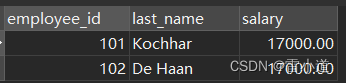
Project webpage: https://splice-vit.github.io
Abstruct
将两张图片中语义相近的目标的结构和风格(外观)拼接

1、Introduction
那么这个 Class Token 有什么作用呢?
如果没有这个向量,也就是将9个向量(1~9)输入 Transformer 结构中进行编码,最终会得到9个编码向量,可对于图像分类任务而言,我们应该选择哪个输出向量进行后续分类呢?
因此,ViT算法提出了一个可学习的嵌入向量 Class Token( 向量0 ),将它与9个向量一起输入到 Transformer 结构中,输出10个编码向量,然后用这个 Class Token 进行分类预测即可。
2、Related Work
domain transfer:就是适配分布,特别地是指适配marginal distribution,但是没有考虑类别信息。如何做domain transfer:在传统深度网路的loss上,再加另一个confusion loss,作为classifier能否将两个domain进行分开的loss。两个loss一起计算,就是domain transfer。(https://zhuanlan.zhihu.com/p/30621691 《迁移学习导论》作者 很厉害)
这些方法的目标是学习源domains(图像域)和目标域之间的映射。,典型方法是训练一个GAN网络。(注:图像域:图像内容被赋予了相同属性。 图像翻译:将图像内容从一个图像域X转换到另一个图像域Y,将原始图像的某种属性X移除,重新赋予新属性Y)
SA(Swapping Autoencoder)训练了一个特定的GAN来分解图片的结构和纹理,然后在两张图片的图像域中交换。
单样本image-to-image translation已经出现。
(跟SA相比,本文的方法不限于特定图像域,也不需要数据集进行训练,不涉及到对抗训练。)
以上这些方法只能利用低维信息并缺少语义理解。
STROTSS使用预训练的VGG表示风格和自相似性,在基于优化的框架中捕获结构,在全局方式下进行风格迁移。
Semantic Style transfer 方法在两张图片语义相近的两部分区域匹配,这个方法仅限于色彩变换,或依赖于额外的语义输入。
本文的目标是在两张自然场景图片对中语义相近的两个目标间进行风格迁移,这个目标是随机并灵活的。
论文导读:DINO-自监督视觉Transformers: https://new.qq.com/rain/a/20211202A02CHQ00
DINO:基于Vit的自监督算法: https://zhuanlan.zhihu.com/p/439244656
3、Method
原始structure图:Is,目标appearance图:It,生成新的图片Io
Io:=Is中的objects “painted”成It中与之语义相关对象的视觉外观风格。
输入图片对{Is,It} ,训练一个生成器Gɵ(IS)=Io
损失函数:用自监督的DINO-ViT(预训练ViT模型)确定训练损失。
把structure/appearance图片输入到模型中,训练Gɵ生成目标图片。
Lapp是Io和It的损失(交叉熵?)
Lstructure是Io和Is的损失
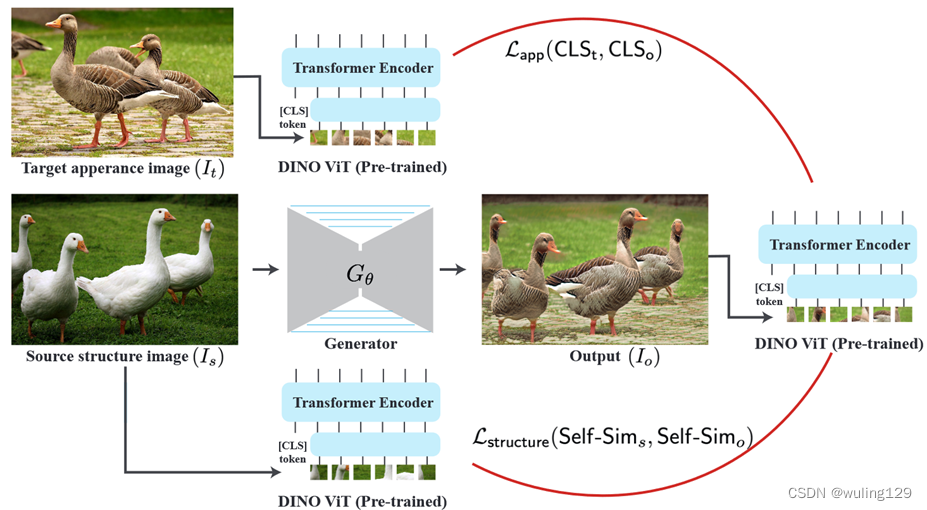
1、 for a given pair{Is, It}, we train a generator Gθ(Is) = Io.
2、 To establish our training losses, we leverage DINO-ViT – a self-supervised, pre-trained ViT model – which is kept fixed and serves as an external high-level prior.
3、We propose new deep representations for structure and appearance in DINO-ViT feature space:
we represent structure via the self-similarity of keys in the deepest attention module (Self-Sim), and appearance via the [CLS] token in the deepest layer.
4、we train Gθ to output an image, that when fed into DINO-ViT, matches the source structure and target appearance representations.
our training objective is twofold: (i) Lapp that encourages the deep appearance representation of Io and It to match, and (ii) Lstructure,which encourages the deep structure representation of Io and Is to match.
3.1 Vision Transformers – overview ViT模型回顾

参考博文:
1、vit网络模型简介 https://blog.csdn.net/m0_63156697/article/details/126889774
2、ViT(Vision Transformer)解析(更详细) https://zhuanlan.zhihu.com/p/445122996
3、ViT学习笔记(有代码) https://blog.csdn.net/m0_53374472/article/details/127665215


