在 「一文讲透研发,SRE,运维,DevOps 的区别」里,我们讲了几大工种的区别,这篇我们重点讲一下 SRE (Site Reliability Engineering)。

SRE 的兴起
SRE 最早起源于 2003,由 Google 提出。SRE 既是一种理念,也是一套围绕这个理念的实践,由这个实践也诞生了一个新的工种,同样叫 SRE。SRE 的兴起有多方面的原因:
- 天时 - 互联网在线服务大规模普及。一边服务复杂度极具提升,一边稳定性的要求越来越高。
- 地利 - 由 Google 带头的一批头部科技公司背书,尤其是 2016 年 Google SRE 团队撰写的 Site Reliability Engineering: How Google Runs Production Systems 堪称行业里最经典的著作。
- 人和 - Ops 们需要找新的出路,因为云服务等基础设施的完善消灭了传统运维 (IT Ops) 的大量工作。
SRE 和 Dev 间的生产关系
关于 SRE 和 Dev 之间的关系,网上读到的一个精彩描述:

再具体一点,我们可以拿 DORA 的四大核心指标来看:
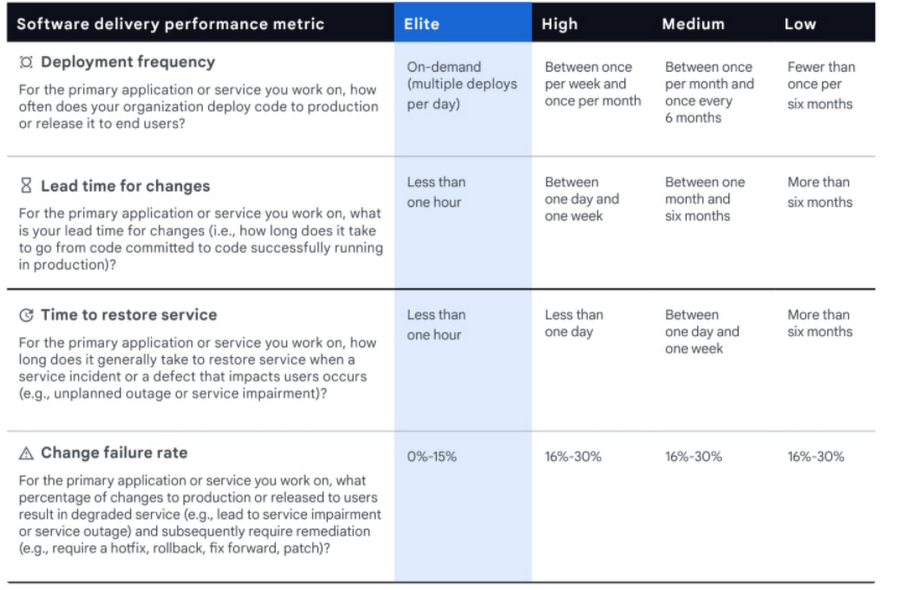
- Deployment frequency (部署频率)
- Lead Time for Changes (从代码提交到最终发布耗时)
- Change Failure Rate (发布失败率)
- Time to Restore Services (服务恢复时间)
前两个指标指向的是 Velocity (速度),后两个指向的是 Stability (稳定性)。Dev 的目标是优化迭代速度,而 SRE 的目标则是优化稳定性。DORA 报告里提到的精英团队能做到即快又稳,但这也是相对而言的。毕竟大家都知道,变更是造成生产故障的第一大根因,这也是为什么许多团队会定下周五不发布的规矩。每一个研发组织还是要在 Velocity 和 Stability 之间做权衡,这也自然导致负责 Velocity 的 Dev 和盯着 Stability 的 SRE 团队间发生摩擦。正好前不久 Google SRE 团队又发表了一篇文章 How Google SRE And Developers Collaborate 着重谈了这点:
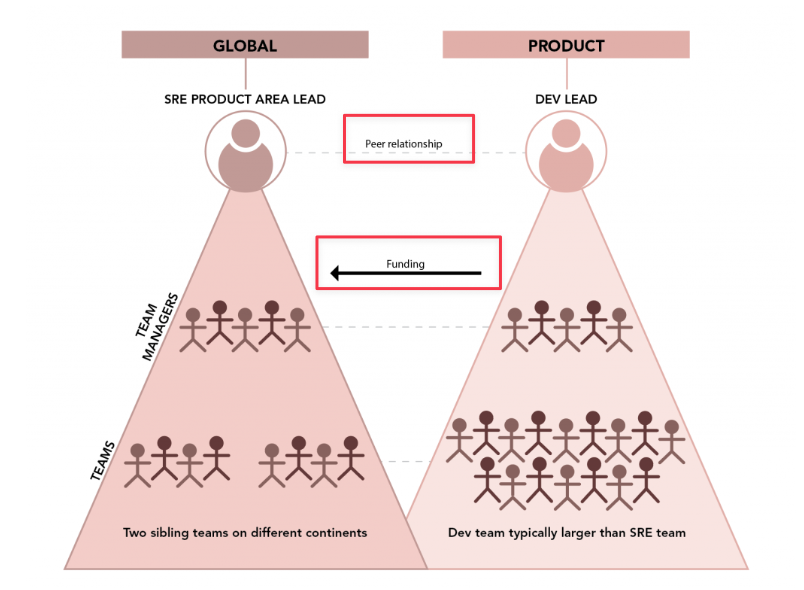
