
物理结构、逻辑结构、实例(内存结构、进程结构)
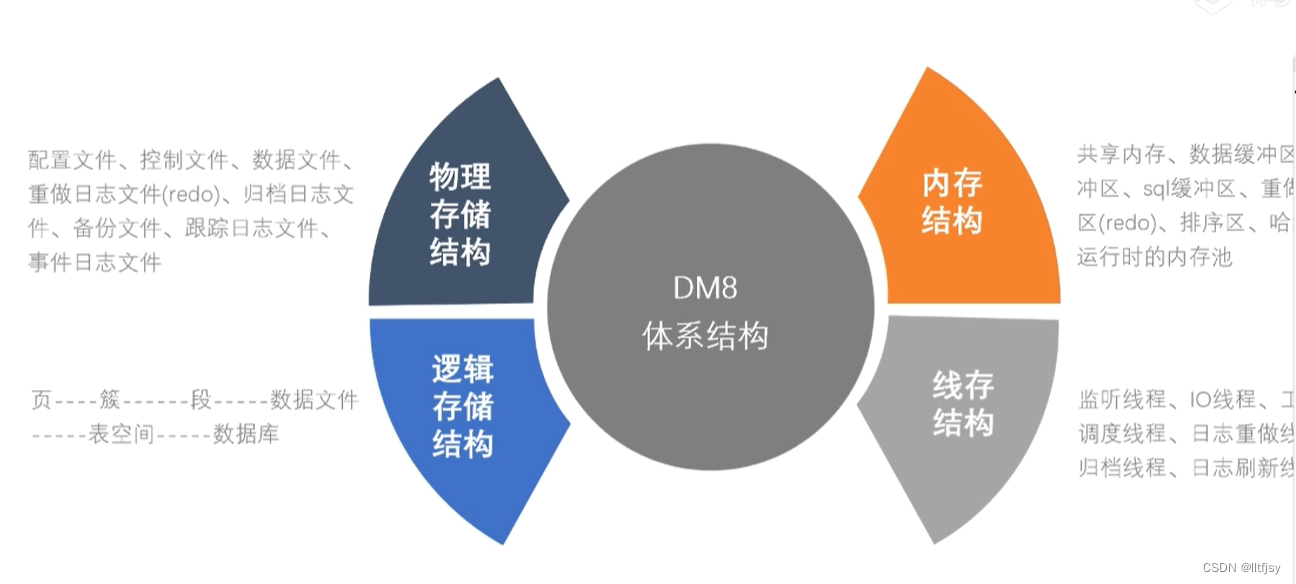
一、物理结构
配置文件、控制文件、数据文件、重做日志文件、归档日志文件、备份文件、跟踪日志文件、事件日志文件
(一)配置文件
以.ini结尾的文件,例如dm.ini (相当于oracle数据库中的pfile文件)、dmmal.ini、dmarch.ini、dm_svc.conf
1.dm.ini
一般跟数据文件在同一个目录下
每创建一个 DM 数据库,就会自动生成 dm.ini 文件。dm.ini 是 DM 数据库启动所必须的配置文件,通过配置该文件可以设置 DM 数据库服务器的各种功能和性能选项,
当 dm.ini 中的某参数值设置为非法值时,若设置值与参数类型不兼容,则参数实际取值为默认值;
若设置值小于参数取值范围的最小值,则实际取值为最小值;若设置值大于参数取值范围的最大值,则实际取值为最大值。
参数属性分为三种:静态、动态和手动。
(1)静态,可以被动态修改,修改后重启服务器才能生效。
(2)动态,可以被动态修改,修改后即时生效。动态参数又分为会话级和系统级两种。
会话级参数被修改后,新参数值只会影响新创建的会话,之前创建的会话不受影响;
系统级参数的修改则会影响所有的会话。
(3)手动,不能被动态修改,必须手动修改 dm.ini 参数文件,然后重启才能生效。
动态修改是指 DBA 用户可以在数据库服务器运行期间,通过调用系统过程 SP_SET_PARA_VALUE()、SP_SET_PARA_DOUBLE_VALUE()和 SP_SET_PARA_STRING_VALUE()对参数值进行修改
2.dmmal.ini
dmmal.ini 是 MAL 系统的配置文件。需要用到 MAL 环境的实例,所有站点 dmmal.ini 需要保证严格一致。
3.dmarch.ini
dmarch.ini 用于本地归档和远程归档。
4.dm_svc.conf
DM 安装时生成一个配置文件 dm_svc.conf,不同的平台所在目录有所不同。
(1)32 位的 DM 安装在 Win32 操作平台下,此文件位于%SystemRoot%\system32 目录;
(2)64 位的 DM 安装在 Win64 操作平台下,此文件位于%SystemRoot%\system32 目录;
(3)32 位的 DM 安装在 Win64 操作平台下,此文件位于%SystemRoot%\SysWOW64 目录;
(4)在 Linux 平台下,此文件位于/etc 目录
dm_svc.conf 文件中包含 DM 各接口及客户端需要配置的一些参数。
(二)控制文件
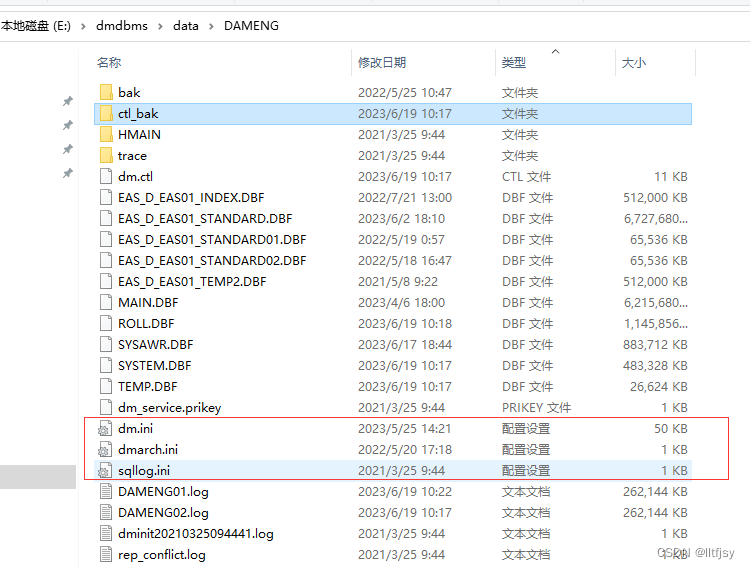
达梦数据库中控制文件只有一个。dm.ini配置文件中可以看到控制文件的路径、控制文件自动备份的路径,一次备份多少个
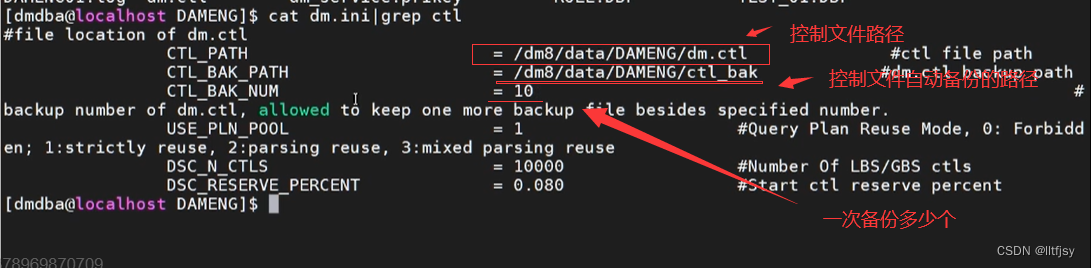
控制文件是一个二进制文件,它记 录了数据库必要的初始信息,其中主要包含以下内容:
1. 数据库名称;
2. 数据库服务器模式;
3. OGUID 唯一标识;
4. 数据库服务器版本;
5. 数据文件版本;
6. 数据库的启动次数;
7. 数据库最近一次启动时间;
8. 表空间信息,包括表空间名,表空间物理文件路径等,记录了所有数据库中使用的 表空间,数组的方式保存起来;
9. 控制文件校验码,校验码由数据库服务器在每次修改控制文件后计算生成,保证控 制文件合法性,防止文件损坏及手工修改。
在服务器运行期间,执行表空间的 DDL 等操作后,服务器内部需要同步修改控制文件内 容。如果在修改过程中服务器故障,可能会导致控制文件损坏,为了避免出现这种情况,在修改控制文件时系统内部会执行备份操作。
备份策略如下:
策略一 在修改 dm.ctl 之前,先执行一次备份,确定 dm.ctl 修改成功后,再将 备份删除,如果 dm.ctl 修改失败或中途出现故障,则保留备份文件。
策略二 在修改 dm.ctl 成功之后,根据 dm.ini 中指定的 CTL_BAK_PATH/CTL_BAK_NUM 对最新的 dm.ctl 执行备份,如果用户指定的 CTL_BAK_PATH 是非法路径,则不再生成备份文件,在路径有效的情况下,生成备份文件时 根据指定的 CTL_BAK_NUM 判断是否删除老的备份文件。
注意:
如果 dm.ctl 文件存放在裸设备上,则【策略一】不会生效。
如果指定的 CTL_BAK_PATH 是无效路径,则【策略二】也不会生效。
如果【策略一】和【策略二】的条件都满足,则都会生效执行,否则只执行满足条 件的备份策略,如果都不满足,则不会再生成备份文件。
如果是初始化新库,在初始化完成后,会在“SYSTEM_PATH/CTL_BAK”路径下对 原始的 dm.ctl 执行一次备份。
(三)数据文件
数据文件以 dbf 为扩展名,它是数据库中最重要的文件类型,一个 DM 数据文件对应磁盘上的一个物理文件,数据文件是真实数据存储的地方,每个数据库至少有一个与之相关的 数据文件。在实际应用中,通常有多个数据文件。 当 DM 的数据文件空间用完时,它可以自动扩展。可以在创建数据文件时通过 MAXSIZE 参数限制其扩展量,当然,也可以不限制。但是,数据文件的大小最终会受物理磁盘大小的 限制。在实际使用中,一般不建议使用单个巨大的数据文件,为一个表空间创建多个较小的 数据文件是更好的选择。 数据文件在物理上按照页、簇和段的方式进行管理。
(1)SYSAWR.DBF
(2)SYSTEM.DBF
(3)ROLL.DBF(相当于undo数据库文件)
(4)MAIN.DBF(相当于user数据库文件)
(5)TEMP.DBF
......

