Producer源码解读
在 Kafka 中, 我们把产生消息的一方称为 Producer 即 生产者, 它是 Kafka 的核心组件之一, 也是消息的来源所在。它的主要功能是将客户端的请求打包封装发送到 kafka 集群的某个 Topic 的某个分区上。那么这些生产者产生的消息是怎么传到 Kafka 服务端的呢?
Producer之整体流程
我们回顾一下之前我们讲过Kafka一条消息发送和消费的流程
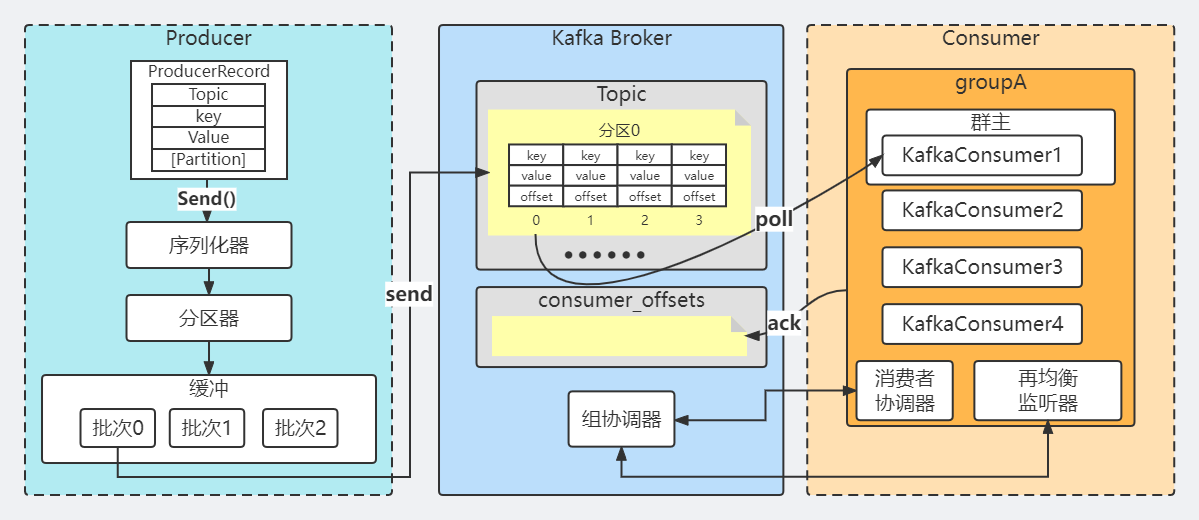
但是站在源码的核心角度,我们可以把Producer分成以下几个核心部分:
1、Producer之初始化
2、Producer之发送流程
3、Producer之缓冲区
4、Producer之参数与调优
Producer源码解读
从生产流程可以知道,Producer里面的核心有序列化器,分区器,还有缓冲,所以初始化的流程肯定是围绕这几个核心来处理。
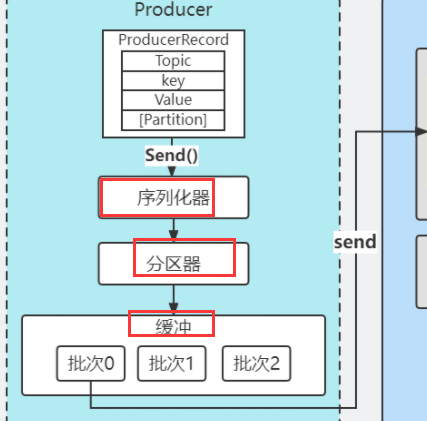
KafkaProducer之初始化
因为源码中有非常多的一些额外处理,所以我们解读源码没必要每行都读,只需要根据我们之前梳理的主流程找到核心代码进行解读就可以,这也是推荐大家去初次解读源码的最优方式。
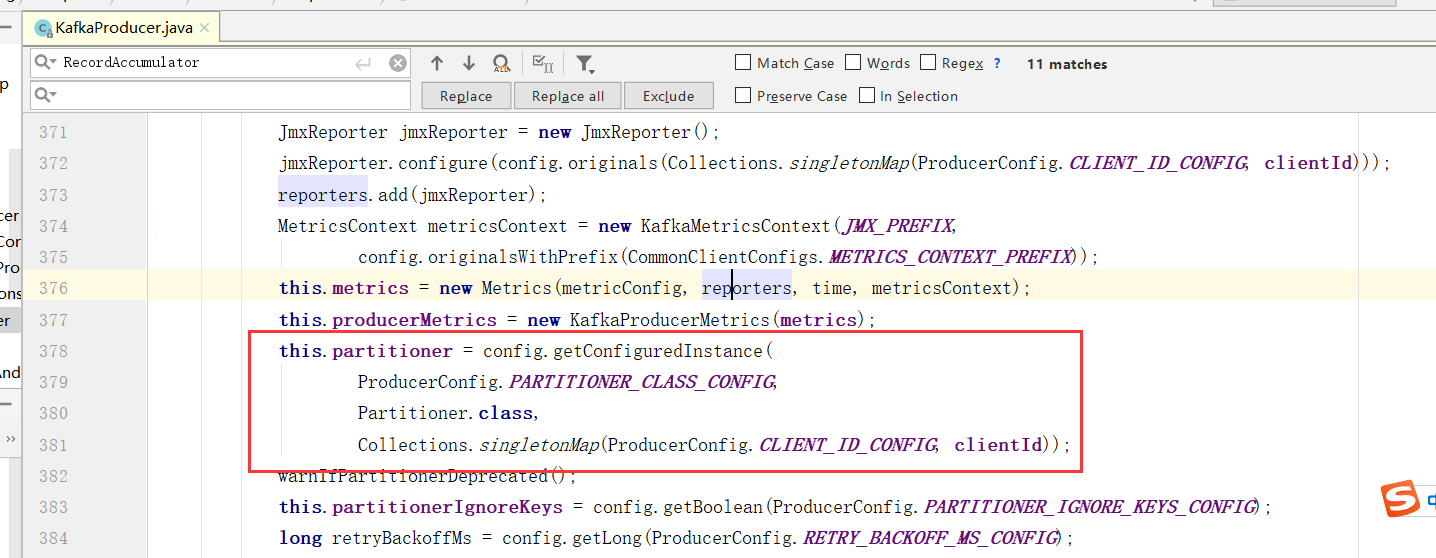
1)、设置分区器
设置分区器(partitioner),分区器是支持自定义的
2)、设置重试时间
