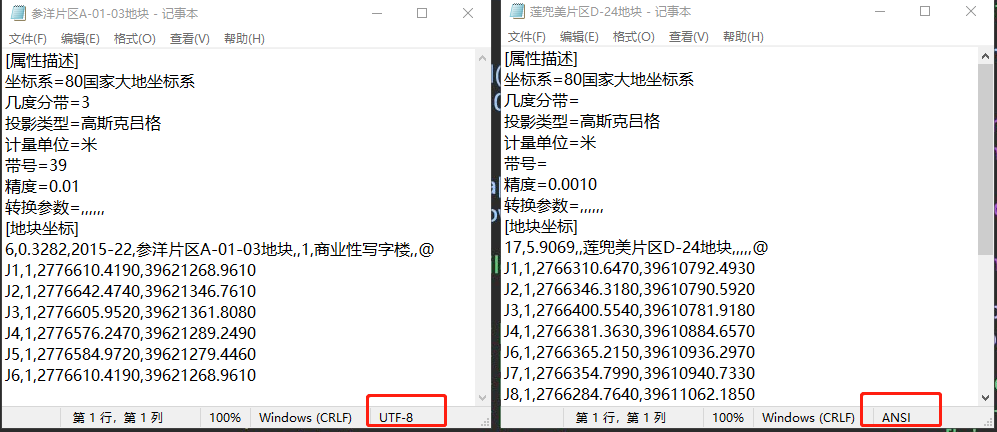
通过解析,发现这个ANSI返回的也是UTF-8,但是按UTF-8打开却发现中文部分是乱码。
之前没接触过这部分的知识,实在是不知道什么原理。只是对返回结果的差异点作个判断。
// 解析txt文件内容,创建面要素
foreach (var path in files)
{
// 预设文本内容
string text = "";
// 获取txt文件的编码方式
Encoding encoding = ToolManager.GetEncodingType(path);
// 读取【ANSI和UTF-8】的不同+++++++(ANSI为0,UTF-8为3)
// 我也不知道具体原理,只是找出差异点作个判断,以后再来解决这个问题------
int encoding_index = int.Parse(encoding.Preamble.ToString().Substring(encoding.Preamble.ToString().Length - 2, 1));
if (encoding_index == 0) // ANSI编码的情况
{
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
using (StreamReader sr = new StreamReader(path, Encoding.GetEncoding("GBK"))) { text = sr.ReadToEnd(); }
}
else if (encoding_index == 3) // UTF8编码的情况
{
using (StreamReader sr = new StreamReader(path, Encoding.UTF8)) { text = sr.ReadToEnd(); }
}
}读取到txt文件的内容后,就可以逐步分解,找到有用的信息:
// 获取坐标点文本
string txt_cod = text.Substring(text.IndexOf("@") + 1);
// 根据换行符分解坐标点文本
string[] list_point = txt_cod.Split("\n");
// 构建坐标点集合
var vertices = new List<Coordinate2D>();
foreach (var point in list_point)
{
if (!point.Contains("J")) // 跳过无坐标部份的文本
{
continue;
}
double lat = double.Parse(point.Split(",")[3]); // 经度
double lng = double.Parse(point.Split(",")[2]); // 纬度
// 加入坐标点集合
vertices.Add(new Coordinate2D(lat, lng));
}
// 获取名称、地块编号、功能等文本
string txt_filed = text.Substring(text.IndexOf("[地块坐标]") + 1).Split("\n")[1];
string bh = txt_filed.Split(",")[2]; // 地块编号
string mc = txt_filed.Split(",")[3]; // 地块名称
string gn = txt_filed.Split(",")[6]; // 功能获取到所需信息后,就可以用来构面,写入字段值,并保存到数据库中:
/// 构建面要素
// 创建编辑操作对象
EditOperation editOperation = new EditOperation();
editOperation.Callback(context =>
{
// 获取要素定义
FeatureClassDefinition featureClassDefinition = featureClass.GetDefinition();
// 创建RowBuffer
using RowBuffer rowBuffer = featureClass.CreateRowBuffer();
// 写入字段值
rowBuffer["地块编号"] = bh;
rowBuffer["地块名称"] = mc;
rowBuffer["功能分类"] = gn;
// 给新添加的行设置形状
rowBuffer[featureClassDefinition.GetShapeField()] = new PolygonBuilderEx(vertices).ToGeometry();
// 在表中创建新行
using Feature feature = featureClass.CreateRow(rowBuffer);
context.Invalidate(feature); // 标记行为无效状态
}, featureClass);
// 执行编辑操作
editOperation.Execute();编辑后,出现结果未保存的情况,搞不清楚原理,就来个硬保存:
// 保存编辑
Project.Current.SaveEditsAsync();以上便实现了工具的基本功能。
这里可能还有一些未考虑的细节,包括一些因为不懂基本原理的因素,估计会有些BUG,后面边试边改吧。
三、工程文件分享
最后,放上工程文件的链接:
TXT2FeatureClass![]() https://pan.baidu.com/s/1mysXD0LmS_xJ9mPHiVyFfg?pwd=5haiPS:可以直接点击...bin\Debug\net6.0-windows\下的.esriAddinX文件直接安装。
https://pan.baidu.com/s/1mysXD0LmS_xJ9mPHiVyFfg?pwd=5haiPS:可以直接点击...bin\Debug\net6.0-windows\下的.esriAddinX文件直接安装。