(四)重做日志文件
重做日志(即 REDO 日志)指在 DM 数据库中添加、删除、修改对象,或者改变数据, DM 都会按照特定的格式,将这些操作执行的结果写入到当前的重做日志文件中。
重做日志文 件以 log 为扩展名。
每个 DM 数据库实例必须至少有 2 个重做日志文件,默认两个日志文件 为 DAMENG01.log、DAMENG02.log,这两个文件循环使用。 重做日志文件因为是数据库正在使用的日志文件,因此被称为联机日志文件。
重做日志文件主要用于数据库的备份与恢复。理想情况下,数据库系统不会用到重做日 志文件中的信息。然而现实世界总是充满了各种意外,比如电源故障、系统故障、介质故障, 或者数据库实例进程被强制终止等,数据库缓冲区中的数据页会来不及写入数据文件。
这样,在重启 DM 实例时,通过重做日志文件中的信息,就可以将数据库的状态恢复到发生意外时的状态。 重做日志文件对于数据库是至关重要的。它们用于存储数据库的事务日志,以便系统在 出现系统故障和介质故障时能够进行故障恢复。
在 DM 数据库运行过程中,任何修改数据库 的操作都会产生重做日志,例如,当一条元组插入到一个表中的时候,插入的结果写入了重 做日志,当删除一条元组时,删除该元组的事实也被写了进去,这样,当系统出现故障时, 通过分析日志可以知道在故障发生前系统做了哪些动作,并可以重做这些动作使系统恢复到 故障之前的状态。
(五)归档日志文件
归档日志文件以归档时间命名,扩展名也是 log。但只有在归档模式下运行时, DM 数据库才会将重做日志写入到归档日志文件中。采用归档模式会对系统的性能产生影响, 然而系统在归档模式下运行会更安全,当出现故障时其丢失数据的可能性更小,这是因为一 旦出现介质故障,如磁盘损坏时,利用归档日志,系统可被恢复至故障发生的前一刻,也可 以还原到指定的时间点,而如果没有归档日志文件,则只能利用备份进行恢复。
1.查询归档
(1)查看是否配置归档
select name,arch_mode from v$database;
(2)查看是否归档,及归档的空间,路径
select arch_name,arch_type,arch_dest,arch_file_size,arch_space_limit from v$dm_arch_ini;
(3)查看数据库实例名,状态,主机名
select instance_name,status$,host_name from v$instance;
2.配置归档
方法一:sql命令修改
1)修改数据库为 MOUNT 状态。
disql sysdba/Dbadba12345
SQL> ALTER DATABASE MOUNT; --将数据库设置为mount状态
2)配置本地归档,设置归档路径
SQL> ALTER DATABASE ADD ARCHIVELOG 'DEST = G:\dmdbms\arch, TYPE = local,FILE_SIZE = 1024,SPACE_LIMIT = 204800';
(file_size指的是单个归档日志文件大小)
3)开启归档模式
SQL>ALTER DATABASE ARCHIVELOG;
4)修改数据库为 OPEN 状态
SQL>ALTER DATABASE OPEN;
方法二:直接修改文件
1)手动编辑 dmarch.ini 文件,之后保存在 dm.ini 所在的目录。
dmarch.ini 文
件内容如下:
[ARCHIVE_LOCAL1]
ARCH_TYPE = LOCAL
ARCH_DEST = G:\dmdbms\arch
ARCH_FILE_SIZE = 1024
ARCH_SPACE_LIMIT = 20480
2)编辑 dm.ini 文件,设置参数 ARCH_INI=1,保存。
3)重启数据库,服务器已运行于归档模式。
(六)备份文件
达梦备份文件是备份集,备份完成时会生成一个目录,该目录下会生成两个文件,一个是.bak文件 ,一个是.meta文件(元数据文件)
(七)跟踪日志文件

SVR_LOG=1时开启,默认是0(关闭的状态)