设置重试时间(retryBackoffMs)默认100ms
如果发送消息到broker时抛出异常,且是允许重试的异常,那么就会最大重试retries参数指定的次数,同时retryBackoffMs是重试的间隔。
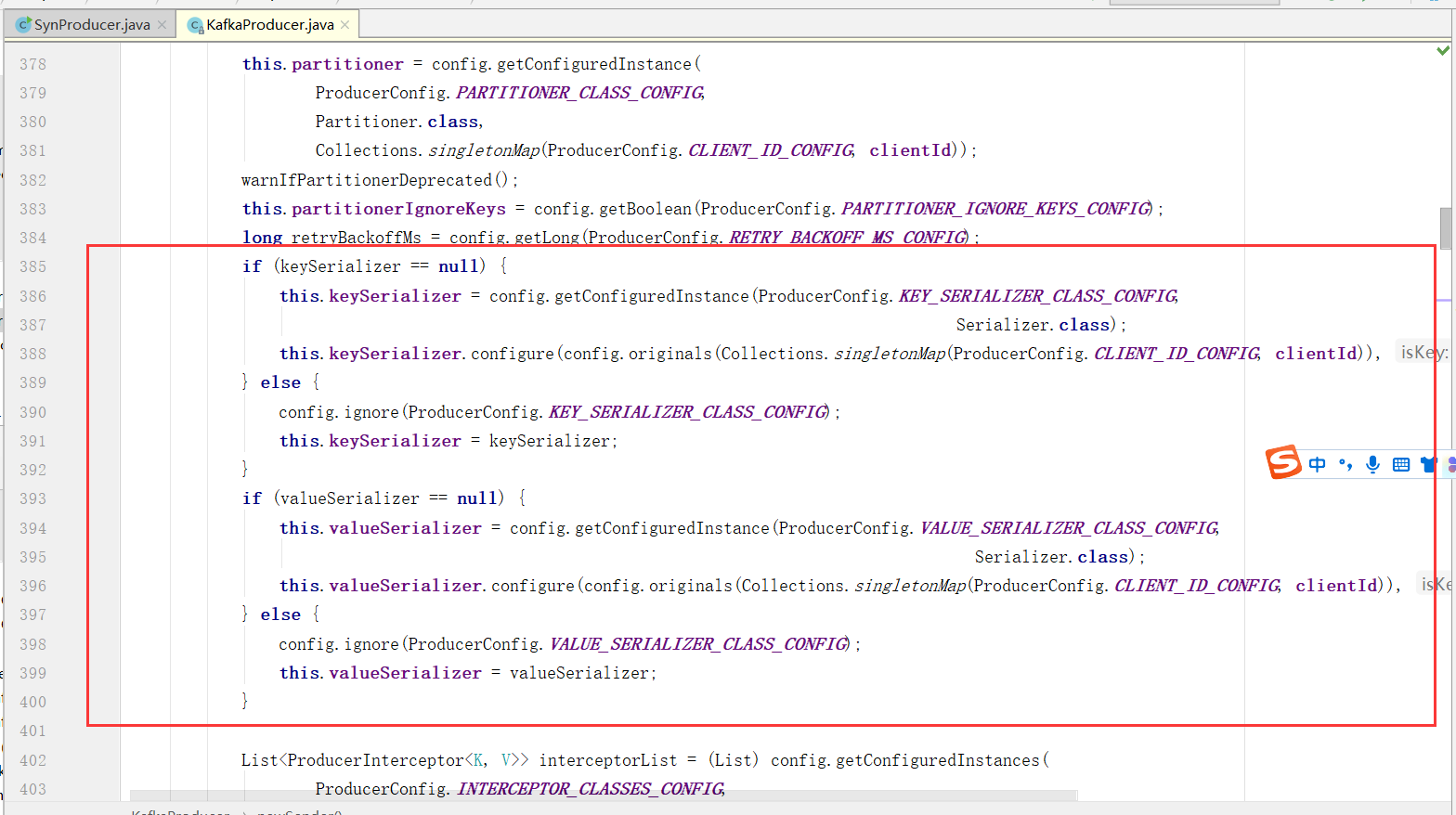
3)、设置序列化器
设置序列化器(Serializer)
4)、设置拦截器
设置拦截器(interceptors),关于拦截器,这个后面会有讲解和介绍。

5)、设置缓冲区
在之前,还有一些参数的设置。
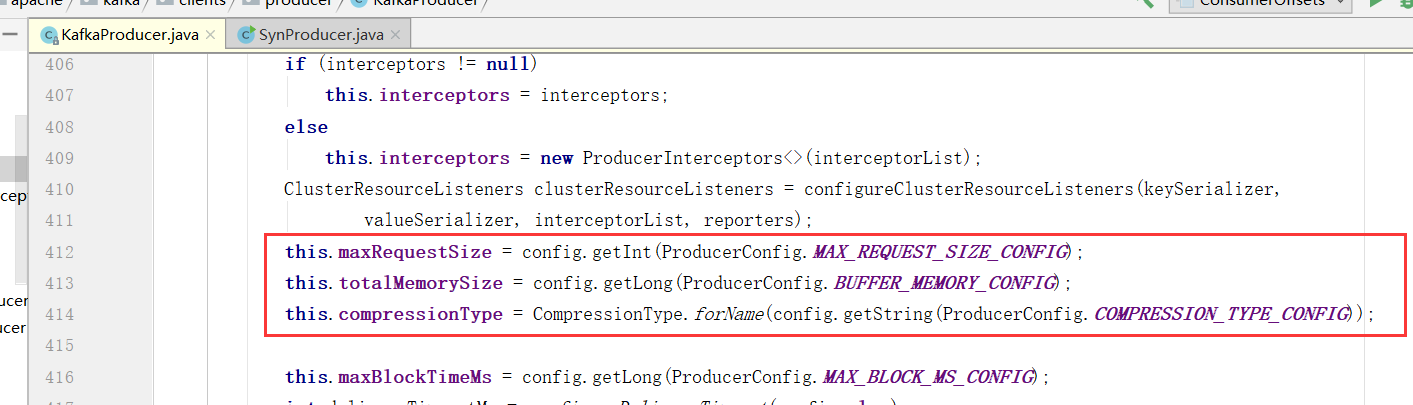
1、设置最大的消息为多大(maxRequestSize), 默认最大1M, 生产环境可以提高到10M
2、设置缓存大小(totalMemorySize) 默认是32M
3、设置压缩格式(compressionType)
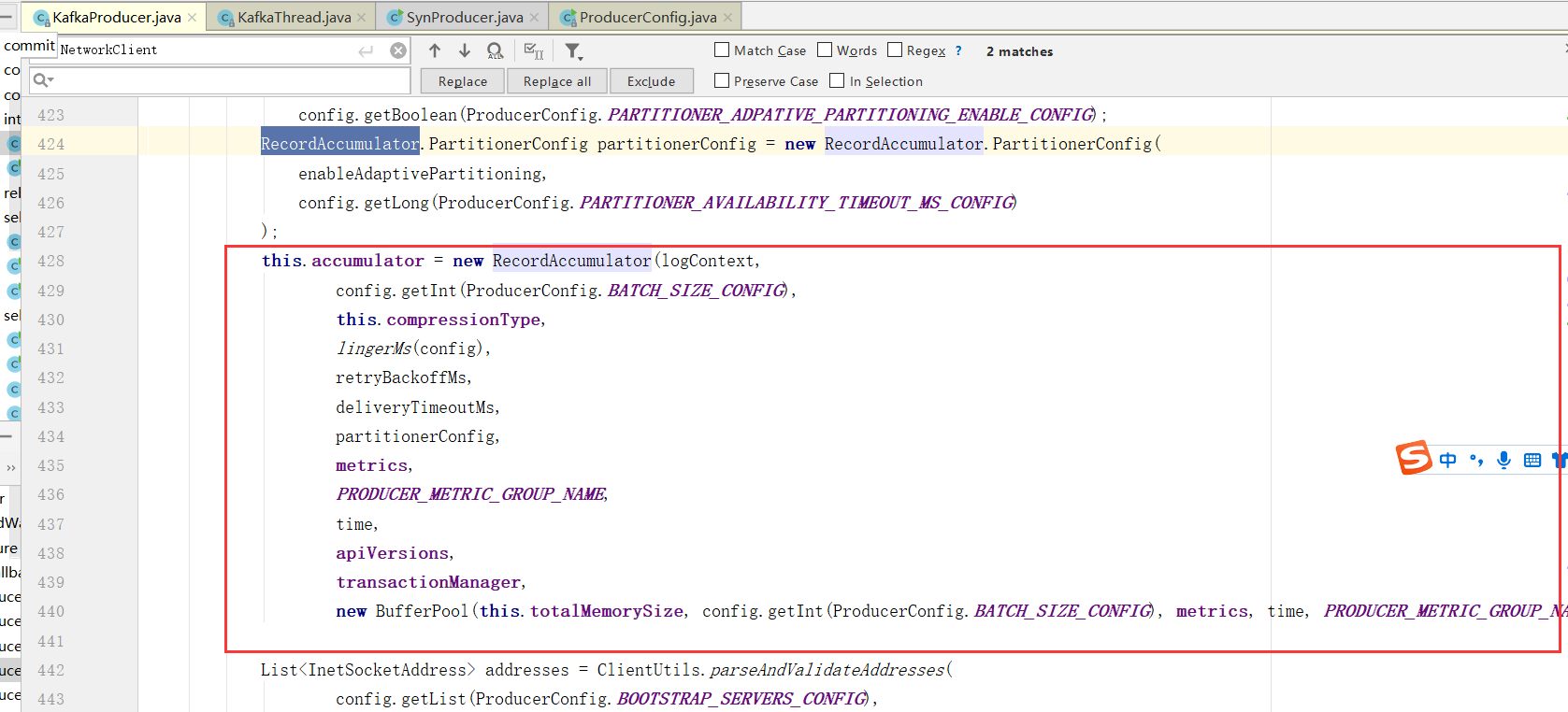
4、初始化RecordAccumulator也就是缓冲区指定为32M
6)、设置消息累加器
因为生产者是通过缓冲的方式发送,发送的条件之前的课程讲过,所以这里需要一个消息累加器配合才能完成消息的发送。
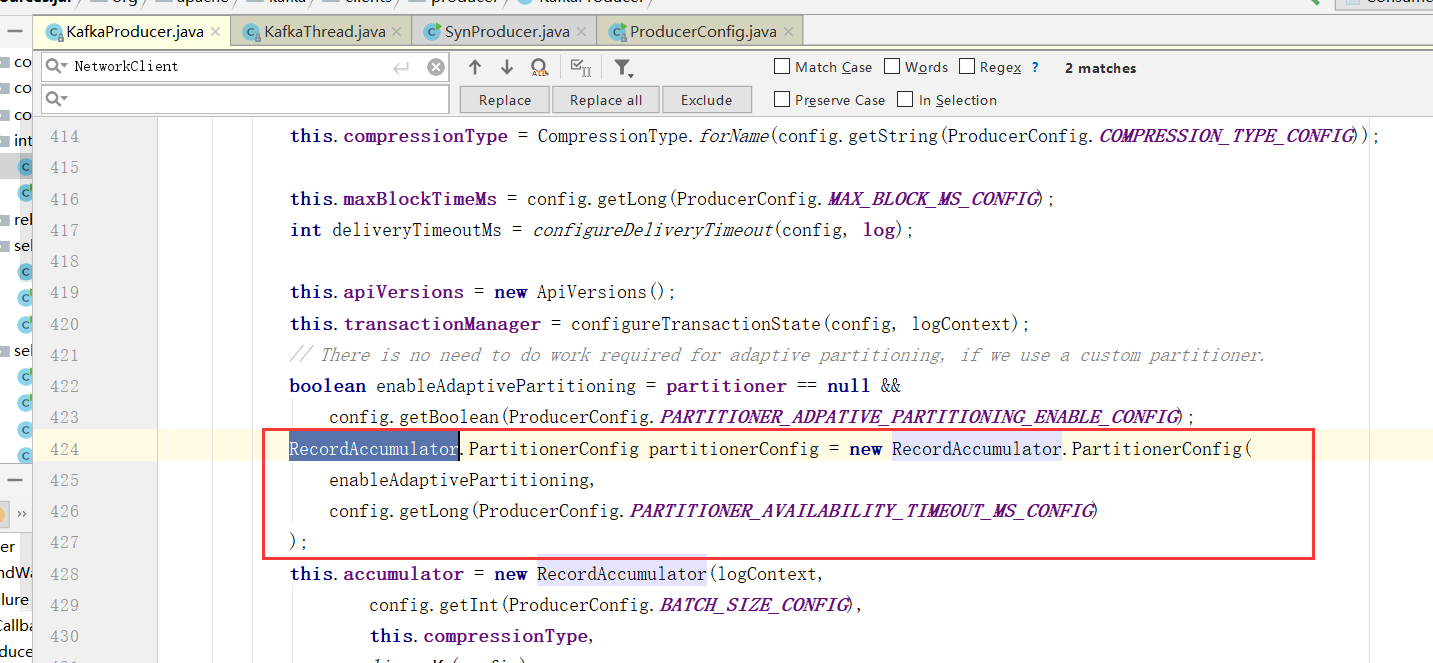
5、初始化集群元数据(metadata),刚开始空的
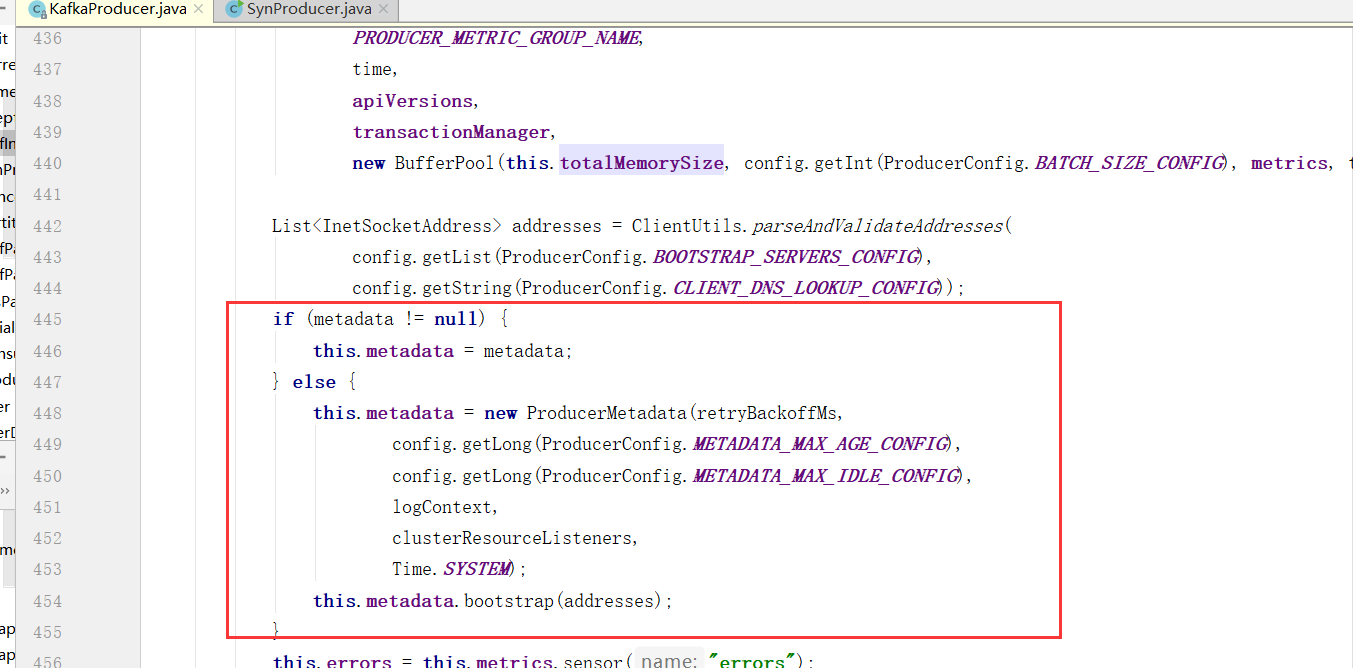
