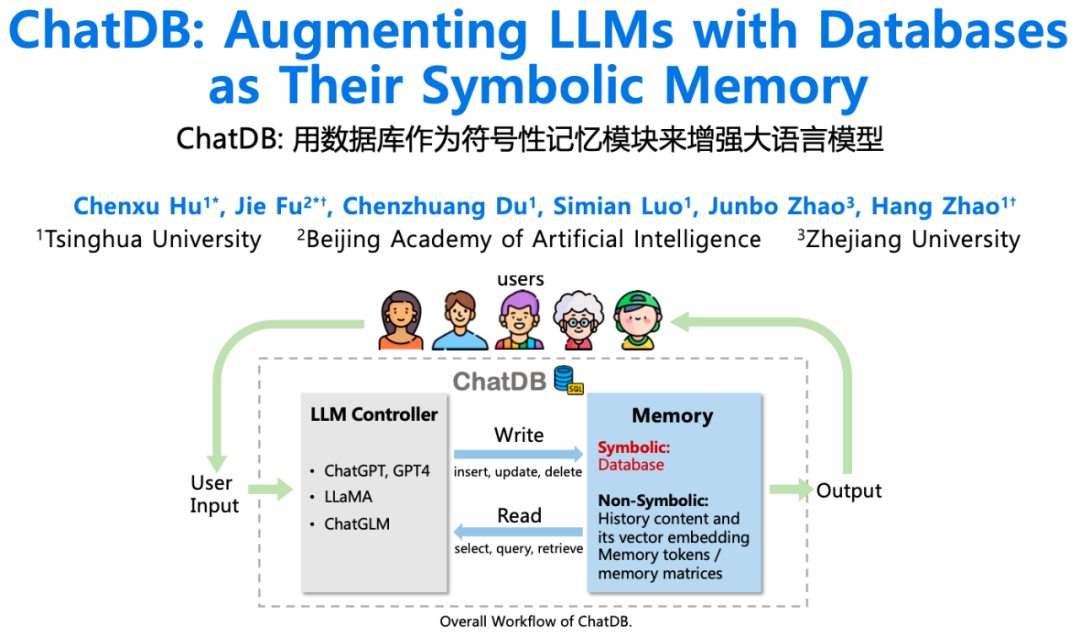
结合符号性记忆,清华等提出ChatDB,提升大模型的复杂推理能力
随着大语言模型(Large Language Models)的爆火,例如 ChatGPT,GPT-4,PaLM,LLaMA 等,如何让大语言模型更好的应对有很长的上下文信息(超出其最大处理长度)的场景并利用相关历史信息做复杂的推理,成为一个热点研究话题。现有的主流做法是给大语言模型增加记忆(memory)模块,在需要的时候从记忆模块中提取相关的历史信息帮助大语言模型。
近期,清华大学和北京智源人工智能研究院的研究者们提出了一种新型的符号性(symbolic)记忆模块。他们从现代计算机架构中汲取灵感,利用符号性记忆模块来增强大型语言模型。这种符号性记忆模块可以利用符号性的操作,精确的控制记忆模块中的信息。这样的符号性记忆框架由一个大语言模型(如 ChatGPT)和一个数据库组成,称为 ChatDB。其中大语言模型负责控制对记忆模块的读写操作。在 ChatDB 中,大语言模型通过生成 SQL 指令来操纵数据库,从而实现对记忆模块中历史信息精确的增删改查,并在需要时为大语言模型提供信息,以帮助其回应用户的输入。这项研究可以让大语言模型胜任需要对历史信息进行长期且精确的记录、处理和分析的场景,例如各种管理和分析系统,以后甚至有望替代管理者,直接让大语言模型根据精确的历史数据做分析和决策。