用户在 dm.ini 中配置 SVR_LOG 和 SVR_LOG_SWITCH_COUNT 参数后就会打开跟踪日 志。跟踪日志文件是一个纯文本文件,以“dm_commit_日期_时间”命名,默认生成在 DM 安装目录的 log 子目录下面,管理员可通过 ini 参数 SVR_LOG_FILE_PATH 设置其生成路 径。 跟踪日志内容包含系统各会话执行的 SQL 语句、参数信息、错误信息等。跟踪日志主要 用于分析错误和分析性能问题,基于跟踪日志可以对系统运行状态有一个分析,比如,可以 挑出系统现在执行速度较慢的 SQL 语句,进而对其进行优化。 系统中 SQL 日志的缓存是分块循环使用,管理员可根据系统执行的语句情况及压力情况 设置恰当的日志缓存块大小及预留的缓冲块个数。当预留块不足以记录系统产生的任务时, 系统会分配新的用后即弃的缓存块,但是总的空间大小由 ini 参 数 SVR_LOG_BUF_TOTAL_SIZE 控制,管理员可根据实际情况进行设置。 打开跟踪日志会对系统的性能会有较大影响,一般用于查错和调优的时候才会打开,默 认情况下系统是关闭跟踪日志的。若需要跟踪日志但对日志的实时性没有严格的要求,又希 望系统有较高的效率,可以设置参数SQL_TRACE_MASK和SVR_LOG_MIN_EXEC_TIME 只 记录关注的相关记录,减少日志总量;设置参数 SVR_LOG_ASYNC_FLUSH 打开 SQL 日志异 步刷盘提高系统性能。
(八)事件日志文件
DM 数据库系统在运行过程中,会在 log 子目录下产生一个“dm_实例名_日期”命名的 事件日志文件。事件日志文件对 DM 数据库运行时的关键事件进行记录,如系统启动、关闭、 内存申请失败、IO 错误等一些致命错误。事件日志文件主要用于系统出现严重错误时进行查 看并定位问题。事件日志文件随着 DM 数据库服务的运行一直存在。 事件日志文件打印的是中间步骤的信息,所以出现部分缺失属于正常现象。
二、逻辑结构
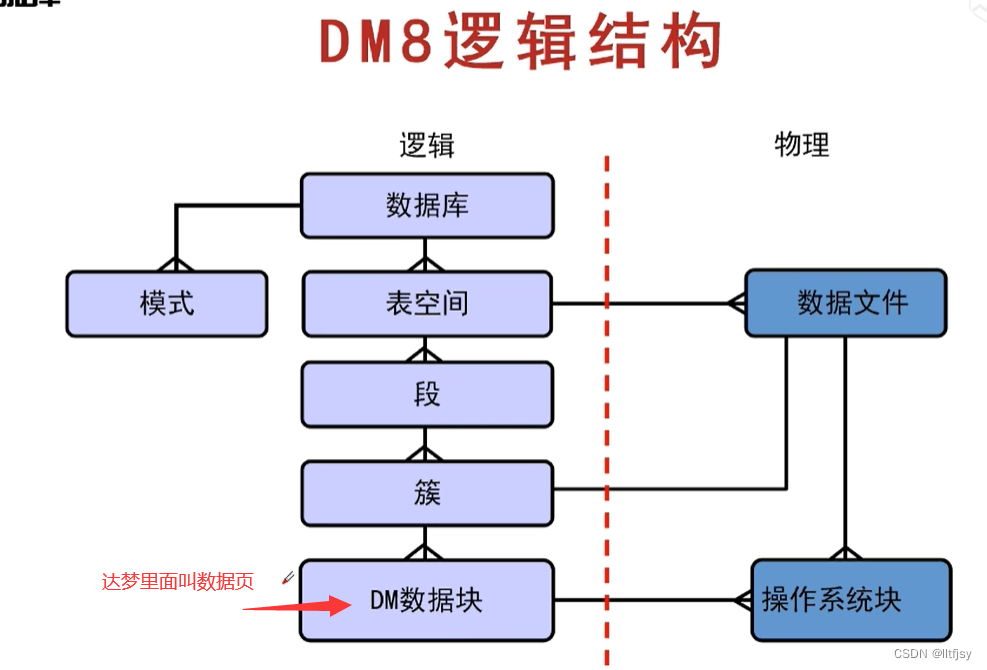
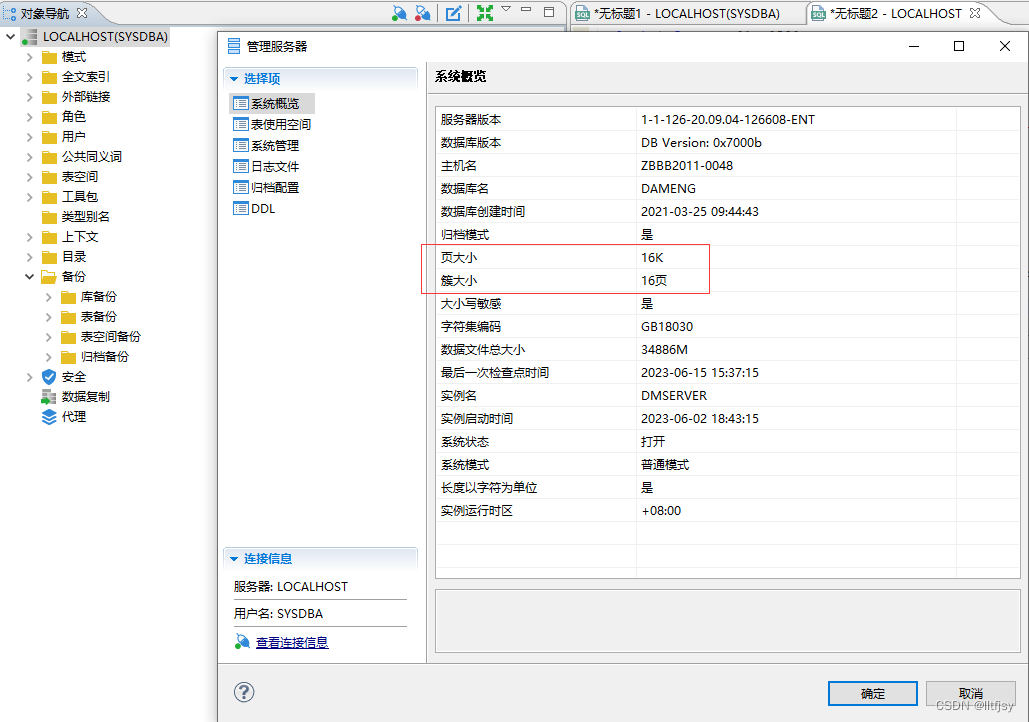
数据文件的最小值是4096*页大小。一个表空间最多有256个文件组成
(如果数据页的大小是16k ,那么数据文件的最小值是4096*16k=64M
如果数据页的大小是8k ,那么数据文件的最小值是4096*8k=32M)
三、内存结构
内存结构分为内存池、缓冲区、其他内存结构。
内存池有共享内存池
缓冲区中有数据缓冲区、日志缓冲区、sql缓冲区、字典缓冲区。
其他内存结构有排序区、hash区、会话内存等
(一)共享内存池
共享内存池是 DM Server 在启动时从操作系统申请的一大片内存。
在 DM Server 的运行期间,经常会申请与释放小片内存,而向操作系统申请和释放内存时需要发出系统调用,此时可能会引起线程切换,降低系统运行效率。
采用共享内存池则可一次向操作系统申请一片较大内存,即为内存池,当系统在运行过程中需要申请内存时,可在共享内存池内进行申请,当用完该内存时,再释放掉,即归还给共享内存池。
共享内存池相当于一个库存,一个保障。其他区域(如排序区、hash区等)不够的时候,可以向共享内存池申请内存,当其用完时还给共享内存池。
当共享内存池也不够的时候,则向操作系统申请,MEMORY_EXTENT_SIZE指定了共享内存池每次扩展的大小。
与共享内存池相关的参数如下:
1. MEMORY_POOL:
共享内存池初始值,以M为单位,默认200。有效值范围:64~67108864。在物理内存较大的情况下,比如大于64G,可以将MEMORY_POOL设置为2048,即2G(也就是说高并发时应调大,避免频繁向os申请内存)(例子:一个cpu:4路8核,内存:256,磁盘阵列:1T密集交易型数据库服务器的MEMORY_POOL参数可以设置为2048,即2G)
2. MEMORY_EXTENT_SIZE
共享内存池每次扩充的大小
3.MEMORY_TARGET:
共享内存池能扩充到的最大大小,以M为单位,默认为0,即没有限制最大值。
select para_name,para_value from v$dm_ini where para_name='MEMORY_POOL'; --查询共享内存池初始大小
SELECT NAME,N_PAGES,N_LOGIC_READS,RAT_HIT FROM V$BUFFERPOOL; --查询内存池BUFFERPOOL的页数、读取页数和命中率信息。
(二)数据缓冲区
数据缓冲区是DM Server在将数据页写入磁盘之前以及从磁盘上读取数据页之后,数据页所存储的地方。 这是DM Server至关重要的内存区域之一,将其设定得太小,会导致缓冲页命中率低,磁盘IO频繁;将其 设定得太大,又会导致操作系统内存本身不够用。
系统启动时,首先根据配置的数据缓冲区大小向操作系统申请一片连续内存并将其按数据页大小进行格式 化,并置入“自由”链中。数据缓冲区存在三条链来管理被缓冲的数据页,一条是“自由”链,用于存放 目前尚未使用的内存数据页,一条是“LRU”链,用于存放已被使用的内存数据页(包括未修改和已修改), 还有一条即为“脏”链,用于存放已被修改过的内存数据页。
