一、先了解什么是本地事务
1. 概念
本地事务是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器位于同一节点相同数据库上。
又称为传统事务。它是一个操作序列,这些操作要么都执行,要么都不执行,是一个不可分割的工作单位。例如,银行转账工作:从一个帐号扣款并使另一个帐号增款,这两个操作要么都执行,要么都不执行。数据库事务必须具备ACID特性,即原子性、一致性、隔离性和持久性。
如图:
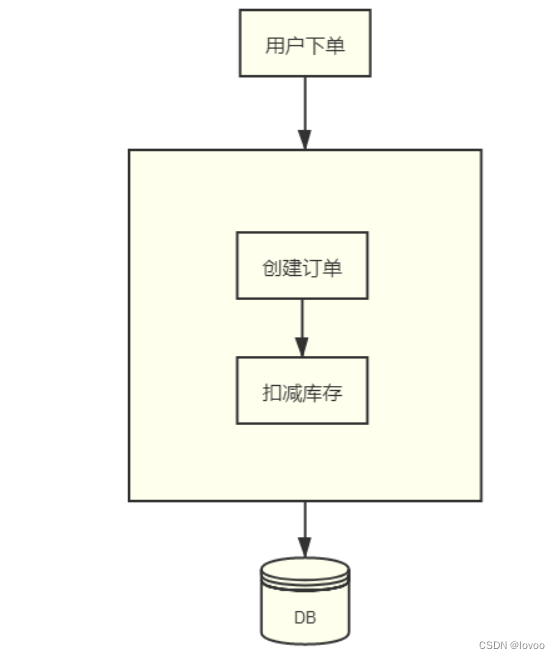
2. ACID理论(强一致性)
原子性(Atomicity)、一致性(Consistency )隔离性或独立性( Isolation)和持久性(Durabilily),简称就是ACID;
- 原子性:一系列的操作整体不可拆分,要么同时成功,要么同时失败
- 一致性:数据在事务的前后,不能破坏数据的完整性以及业务逻辑上的一致性。
转账。A:1000;B:1000;转200事务成功;A:800B: 1200 - 隔离性:多个事务并发访问时,事务之间互相隔离。(脏读、不可重复读、幻读)
- 持久性:事务成功后,数据会保存在数据库并不再回滚
3. 事务间的影响
三者可能同时出现,都会导致同一事务中前后两次读取结果不一致
| 描述 | |
|---|---|
| 脏读 | 在一个事务中读取了另一个事务未提交的脏数据(前后两次结果读取不一致) |
| 不可重复读 | 在一个事务中读取了另一个事务dml操作并提交的数据(前后两次结果读取不一致) |
| 幻读 | 在一个事务中读取了另一个事务ddl操作并提交的数据(前后两次结果读取不一致) |
4. 解决方法
解决方法:
- 开启事务,设置事务隔离级别
- 在数据库管理系统(DBMS)中,默认情况下一条SQL就是一个单独事务,事务是自动提交的。
- 只有显式的使用start transaction开启一个事务,才能将一个代码块放在事务中执行。
- 保障事务的原子性是数据库管理系统的责任,为此许多数据源采用日志机制。
例如,SQL Server使用一个预写事务日志,在将数据提交到实际数据页面前,先写在事务日志上。
5. 事务隔离级别
概述:
事务之间会存在互相影响的情况,事务隔离级别不同影响的范围也不同
谁实现的?