相关论文为:ChatDB: Augmenting LLMs with Databases as Their Symbolic Memory,代码已开源。
-
论文地址:https://arxiv.org/abs/2306.03901
-
项目主页:https://chatdatabase.github.io
-
项目代码:https://github.com/huchenxucs/ChatDB
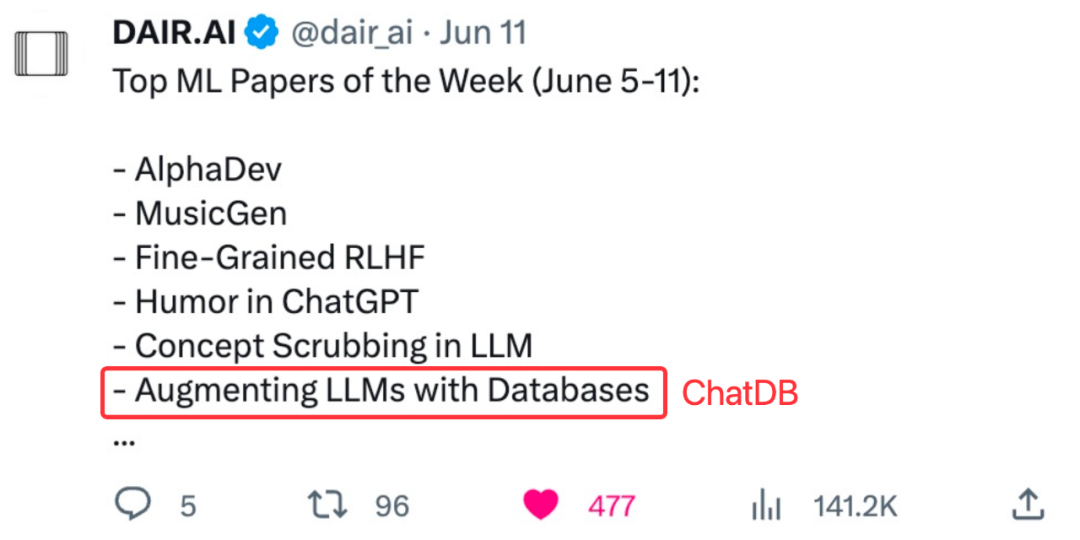
推特上一些知名的机器学习和自然语言处理研究者也对这项研究进行了宣传:

与相关工作的对比
之前的记忆模块主要分为,Prompt-based memory 和 Matrix-based memory 两类。Prompt-based memory 是将之前的历史文本和相应文本的 vector embedding 保存下来,需要的时候再利用 vector embedding 间的相似性找到相关的历史信息,然后放到 prompt 中,作为大语言模型的输入,相关的工作有 Auto-GPT 和 Generative Agents 等等。