LRU链对系统当前使用的页按其最近是否被使用的顺序进行了排序。这样当数据缓冲区中的自由链被用完 时,从LRU链中淘汰部分最近未使用的数据页,能够较大程度地保证被淘汰的数据页在最近不会被用到, 减少IO。
在系统运行过程中,通常存在一部分“非常热”(反复被访问)的数据页,将它们一直留在缓冲区中,对 系统性能会有好处。对于这部分数据页,数据缓冲区开辟了一个特定的区域用于存放它们,以保证这些页 不参与一般的淘汰机制,可以一直留在数据缓冲区中。
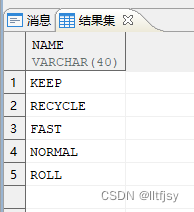
达梦数据库中有四种类型的数据缓冲区,分别是NORMAL、KEEP、FAST和RECYCLE。
select distinct name from v$bufferpool;
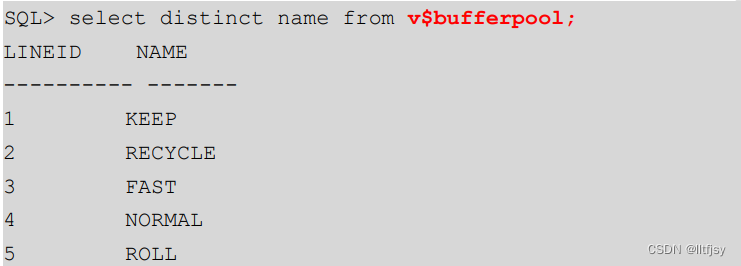
其中,用户可以在创建表空间或修改表空间时,指定表空间属于NORMAL或KEEP缓冲区。
KEEP的特性是对缓冲区中的数据页很少或几乎不怎么淘汰出去,主要针对用户的应用是否需要经常处在内 存当中,如果是这种情况,可以指定缓冲区为KEEP。
RECYCLE缓冲区供 临时表空间使用。
FAST缓冲区根据用户指定的FAST_POOL_PAGES大小由系统自动进行管理,用户不能指定使用RECYCLE和FAST缓冲区的表或表空间。
NORMAL缓冲区主要是提供给系统处理的一些数据页,没有特定指定缓冲区的情况下,默认缓冲区为NORMAL;
查看数据缓冲区相关参数:
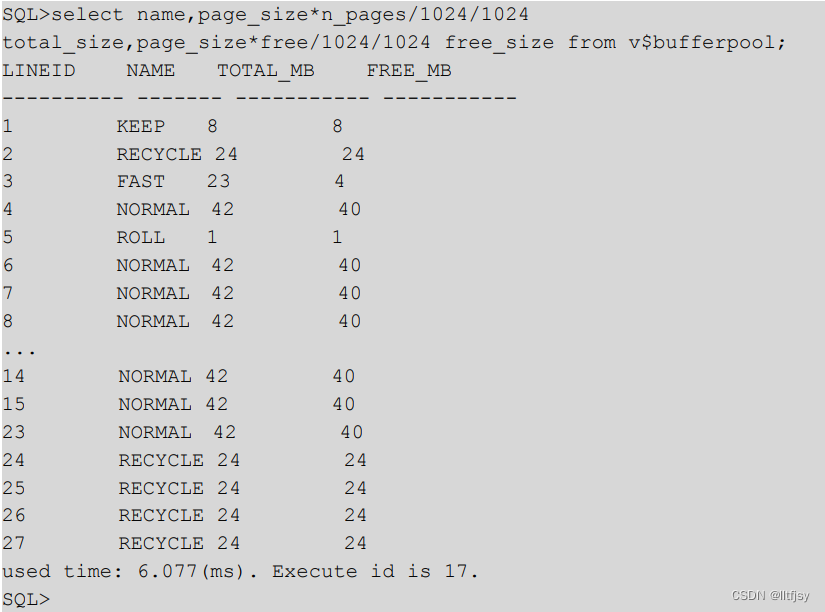
如何查看数据缓冲区使用情况
查出当前数据库的缓冲区使用情况。 具体 SQL 如下
SQL> select name,page_size*n_pages/1024/1024 total_size,page_size*free/1024/1024 free_size from v$bufferpool ;
读多页
在需要进行大量I/O的应用当中,DM之前版本的策略是每次只读取一页。如果知道用户需要读取表的大量 数据,当读取到第一页时,可以猜测用户可能需要读取这页的下一页,在这种情况下,一次性读取多页就 可以减少I/O次数,从而提高了数据的查询、修改效率。 DM Server提供了可以读取多页的参数,用户可以指定这些参数来调整数据库运行效率的最佳状态。在DM 配置文件dm.ini中,可以指定参数MULTI_PAGE_GET_NUM大小(默认值为16页),来控制每次读取的页数。 如果用户没有设置较适合的参数 MULTI_PAGE_GET_NUM 值大小,有时可能会给用户带来更差的效果。如果 MULTI_PAGE_GET_NUM 太大,每次读取的页可能大多都不是以后所用到的数据页,这样不仅会增加 I/O 的读 取,而且每次都会做一些无用的 I/O,所以系统管理员需要衡量好自己应用需求,给出最佳方案。
下面分别介绍Normal缓冲区、Keep缓冲区、RECYCLE缓冲区、FAST缓冲区4种。
1.NORMAL(普通) 缓冲区
NORMAL(普通) 缓冲区主要是提供给系统处理的一些数据页,没有特定指定缓冲区的情况下, 默认缓冲区为 NORMAL。用户可以在创建表空间或修改表空间时,指定表空间属于 NORMAL 或 KEEP 缓冲区。默认是NORMAL 。
与NORMAL(普通) 缓冲区相关的参数如下:
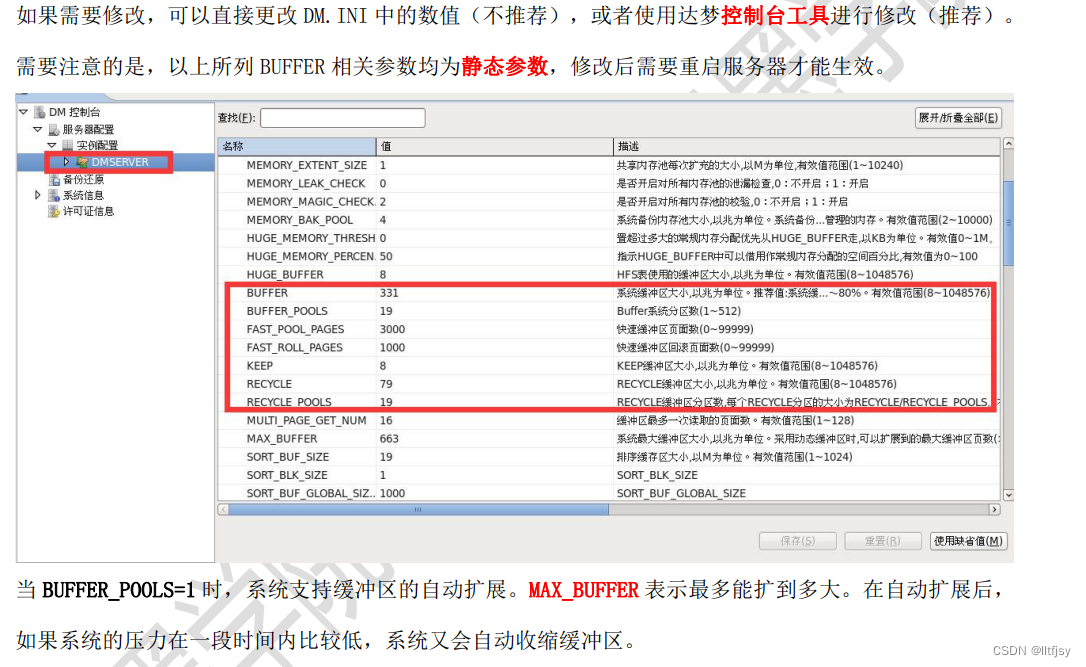
(1)BUFFER
系统缓冲区大小,以兆为单位。推荐值:系统缓冲区大小为可用物理内存的 60%~80%。有 效值范围(8~1048576)
(2)MAX_BUFFER
数据缓冲区扩展最大值,建议配置成=BUFFER
(3)BUFFER_POOLS
BUFFER 系统分区数(一般配置为质数),每个 BUFFER 分区的大
小为 BUFFER/BUFFER_POOLS,并发较大的系统需要配置这个参数,减少数据缓冲区并发冲突,建议BUFFER/ BUFFER_POOLS>=500MB。在内存不大的情况下,建议调小该值。
(例子:一个cpu:4路8核,内存:256,磁盘阵列:1T密集交易型数据库服务器的BUFFER_POOLS参数可以设置为101,即建议BUFFER/ BUFFER_POOLS>=500MB)
2.KEEP(驻留)缓冲区
KEEP (驻留) 的特性是对缓冲区中的数据页很少或几乎不怎么淘汰出去, 主要针对用户的应用是否需要经常处在内存当中,如果是这种情况,可以指定缓冲区为KEEP。达梦的KEEP 缓冲区只能在表空间级别进行设置。
(1)KEEP
KEEP缓冲区大小,以兆为单位。有效值范围 (8~1048576)