由数据库实现
在JAVA中只是设定事务隔离级别,而不是实现它
MySql的InnoDB 引擎可以通过next-key locks机制(参考下文"行锁的算法"一节)来避免幻读
| 脏读 | 不可重复读 | 幻读 | 默认级别 | 实现方法 | |
|---|---|---|---|---|---|
| Read uncommitted | √ | √ | √ | ||
| Read committed | × | √ | √ | SQLServer/Oracle | |
| Repeatable read | × | × | √ | Mysql | 行锁 |
| Serializable | × | × | × | 表锁 |
二、Spring事务
1. 设置事务的隔离级别
@Transactional(isolation=Isolation.REPEATABLE_READ)
DEFAULT(-1), 默认
READ_UNCOMMITTED(1), 读未提交
READ_COMMITTED(2), 读已提交
REPEATABLE_READ(4), 可重复读
SERIALIZABLE(8); 串行化
2. Spring的传播行为
PROPAGATION_REQUIRED:(要求一个事务)当前没有事务,创建事务;如果存在事务,就加入该事务【常用】
PROPAGATION_SUPPORTS:(支持当前事务)当前存在事务,就加入该事务;如果当不存在事务,以非事务执行
PROPAGATION_MANDATORY:(强制使用当前事务)当前存在事务,就加入该事务;如果不存在事务,抛出异常
PROPAGATION_REQUIRES_NEW:(要求一个新事务)创建新事务执行
PROPAGATION_NOT_SUPPORTED:(不使用事务)以非事务方式执行,如果存在事务,就把当前事务挂起
PROPAGATION_NEVER:(强制不使用事务)如果当前存在事务,则抛出异常
PROPAGATION_NESTED:(嵌套事务)如果存在事务,则在嵌套事务内执行;如果没有事务,创建事务
例如:
@Transactional(timeout=30)
public void a() {
b();// a事务传播给了b事务,并且b事务的设置失效
c();// c单独创建一个新事务
}
@Transactional(propagation = Propagation.REQUIRED, timeout=2)
public void b() {
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void c() {
}
3. Spring设置传播行为
@Transactional(propagation = Propagation.REQUIRED, timeout=2)
4. 本地事务失效
案例
事务方法调用本方法内的其他事务方法,出现本地事务失效的问题
@Transactional(timeout=30)
public void a() {
b();// 绕过了代理对象,异常不会回滚
c();// 绕过了代理对象,异常不会回滚
}
@Transactional(propagation = Propagation.REQUIRED, timeout=2)
public void b() {
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void c() {
}
原因
Spring事务的原理是使用了代理对象,如果两个事务方法在同一个Service类内,事务A方法直接调用事务B方法,即绕过了代理对象,事务未生效
解决
使用代理对象来调用事务方法,不能使用this.b(),也不能注入自己
具体步骤:
4.1、引入aop依赖
<!-- 引入aop,解决本地事务失效问题 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
4.2、在启动类添加注解,开启动态代理
加该注解后使用aspectj作动态代理【即使没有接口也能代理,使用cglib继承的方式完成动态代理】
exposeProxy = true:对外暴露代理对象
@EnableAspectJAutoProxy(exposeProxy = true)
4.3、本类互相调用使用代理对象
获取当前类的代理对象
OrderServiceImpl orderService = (OrderServiceImpl)AopContext.currentProxy();
orderService.b();
orderService.c();
三、分布式CAP定理和BASE理论