6)、创建Sender线程
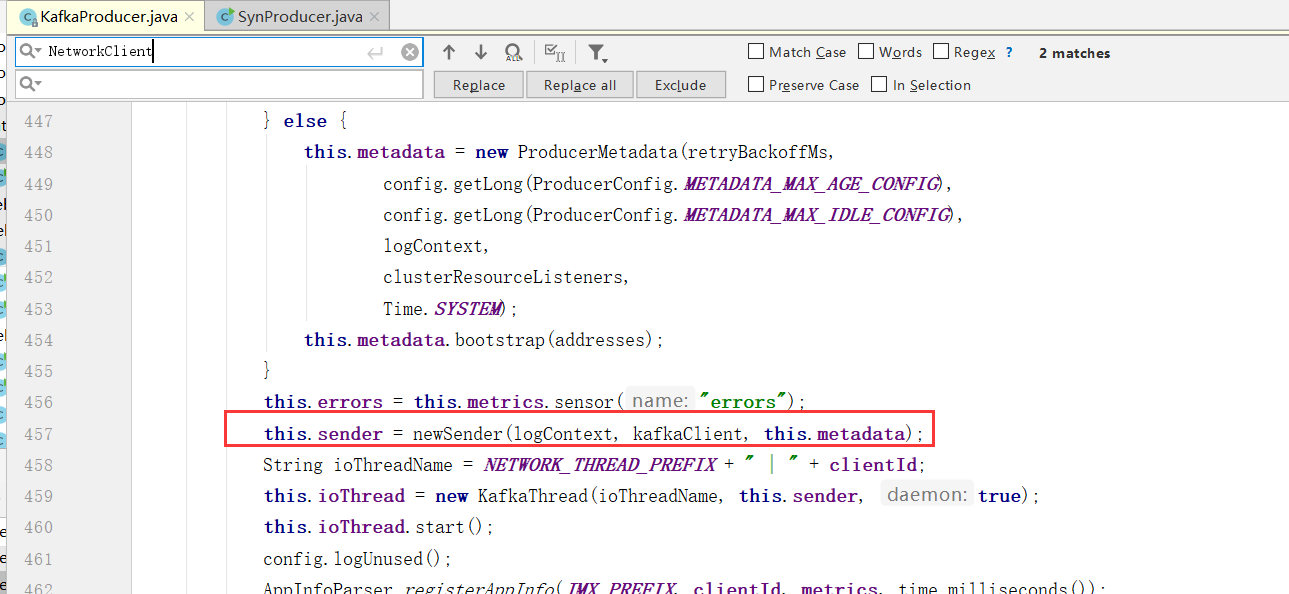
这里还初始化了一个重要的管理网路的组件 NetworkClient
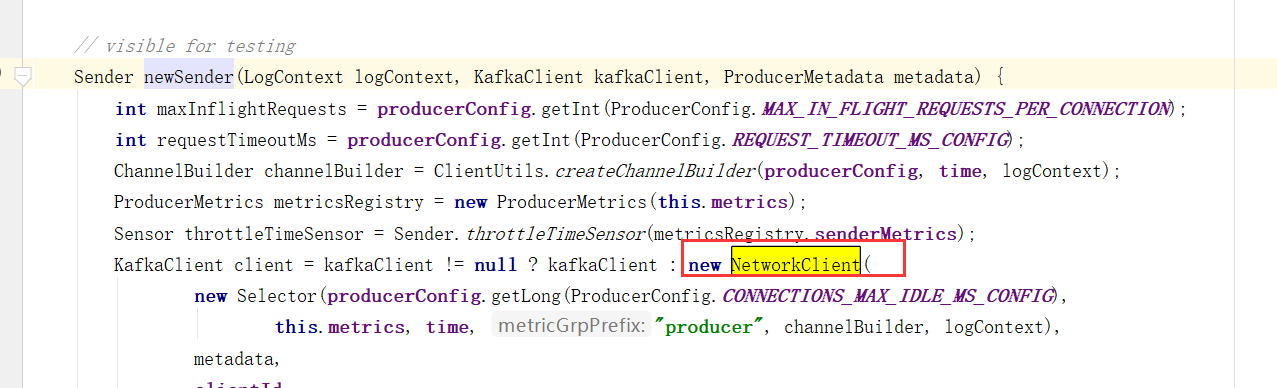
KafkaThread将Sender设置为守护线程并启动
拦截器使用及介绍
这里讲一讲拦截器的使用和基本作用,拦截器一般用得不多,所以这里只是讲一讲案例,不推荐生产中使用。
想要实现拦截器,我们需要先实现ProducerInterceptor接口即可,然后在生产者中设置进去即可。
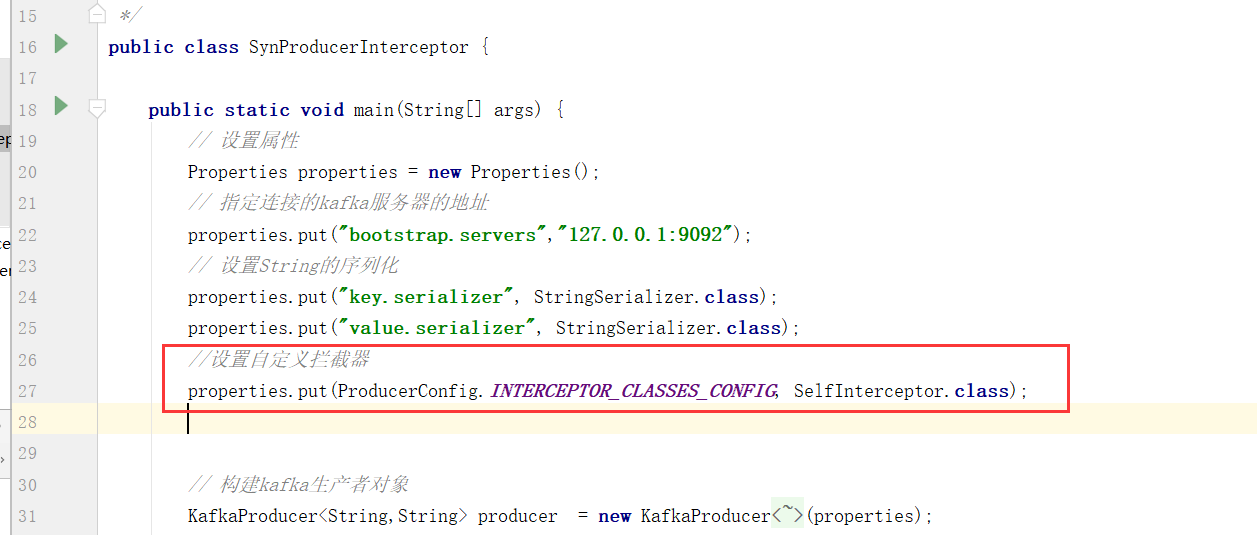
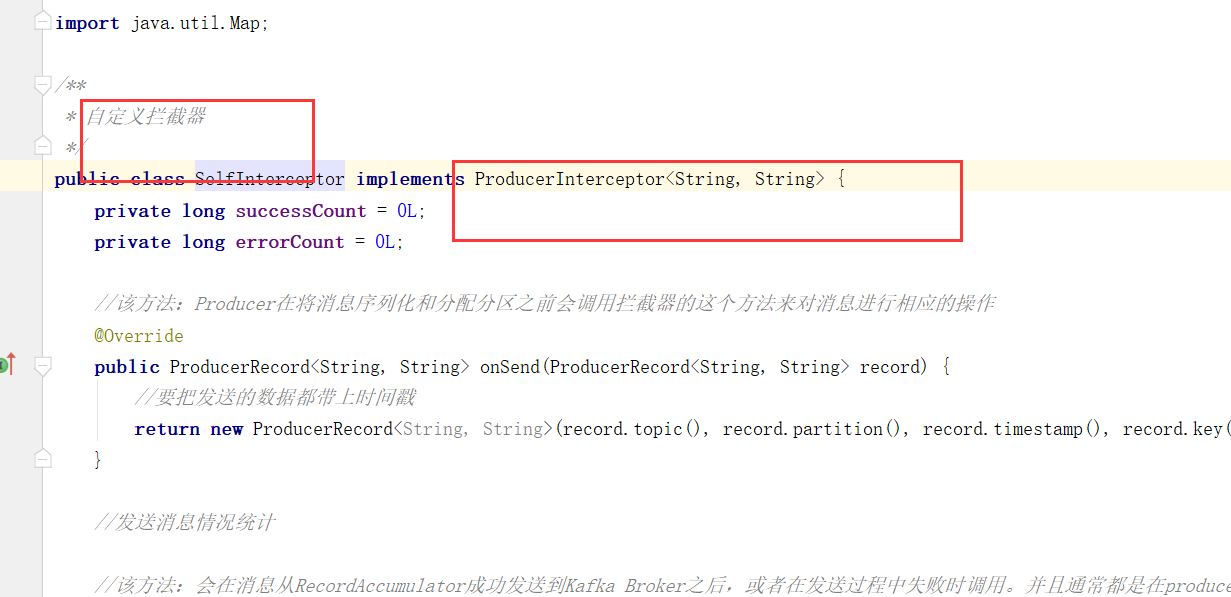
1、想要把发送的数据都带上时间戳
2、实现统计发送消息的成功次数和失败次数
在 onAcknowledgement(RecordMetadata, Exception)里面,根据消息发送后返回的异常信息来判断是否发送成功。一般异常如果为空就说明发送成功了,反之就说明发送失败了。
然后定义两个变量,并根据Exception的值分别累加就可以统计到了
最后在close方法里输出两个变量的值,这样当producer发送数据结束并close后,会自动调用拦截器的close方法来输出咱们想要统计的成功和失败次数


不过这里要注意一个点:
onAcknowledgement运行在producer的IO线程中,因此不要在该方法中放入很复杂的逻辑,否则会拖慢producer的消息发送效率。
3、拦截链路
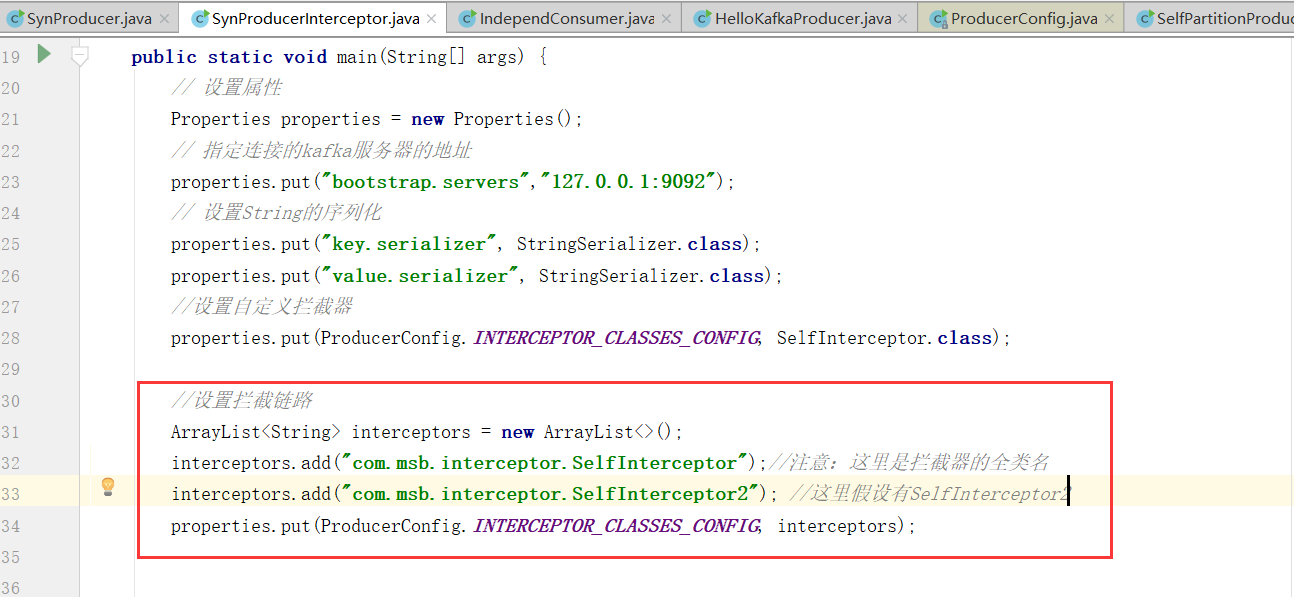
拦截器链里的拦截器是按照顺序组成的,因此我们要注意前后拦截器对彼此的影响,比如这里拦截器1的onsend方法不能返回null,不然拦截器2的onsend就丢失了信息,会发生异常。
Producer之发送流程
Producer之发送流程
Kafka Producer 发送消息流程如下:
1)、执行拦截器逻辑
执行拦截器逻辑,预处理消息, 封装 Producer Record
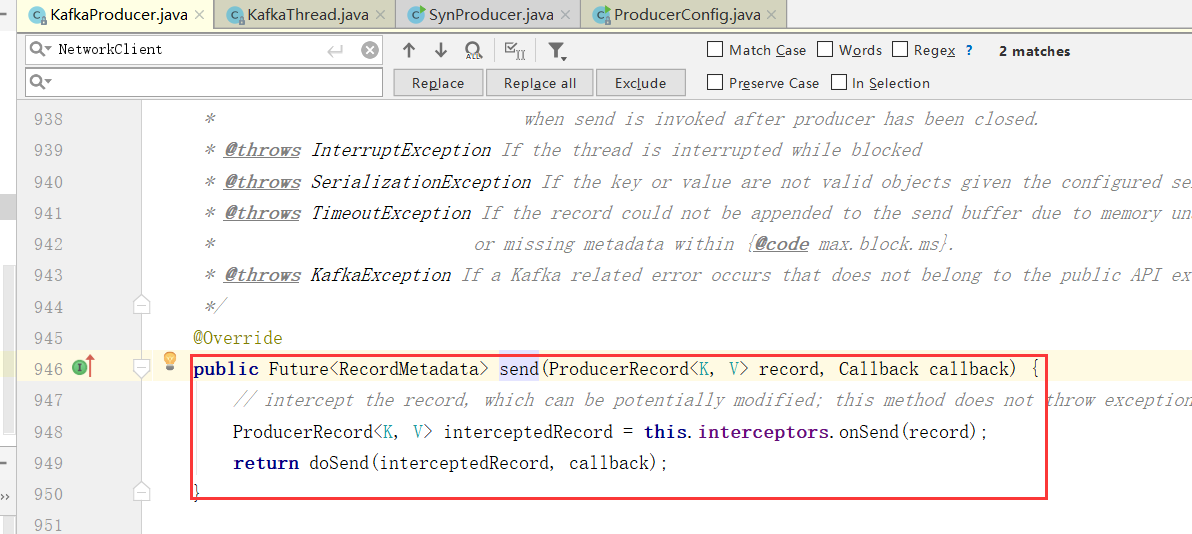
2)、集群元数据
从 Kafka Broker 集群获取集群元数据metadata
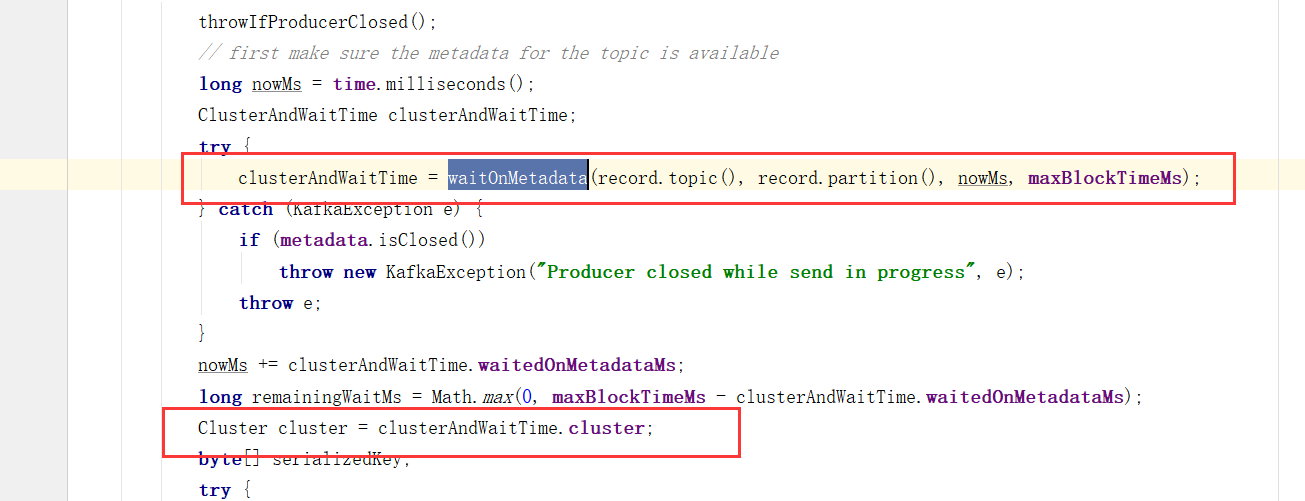
3)、序列化
调用Serializer.serialize()方法进行消息的key/value序列化
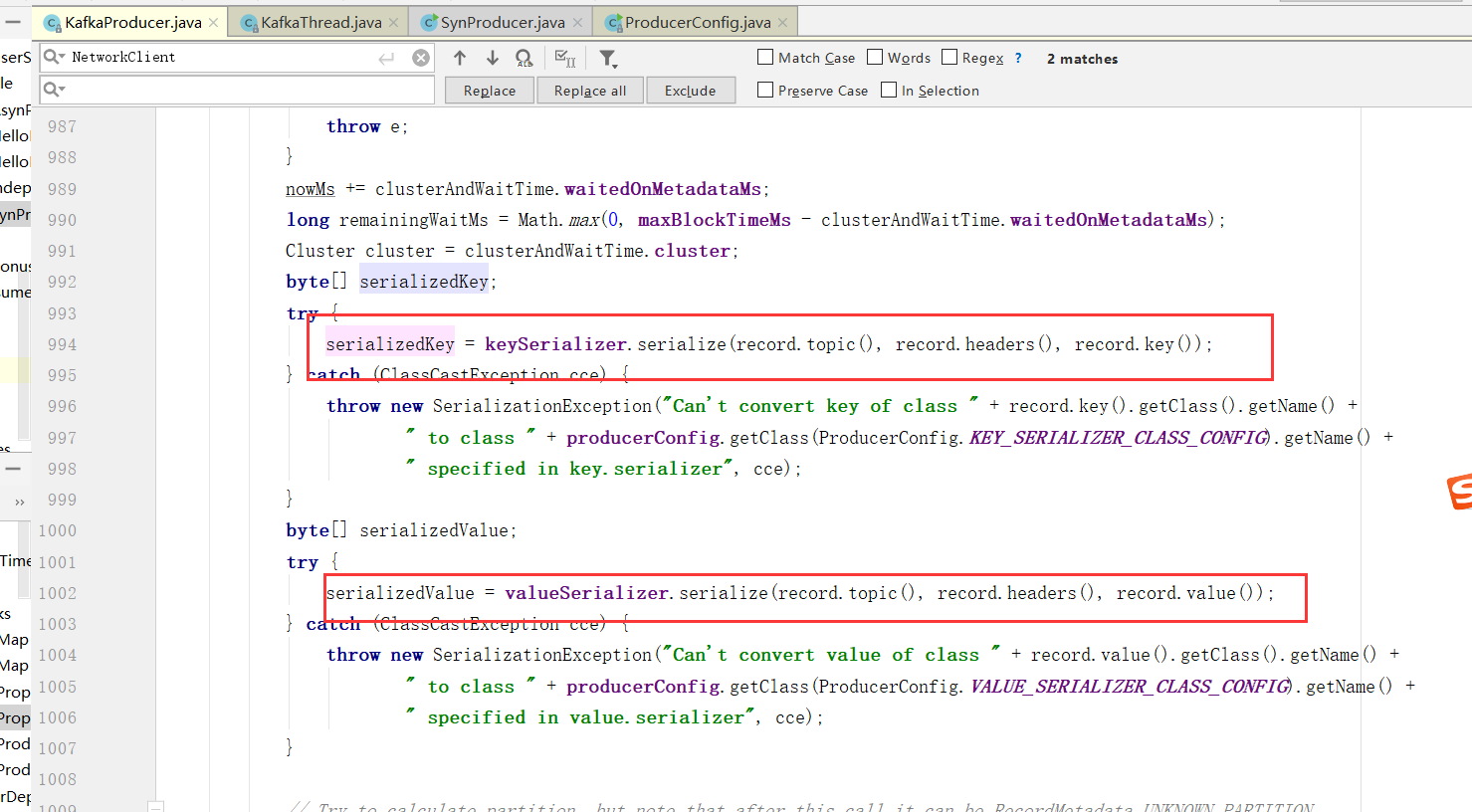
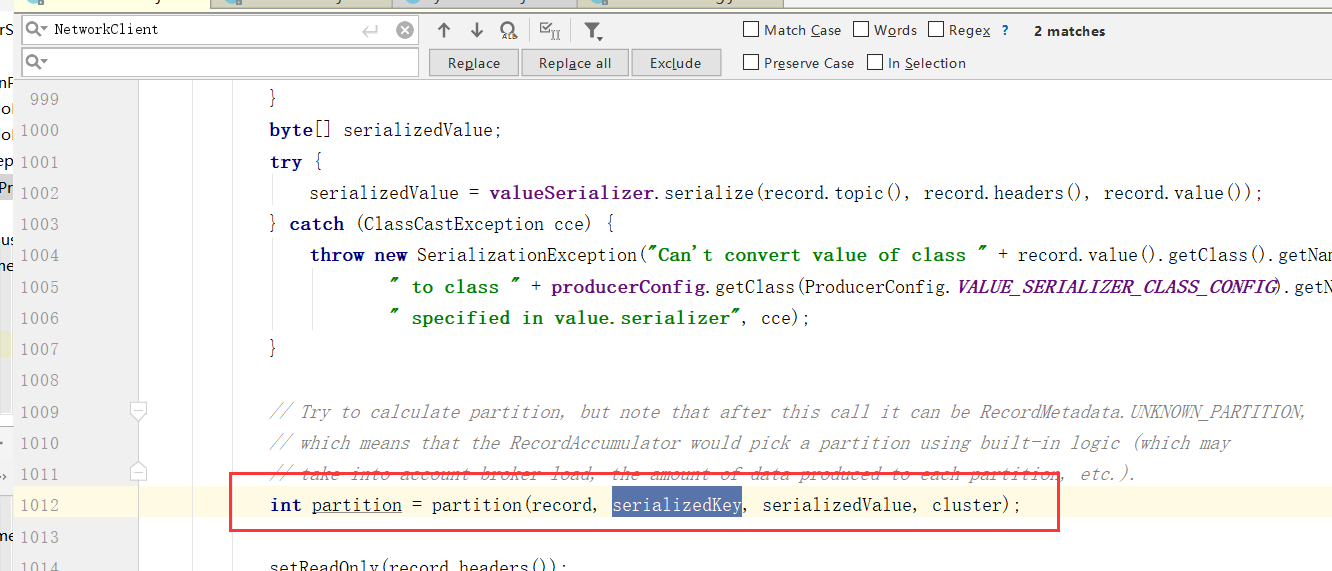
4)、分区
调用partition()选择合适的分区策略,给消息体 Producer Record 分配要发送的 topic 分区号
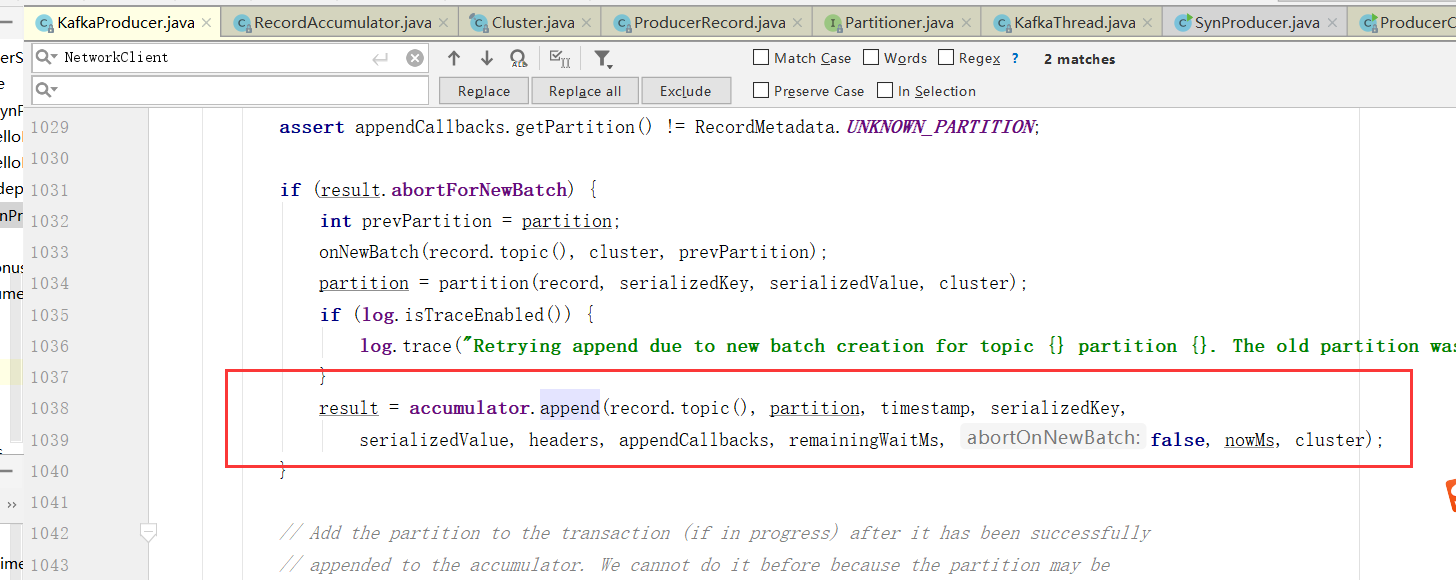