Matrix-based memory 是利用额外的 memory tokens 或者 memory matrices 来记录历史信息,相关的工作有 Recurrent Memory Transformer 等等。之前这些记忆模块的设计,要么需要依靠文本的 vector embedding 之间的相似度,要么将历史信息隐式地存储在神经网络的权重中,都涉及神经性(neural)的操作,无法像符号性操作那样精确操纵记忆模块中的历史信息。
它们的主要问题有两点:(1) 没有以结构化的形式存储历史信息;(2) 对存储在记忆模块中的信息的操作不够精确:它们依赖于一些向量相似度的计算,这可能不准确,长期下来或者进行多步推理的时候就会导致错误的积累。
ChatDB 借鉴之前 Neuro-symbolic AI 的一些工作,如 Neural Symbolic Machines,利用支持 SQL 指令的数据库作为符号性记忆模块,来支持对历史信息抽象的(abstract),可拓展的(scalable)和精确的(precise)的操作。这些都是引入符号性记忆模块所带来的优势。符号性记忆模块还可以跟之前的记忆模块同时使用,起到相辅相成的作用。
之前的一些大语言模型和数据库结合的工作(比如DB-GPT和ChatExcel)也涉及用大语言模型生成 SQL 或 Excel 的指令,但 ChatDB 跟它们有本质上的不同。