SRE 和 Dev 之间的生产关系,顶层是 Peer,执行层则是 Funding,SRE 的 HC 是由 Dev 团队提供的。具体几点:
- Funded by Dev
- Strategic Partnership
- Dev Ownership
- Joint Partnership
- Shared Endeavor
总体而言在 SRE 和 Dev 的关系里,Dev 还是占主导地位。在 Google 的组织架构里,虽然 SRE 是一条独立的汇报线,但 SRE 的日常工作是嵌入在 Dev 团队中的。那为什么不直接把 SRE 归并到 Dev 组织中,而要单独设一条线呢:
- 更好地制衡 Dev,Dev 无论是从自身还是因为产品经理的压力总是想着尽快上线功能,而忽视长期的服务稳定性和可运维性建设。把 SRE 独立出来可以起到更好的监督作用。
- SRE 组织里面也有两部分,一部分是嵌入在 Dev 团队中的,叫作业务 SRE,同时也有横向的 (在 Google 里叫 Horizontal) ,来制定整体的规范,提供通用的基础设施和工具。
- SRE 的工作内容和 Dev 还是有明显差别,比如负责稳定性就要随时应急,需要全球 7 x 24 覆盖。Google SRE 团队通常会分布在美国和欧洲,而许多 Dev 团队都只需要在一个时区。
其他公司也会采用不同于 Google 的组织架构,比如采用双线汇报,SRE 既汇报给 SRE 的负责人,同时又汇报给 Dev 负责人。有些公司的 SRE 会有自主 HC,并不需要 Dev 团队的资助。不同的架构取决于组织希望 SRE 和 Dev 走得有多近,过近达不到制衡的目的,而过远则会造成更多的协同摩擦。但两个部门的存在,摩擦是很难避免的。以下是一个常见的 Dev 和 SRE 关系发展时间线:
Dev: 运维压力太大,还要做业务需求,开发团队忙不过来了,看上周又出了个 P1 故障,还是找个 SRE 团队来帮忙吧。
SRE: 这些 xx 监控指标先加一下,我们看看现在服务的稳定性再说。
(过了一段时间)
Dev: 我们弄了一些,但业务压力太大了,我们实在不行了,你们赶紧来吧。
SRE: 好吧。
(又过了一段时间)
Dev: SRE 好像也只会接个告警,排查还是要我们上。还老是卡上线,每做一个功能,都要加这加那指标。本来上周的发布又被 SRE 叫停了。
SRE: Dev 开发功能都不测试,一上线各种问题,让我们半夜起来擦屁股,上周又出了一个 P1 故障,这个月 SLA 已经破线了,不能让 Dev 发布了。
(开始逐渐互相看不惯对方,要么将就相处,要么一拍两散)
