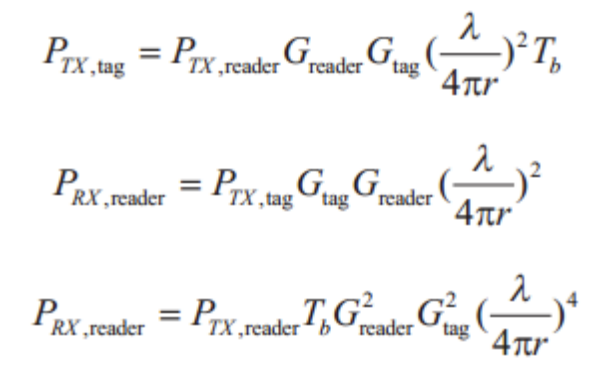文章目录
- PEFAT: Boosting Semi-supervised Medical Image Classification via Pseudo-loss Estimation and Feature Adversarial Training
- 摘要
- 本文方法
- Feature Adversarial Training
- 实验结果
PEFAT: Boosting Semi-supervised Medical Image Classification via Pseudo-loss Estimation and Feature Adversarial Training
摘要

伪标记方法已被证明对计算机视觉和医学成像中的半监督学习(SSL)方案是有益的。大多数工作都致力于从模型预测概率的角度寻找具有高置信度伪标签的样本。而如果不仔细调整阈值,这种方式可能导致包含错误的伪标记数据。此外,低置信度概率样本经常被忽视,并且没有充分发挥其潜力。
本文方法
- 提出了一种新的伪损失估计和特征对抗训练半监督框架,称为PEFAT,以从损失分布建模和对抗训练的角度提高多类别和多标签医学图像分类的性能
- 开发了一种值得信赖的数据选择方案来分割高质量的伪标记集,其灵感来自于可分割的伪损失假设,即干净数据往往显示出较低的损失,而噪声数据则相反
- 提出了一种新的正则化方法,通过在特征级注入对抗性噪声来平滑决策边界,从而从这些样本中学习判别信息,而不是直接丢弃具有低质量伪标签的样本。
代码地址
本文方法
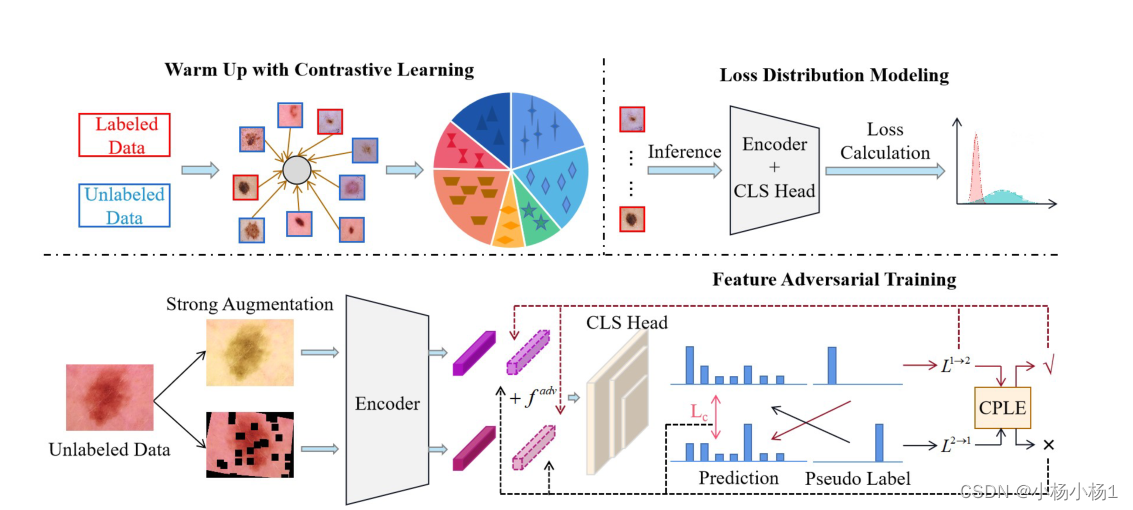
