Push好在两点:1.把结果下推到下流节点,与控制流解耦合,有利于cache
2.对于有向无环图,而不仅仅是树的query plan有更好的效果
解释:
pull伪代码

push 伪代码

解释一下push,就是把操作下推到叶子节点,然后返回result buffer。
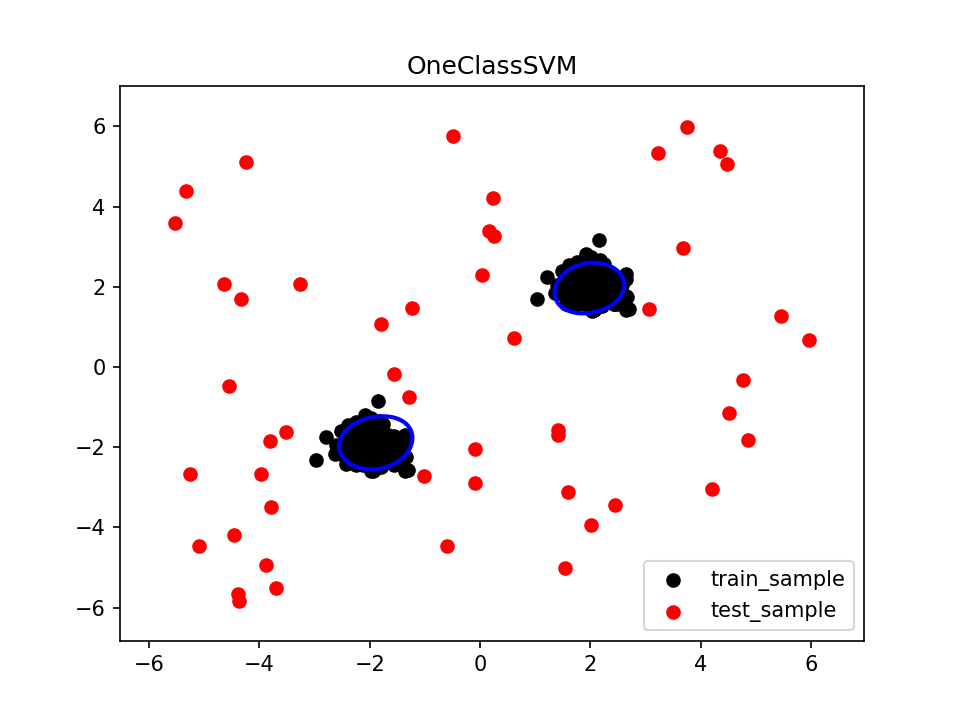
对于push第二个点好处的解释:两个请求节点,对一个节点做请求
0 0
---》0 《---
1.调度
如果是pull的话,“requests for rows” and “computations to produce rows” are no longer one-to-one. messier with multiple outputs。也就是说,你发起对一行的请求,但是下游算子计算的是别的行的,这可能会导致bug,不太直观
而push就没有这个问题。scheduling of operators was never tied to their outputs in the first place。本来这个顺序对应在这里就不重要,缺少了缺少了嘛
2.生命周期的控制
push:
operators now drive when their consumers process a row, they can effectively force them to take ownership of a row and deal with it.最是完成了就传给上层就行了,依赖反过来后,就没有两个拉取,就一个结果往两个父节点上推
而在pull系统中要做一个没有边界的buffer?这显然不太好
对于cache友好:
与逻辑解耦了,这样比较好,而且actually extremely easy to unroll a synchronous, push-based query into the equivalent code you’d write by hand.编译容易优化?毕竟把操作下推了?
但是对于要求对子节点控制的算法,比如join(迭代器), limit来说就不太好
总之,这个两个没有绝对的好坏,看工作场景。
参考资料:
Query Engines: Push vs. Pull