NeurIPS 2022|DeepMind最新研究:大模型背后的ICL可能与数据分布密切相关
- 大模型
- 自然语言处理
- 机器学习
传统的文本语言模型倾向于两阶段的训练模式,即首先在大规模语料库上进行预训练,然后在目标下游任务上进行微调,这种方式会受数据标注质量和过拟合等多方面的影响。最近兴起并流行的大型语言模型(large language models,LLMs)已经克服了这类问题,并且会展现出惊人的ICL能力(In-Context Learning),无需对其进行明确的下游任务微调训练,即可执行上下文相关的小样本学习任务。这一观察使语言模型研究者们抛出了这样一个问题:到底是训练阶段中的哪些方面导致了这种上下文学习呢?

论文链接:
https://arxiv.org/abs/2205.05055
代码链接:
https://github.com/deepmind/emergent_in_context_learning
本文介绍一项来自DeepMind发表在NeurIPS 2022(Oral)上的工作,在这项工作中,他们对ICL的内部机制进行了探索。作者团队表明,这一现象很大程度上是由训练数据本身的分布驱动的,当训练数据表现出特定的分布特征时,例如数据出现突发性类别分布时(即处于分布尾部的类别数量急剧增加时),ICL就会出现。而且当这些样本的语义并不固定呈现动态变化时,ICL也会进行的更彻底。而对于传统监督学习范式中,每个样本都具有明确的语义属性,这种方式更专注于基于权重的模型学习。
本文作者想到,是否可以将ICL与传统的权重式学习进行有机结合呢,在最初的实验中,模型无法兼顾二者。作者随后从数据分布的角度入手,发现当模型按照有偏的Zipfian分布[1](幂律分布)进行训练时,这两种学习模式可以实现一种权衡。此外还有一个非常重要的发现是,这种ICL只能在Transformer架构中进行上下文学习,在传统的递归模型中则无法进行。这也侧面印证了基于Transformer的架构在语言学习中更具优势,如果能进一步研究其与训练数据分布之间的理论关系,将会更有效的促进”具有魔力“的ICL。
一、引言
ICL可以使基于Transformer的LLMs进行小成本的上下文学习,这其实是一种无需对模型进行梯度更新的优化过程。其与传统的权重学习形成了鲜明对比,后者作为监督学习的标准模式具有一定的局限性,例如学习速度缓慢,对数据标注要求过高等等。而ICL无需明确指定下游任务就可以完成小样本学习任务。这种差异性到底是由什么引起的呢,作者首先考虑了模型架构上的变化,例如Transformer模型目前已在语言学习领域逐渐取代了传统的递归模型,背后的原因就是Transformer架构具有更优秀的上下文学习能力。