1.CAP定理
1.1.概述
CAP定理,指的是在一个分布式系统中:
-
一致性(Consistency):
在分布式系统中的所有数据备份,在同一时刻是一致的。(3个数据库,同一份数据值一致) -
可用性(Availability):
在集群中一部分节点故障后,集群整体仍能响应客户端的请求。(同一时刻数据可允许出现不一致) -
分区容错性(Partition tolerance):
分布式系统之间允许通信失败。(分布式网络必须保证分区容错性,因为网络通信一定会出现问题)
大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition)
分区容错的意思是,区间通信可能失败。比如,一台服务器放在中国,另一台服务器放在美国,
这就是两个区,它们之间可能无法通信。
CAP原则指的是,这三个要素最多只能同时实现两点,不可能三者兼蹊。
- CA:互斥
- AP:可用性+分区容错性,允许出现子网络通信失败,并保证可用性(出现数据未同步,不能保证一致性)
- CP:一致性+分区容错性,允许出现子网络通信失败,并保证数据一致性(网络通信故障的节点无法继续提供服务,牺牲可用性)
1.2.实现一致性的算法
raft、paxos
[raft算法演示]: http://thesecretlivesofdata.com/raft/
[raft详细演示]: raft.github.io
1.3. raft算法(CP)
1.3.1.概述
1.raft算法通过领导选举、日志复制实现一致性+分区容错性
2.无法实现可用性,例如出现两个分区的时候,出现了两个领导并且两个分区节点数相等时,两个分区都无法工作(无法选出领导,因为无法获得大多数选举人的投票)
三种状态
Follower:随从(集群所有节点启动默认都是随从状态)
Candidate:候选者(没有在集群中监听到领导者,变成候选者)
Leader:领导者(得票多者被选举为领导者,所有的修改都必须经过领导)
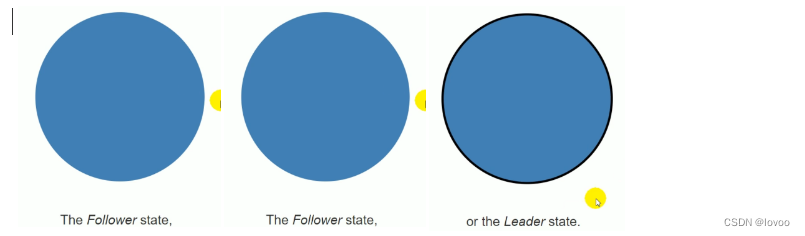
三个超时时间
election timeout:选举超时(随从者成为候选者的自旋时间)
150ms~300ms之间
heartbeat timeout:心跳超时(领导者发送心跳给跟踪者的间隔时间)
最小选举超时:
如果集群中存在Leader时,并且接收到心跳信息之后在最小选举超时时间内接受到请求投票消息,那么将会忽略掉该投票消息。
在分布式系统中,有时候需要对集群中的成员数量进行更新的操作。对于被删除的服务器而言,如果它们没有及时关闭,那么它们将不会接收到心跳信息和日志信息,从而不断发生超时,最后导致任期不断增加(高于集群中所有成员的任期),然后不断向集群中发送请求投票消息。集群中的Leader将变为Follower,集群中将不断开始新的选举,从而扰乱集群的正常运行。
1.3.2.领导选举
选举步骤:
1.集群启动各节点进入随从态,若未监听到领导者,各自进行选举倒计时,倒计时结束成为候选者,并发起第一轮选举,向其他节点发起投票请求(自己会给自己投一票)
2.其他节点如果当前未投过票,就会投票给自己(可能投给了其他候选者)
3.随从节点投票完后立即进入下一选举时间(重置选举时间进入自旋态)
4.领导会发送追加日志消息给随从节点,并且不断给随从节点发送心跳
5.随从者接收心跳后重新进入下一轮选举自旋
6.领导者宕机后,随从者选举超时成为候选者进入第二轮选举,并向其他节点发起投票请求
7.随从节点投票后也进入第二轮选举
注意:
1.领导者也会回复投票请求
2.领导者接收到其他领导者的心跳检测后会让出领导者
3.同一轮投票时,每个节点只能给一个候选节点投票
1.3.3.日志复制
日志复制:
指集群使用raft算法,以日志复制的方式实现一致性
步骤:
1.所有修改数据都必须经过领导者
2.领导者创建节点日志,此时日志是未提交状态,且数据未修改
3.日志不会马上发出,会伴随心跳发送给每一个节点,节点收到心跳后回复
4.当大多数节点回复后领导者提交,数据更新
5.领导者更新成功响应客户端更新成功,并在下一次心跳通知其他节点也提交更新
7.所有节点修改成功后,集群实现一致性
注意:
1.修改数据的请求到达leader后创建日志,但是日志发出是随下一次心跳发出的
2.领导者提交后就会响应客户端修改成功,并在下一个心跳时间告诉其他节点提交
3.如果领导者没有接收到大多数节点的回复,日志不会提交
1.4.paxos算法
Paxos算法是一种分布式一致性算法,用于在一个分布式系统中达成一致性。这个算法被广泛应用于分布式数据库和分布式系统中。Paxos算法主要解决了一个分布式系统中多个节点之间的一致性问题,其中节点之间可能存在网络延迟、消息丢失等问题,这些问题都会导致各个节点之间的状态不一致。