即使是 SRE 届的标杆 Google,SRE 和 Dev 都发生过炒对方鱿鱼的事情。在 Google 内部,每当生产事故发生后,都会写 postmortem。有时 SRE 和 Dev 在分手的时候,也会以 postmortem 的方式写分手信,这总会引起大家的围观,因为每个人对于 SRE 和 Dev 间的相爱相杀都或多或少地感同身受吧。
SRE 的身份认同
由于 SRE 在组织架构中的模糊性,导致 SRE 团队的自身定位也一直是个问题。
首先,许多组织设立的 SRE 团队只是把原来的 Ops 团队换了一个高大上的名字,这显然会造成部门内外的认知困扰。
而在真正的 SRE 团队内部,业务 SRE 更多是参与到 Dev 团队的项目里。虽然不属于 Dev 团队,却又扮演着不讨好的看门人角色,以及负责压力更大的线上稳定性工作。横向 SRE 更多的时间则花在基础设施建设上,其所做的工作又基本和 Infra Dev 无异。前面提到的 Google SRE 文章里还提到 Meaningful Work:

Dev 通常更容易找到 Meaningful Work,因为用户感知到的功能主要由 Dev 来开发,SRE 则需要在 Dev 圈好的地之外再去发掘机会,难度更高。
SRE 们往往负重前行,但相比 Dev 们更缺少鲜花和掌声。优秀的 SRE 容易流失,毕竟一个具备研发能力的 SRE,可以转成 Dev。在 Google,从 SRE 转成 Dev 的数量是要远远多于 Dev 转成 SRE 的。
SRE 还被需要吗
来到标题里的疑问,首先 SRE 承担的职能还是会长期存在,但是只要 SRE 和 Dev 间的生产关系跳不出 Google 当初所设计的范畴,SRE 的发展就有局限性。我们总是听到 Dev 抱怨 SRE 只会接一个告警,问题最终还是要交给 Dev 来看。很大程度上这是组织设计的锅,因为 SRE 和 Dev 不是同一个团队,SRE 关注的 Stability 往往又站在 Dev 的 Velocity 对立面,而产品则还是由 Dev 团队 own。这也是为什么现在更多的团队选择纯 DevOps,只有 DevOps 一个工种,自己 Dev 自己 Ops,这样没有协同的损耗,从激励机制上也是更合理的。