5)、消息累加进缓存
将消息缓存到RecordAccumulator 收集器中, 最后判断是否要发送。
7)、消息发送
前面我们也知道真正的消息发送是Sender线程来做,并且这里还要结合缓冲区来处理。后面会对这个进行详细的讲解,这里我们只需要知道发送的条件:
批次发送的条件为:缓冲区数据大小达到 batch.size 或者 linger.ms 达到上限,哪个先达到就算哪个
Producer之缓冲区
Kafka生产者的缓冲区,也就是内存池,可以将其类比为连接池(DB, Redis),主要是避免不必要的创建连接的开销, 这样内存池可以对 RecordBatch 做到反复利用, 防止引起Full GC问题。那我们看看 Kafka 内存池是怎么设计的。
核心就是这段代码:
Kafka 内存设计有两部分,下面的粉色的是可用的内存(未分配的内存,初始的时候是 32M),上面紫色的是已经被分配了的内存,每个小 Batch 是 16K,然后这一个个的 Batch 就可以被反复利用,不需要每次都申请内存, 两部分加起来是 32M。
申请内存的过程
从 Producer 发送流程的第6步中可以看到会把消息放入 accumulator中, 即调用 accumulator.append() 追加, 然后把消息封装成一个个Batch 进行发送, 然后去申请内存(free.allocate())
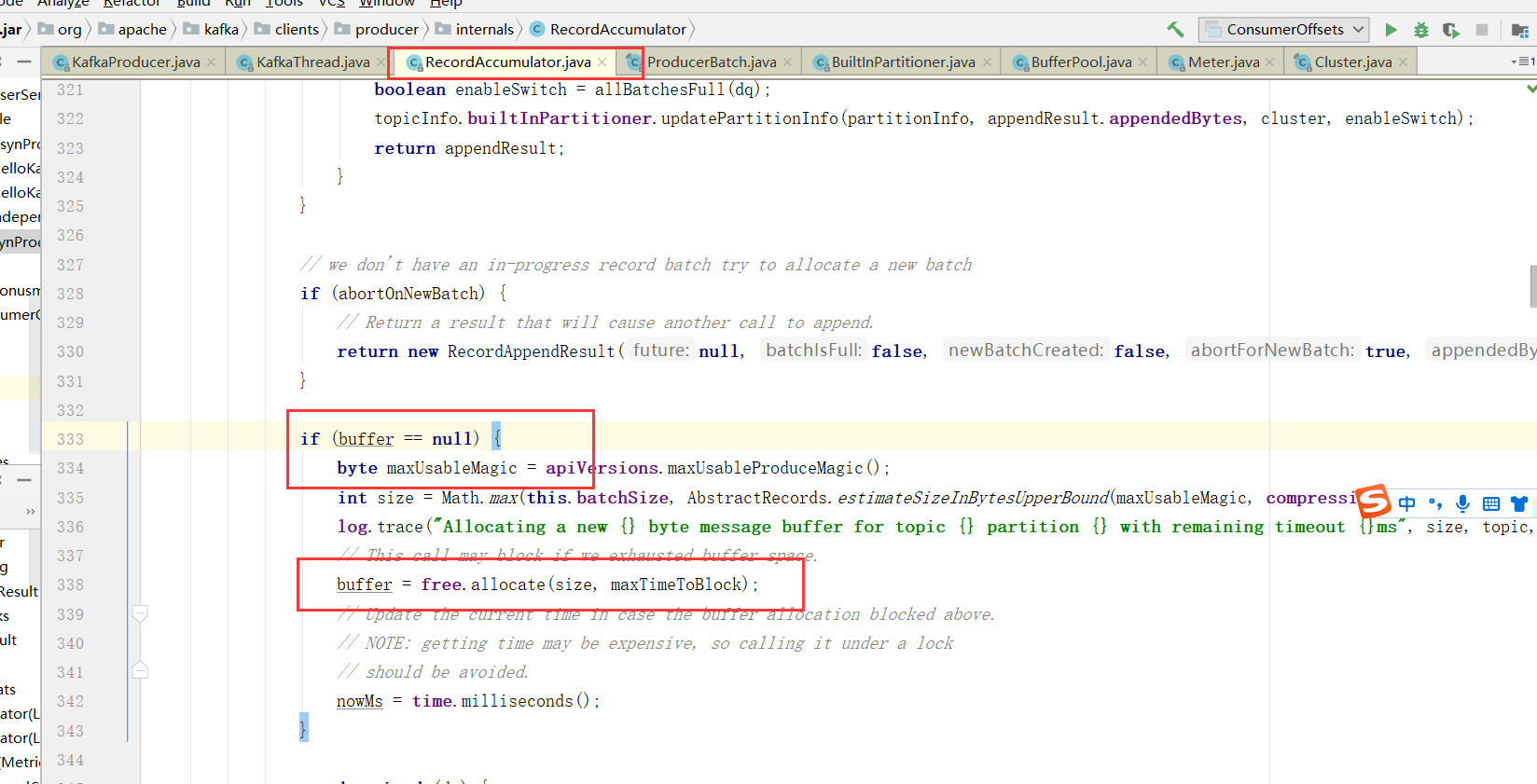