DB-GPT 和 ChatExcel 更多关注利用大语言模型解决自然语言到 SQL 或 Excel 指令的转化,而且更多只是用来解决查询的问题,数据源本身是给定好的。ChatDB 则是将数据库作为符号性记忆模块,不只涉及查询,包括了数据库的增删改查等所有操作,整个数据库是从无到有,不断记录并更新大语言模型的历史信息。并且,ChatDB 中的数据库,即符号性记忆模块,是与大语言模型紧密关联、融为一体的,可以帮助大语言模型进行复杂的多步推理。
从大语言模型使用工具的视角来看,类比之前的工作 Toolformer 和 Langchain,ChatDB 将符号性记忆模块(即数据库)用作工具。其优势在于,对于需要使用准确历史数据进行多步推理的问题,它可以让大语言模型更准确的存储并使用历史数据,而且可以利用数据库存储和再利用推理的中间结果,从而取得更好的效果。
重要意义
该工作对大语言模型(LLMs)领域做出了如下几个贡献:
-
首先,提出了 ChatDB—— 一个用数据库作为 LLMs 的符号性记忆模块来增强 LLMs 的框架。这使得历史数据可以精确的以结构化的方式进行存储,并且支持使用 SQL 语句进行抽象的、可拓展的、精确的数据操作。
-
其次,提出了 Chain-of-Memory(CoM,记忆链)方法,通过将用户输入转化为多步中间的记忆操作,实现了对记忆模块中历史信息的复杂操作。这提高了 ChatDB 的性能,使其能够处理复杂的、涉及多个表的数据库交互,并提高了准确性和稳定性。
