下文中的代码都使用参考教程中的例子。
会给出一点自己的解释。
参考教程:
文章目录
- Introduction
- 复习一下nn.Module()
- Torchscript
- torch.jit.ScriptModule()
- torch.jit.script()
- torch.jit.trace()
- 一个小区别
- 使用示例
- tracing Modules
- scripting Module
- Mixing scripting and tracing
- 保存和加载模型
- 实践与优化
Introduction
我们训练好并保存的pytorch,支持在python语言下的使用,但是不支持在一些c++语言下使用。为了能让我们的模型在high-performance environment c++环境下使用,我们需要对模型进行格式转换。
好消息!torch本身是有模型格式转换的功能的,所以我们不需要下载额外的包,就可以把它转为能在c++使用的torchscript模型。
复习一下nn.Module()
之前的章节中有讲过,torch中所有模型都是基于nn.Module()这个类,模型的定义都继承了这个类的属性与方法。
一个完整的模型要包括以下三个基本的部分:
- 一个构造函数,用于调用模型模块
- parameters和sub-modules。它们在构造函数中被初始化,并能在调用中被使用。
- forward()函数,决定了模型调用的顺序。
教程中给出了下面一个简单的例子。
例子中定义了一个名为MyCell的类,它继承了torch.nn.Module()的功能。因为这个模型中没有需要训练的参数和网络层,所以先跳过parameters和sub-modules这一步。要注意这里使用了super,调用了父类的构造函数。
在forward()的部分,该方法的传入参数为x和h(忽略了self)。计算过程中只使用了torch.tanh(x+h),这一步没有参数需要更新。返回的结果为new_h。
class MyCell(torch.nn.Module):
def __init__(self):
super(MyCell, self).__init__()
def forward(self, x, h):
new_h = torch.tanh(x + h)
return new_h
my_cell = MyCell()
x = torch.rand(3, 4)
h = torch.rand(3, 4)
print(my_cell(x, h))
接下来对这个小模型进行一些改动,增加一些需要训练的参数。在教程例子中,它给这个模型增加了一个线性层。
class MyCell(torch.nn.Module):
def __init__(self):
super(MyCell, self).__init__()
self.linear = torch.nn.Linear(4,4) # 在这部分增加了一个线性层
def forward(self, x, h):
new_h = torch.tanh(self.linear(x) + h) # 在调用的时候也使用了线性层,这里的参数需要在训练中更新
return new_h, new_h
my_cell = MyCell()
x = torch.rand(3,4)
h = torch.rand(3,4)
print(my_cell(x,h))
可以看一下我们输出的结果中,多了一个grad_fn,之前我们曾经解释过,这个是反向传播中梯度计算的方法,因为现在有了要学习的参数,所以增加了这个方法。