当年互联网大潮开启,从单机应用走向互联网服务。快速迭代,海量并发,时刻在线,这些互联网业务独有的特性对于服务的稳定性带来了巨大挑战。那时 Dev 忙着上线业务,Ops 又希望转型,而行业又缺少体系化的手段来解决稳定性问题,SRE 的出现恰好补了位。经过这些年的打磨,解决服务稳定性的方法论和最佳实践已经成型,云基础设施保证了底层的稳定性,各种 SaaS 服务,开源产品也大大降低了 Dev 自己做 Ops 的门槛,这个时候 SRE 团队和 Dev 团队之间的组织摩擦就逐渐上升为了主要矛盾。过去 20 多年,行业从没有 SRE,到拥抱 SRE,再到去 SRE:
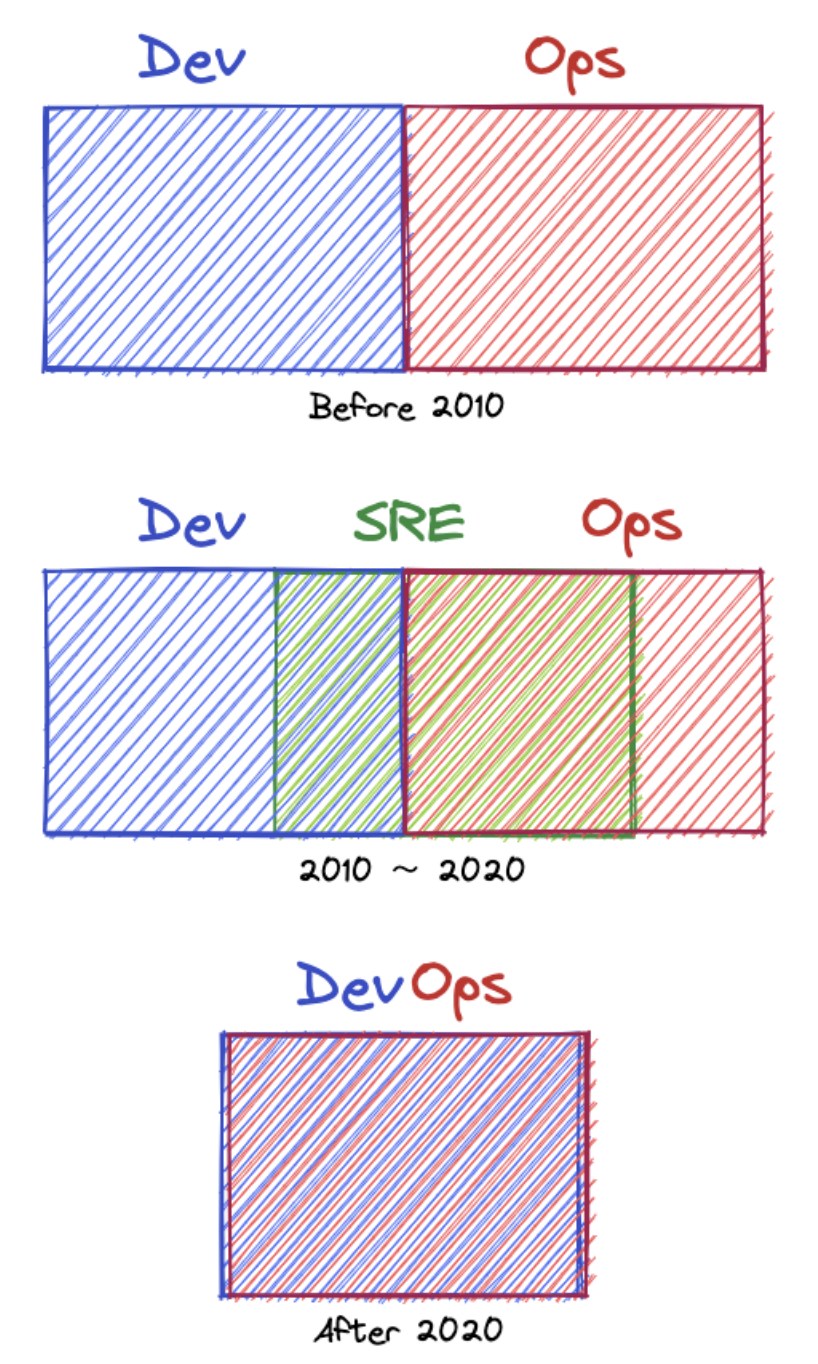
这个过程和中台演进也颇为相似,前些年是建中台,这两年开始去中台,SRE 就类似提供系统稳定性的中台职能。去掉 SRE,并不是放弃稳定性,而是看到 DevOps 本身可以在保障系统相对稳定的情况下更快地进行业务迭代。当靠 DevOps 团队也能做到 99.9% 的 SLA (Service Level Agreement) 时,许多团队便不会再引入 SRE ,以牺牲迭代速度的代价换取提升 SLA 到 99.99%。
SRE 留下的财富
即使将来 SRE 风光不再,但整个 SRE 周期也留下了一堆的财富。
首先 Google 想出了 SRE 这个好名字,Site 代表规模,Reliability 代表稳定性,Engineering 代表工程,正好描述了 SRE 是用工程的方法来解决规模化后的稳定性问题。
因为 SRE 而诞生的 SLI (Service Level Indicator), SLO (Service Level Objective), SLA (Service Level Agreement) 定义了稳定性工作的北极星指标;Blameless, Postmortem 的文化也是经过 SRE 和 Dev 的不断磨合成为了业界共识;Logs, metrics and traces 三大件,Chaos Engineering 这些也都是由 SRE 推动成为了最佳实践,在此之上也建立起了 Datadog, Elastic 这样的商业帝国。
其次 SRE 帮助传统 Ops 完成了转型,如果没有 SRE 作为过渡,Ops 很难直接转型为 Dev,是 SRE 让 Dev 和 Ops 可以 meet in the middle。而经过 10 多年的 battle,SRE 最终燃烧了自己,融化了 Dev,再一起合体成了 DevOps。
船停在码头是最安全的,但那不是建造他的目的。告别 SRE,也告别 Dev,直接挂上 DevOps 的旗子,不用再争论今天是否可以出海,这实在是太好了。
Ship it

💡 你可以访问官网,免费注册云账号,立即体验 Bytebase。