Paxos算法的基本思路是采用一个提案(proposal)来更新系统中的某个值,提案包括两个部分:value和number。其中,value表示待更新的值,number表示提案的编号。Paxos算法通过两个阶段来保证一致性:
阶段一:准备(Prepare)
在准备阶段,一个节点想要更新某个值时,会发起一个准备请求,其中包含了当前提案的编号和待更新的值。其他节点在收到准备请求后,会检查该提案的编号是否大于自己已经收到的最大编号,如果是,则返回“accept”消息,其中包含了该节点的最新值和编号;否则,返回“reject”消息,拒绝该提案。
阶段二:接受(Accept)
在接受阶段,发起节点会根据收到的“accept”消息中的值和编号,生成一个新的提案,并发送给其他节点。其他节点在收到提案后,会检查该提案的编号是否大于自己已经收到的最大编号,如果是,则接受该提案,并更新自己的值;否则,拒绝该提案。
通过这两个阶段的交互,Paxos算法能够保证最终所有节点的值都是一致的,即使存在网络延迟、消息丢失等问题。
Paxos算法的实现比较复杂,需要考虑很多细节问题,例如如何处理重复的提案、如何处理故障节点等。因此,实际应用中通常采用一些开源的实现,例如Apache ZooKeeper和etcd等。
2.BASE理论(最终一致性)
2.1.概述
是对CAP理论的延伸,思想是即使无法做到强一致性(CAP的一致性就是强一致性),但可以采用适当的采取弱一致性,即最终一致性。【保证AP时,无法保证C,但是可以最终一致性】
BASE是指
- 基本可用(Basically Available)
- 基本可用是指分布式系统在出现故障的时候,允许损失部分可用性(例如响应时间、功能上的可用性),允许损失部分可用性。需要注意的是,基本可用绝不等价于系统不可用。
- 响应时间上的损失:正常情况下搜索引擎需要在0.5秒之内返回给用户相应的查询结果,但由于出现故障(比如系统部分机房发生断电或断网故障),查询结果的响应时间增加到了1~2秒。
- 功能上的损失:购物网站在购物高峰(如双十一)时,为了保护系统的稳定性,部分消费者可能会被引导到一个降级页面。
- 基本可用是指分布式系统在出现故障的时候,允许损失部分可用性(例如响应时间、功能上的可用性),允许损失部分可用性。需要注意的是,基本可用绝不等价于系统不可用。
- 软状态(Soft State)
- 软状态是指允许系统存在中间状态,中间状态不会影响系统整体可用性。分布式存储中一般一份数据会有多个副本,允许不同副本同步的延时就是软状态的体现。mysal replication的异步复制也是一种体现。通俗解释就是一致性只有两个状态,成功、失败,软状态是二者之间的状态
- 最终一致性(Eventual Consistency)
- 最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
2.2.案例
创建订单
1)远程锁定库存
2)创建订单
3)扣减积分
当扣减积分异常时,订单可以回滚,但是库存已经锁定无法回滚,所以在最后将锁定的库存释放,达到最终一致性。
2.3.强一致性、弱一致性、最终一致性
强一致性:更新后的数据后续访问能看到(数据强一致,及时更新到所有节点)
弱一致性:容忍部分或全部访问不到(数据不一致,数据未及时同步到所有节点)【软状态,存在不一致的数据】
最终一致性:弱一致性经过一段时间后更新到最新数据【订单创建失败,经过一段时间后释放库存】
四、分布式事务
1.分布式事务概述
分布式事务是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。
分布式事务的方案其实就是根据不同一致性设计的几种不同方案
2. 分布式事务有
分布式事务:2PC、3PC、SAGA、TCC
3. 分布式事务场景
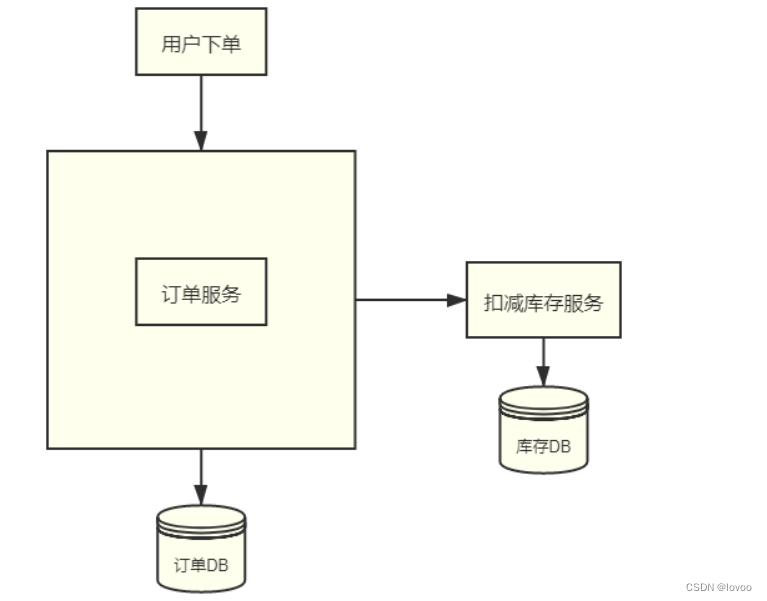

4. 分布式系统出现的异常
异常:
机器宕机、网络异常、消息丢失、消息乱序、数据错误、不可靠的TCP、存储数据丢失
案例:
1.远程服务假失败:
远程服务其实成功了,由于网络故障没有返回
导致:订单回滚,库存成功扣减
2.远程服务执行完成,用户服务扣减积分异常
导致:订单回滚,库存成功扣减
5. 分布式事务的解决方案有如下几种:
- 全局消息:基于可靠消息服务的分布式事务。
- 最大努力通知:TCC 最大努力通知方案。
- 本地消息表:异步确保型事务。
- MQ事务消息:基于消息队列的分布式事务。
- 两阶段锁:基于数据库的两阶段锁。
- 全局事务:基于DTP模型的分布式事务。