-
最后,将符号性记忆模块与 LLMs 结合,可以避免错误的累积,方便地存储中间结果,从而提高了多步推理(multi-hop reasoning)能力,使 ChatDB 在合成数据集上显著优于 ChatGPT。
方法
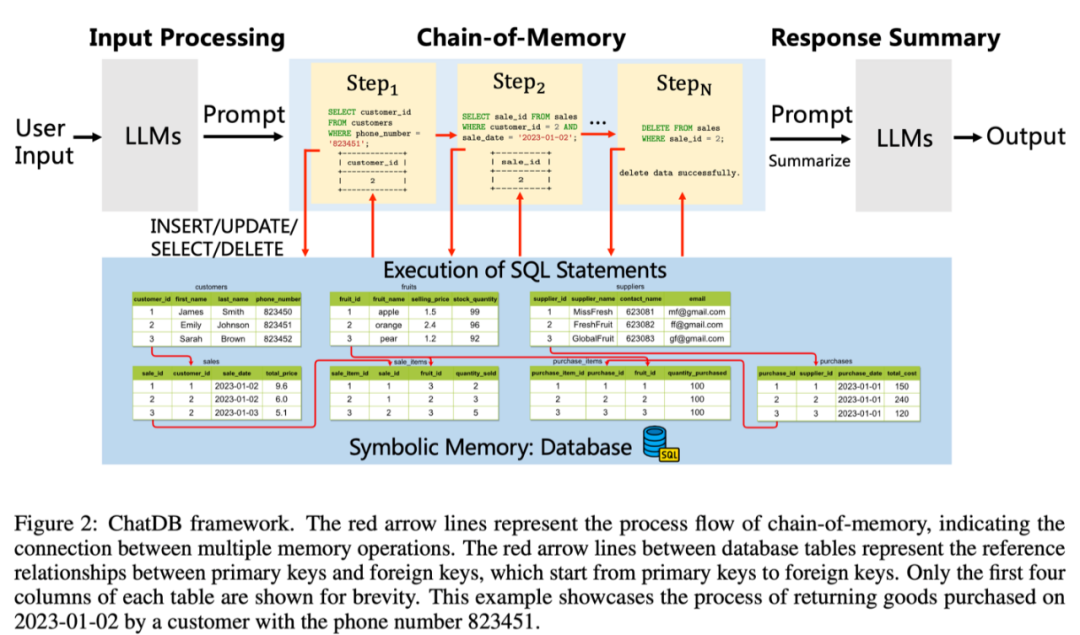
ChatDB 框架包含三个主要阶段:input processing(输入处理),chain-of-memory(记忆链),和 response summary(总结回复),如图 2 所示。
1 输入处理:对于用户的输入,如果不涉及使用记忆模块,则直接生成回复;如果需要记忆模块,如查询或者更新数据库,语言模型则生成与记忆模块交互的一系列 SQL 语句。
2 记忆链:执行一系列记忆操作来与符号性记忆模块交互。ChatDB 按照先前生成的一系列 SQL 语句依次操作符号性记忆模块,包括插入、更新、选择、删除等操作。外部数据库执行相应的 SQL 语句,更新数据库并返回结果。值得注意的是,在执行每一步记忆操作之前,ChatDB 会根据先前 SQL 语句的结果决定是否更新当前记忆操作。ChatDB 按照此过程执行每一步记忆操作,直到所有记忆操作完成。
