目录
第一部分、前言
第二部分、初识数据类型
1、C语言为啥要这么多的数据类型?
2、表格中所占内存的大小是如何计算得到的?
2.1、计算机的内数据存储单位
2.2、关键字sizeof的使用说明(具体后面会更详细的解释)
3、为什么char类型的数值范围是-128~127,为啥不是-127~128?
3.1、整型数据在计算机内的编码方式
3.2、为啥要补码?
3.3、回答char类型的数值范围为啥是-128~127?
4、为啥int和long的数值范围是一样的?
5、这些类型如何输出?
6、如何将一个类型转换成另一个类型?
第三部分、进阶数据类型
1、整型家族
1.1、为什么char和unsigned char属于整型?
1.2、26个大小写英文字母的ASCII码数值
2、浮点家族
第四部分、总结及内容全览
第一部分、前言
该文章是我复习C语言的笔记,笔记中给出的各种问题及解答都是我之前不会的,或者我之前存在疑惑的,或者我新学到的,所以很多细节的地方还希望大家去参考详细的学习资料。
第二部分、初识数据类型
文章是我复习C语言的笔记,所以笔记中给出的各种问题及解答都是我之前不会的,或者我之前存在疑惑的,或者我新学到的,所以很多细节的地方还希望大家去参考详细的学习资料。
| 数据类型 | 名称 | 占内存的大小 | 表达的数值范围 |
| char | 字符数据类型 | 1byte | -128~127 |
| unsigned char | 无符号字符数据类型 | 1byte | 0~255 |
| short(int) | 短整型 | 2byte | -32,768~32,767 |
| unsigned short(int) | 无符号短整型 | 2byte | 0~65535 |
| int | 整形 | 4byte | -2^31~-2^31-1 |
| unsigned int | 无符号的整型 | 4byte | 0~2^32-1 |
| long(int) | 长整型 | 4byte | -2^31~-2^31-1 |
| long long(int) | 更长的整形 | 8byte | -2^63~2^63-1 |
| float | 单精度浮点数 | 4byte | -3.4x10^-38 ~ 3.4x10^38 |
| double | 双精度浮点数 | 8byte | -1.7x10^-308 ~ 1.7x10^308 |
1、C语言为啥要这么多的数据类型?
这么多的数据类型,其实是为了更加丰富的表达出生活中的各种数值,提高空间利用率。也可以这样理解学习C语言主要是为了和计算机沟通,增加这些数据类型能够提高与机器对话的效率。
2、表格中所占内存的大小是如何计算得到的?
2.1、计算机的内数据存储单位
在解决这个问题之前,首先明白下面两个问题:
- 计算机最小的数据存储单位是:字节(Byte)(这个很重要,记住!)
- 计算机最小的数据传输单位是:位/比特(bit)
内存的换算关系如下:
1TB = 1024GB
1GB = 1024MB
1MB = 1024KB
1Kb = 1024byte(字节)
1byte = 8 bit(比特/位)
- 那我又有一个疑问,那32位机和64位机又是什么意思呢?
其实这表示处理器一次处理数据的能力,32位 = 一次能处理32bit位的数据,64位 = 一次能处理64bit为的数据。
2.2、关键字sizeof的使用说明(具体后面会更详细的解释)
关键字sizeof:以字节为单位给出与变量或类型在内存中所占的空间大小。

3、为什么char类型的数值范围是-128~127,为啥不是-127~128?
3.1、整型数据在计算机内的编码方式
计算机中的编码方式主要有原码,反码,补码三种方式。而对于整形来说:数据存放内存中其实存放的是补码。
- 正数的原码、反码、补码三者一致;
例如:int a = 666
原码 = 反码 = 补码 = 00000000 00000000 00000010 10011010
- 负数的补码 = 原码符号位不变,取反再加1;
例如:int a = - 666
原码 = 10000000 00000000 00000010 10011010
反码 = 111111111 111111111 111111101 01100101
补码 = 111111111 111111111 111111101 01100110
- 得到了补码,怎么将补码又变成原码呢?
法一、原码 = 补码符号位不变,取反再加1;(好记)
补码 = 111111111 111111111 111111101 01100110
补码的反码 = 10000000 00000000 00000010 10011001
原码 = 10000000 00000000 00000010 10011010
法二、逆过程推算,原码 = 补码减1,符号位不变再取反 ;(不好记)
补码 = 111111111 111111111 111111101 01100110
补码减一 = 111111111 111111111 111111101 01100101
原码 = 10000000 00000000 00000010 10011010
3.2、为啥要补码?
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理;同时,加法和减法也可以统一处理(CPU只有加法器减法运算是通过转化成加法运算来实现的)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
- 为啥说补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路?