3.RECYCLE(临时) 缓冲区
RECYCLE(临时) 缓冲区供临时表空间使用,用户不能指定使用 RECYCLE(临时) 和 FAST(回滚) 缓冲区的表或表空间。RECYCLE和FAST的是数据库系统自动调节的。
相关的参数如下:
(1)RECYCLE
RECYCLE(临时)缓冲区大小,以M为单位。有效值范围(8~1048576),建议设置为500M以上,高并发或大量使用with,临时表,排序等应该调大(例子:一个cpu:4路8核,内存:256,磁盘阵列:1T密集交易型数据库服务器的BRECYCLE参数可以设置为5000,即5G)
(2)RECYCLE_POOLS
RECYCLE 缓冲区分区数,每个 RECYCLE 分区 的大小为 RECYCLE/RECYCLE_POOLS。有效 值范围(1~512)
4.FAST(回滚) 缓冲区
FAST(回滚) 缓冲区根据用户指定的 FAST_POOL_PAGES 大小由系统自动进行管理,用户不能指定使用 RECYCLE 和 FAST 缓冲区的表或表空间。
(1)FAST_POOL_PAGES
快速缓冲区页数。默认值3000,有效值范围(0~99999)。 FAST_POOL_PAGES 的值最多不能超过 BUFFER 总页数的一半,如果超过,系统会自 动调整为 BUFFER 总页数的一半
(三)日志缓冲区
日志缓冲区是用于存放重做日志的内存缓冲区。为了避免由于直接的磁盘 IO 而使系统性能受到影响,系统在运行过程中产生的日志并不会立即被写入磁盘,而是和数据页一样,先将其放置到日志缓冲区中。
相关参数:
1. RLOG_POOL_SIZE
最大日志缓冲区大小(以 M 为单位)。默认为128M 。
一般在内存小于16G的情况下,建议设置为256M,
内存大于16G,小于64G,建议设置为1024M,
当内存大于64G时,建议设置为2048M。
日志缓冲区是用于存放重做日志的内存缓冲区。为了避免由于直接的磁盘IO而使系统性能受到影响,系统 在运行过程中产生的日志并不会立即被写入磁盘,而是和数据页一样,先将其放置到日志缓冲区中。那么 为何不在数据缓冲区中缓存重做日志而要单独设立日志缓冲区呢? 主要是基于以下原因:
. 重做日志的格式同数据页完全不一样,无法进行统一管理;
. 重做日志具备连续写的特点;
. 在逻辑上,写重做日志比数据页IO优先级更高。
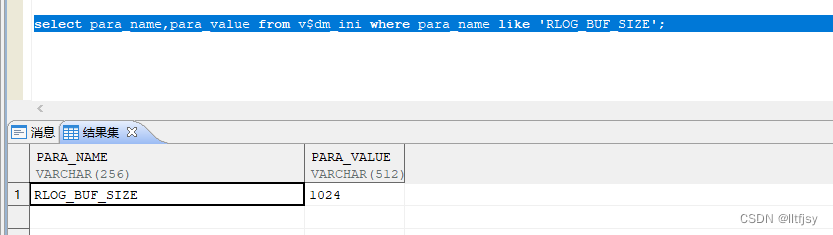
DM Server 提供了参数 RLOG_BUF_SIZE 对日志缓冲区大小进行控制,日志缓冲区所占用的内存是从共享内存池中申请的,单位为页数量,且大小必须为 2 的 N 次方,否则采用系统默认大小 512 页。
select para_name,para_value from v$dm_ini where para_name like 'RLOG_BUF_SIZE';

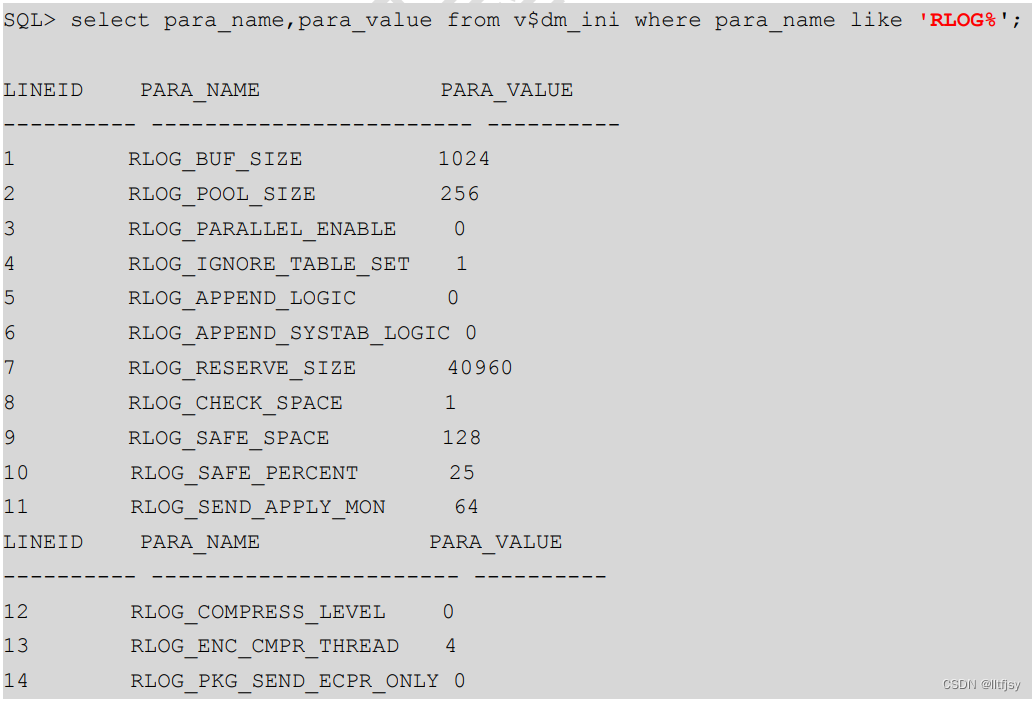
Rlog_buf_size 日志缓冲区的大小 单位 page
RLOG_POOL_SIZE 最大日志缓冲区的大小,单位 M
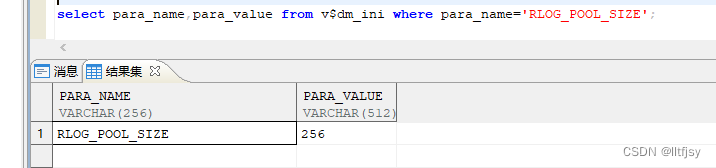
RLOG_POOL_SIZE的建议值:
(1)一般在内存小于等于16G的情况下,建议设置为256M
(2)内存大于16G,小于等于64G,建议设置为1024M
(3)当内存大于64G时,建议设置为2048M。
写机制:每 3 秒写一次;Commit; 数据写之前。
(四)字典缓冲区
字典缓冲区主要存储一些数据字典信息,如模式信息、表信息、列信息、触发器信息等。
相关参数:
1. DICT_BUF_SIZE
字典缓冲区大小,以 M 为单位,默认为5M,如果数据库中对象数量较多,或者存在大量分区表,可适当调大。建议改成50M以上。
存放最近使用的数据字典,目的还是减少磁盘IO
select para_name,para_value from v$dm_ini where para_name like 'DICT_BUF_SIZE';

注:当cache_pool_size的值大于等于PLN_DICT_HASH_THRESHOLD的值的时候,才开启记录执行计划中关联的数据字典,从而减少物理IO,调优时需注意。
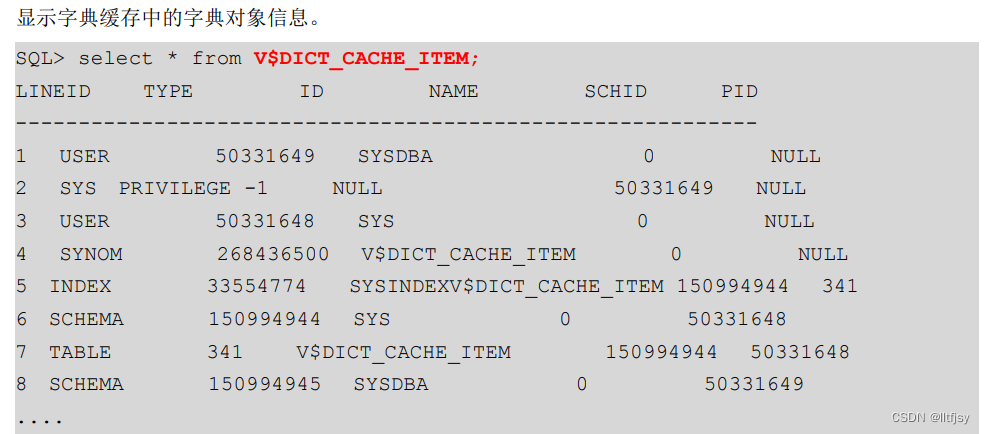
显示字典缓存中的字典对象信息。
SELECT * FROM V$DICT_CACHE_ITEM
显示字典缓存区空间使用情况:
SELECT * FROM V$DICT_CACHE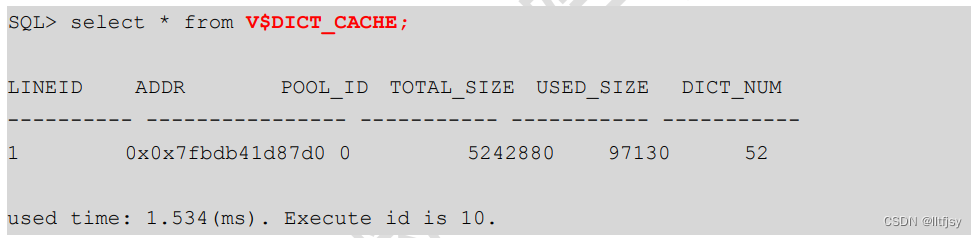