3 总结回复: 语言模型综合与数据库交互得到的结果,并对用户的输入做出总结回复。
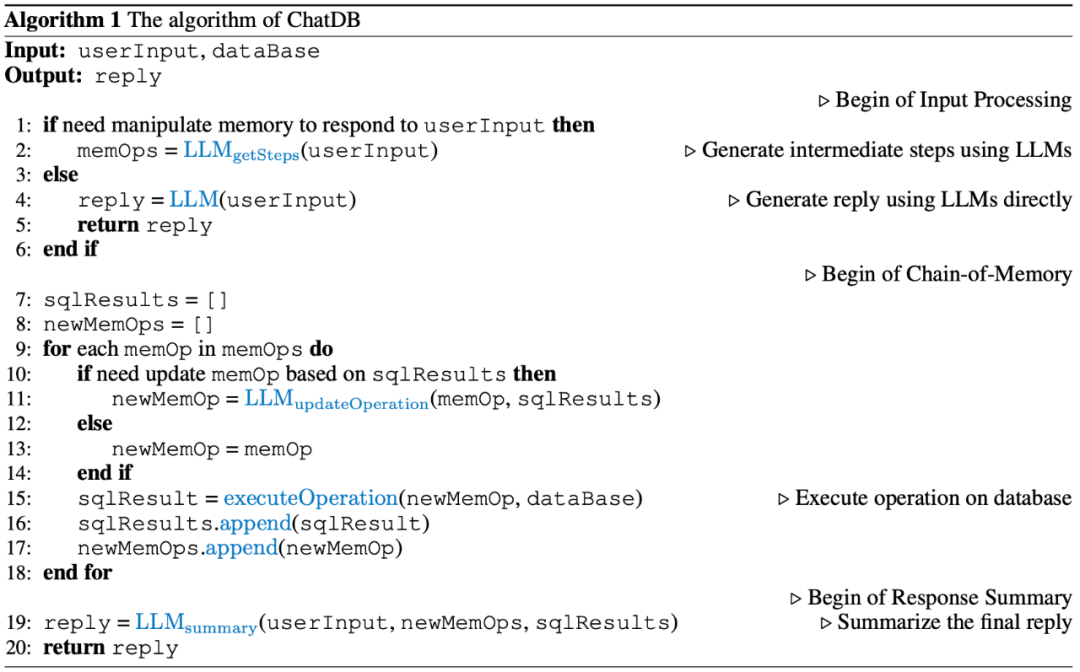
其中 Chain-of-Memory(CoM,记忆链)是一个新提出的方法,以更有效地操作符号性记忆模块,从而进一步增强 LLMs 的推理能力。记忆链方法将用户输入转化为一系列中间记忆操作步骤,将复杂的问题用多个记忆操作步骤来解决,每个中间步骤涉及一个或多个 SQL 语句,大大降低了解决问题的复杂度。
实验和结果
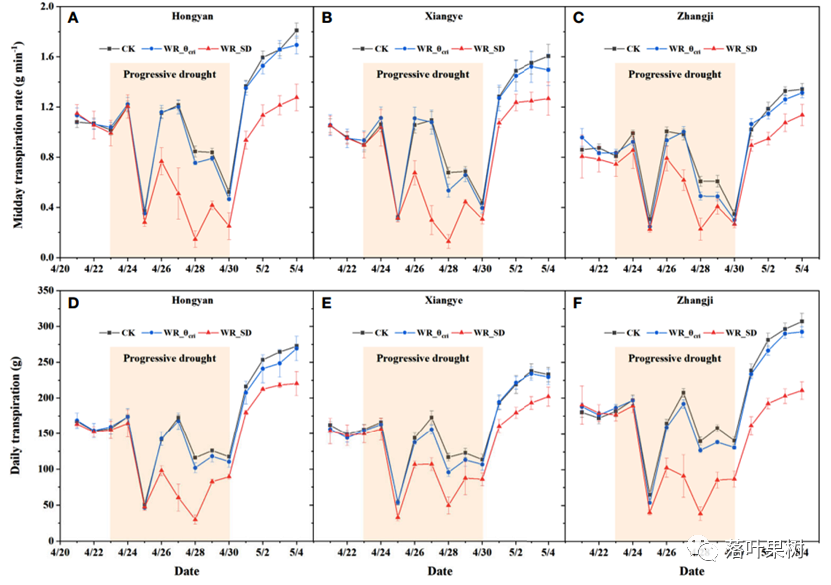
实验设置:为了验证 ChatDB 中将数据库作为符号性记忆模块来增强大语言模型的有效性,并与其他的模型进行定量比较,作者构造了一个模拟一家水果店的运营管理的合成数据集。该数据命名为 “水果商店数据集”,其中包含了 70 条按时间顺序生成的商店记录,总共约有 3.3k 个 tokens(小于 ChatGPT 最大上下文窗口长度 4096)。这些记录包含水果店的四种常见操作:采购、销售、价格调整和退货。为了评估模型的性能,作者针对销售记录收集了 50 个问题,并为这些问题标注了标准答案。这些问题主要涉及商店数据的分析和管理,它们难度各不相同,既包括需要进行多次推理的困难问题,也包括只需从历史数据中检索信息的简单问题。其中包含了 15 个简单问题和 35 个困难问题。