pytorch具有很高的灵活性。在教程中提到了重要的一点是,很多框架都会在给出完整定义的情况下再进行求导的计算,而在pytorch中不是的,pytorch会在计算进行的时候记录这个操作,并在求导的过程中replay。所以pytorch时并没有很明确的对这些求导操作做出定义。
我自己也不是太理解这些话。我的个人理解是在backwards过程中tensor的grad_fn是随着当前步更新的,而不是预设好的。下面放出原文。
Many frameworks take the approach of computing symbolic derivatives given a full program representation. However, in PyTorch, we use a gradient tape. We record operations as they occur, and replay them backwards in computing derivatives. In this way, the framework does not have to explicitly define derivatives for all constructs in the language.
Torchscript
torchscript的作用就是根据pytorch code来创建一个模型,这个模型可以在非python环境下被使用。所以在pytorch中训练的模型,能够很容易地被应用到一个非python依赖的生产环境中去。
我们先来看一下代码,熟悉一下其中的方法的作用。
torch.jit.ScriptModule()
ScriptModule()也继承了nn.Module()类,所以它也有很多和nn.Module()一样的方法。比如children(),named_children()等。
它还包括一些神秘的方法。比如:
PROPERTY code 返回forward()函数中代码。这个功能是nn.Module()中没有的。
PROPERTY graph 返回forward()函数中的graph。
torch.jit.script()
torch.jit.script(obj, optimize=None, _frames_up=0, _rcb=None, example_inputs=None)
script() 的作用是检查一个function或者nn.Module()的源码,并把它编译成torchscript code并返回一个ScriptModule或者ScriptFunctions。
TorchScript本身是python language的一个子集,所以它并不能完全支持python中的所有功能,但是一些模型相关的计算它都是支持的。
更详细的介绍可以参考。
https://pytorch.org/docs/stable/jit_language_reference.html#language-reference
里面提到了一些对torchscript的限制,比如函数中的参数类型是不可以发生改变的,在python语言中你可以判断参数的种类并作出对应的操作,在torchscript中这是一个错误操作。torchscript中的参数为做特别说明的情况下,均默认为tensor。
这里的输入可以是一个function也可以是一个nn.Module(),要注意这里的example_inputs是有格式要求的:
(Union[List[Tuple], Dict[Callable, List[Tuple]], None])。
我们对我们定义的MyCell进行script,输入是一个nn.Module(),返回结果是一个ScriptModule()。
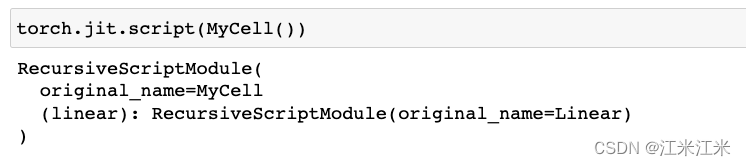
torch.jit.trace()
torch.jit.trace(func, example_inputs=None, optimize=None, check_trace=True, check_inputs=None, check_tolerance=1e-05, strict=True, _force_outplace=False, _module_class=None, _compilation_unit=<torch.jit.CompilationUnit object>, example_kwarg_inputs=None, _store_inputs=True)
torch.jit.trace()可以对一个function进行追踪,并返回一个可执行object或者一个ScriptFunction。你必须提供一个example_inputs。
- The resulting recording of a standalone function produces ScriptFunction.
- The resulting recording of nn.Module.forward or nn.Module produces ScriptModule.
当传入的是一个普调的function时,如下图,返回的结果是一个scriptfunction。

不管传入的是nn.Module还是它本身的forward函数,返回的结果都是一样的。

一个小区别
torch.jit.trace(func, input)只会记录这个input在function中走过的路径,比如下图的示例,虽然我们的在forward()中定义了一个a = torch.rand(3,4),但是这个值和我们的input没有什么关系,所以trace的时候没有记录。而script()则会对整个源码进行分析与记录。

此外trace()无法对if-else等分支进行记录,后面会详细介绍。
使用示例
tracing Modules
torchscript提供了一个方法,帮你获取你的模型的完整定义。首先来看一下tracing方法的作用。
使用上方定义的带线性层的小模型。
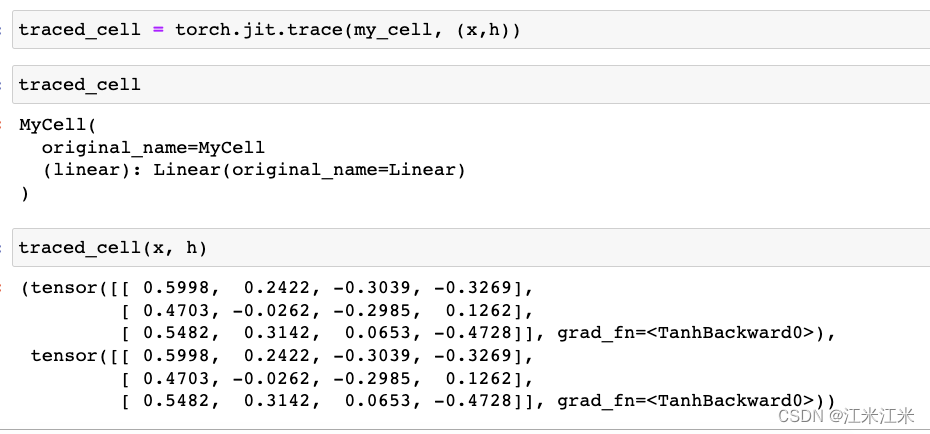
来看一下jit.trace做了什么操作,它首先传入了my_cell,然后传入了对应的输入。trace方法会调用这个Module,并且记录其中的每一步操作,并创造一个ScriptModule的实例。
我们可以看一下它的code。