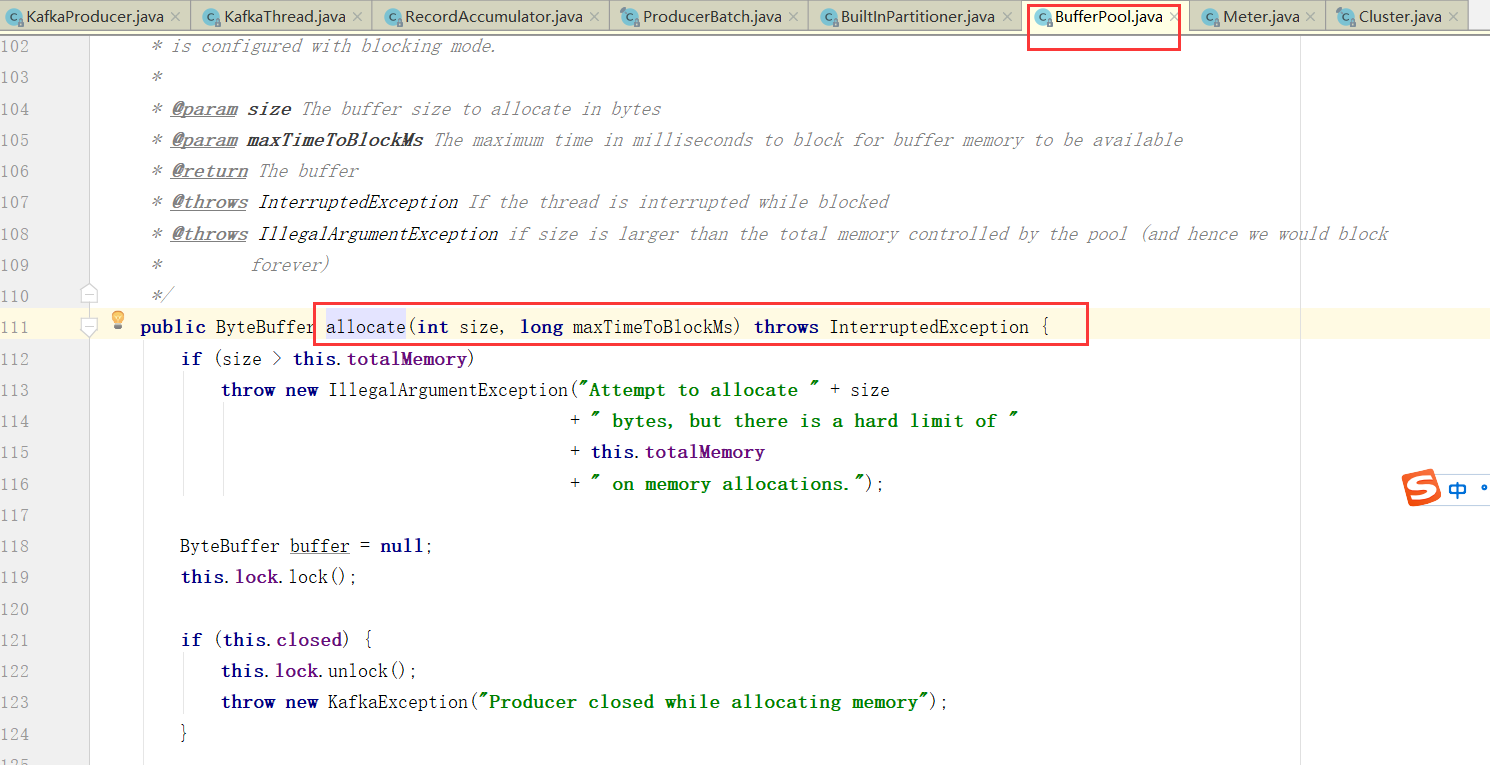
(1)如果申请的内存大小超过了整个缓存池的大小,则抛异常出来
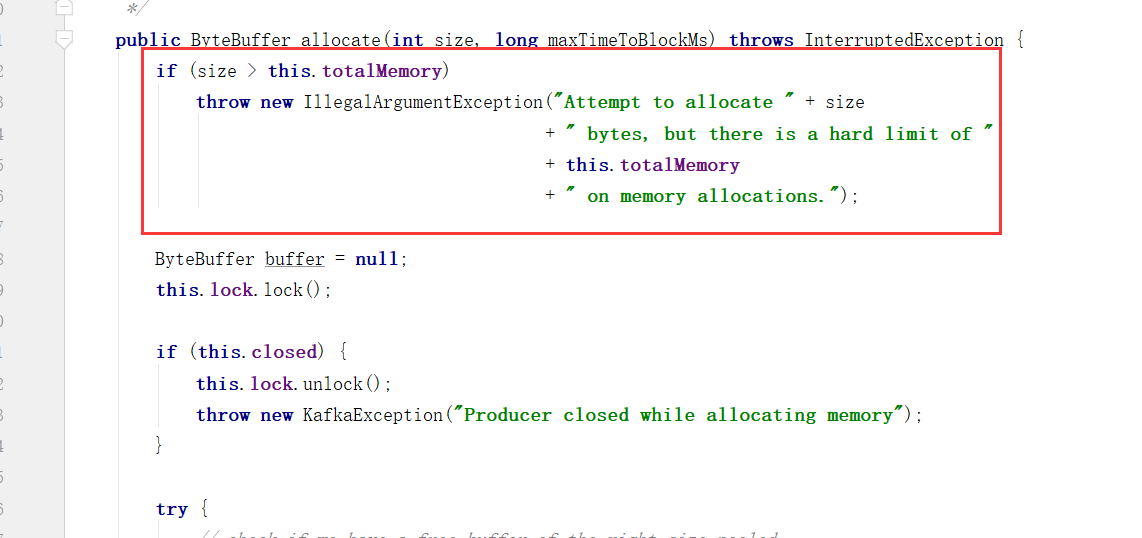
(2)对整个方法加锁:
this.lock.lock();
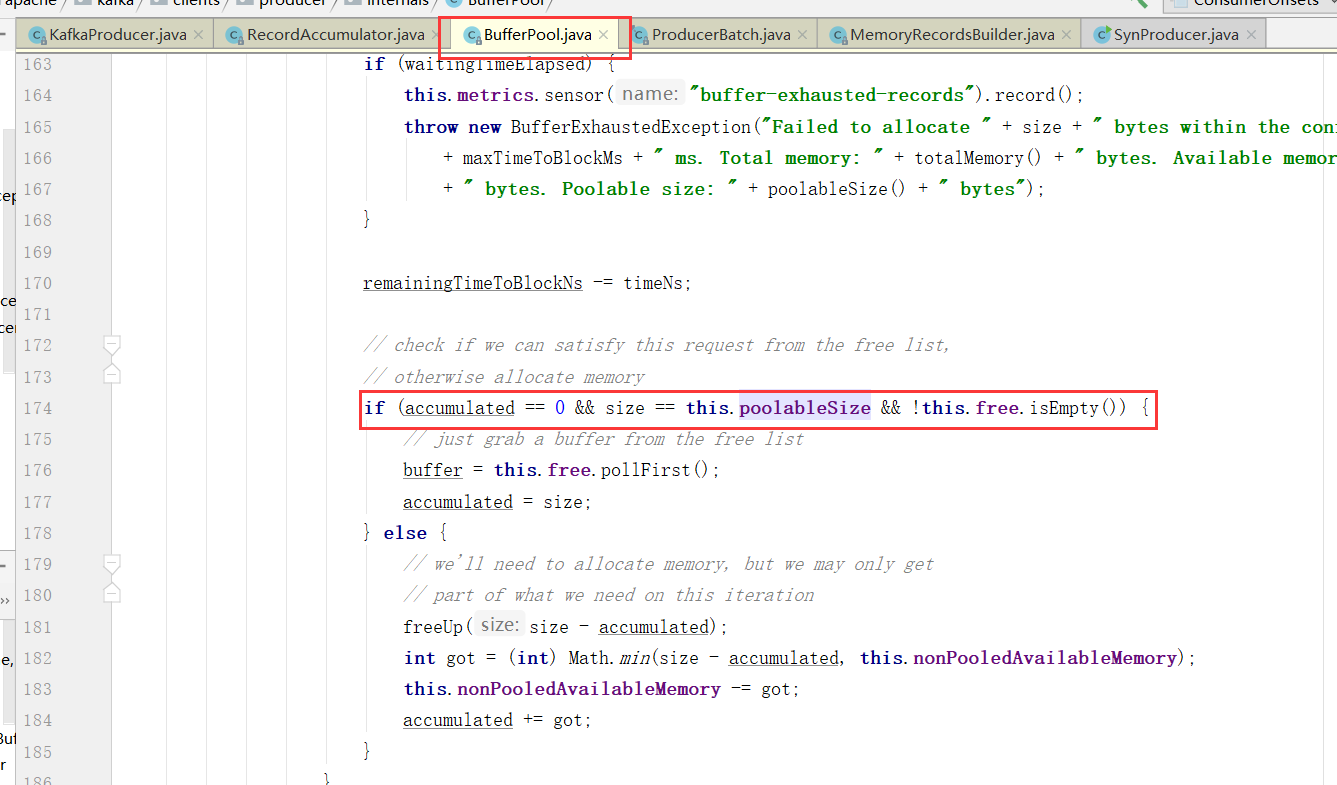
(3)如果申请的大小是每个 recordBatch 的大小(16K),并且已分配内存不为空,则直接取出来一个返回。
if (size == poolableSize && !this.free.isEmpty())
return this.free.pollFirst();
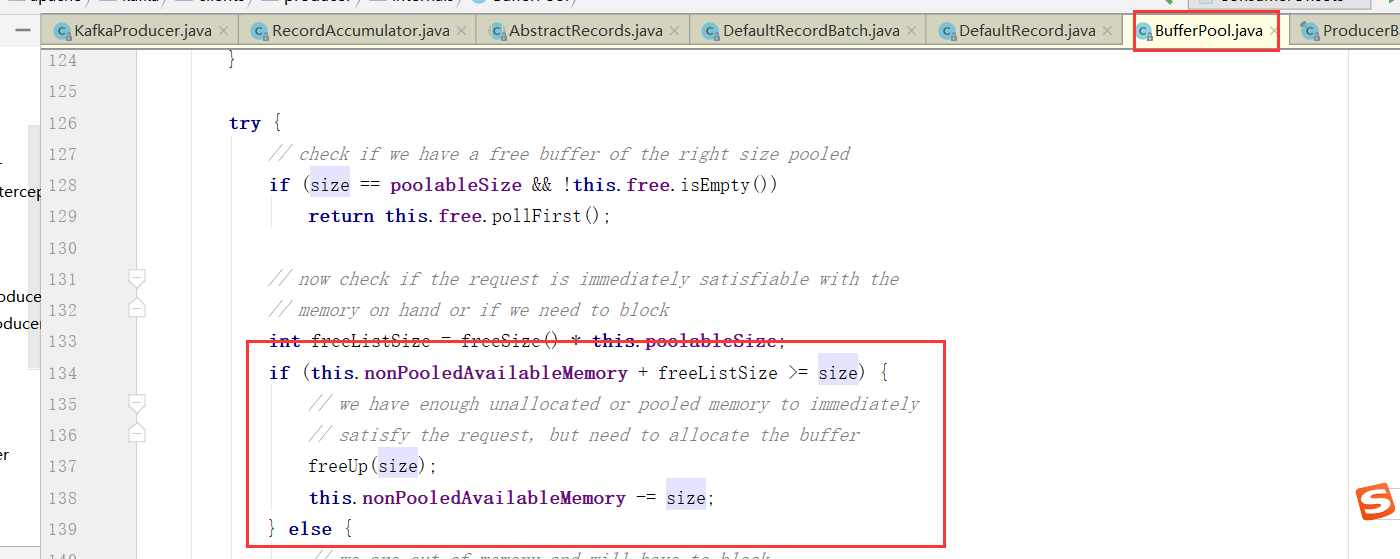
(4)如果整个内存池大小比要申请的内存大小大 (this.availableMemory + freeListSize >= size),则直接从可用内存(即上图粉色的区域)申请一块内存。并且可用内存要去掉申请的那一块内存。
Sender线程
Producer之参数调优
我们知道在 Kafka 实际使用中,Producer 端既要保证吞吐量,又要确保无消息丢失,一些核心参数的配置就显得至关重要。接下来我们就来看看生产端都有哪些重要的参数,及调优建议。
acks
参数说明:对于 Kafka Producer 来说是一个非常重要的参数,它表示指定分区中成功写入消息的副本数量,是 Kafka 生产端消息的持久性的保证, 详细可以查看