(五)SQL缓冲区
SQL 缓冲区提供在执行 SQL 语句过程中所需要的内存,包括计划、SQL 语句和结果集缓存。
有关参数:
CACHE_POOL_SIZE
SQL 缓冲池大小,以兆为单位。默认值20m ,有效值范围: 32 位平台下为(1~2048);64 位平台下为 (1~67108864)。单位:MB
一般在内存小于等于16G的情况下,建议设置为200M
内存大于16G,小于等于64G,建议设置为1024M
当内存大于64G时,建议设置为2048M。
一般配置为1000-4000
补充:
SQL缓冲区提供在执行SQL语句过程中所需要的内存,包括计划、SQL语句和结果集缓存。
很多应用当中都存在反复执行相同SQL语句的情况,此时可以使用缓冲区保存这些语句和它们的执行计划, 这就是计划重用。这样带来的好处是加快了SQL语句执行效率,但同时给内存也增加了压力。
DM Server在配置文件dm.ini提供了参数来支持是否需要计划重用,参数为USE_PLN_POOL,当指定为非0时, 则启动计划重用;为0时禁止计划重用。DM同时还提供了参数CACHE_POOL_SIZE(单位为MB),来改变SQL 缓冲区大小,系统管理员可以设置该值以满足应用需求,默认值为20M。
结果集缓存包括SQL查询结果集缓存和DMSQL程序函数结果集缓存,在INI参数文件中同时设置参数RS_CAN_CACHE=1且USE_PLN_POOL非0时DM服务器才会缓存结果集。
select para_name,para_value from v$dm_ini where para_name='USE_PLN_POOL'
客户端结果集也可以缓存,但需要在配置文件dm_svc.conf中设置参数:
ENABLE_RS_CACHE = (1) //表示启用缓存;
RS_CACHE_SIZE = (100) //表示缓存区的大小为100M, 可配置为1-65535
RS_REFRESH_FREQ = (30) //表示每30秒检查缓存的有效性,如果失效,自动重查; 0表示不检查。
同时在服务器端使用 INI 参数文件中的 CLT_CACHE_TABLES 参数设置哪些表的结果集需要缓存。另外, FIRST_ROWS 参数表示当查询的结果达到该行数时,就返回结果,不再继续查询,除非用户向服务器发一个 FETCH 命令。这个参数也用于客户端缓存的配置,仅当结果集的行数不超过 FIRST_ROWS 时,该结果集才可 能被客户端缓存。
select sql_id,TOP_SQL_TEXT from v$sql_history;
select sql_id,sql_text from v$sqltext;
select para_name,para_value from v$dm_ini where para_name like 'CACHE_POOL_SIZE';
(六)排序区
相关参数:
1.SORT_FLAG
排序机制,默认为0,参数含义:0:原排序机制;1:新排序机制。
在内存大于64G时建议使用新排序机制,其他情况使用原排序机制。
2.SORT_BUF_SIZE
原排序机制下,排序缓存区最大值,以 M 为单 位。有效值范围(1~2048)
在内存小于64G时建议设置为10M,大于64G时建议设置为512M。
3.SORT_BUF_GLOBAL_SIZE
新排序机制下,排序全局内存使用上限,以 M 为单位。有效值范围(10~4294967294)
默认为1000M。当内存小于16G时,建议设置为500M,大于16G小于64G时建议设置为2000,当内存大于64G时,建议设置为5120M。
4.SORT_BLK_SIZE
默认为 1M,新排序机制下,每个排序分片空间的大小,必须小于 SORT_BUF_GLOBAL_SIZE。
SORT_BLK_SIZE一般不需要设置太大,该内存片大小能容纳1万至5万行待排序的数据即可。该值大小不会超过SORT_BUF_SIZE,超过会重置为SORT_BUF_SIZE。为了保证归并排序的效率,对于大内存排序缓冲区的总的分片个数系统上限为10000个,因此,当SORT_BUF_GLOBAL_SIZE足够大的时候,为了保证大内存排序缓冲区能容纳足够多的数据,需要适当调大SORT_BLK_SIZE。例如,当SORT_BLK_SIZE为1时,SORT_BUF_GLOBAL_SIZE的最大可用值为10000。如果SORT_BUF_GLOBAL_SIZE需要20000M可用空间排序时,需要设置SORT_BLK_SIZE最小为2。
(七)hash区
1.HJ_BUF_SIZE :
单个hash使用的内存。单个 HASH 连接操作符的数据总缓存大小,以 兆为单位。有效值范围(2~100000),默认50m