模型对比:ChatDB 模型中的 LLM 模块使用了 ChatGPT (GPT-3.5 Turbo),温度参数设置为 0,并使用 MySQL 数据库作为其外部符号性记忆模块。对比的基线模型为 ChatGPT (GPT-3.5 Turbo),最大的上下文长度为 4096,温度参数也设置为 0。
指标结果:作者在水果商店问答数据集上进行了实验,相对于 ChatGPT,ChatDB 在这些问题的解答上展现出了显著的优势。
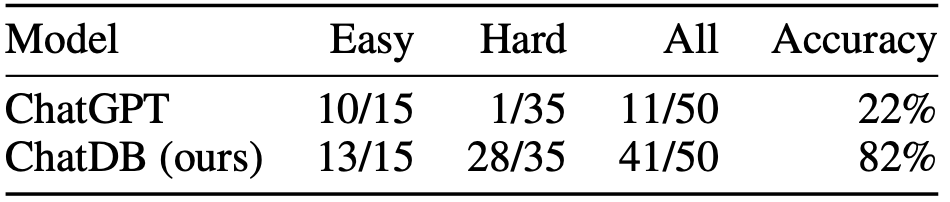
表 1:回答水果商店数据集中问题的正确率
作者表示目前实验还只是在一个简单的合成数据集上进行的,之后会在更复杂更贴近现实需求的场景下进行实验,拓展 ChatDB 的应用价值。
Demo 展示
下面是用大语言模型作为店长经营一家水果商店的例子:

商店进货
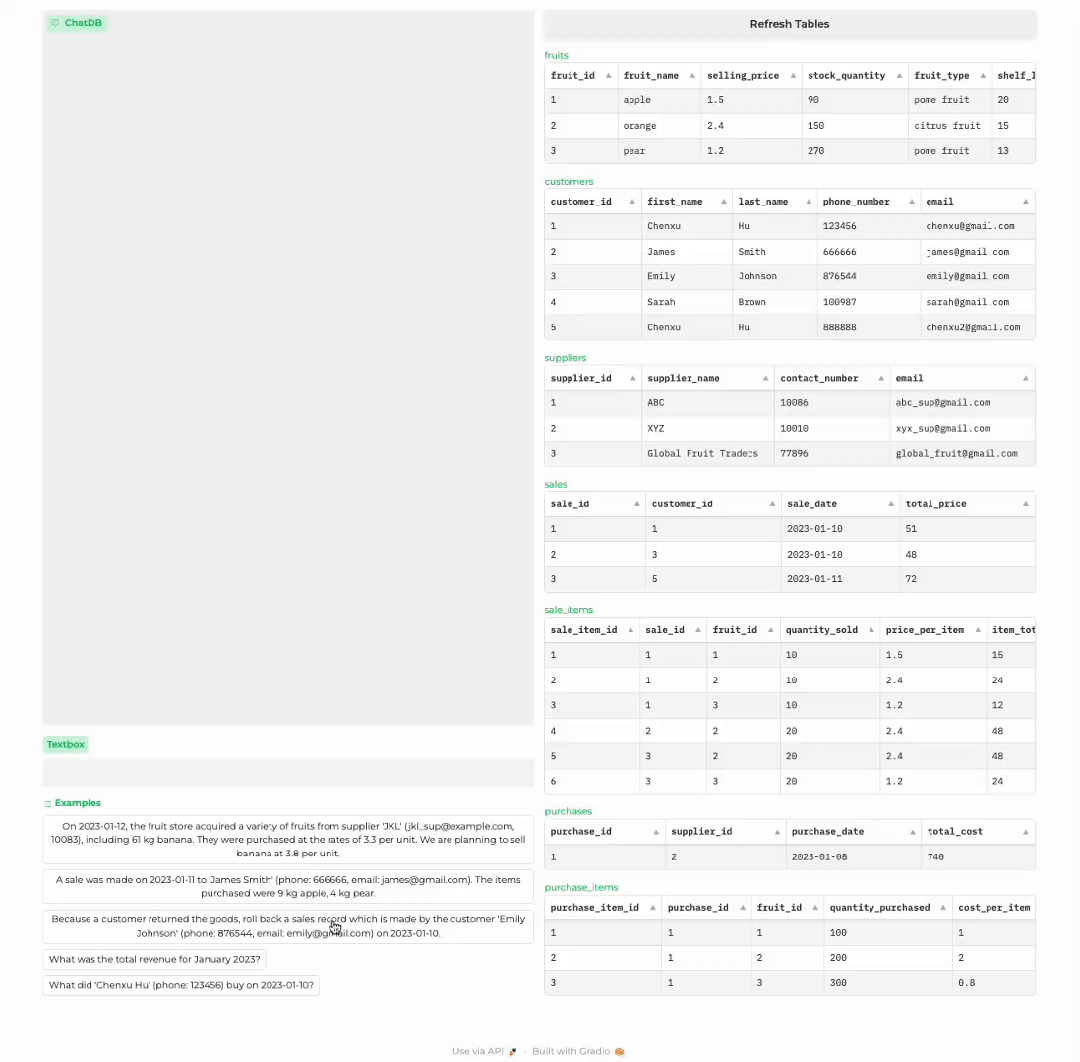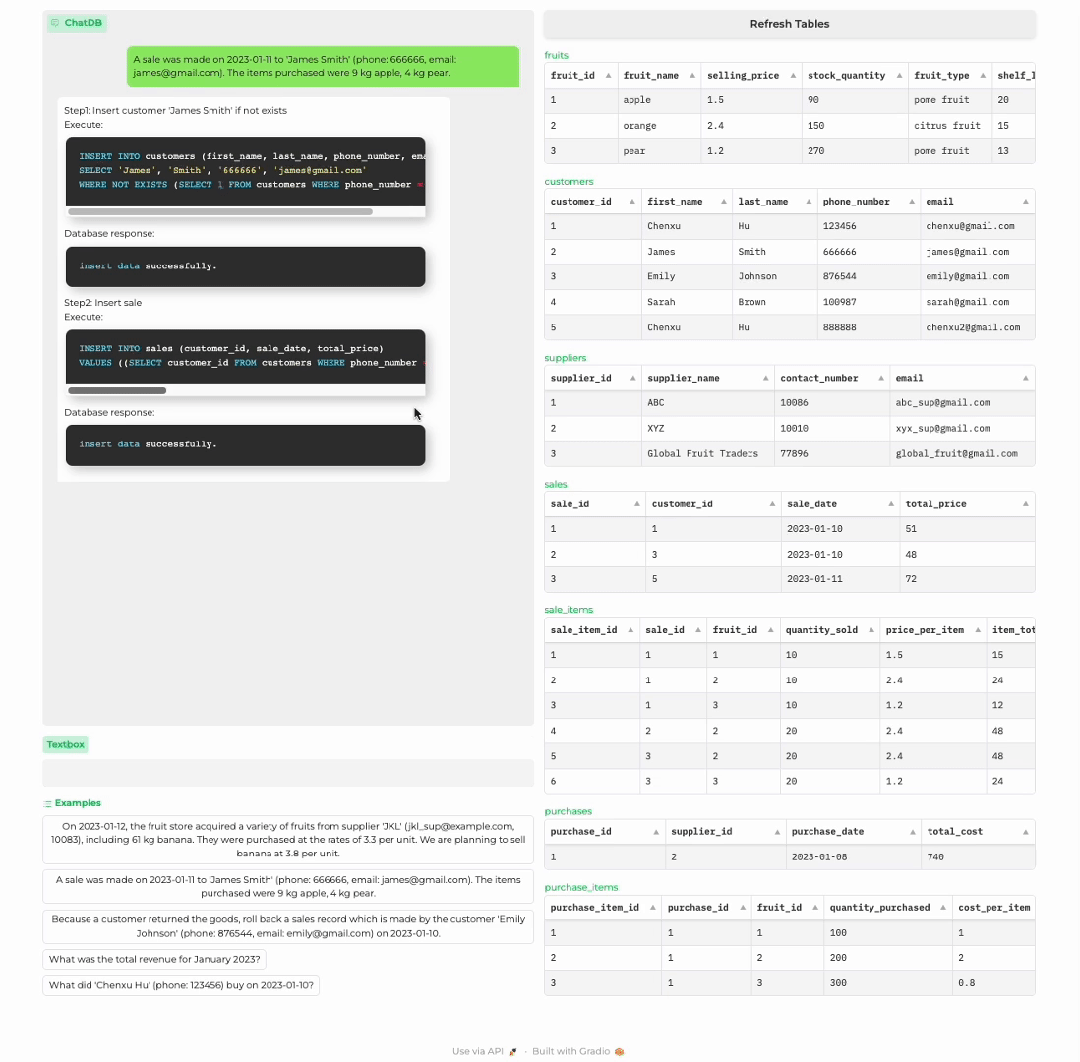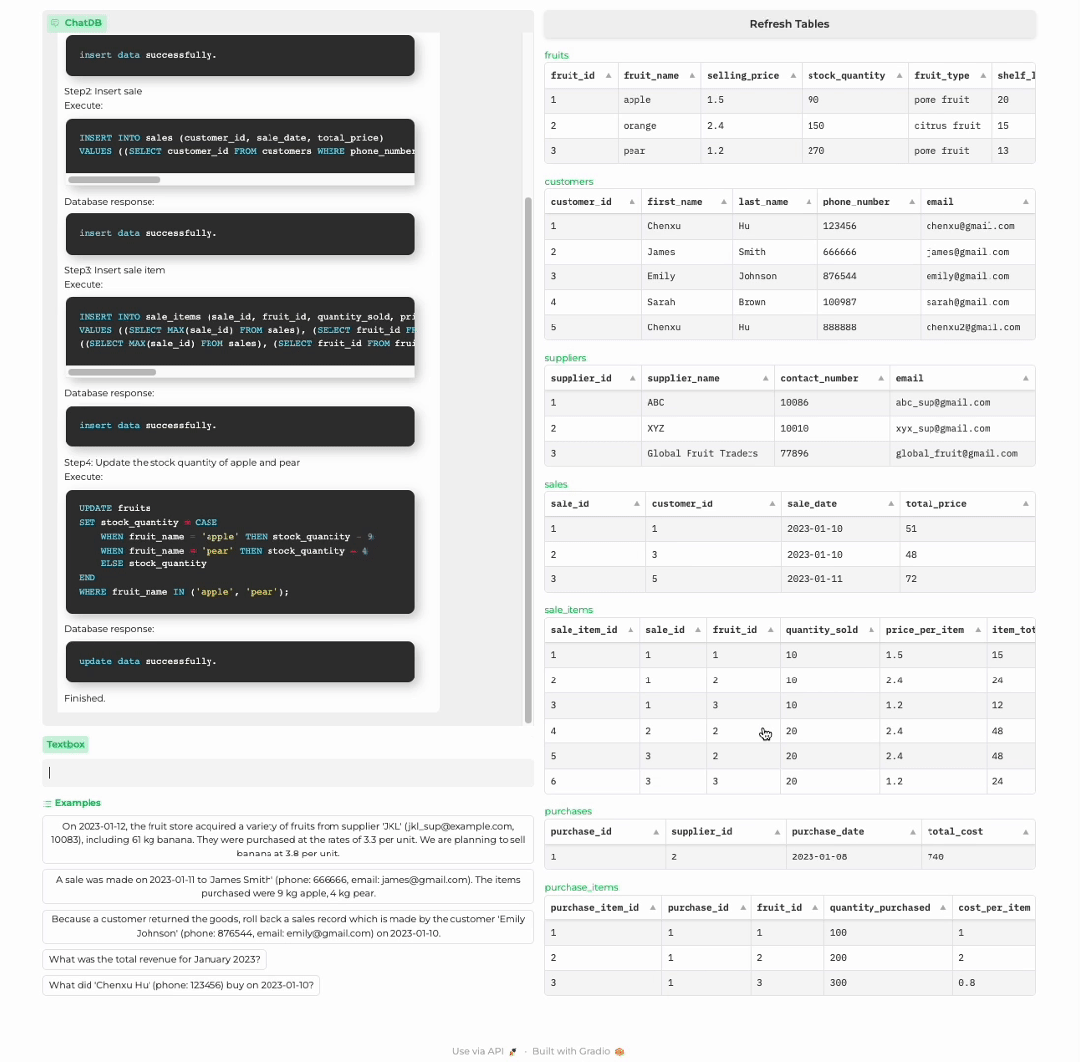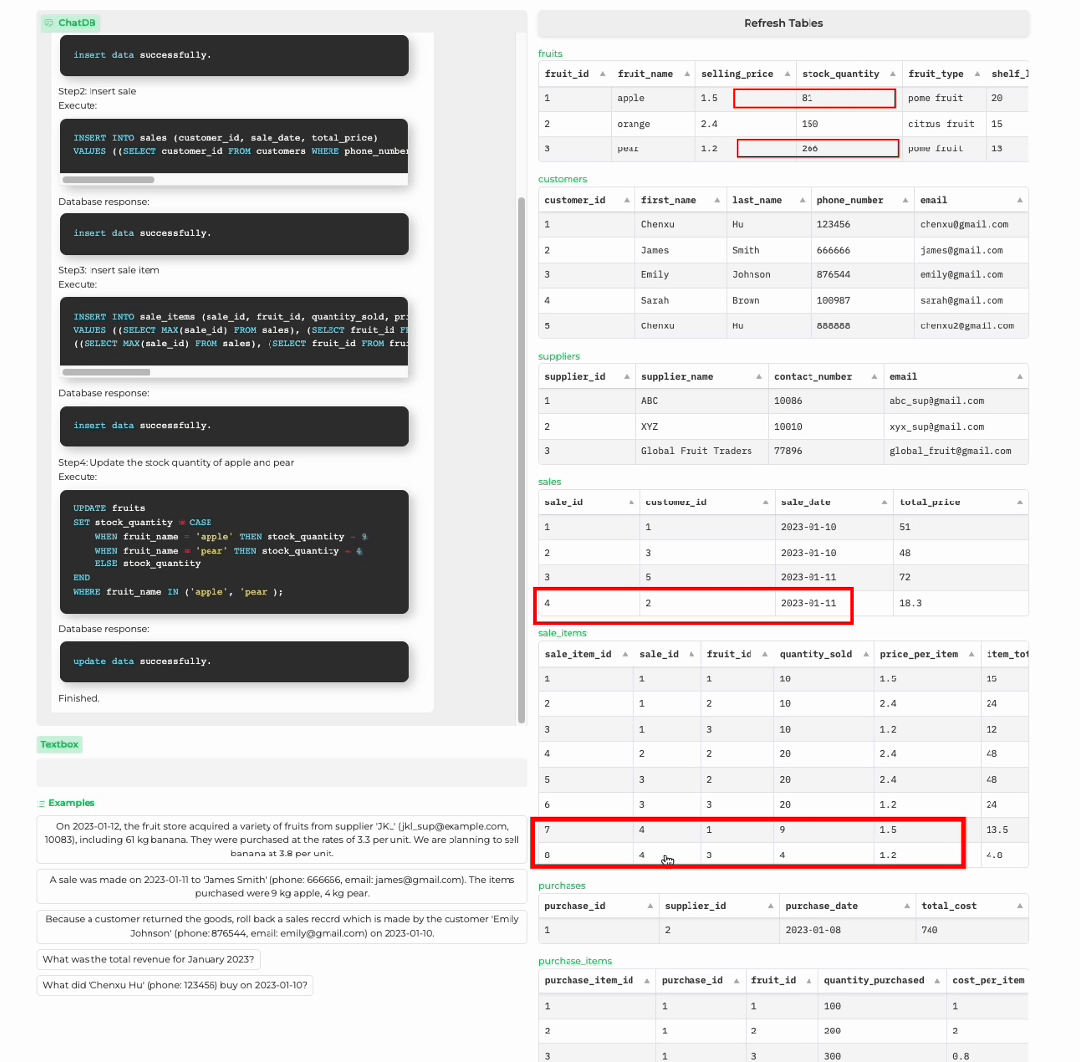