除了这种新颖模型架构变化的因素,作者探讨了第二种可能性:模型上下文学习的能力取决于训练数据的分布质量。因此在本文中,作者设计实验来具体操作训练数据的分布情况,并且使用专业度量测算了其对ICL小样本学习的影响。作者选用小样本任务基准进行评估,并且对数据集的原有分布进行调整,来观察数据分布变化是否会直接导致ICL的发生。实验结果表明,当出现突发性的尾部类别数量增加以及样本语义动态变化时,Transformer模型会出现ICL的行为。此外作者还强调,模型架构对于ICL也非常重要,例如像LSTM和RNN这样的经典递归模型,即使在参数规模相同的情况下,仍然无法进行像Transformer结构一样的上下文学习。
二、实验方法
2.1 训练数据
为了在数据层面分析模型在小样本任务中的ICL能力,作者在这里选用了Omniglot数据集[2]进行实验,并且独立创建了新的训练和评估列表。Omniglot数据集是一种专用于小样本学习的标准图像数据集,其由来自国际字母表中的1623个不同的字符类组成,每个类包含20个手写示例。使用Omniglot数据集也方便后续对模型进行专业的小样本能力评估。

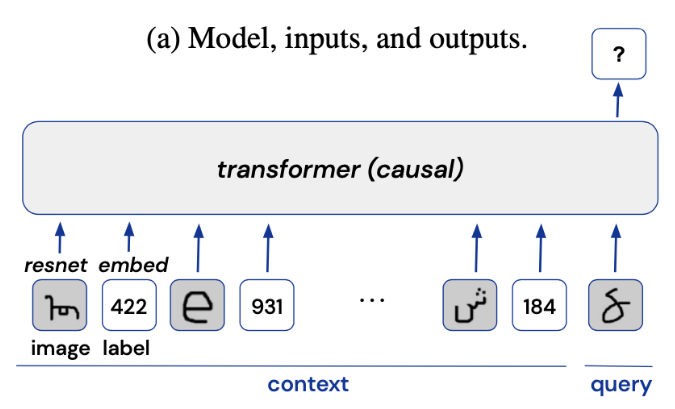
具体的训练数据由图像和标签序列组成,如上图所示。其中每个序列的前16个元素包含“上下文”,并由8个图像标签对组成(其中每个图像始终绑定其相应的标签)。最后一个元素是query图像,模型的学习目标是准确预测query的正确标签。
2.2 模型设计
本文的实验模型设计简单直观,输入序列的每个元素首先通过两个编码器(一个用于对整数标签编码的标准嵌入层,一个用于对图像进行编码的ResNet)生成嵌入。随后这些嵌入的tokens被送入到一个因果Transformer模型[3]中,如下图所示。这里作者设置了12层且嵌入向量大小为64的Transformer层,模型最终对输入图像的预测使用softmax交叉熵损失函数进行优化。
2.3 评估数据
在模型训练结束后,作者遵循标准的小样本学习设置,构建了测试数据集来评估模型的小样本学习能力,其中上下文包括2个不同图像类的随机排序,每个图像类有4个示例,query是从两个图像类之一中随机选择的,在小样本学习中,这种设置称为”2-way 4-shot“问题。此外需要注意的是,此时的评估序列与训练阶段的固定标签不同,这两个图像类别的标签需要进行重新分配,即一个图像类别被分配给0,另一个被分配给1,如下图所示。基于这种设置,模型必须能够理解当前设置中的上下文才可以对query图像进行准确的标签预测,才能够检验出模型真实的ICL能力。

但是这样设计也存在一个缺陷,仅设置两个类别(0和1)来进行ICL能力测试,模型预测正确预测的概率为1/2,会出现随机预测恰好命中目标的情况。
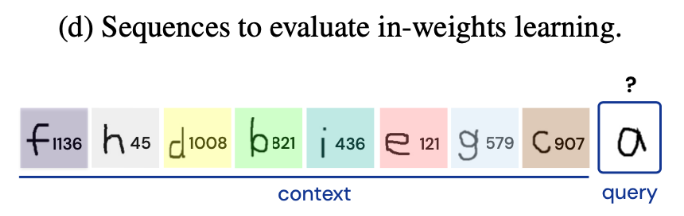
除了对模型进行ICL测试之外,作者也设计对权重学习的评估序列。由于权重学习的限制,评估序列的样本标签与训练时使用的标签是相同的,如上图所示。因此,模型正确预测标签的唯一方法是依赖于存储在模型权重中的信息。对于这种设置,模型预测正确的概率通常是1/1600。
三、实验结果分析
通过对实验结果进行分析,作者回答了上文提出的几个疑问,下面进行详细介绍。
3.1 什么样的训练数据可以促进ICL?