使用trace方法会有一些天然的缺陷。它追踪了你的输入在function中经过的每一步操作,所以如果你的function中存在判断语句时,未被触发的操作就会被忽略掉。
使用教程中给出的例子。
class MyDecisionGate(torch.nn.Module):
def forward(self, x):
if x.sum() > 0:
return x
else:
return -x
class MyCell(torch.nn.Module):
def __init__(self, dg):
super(MyCell, self).__init__()
self.dg = dg
self.linear = torch.nn.Linear(4, 4)
def forward(self, x, h):
new_h = torch.tanh(self.dg(self.linear(x)) + h)
return new_h, new_h
my_cell = MyCell(MyDecisionGate())
traced_cell = torch.jit.trace(my_cell, (x, h))
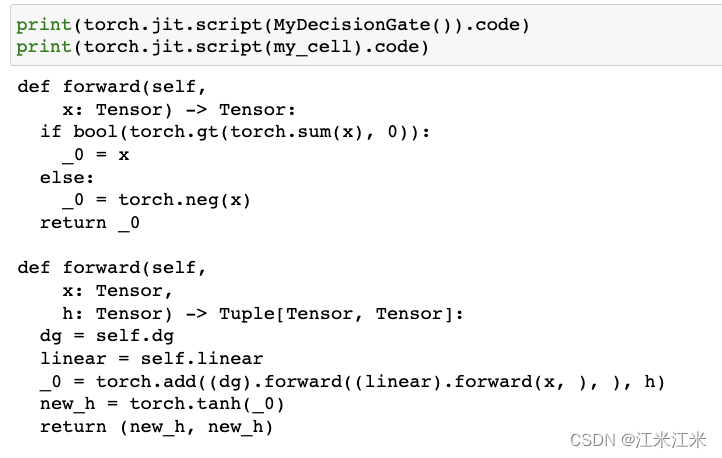
print(traced_cell.dg.code)
print(traced_cell.code)
在这个例子中,MyDecisionGate函数进行了一个判断,假如传入的x的总和大于0,就返回x本身,假如x的总和小于0,就返回-x。
Converting a tensor to a Python boolean might cause the trace to be incorrect. We can’t record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!

我们可以看到因为我们的输入并不能走过if-else的两条路径,所以我们trace的结果中也只有一条路。我们的if-else方法不见了。
scripting Module
在上面的trace方法中,它对你的输入走过的路径进行记录,所以它看不到输入没有经过的地方。而我们的第二个方法,script() 则是直接对你的源码进行分析,所以能够保留比较完整的结果。
Mixing scripting and tracing
假如你的代码中有些不希望被torch.jit.script记录的常量,你可以使用trace和script的组合,将这些常量隐藏。
对这部分的理解是,对于有多个分支并且又有你想要隐藏的参数的情况下,可以使用trace和script的组合。多分支的部分用script记录,隐藏参数的部分用trace记录。
class MyDecisionGate(torch.nn.Module):
def forward(self, x):
if x.sum() > 0:
return x
else:
return -x
scripted_gate = torch.jit.script(MyDecisionGate())
class MyCell(torch.nn.Module):
def __init__(self, dg):
super(MyCell, self).__init__()
self.dg = dg
self.linear = torch.nn.Linear(4, 4)
def forward(self, x, h):
new_h = torch.tanh(self.dg(self.linear(x)) + h)
return new_h, new_h
第一个例子,torch.jit.script和traced module内联。
class MyRNNLoop(torch.nn.Module):
def __init__(self):
super(MyRNNLoop, self).__init__()
self.cell = torch.jit.trace(MyCell(scripted_gate), (x, h))
def forward(self, xs):
h, y = torch.zeros(3, 4), torch.zeros(3, 4)
for i in range(xs.size(0)):
y, h = self.cell(xs[i], h)
return y, h
rnn_loop = torch.jit.script(MyRNNLoop())
print(rnn_loop.code)
第二个例子,torch.jit.trace()和scripted module内联。
class WrapRNN(torch.nn.Module):
def __init__(self):
super(WrapRNN, self).__init__()
self.loop = torch.jit.script(MyRNNLoop())
def forward(self, xs):
y, h = self.loop(xs)
return torch.relu(y)
traced = torch.jit.trace(WrapRNN(), (torch.rand(10, 3, 4)))
print(traced.code)
我们观察一下第二个例子,比较一下最后使用jit.trace和jit.script有什么区别。
大家可以看到使用trace时,loop的返回结果是_0, y;使用script时,lopp返回的结果是y, h。