顾客购买商品

顾客退货

分析商店历史记录
ChatDB 交互示例:
ChatDB对水果商店数据集中四种常见操作的回应:
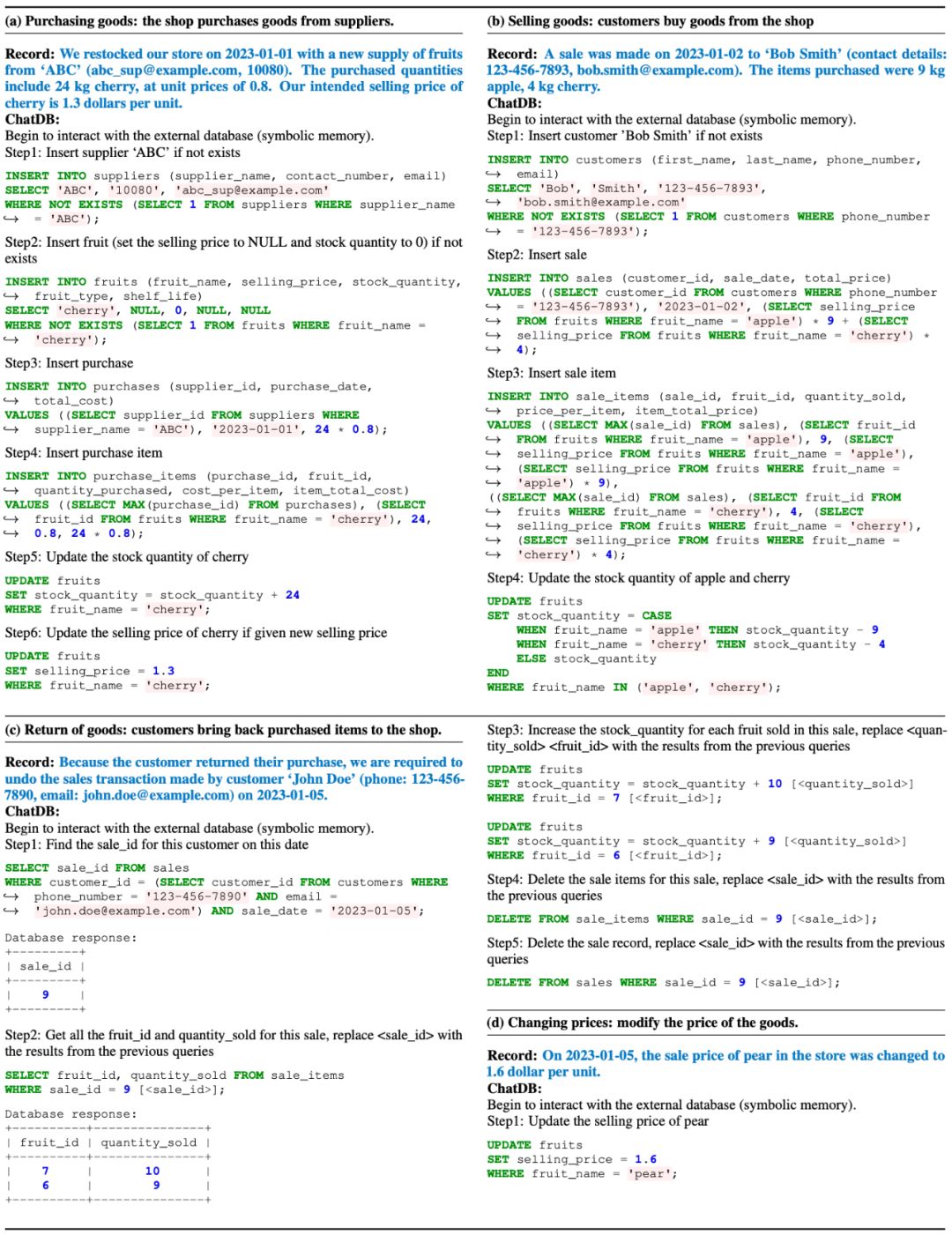
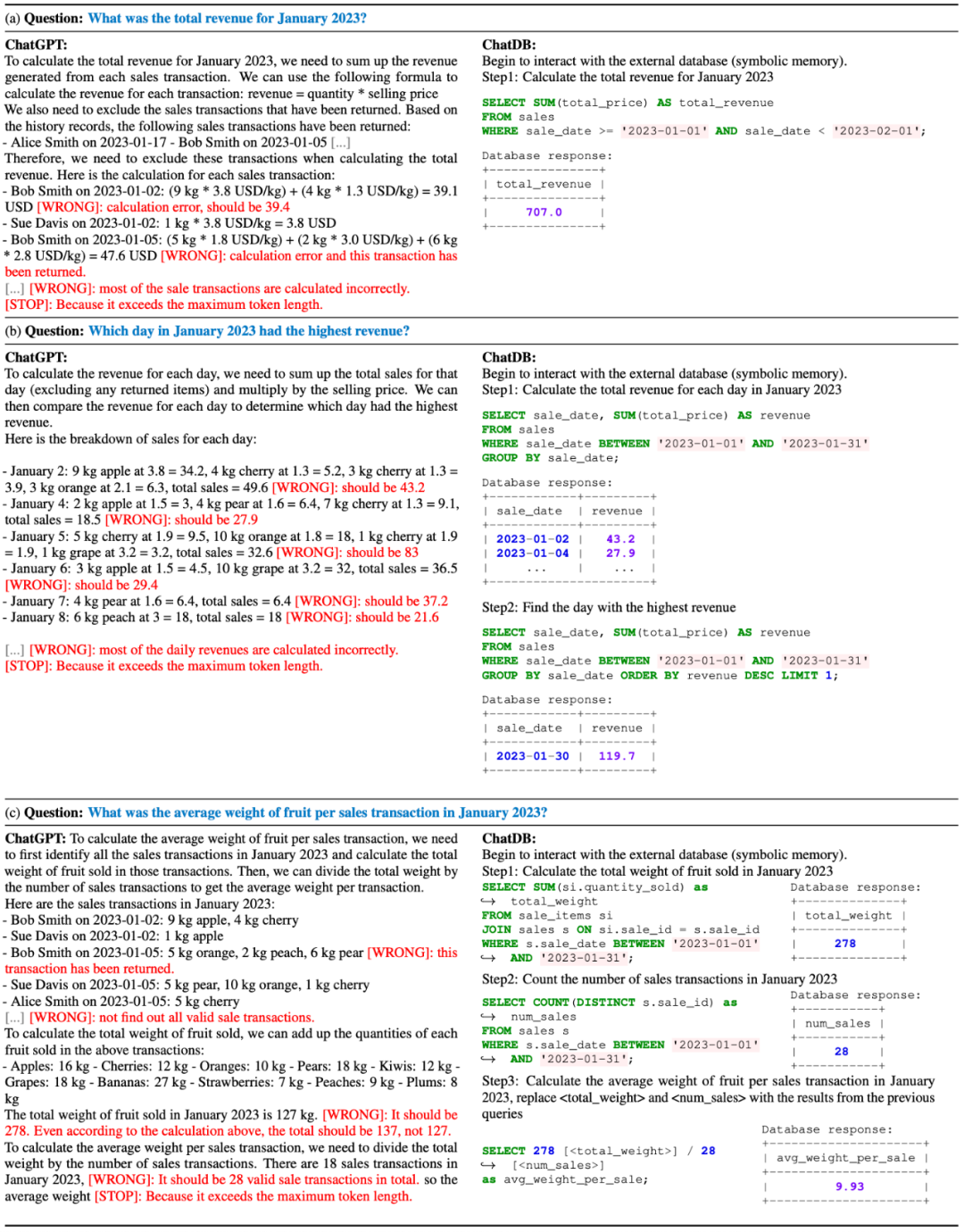
ChatDB和ChatGPT回答问题的示例:
这三个例子中,ChatGPT无法正确回答任何问题,但ChatDB成功回答了所有问题。
团队介绍
该论文来自于清华大学 MARS Lab和北京智源研究院,论文的作者为清华大学博士生胡晨旭,杜晨壮,骆思勉,指导老师为付杰,赵行,赵俊博。
清华大学MARS Lab,是清华大学交叉信息院下的人工智能实验室,由赵行教授组建和指导。我们尝试解决一系列探索性的AI问题,并且一直在寻找新的挑战。当前我们特别感兴趣如何让机器像人一样的能够通过多种感知输入进行学习、推理和交互。我们的研究涵盖了许多基础AI问题及其应用:(1)多媒体计算, (2)自动驾驶, (3)机器人。




![强化学习从基础到进阶-常见问题和面试必知必答[2]:马尔科夫决策、贝尔曼方程、动态规划、策略价值迭代](https://img-blog.csdnimg.cn/8f84b5eeda21460e9be56aa2aa3cb0c5.png#pic_center)