训练数据分布对于ICL的影响因素主要包括样本突发性、尾部类数量增加、标签的多样性和类内差异明显四个方面。
3.1.1 样本突发性
作者在第一个实验中通过改变训练数据中突发序列与非突发序列的比例来改变训练数据中的突发性水平。通过实验发现,Transformer结构可以在这种数据分布中进行ICL的小样本学习,如下图(a)所示,此外在这种情况下,ICL与权重学习之间已经出现一定的权衡,更大的数据突发程度会导致权重学习的比例下降,如下图(b)所示,而且在特殊情况下,模型可能会逐渐抛弃ICL,完全转向权重学习。
3.1.2 尾部类别数量增加
本文的第二组实验表明,ICL的性能取决于训练类的数量,当训练类别数量从100增加到1600时,ICL的性能会逐渐上升,如下图(a)所示,而权重学习的性能则会呈下降趋势,如下图(b)所示,这一现象符合长尾分布问题中的假设。为了进一步增加原始Omniglot数据集中可用的1623个类别数量,作者对原数据集进行旋转(0°、90°、180°、270°)和翻转(左右)操作,使类别数量增加到12800,这一操作进一步改善了ICL并削弱了权重学习。
3.1.3 标签的多样性
作者在第三组实验中探索了数据语义动态变化的影响,即训练分布中的图像没有完全固定的标签,每个图像类别被分配给多个可能的标签。如果一个类别在同一序列中出现不止一次,则该序列中的所有样本的标签都应该是一致的(这在语言数据分布等自然数据中也很常见)。在下图中,作者展示了增加”标签多样性“对ICL的正向促进作用。
3.1.4 类内差异
第四组实验探索了动态语义变化的另外一种方式,即图像类内本身的差异。在差异性最低的情况下,每个图像类别仅包含一张图像,即给定类别的图像始终相同。在差异性中等的情况下,作者向每个类别中的图像添加了高斯像素噪声,相当于对样本进行重新采样。而在差异性较高的情况下,作者使用完整的Omniglot类别(其中每个类由20个不同的手写的20张不同的图像组成)。通过对这三种差异性进行ICL实验,作者发现更大的类内差异会导致更明显的ICL,如下图所示。
3.2 什么样的训练数据能使ICL和权重学习在同一个模型中共存?
从模型综合能力角度来看,ICL和权重学习都具有各自的优势,如果能够权衡二者,使一个模型同时拥有这两种能力,将会大大提升模型的竞争力。模型一方面可以牢牢记住在训练阶段出现的类别信息,另一方面在面对新类具有突变性的样本时,能够进行快速的ICL。这两种能力正是当下大型语言模型所期盼的。
那如何才能做到这一点?作者在对之前的所有实现进行分析,发现如果保持训练数据按照类别均匀分布,那权重学习始终得不到优化,因此作者推测,可能通过对训练分布进行一种有偏调整,就可以在同一个模型中实现两种类型的学习。在这种调整之下,数据集中的一些类别出现频率较高,而大多数类别出现频率会很低,这种分布也符合一些自然现象,例如单词的分布基本上也符合这种分布,这种形式也被定义为Zipfian(幂律)分布:
3.3 模型架构也非常重要
作者还强调,数据分布并不是促进ICL的唯一决定因素,对模型架构的选择也同样重要。作者使用递归神经网络系列进行了类似的实验,使用普通递归网络替换了Transformer,使用与之前实验相同的训练序列,使用相同的图像和文本编码器,并且进行了全面的超参数搜索。但遗憾的是,在这些实验中,作者发现递归模型根本无法实现ICL,如下图所示。其中图(a)是Transformer的结果,图(b)和图(c)分别为RNN和LSTM的结果。
四、总结
本文对ICL的发生机制进行了探索,与其他工作不同的是,作者以数据分布作为切入点进行研究,并且也获得了不小的理论发现。实验证明,数据中越是蕴藏着丰富的语义变化和差异,ICL进行的也越顺利。作者也进一步研究了ICL与传统权重学习之间的关系,同时提出了一种折中方案使模型能够同时具备这两种学习模式的优势。此外,作者强调了模型架构对ICL的决定性作用,基于Transformer的架构设计天然契合ICL的优化环境,这也是Transformer相比传统递归模型的优势体现。作者还考虑了发展ICL可以对社区产生更加广泛的影响,例如我们也可以从数据层面入手来设计和收集新领域的数据集,以求在语言理解以外的方向中也实现ICL,例如在图像领域也设计一个具备快速上下文学习能力的ICL视觉模型。
参考
[1] George Kingsley Zipf. Human Behavior and the Principle of Least Effort - Google Books, 1949.
[2] Brenden M. Lake, Ruslan Salakhutdinov, and Joshua B. Tenenbaum. The Omniglot Challenge: A 3-Year Progress Report. arXiv:1902.03477 [cs], February 2019. URL http://arxiv.org/abs/ 1902.03477. arXiv: 1902.03477.
[3] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is All you Need. page 11, 2017.
作者:seven_Illustration by IconScout Store from IconScout




![强化学习从基础到进阶-常见问题和面试必知必答[2]:马尔科夫决策、贝尔曼方程、动态规划、策略价值迭代](https://img-blog.csdnimg.cn/8f84b5eeda21460e9be56aa2aa3cb0c5.png#pic_center)