由上述补码求反码的反码的方法一可知:对于负数,其补码 = 原码符号位不变,取反再加1;原码 = 补码符号位不变,取反再加1;会发现这个原码到补码,补码再到原码这个过程是一致的。
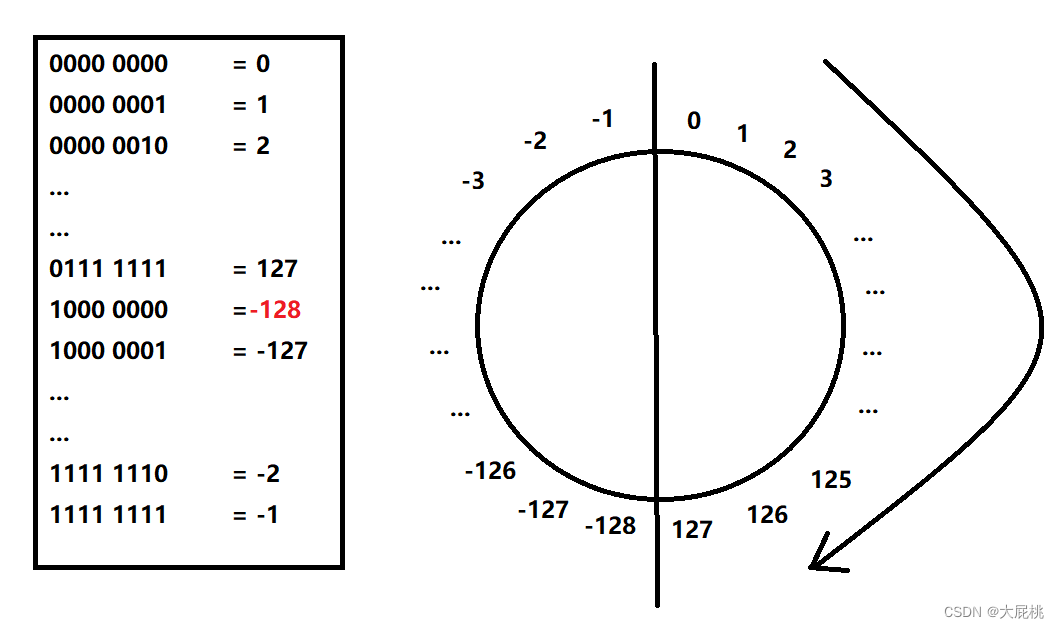
3.3、回答char类型的数值范围为啥是-128~127?
char大小为1个字节,最高位表示符号位,又因为0000 0000表示0,那么1000 0000的最高位为符号位,总不能它也表示为0,为了提高存储效率,计算机就直接将1000 0000翻译为-128。
下图可以帮助理解:
4、为啥int和long的数值范围是一样的?
正常理解下long的数值范围应该是比int数值范围要更广,但是表格中为啥一致呢?
其实这个不是绝对的,这是取决于当前的编译器,在vs2017的编译器中默认int和long的数据类型大小一致。
5、这些类型如何输出?
| %d | int |
| %c | char |
| %s | 字符串 |
| %u | unsigned int |
| %f | float |
| %lf | double |
| %p | 打印地址printf("%p",&a);//观察a的地址,以16进制打印 |
| %x | printf("%x",50);16格式进制打印 |
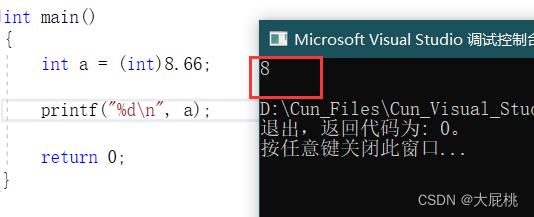
6、如何将一个类型转换成另一个类型?
实现类型之间的转换可以通过强制类型转换的方法来实现。如下图,8.66为浮点类型的数据,通过:(类型)变量 的方式来实现强制类型转换。
第三部分、进阶数据类型
关于数据类型进阶的知识就会设计到数据存储的问题,数据存储的文章如下:
1、整型家族
下面都为整型家族的数据类型。
char = signed char//大多数编译器都是这么规定的,但是C99没有明确规定
unsigned char
short = signed short [int]
unsigned short [int]
int = signed int
unsigned int
long = signed long [int]
unsigned long [int]1.1、为什么char和unsigned char属于整型?
这也是我之前很疑惑的地方,其实这和计算器的存储有关系,根据ASCII码表可以知道,每个英文字母都对应一个ASCII码的数值,而这些数值都是整数。我个人的理解是字符其实在内存中是以整数的形式进行保存的。因此字符类型归属于整型家族。
1.2、26个大小写英文字母的ASCII码数值
做个记录,方便自己查找。
| 大写字母 | ASCII值 | 小写字母 | ASCII值 |
| A | 65 | a | 97 |
| B | 66 | b | 98 |
| C | 67 | c | 99 |
| D | 68 | d | 100 |
| E | 69 | e | 101 |
| F | 70 | f | 102 |
| G | 71 | g | 103 |
| H | 72 | h | 104 |
| I | 73 | i | 105 |
| J | 74 | j | 106 |
| K | 75 | k | 107 |
| L | 76 | l | 108 |
| M | 77 | m | 109 |
| N | 78 | n | 110 |
| O | 79 | o | 111 |
| P | 80 | p | 112 |
| Q | 81 | q | 113 |
| R | 82 | r | 114 |
| S | 83 | s | 115 |
| T | 84 | t | 116 |
| U | 85 | u | 117 |
| V | 86 | v | 118 |
| W | 87 | w | 119 |
| X | 88 | x | 120 |
| Y | 89 | y | 121 |
| Z | 90 | z | 122 |
2、浮点家族
float
double第四部分、总结及内容全览
数据类型这里只是简单后复习了一下,以上为博主复习总结的一些知识点,有很多的不足,还希望读者见谅。