max.request.size
参数说明:这个参数对于 Kafka Producer 也比较重要, 表示生产端能够发送的最大消息大小,默认值为1048576(1M) 。
调优建议:这个配置对于生产环境来说有点小, **为了避免因消息过大导致发送失败,生产环境建议适当调大,比如可以调到10485760(10M)** 。
retries
参数说明:表示生产端消息发送失败时的重试次数,默认值为0,即不重试。 这个参数一般是为了解决因系统瞬时故障导致的消息发送失败,比如网络抖动、Leader 选举及重选举,其中瞬时的 Leader 重选举是比较常见的。因此这个参数的设置对于 Kafka Producer 就显得非常重要 。
调优建议:这里建议设置为一个大于0的值,比如3次。
retry.backoff.ms
参数说明:**设定两次重试之间的时间间隔,避免无效的频繁重试,默认值为100, ****主要跟 retries 配合使用, **在配置 retries 和 retry.backoff.ms 之前,最好先估算一下可能的异常恢复时间,需要设定总的重试时间要大于异常恢复时间,避免生产者过早的放弃重试。
connections.max.idele.ms
参数说明:主要用来判断多久之后关闭空闲的链接,默认值540000(ms)即9分钟。
compression.type
参数说明: 该参数表示生产端是否要对消息进行压缩,默认值为不压缩(none)。 压缩可以显著减少网络IO传输、磁盘IO以及磁盘空间,从而提升整体吞吐量,但也是以牺牲CPU开销为代价的。