论文中的vit表述
1、 an image I is processed as a sequence of n non-overlapping patches as follows:
2、spatial tokens are formed by linearly embedding each patch to a d-dimensional vector
3、and adding learned positional embeddings.
4、 An additional learnable token, a.k.a [CLS] token, serves as a global representation of the image.
The set of tokens are then passed through L Transformer layers:each consists of layer normalization (LN), Multihead Self-Attention (MSA) modules, and MLP blocks:

5、After the last layer, the [CLS] token is passed through an additional MLP to form the final output, e.g., output distribution over a set of labels。
In our framework, we leverage DINO-ViT , in which the model has been trained in a self-supervised manner using a self-distillation approach(自蒸馏方法).
3.2 Structure & Appearance in ViT’s Feature Space

cos-sim是key之间的余弦相似度(见公式1),自相似性维度:![]()
•Understanding and visualizing DINO-ViT’s features

•φ(I) denotes the target features.


•如果不考虑key的appearance信息,只考虑key的自相似性self-similarity

3.3. Splicing ViT Features
training our generator:![]()
其中α和β表示两项之间的相对权重。目标函数的驱动损失为Lapp,所有实验均设α = 0.1, β = 0.1。
Appearance loss:The term Lapp. encourages the output image to match the appearance of It, and is defined as the difference in [CLS] token between the generated and appearance image:



我们将Identity Loss应用于最深层ViT层中的key,这是输入图像的语义可逆表示。
Data augmentations and training
一对图像的输入{It,Is},通过应用增益,例如crops 和 color jittering创建额外的训练样例
Gθ对多个内部示例进行了训练。因此,它必须为包含N个例子的数据集习得一个好的映射函数,而不是解决单个实例的测试时间优化问题。

4、result

own dataset, named Wild-Pairs。 The image resolution ranges from 512px to 2000px.
4.1 Comparisons to Prior Work:Qualitative comparison(定性比较)


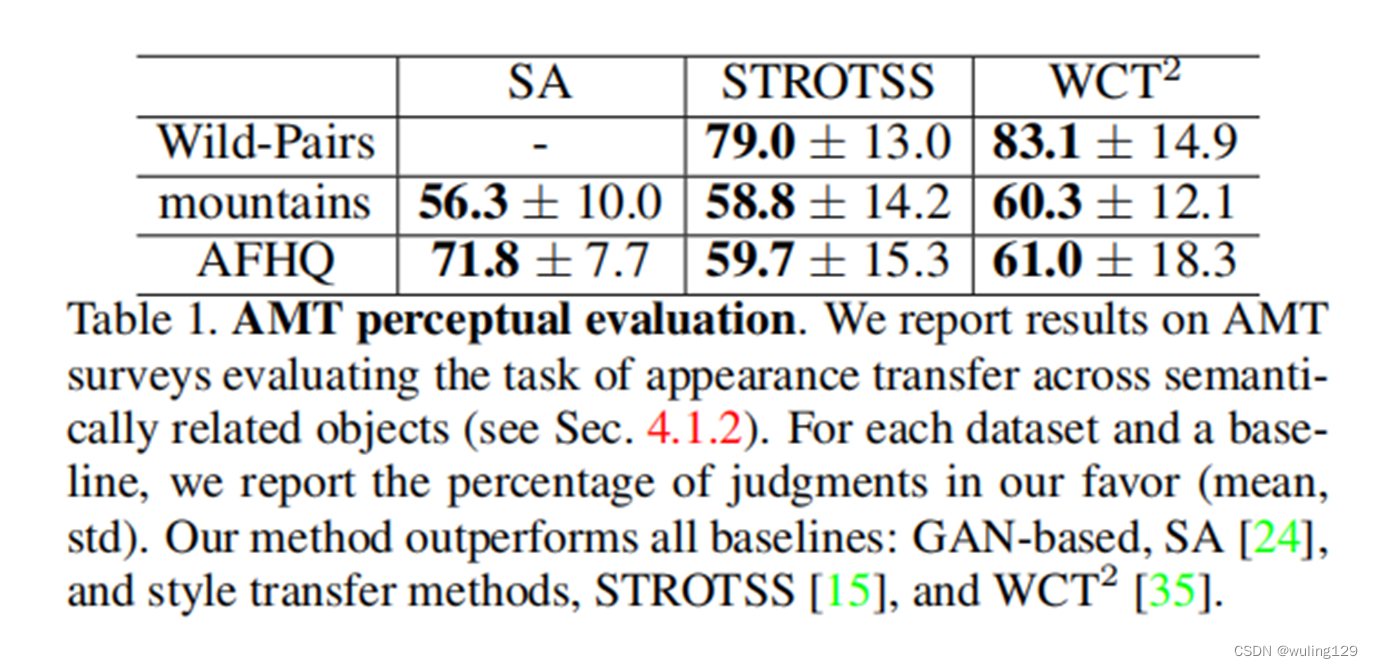
4.1 Comparisons to Prior Work: Quantitative comparison(定量比较)
•Human Perceptual Evaluation(人类感知评估):The participants(参与者) are asked:“Which image best shows the shape/structure of image A combined with the appearance/style of image B?”.

4.2 Ablation

4.3 Limitations(方法的限制)
•对象在语义上是相关的,但有一个图像是高度不现实的(因此超出了DINO-ViT的分布)

方法不能在语义上将鸟与飞机联系起来。