保存和加载模型
torchscript可以将模型独立地保存下来,保存的信息包括模型的code,parameters, attribute和debug information。这些完整的信息让我们的模型可以独立地表达,并在一个完全不同的进程中被加载,下面给出了代码例子。
traced.save('wrapped_rnn.pt')
loaded = torch.jit.load('wrapped_rnn.pt')
print(loaded)
print(loaded.code)
实践与优化
放一下源码的链接OPTIMIZING VISION TRANSFORMER MODEL FOR DEPLOYMENT。链接里内容更详细,有条件的直接看源码。我只是crop出来了中间和torchscript相关的部分。
from PIL import Image
import torch
import timm
import requests
import torchvision.transforms as transforms
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
print(torch.__version__)
# should be 1.8.0
model = torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True)
model.eval()
transform = transforms.Compose([
transforms.Resize(256, interpolation=3),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD),
])
img = Image.open(requests.get("https://raw.githubusercontent.com/pytorch/ios-demo-app/master/HelloWorld/HelloWorld/HelloWorld/image.png", stream=True).raw)
ten = transform(img)[None,]
out = model(ten)
clsidx = torch.argmax(out)
print(clsidx.item())
将模型以script 的形式保存下来
model = torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True)
model.eval()
scripted_model = torch.jit.script(model)
scripted_model.save("fbdeit_scripted.pt")
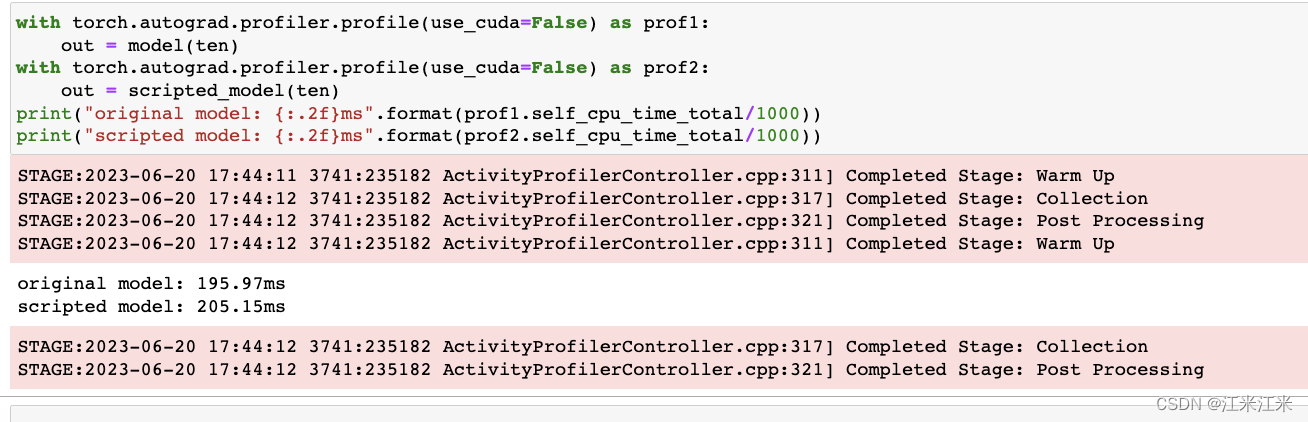
比较一下两者的时间,两者在时间上是没有什么明显差别的。在教程中使用了一些模型加速的方法,所以inference的时间会变快。