调优建议:出于提升吞吐量的考虑,建议在生产端对消息进行压缩。**对于Kafka来说,综合考虑吞吐量与压缩比,建议选择lz4压缩。如果追求最高的压缩比则推荐zstd压缩。**
buffer.memory
参数说明: 该参数表示生产端消息缓冲池或缓冲区的大小,默认值为即33554432(32M) 。这个参数基本可以认为是 Producer 程序所使用的内存大小。
调优建议:通常我们应尽量保证生产端整体吞吐量,建议适当调大该参数,也意味着生产客户端会占用更多的内存。
batch.size
参数说明: 该参数表示发送到缓冲区中的消息会被封装成一个一个的Batch,分批次的发送到 Broker 端,默认值为16KB。 因此减小 batch 大小有利于降低消息延时,增加 batch 大小有利于提升吞吐量。
调优建议:通常合理调大该参数值,能够显著提升生产端吞吐量,比如可以调整到32KB,调大也意味着消息会有相对较大的延时。
linger.ms
参数说明: 该参数表示用来控制 Batch 最大的空闲时间,超过该时间的 Batch 也会自动被发送到 Broker 端。 实际情况中, 这是吞吐量与延时之间的权衡。默认值为0,表示消息需要被立即发送,无需关系 batch 是否被填满。
调优建议:通常为了减少请求次数、提升整体吞吐量,建议设置一个大于0的值,比如设置为100,此时会在负载低的情况下带来100ms的延时。