有大表的hash连接应调大
(1)在服务器物理内存小于等于16GB的情况下,建议使用默认值50M;
(2)当物理内存大于16GB,小于等于64GB时,建议将HJ_BUF_SIZE 设置为500M;
(3)当物理内存大于64GB时,建议将HJ_BUF_SIZE 设置为1000M
2.HJ_BUF_GLOBAL_SIZE
哈希连接使用的内存空间的上限,以兆为单位
HASH 连接操作符的数据总缓存大小(>= HJ_BUF_SIZE),系统级参数,以兆为单位。 有效值范围(10~500000),默认值500m
高并发,hash操作多的话应调大
(1)在服务器物理内存小于等于16GB的情况下,建议使用默认值500M。
(2)当物理内存大于16GB,小于64GB时 。 建议将HJ_BUF_GLOBAL_SIZE 设置为10000M以上。
(3)当物理内存大于64GB时,建议将HJ_BUF_GLOBAL_SIZE 设置为设置为15000M以上。
3.HAGR_BUF_SIZE
单个 HAGR、DIST、集合操作、SPL2、NTTS2以及 HTAB 操作符的数据总缓存大小,默认值50M。
(1)当物理内存大于16GB,小于64GB时,建议将HAGR_BUF_SIZE设置为500M
(2)当物理内存大于64GB时,建议将HAGR_BUF_SIZE 设置为1000M。
4.HAGR_BUF_GLOBAL_SIZE
HAGR、DIST、集合操作、SPL2、NTTS2 以及HTAB 操作符的数据总缓存大小(>= HAGR_BUF_SIZE),默认为500 M。
(1)当物理内存大于16GB,小于64GB时,建议将HAGR_BUF_GLOBAL_SIZE设置为10000M以上。
(2)当物理内存大于64GB时,建议将HAGR_BUF_GLOBAL_SIZE设置为15000M以上。
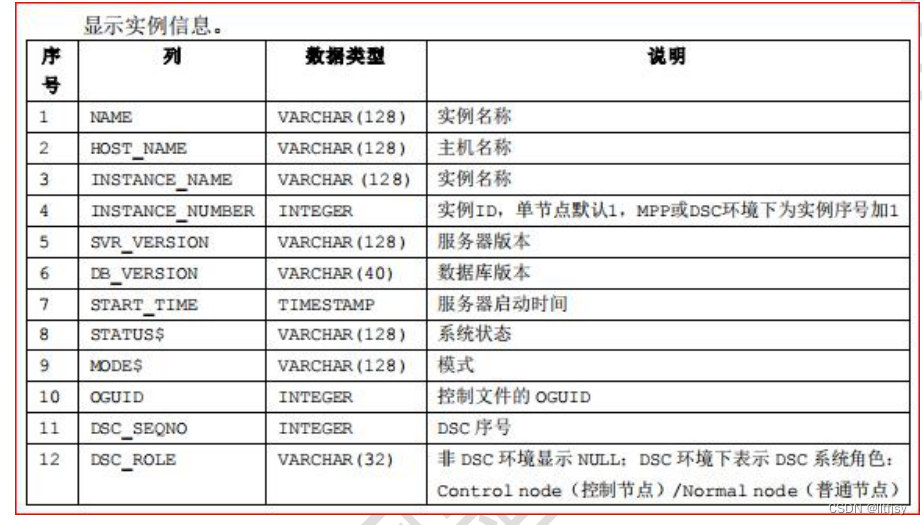
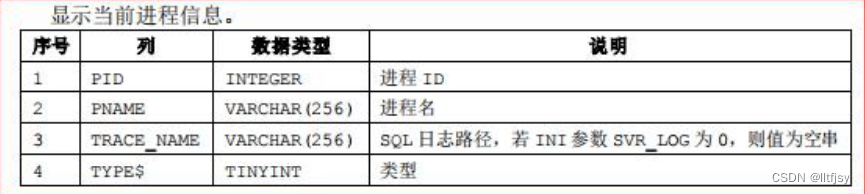
1. 实例信息查看
V$instance 数据字典结构 :
 V$process数据字典结构:
V$process数据字典结构:
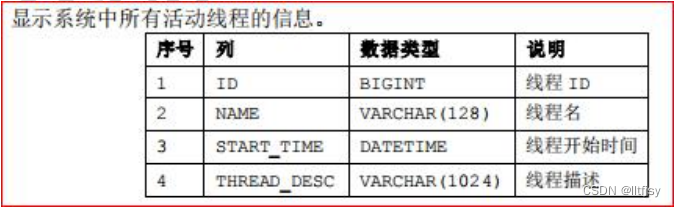
V$thread 数据字典:
查看版本
select db_version,svr_version from v$instance;
版本是dm8
![]()

1.1 进程和线程
查看进程信息:
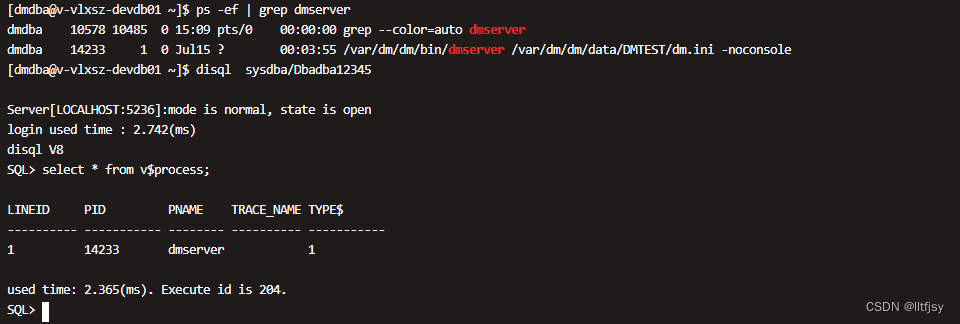
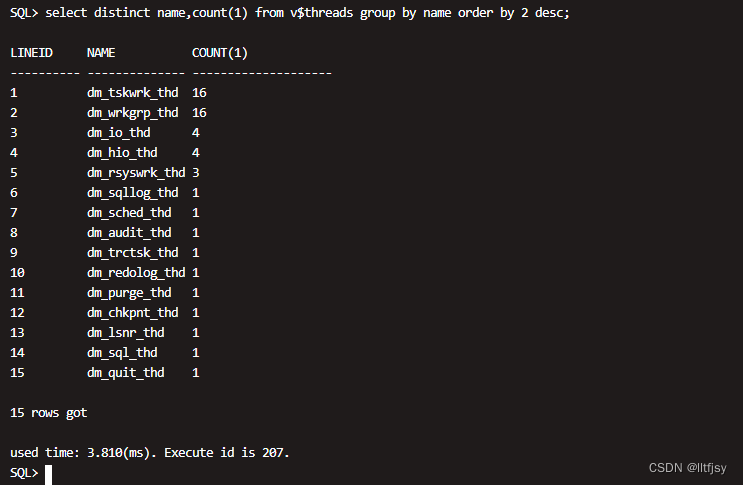
查看进程所对应的线程信息:
select distinct name,count(1) from v$threads group by name order by 2 desc;
select DISTINCT name, thread_desc from v$threads;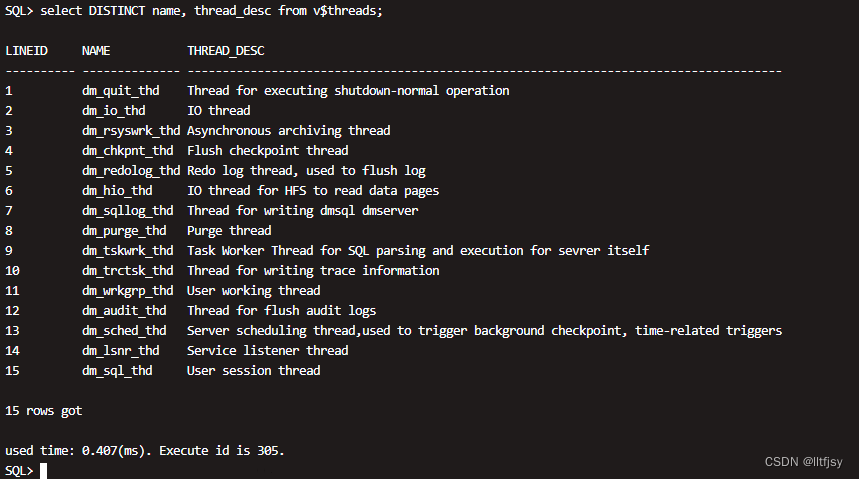
1.2 内存
V$mem_pool 数据字典
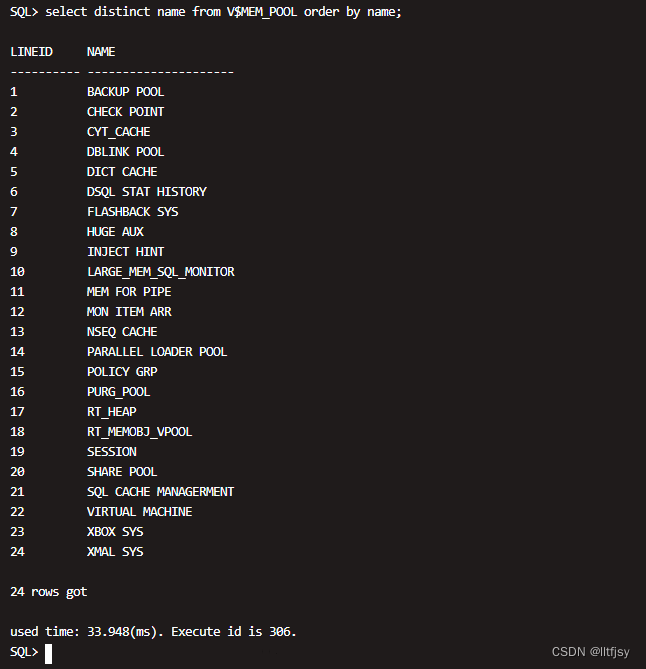
select distinct name from V$MEM_POOL order by name;


select distinct name from V$MEM_POOL order by name;
SQL> host clear 清屏
1.3 缓冲区
1.3.1 数据缓冲区
SQL> select distinct name from v$bufferpool;
select name,page_size*n_pages/1024/1024 total_size,page_size*free/1024/1024 free_size from v$bufferpool;

1.3.2 日志缓冲区
select para_name,para_value from v$dm_ini where para_name like 'RLOG_BUF_SIZE';
2. 实例与数据库
2.1概念
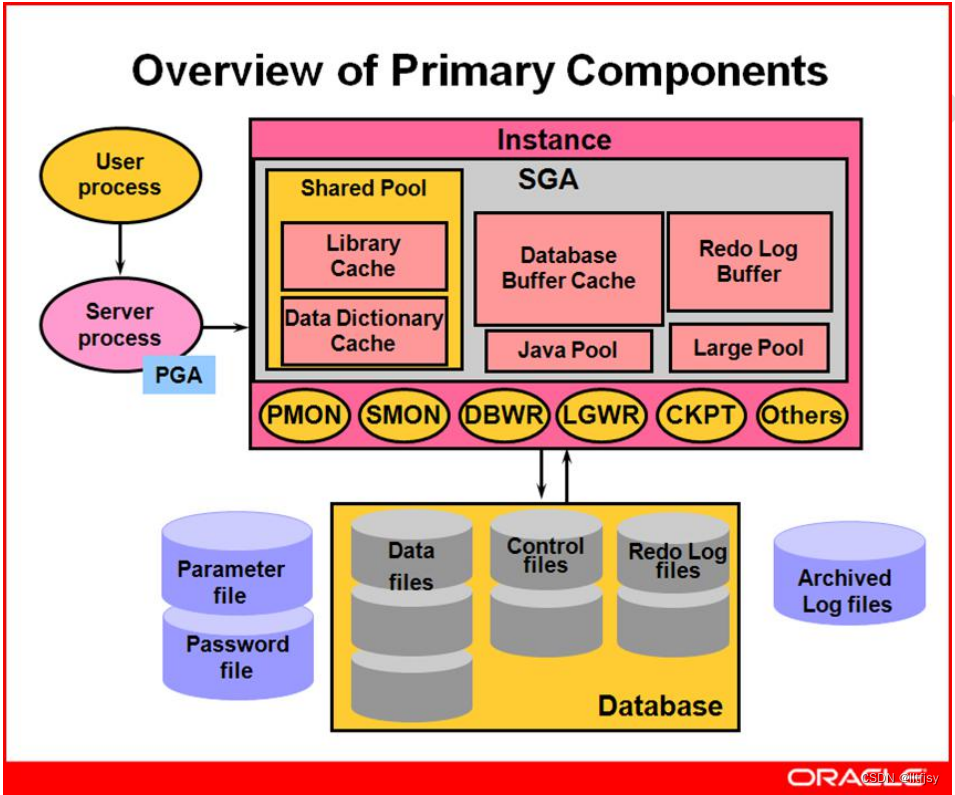

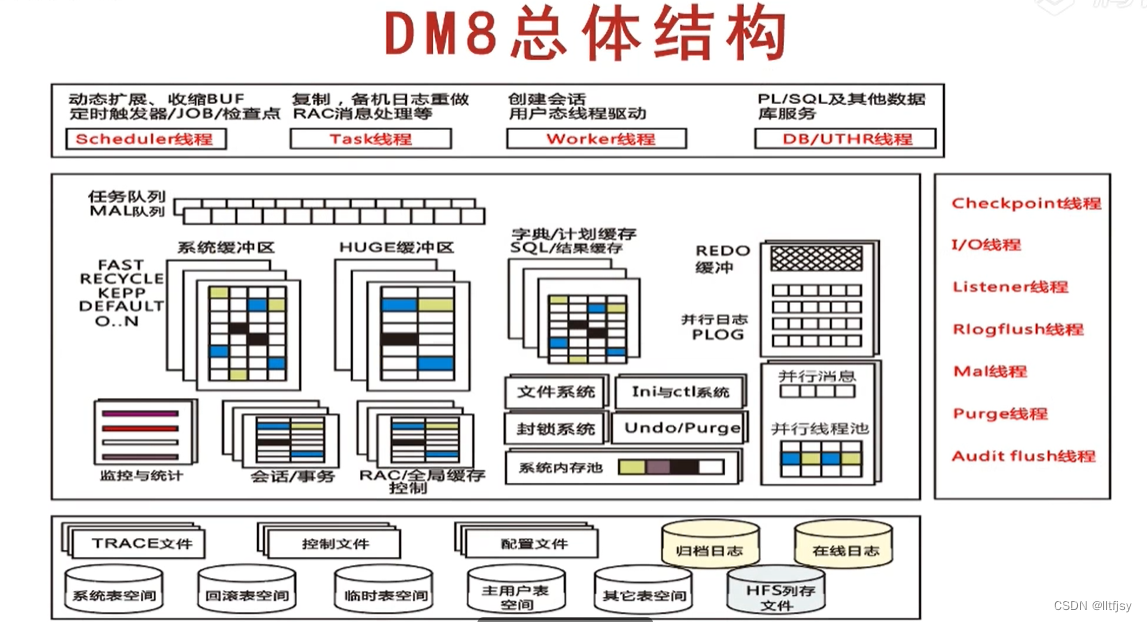
DM 服务器使用“对称服务器构架”的单进程、多线程结构。(这里所指的线程即为操作系统的线程)
DM 进程中主要包括监听线程、IO 线程、工作线程、调度线程、日志线程等.

2.2.2 缓冲区
2.2.2.1 数据缓冲区
2.2.2.2 日志缓冲区
2.2.3 排序区
排序缓冲区提供数据排序所需要的内存空间。当用户执行SQL语句时,常常需要进行排序,所使用的内存 就是排序缓冲区提供的。在每次排序过程中,都首先申请内存,排序结束后再释放内存。
如果内存排序无法完成,把部分排序转到磁盘上即temp表空间中
DM Server 提供了参数来指定排序缓冲区的大小,参数 SORT_BUF_SIZE 在 DM 配置文件 dm.ini 中,系统管 理员可以设置其大小以满足需求,由于该值是由系统内部排序算法和排序数据结构决定,建议使用默认值 2M。
2.2.4哈希区
DM8提供了为哈希连接(hash join)而设定的缓冲区,不过该缓冲区是个虚拟缓冲区。之所以说是虚拟缓冲,是因为系统没有真正创建特定属于哈希缓冲区的内存,而是在进行哈希连接时,对排序的数据量进行 了计算。如果计算出的数据量大小超过了哈希缓冲区的大小,则使用DM8创新的外存哈希方式;如果没有 超过哈希缓冲区的大小,实际上使用的还是VPOOL内存池来进行哈希操作。
DM Server在dm.ini中提供了参数HJ_BUF_SIZE来进行控制,由于该值的大小可能会限制哈希连接的效率,所以建议保持默认值,或设置为更大的值。
除了提供 HJ_BUF_SIZE 参数外,DM Server 还提供了创建哈希表个数的初始化参数,其中,HAGR_HASH_SIZE 表示处理聚集函数时创建哈希表的个数,建议保持默认值 100000。
2.2.5 SSD 缓冲
固态硬盘采用闪存作为存储介质,因没有机械磁头的寻道时间,在读写效率上比机械磁盘具有优势。在内 存、SSD磁盘、机械磁盘之间,符合存储分级的条件。为提高系统执行效率,DM Server将SSD文件作为内存缓存与普通磁盘之间的缓冲层,称为“SSD缓存”。
DM Server在的dm.ini中提供参数SSD_BUF_SIZE和SSD_FILE_PATH来配置SSD缓冲,SSD_BUF_SIZE指定缓冲 区的大小,单位是M,DM Server根据该参数创建相应大小的文件作为缓冲区使用;
SSD_FILE_PATH指定该 文件所在的文件夹路径,管理员需要保证设置的路径是位于固态磁盘上。
默认 SSD 缓冲区是关闭的,即 SSD_BUF_SIZE 为 0。若要配置 SSD 缓冲区,将其设置为大于 0 的数并指定 SSD_FILE_PATH 即可。

2.3【process structures】进程线程结构
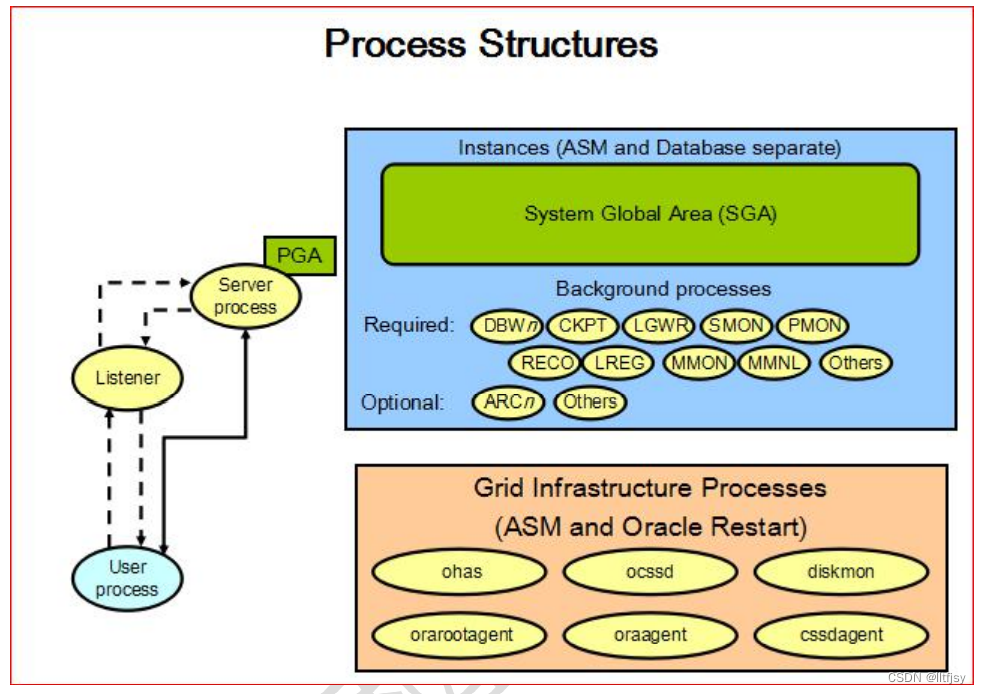
DM 进程中主要包括监听线程、IO 线程、工作线程、调度线程、日志线程等
通过 DM 的动态性能视图查看线程的相关信息。主要相关的视图有如下 4 个:
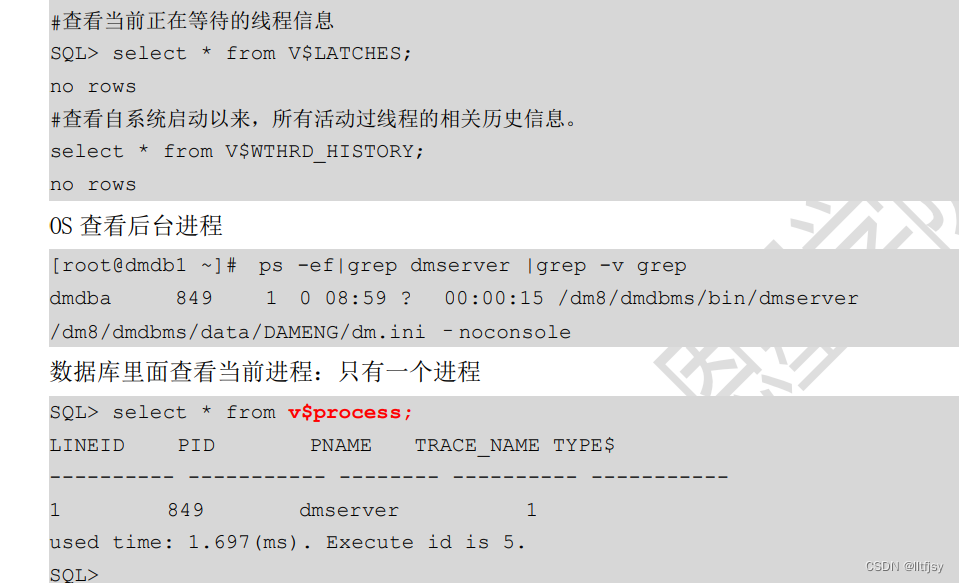
V$LATCHES 记录当前正在等待的线程信息
V$THREADS 记录当前系统中活动线程的信息
V$WTHRD_HISTORY 记录自系统启动以来,所有活动过线程的相关历史信息。
V$PROCESS 记录服务器进程信
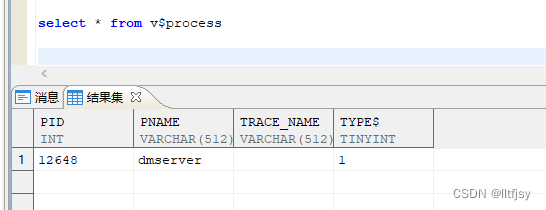
#查看当前进程:只有一个进程
#多线程,v$threads 视图会记录线程启动,对线程的功能描述:
select distinct name,count(1) from v$threads group by name order by 2 desc;

查看线程的描述信息:
select DISTINCT name, thread_desc from v$threads

2.3.1 监听线程 (dm_lsnr_thd Service listener thread)
检测外部会话连接,监听线程名是 dm_lsnr_thd,监听线程主要的任务是在服务器端口上进行循环监听, 一旦有来自客户的连接请求,监听线程被唤醒并生成一个会话申请任务,加入工作线程的任务队列,等待 工作线程进行处理。它在系统启动完成后才启动,并且在系统关闭时首先被关闭。为了保证在处理大量客 户连接时系统具有较短的响应时间,监听线程比普通线程优先级更高。
2.3.2 工作线程