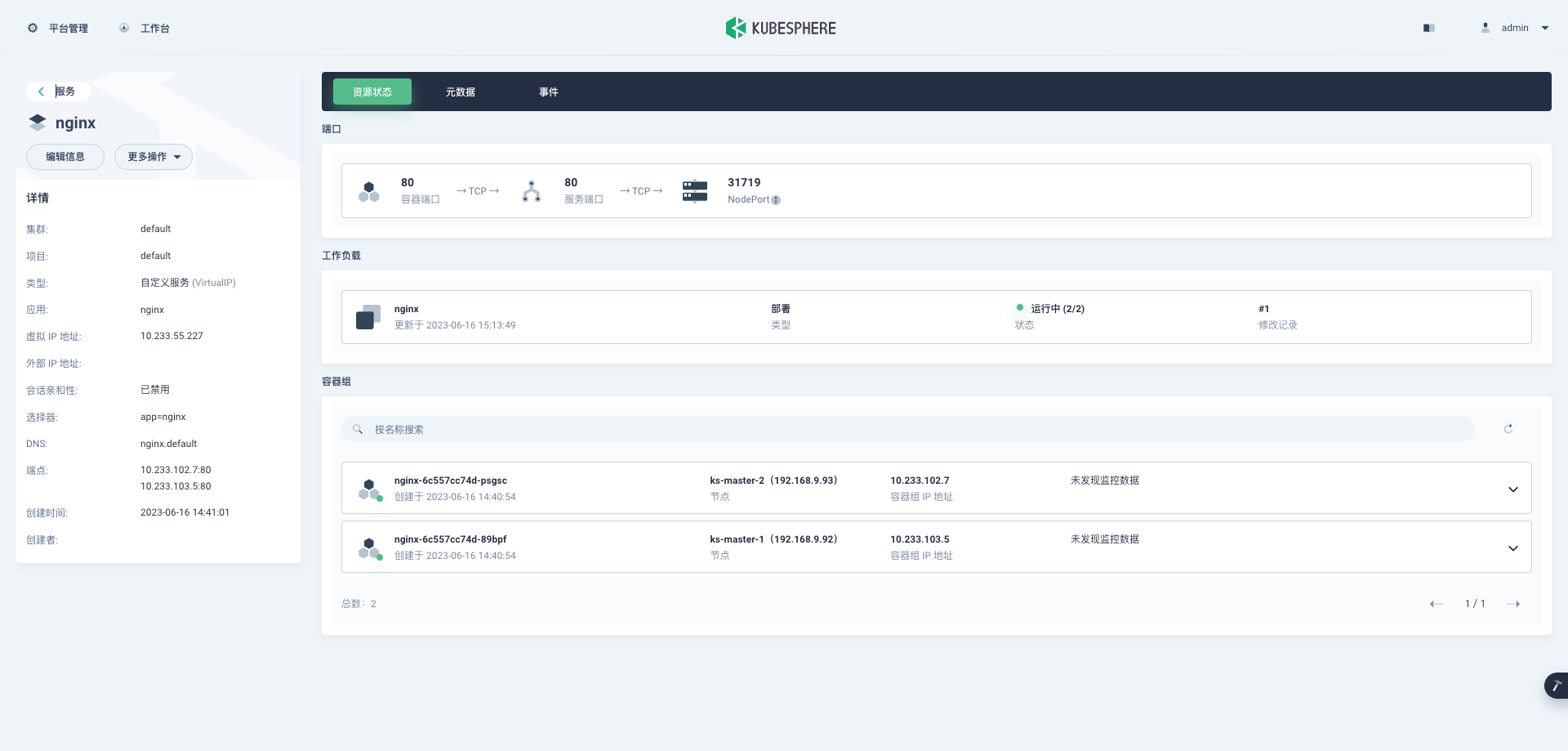
提出的PEFAT的说明:
首先通过对训练数据的对比学习来预热模型,以学习无偏表示
然后,建立了一个双分量GMM来构造在标记数据上计算的损失分布
关于未标记数据的利用,我们使用交叉伪损失估计(CPLE)来进行可信的伪标记数据探索。除此之外,对抗性噪声被注入到特征级别,以更好地进行未标记数据挖掘。
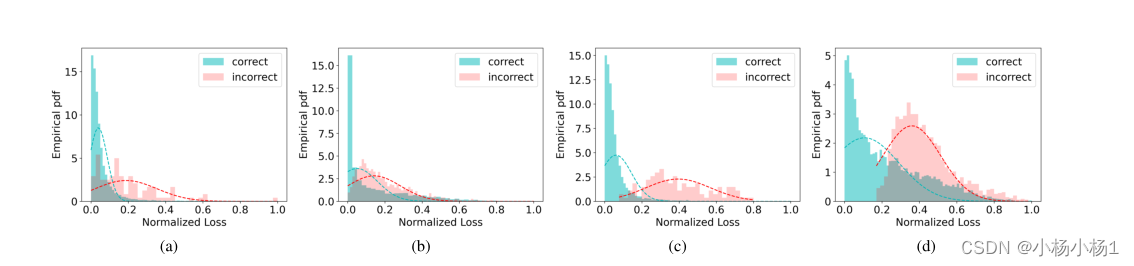
损失分布的拟合GMM的经验概率密度函数(PDF)
(a) 使用FixMatch进行训练,并对标记数据进行损失分配
(b) 使用FixMatch进行训练,并对验证数据进行损失分配
(c) 对标记数据进行PEFAT和损失分布训练
(d) 对PEFAT和验证数据损失分布进行训练
(a) 和(b)给出了零偏损失分布,这主要归因于过度自信预测
(c)和(d)给出了具有正确和不正确伪标签的伪标签数据的可分离分布,验证了交叉伪损失估计的有效性
Feature Adversarial Training
尽管我们可以通过交叉伪丢失估计(CPLE)有效地收集几乎干净的伪标记集,但其余未选择数据对于SSL训练也是有用的。受对抗性训练的启发,添加对抗性扰动有利于平滑决策边界,这是一种实用的策略,尤其是在处理边缘分布样本时。在这项工作中,我们提出了特征对抗训练(FA T),它在特征级别注入有针对性的对抗性噪声,旨在有效地探索未标记样本中的信息。
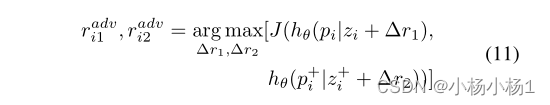
J是Kullback-Leibler散度
r是对抗性噪声
∆是随机噪声
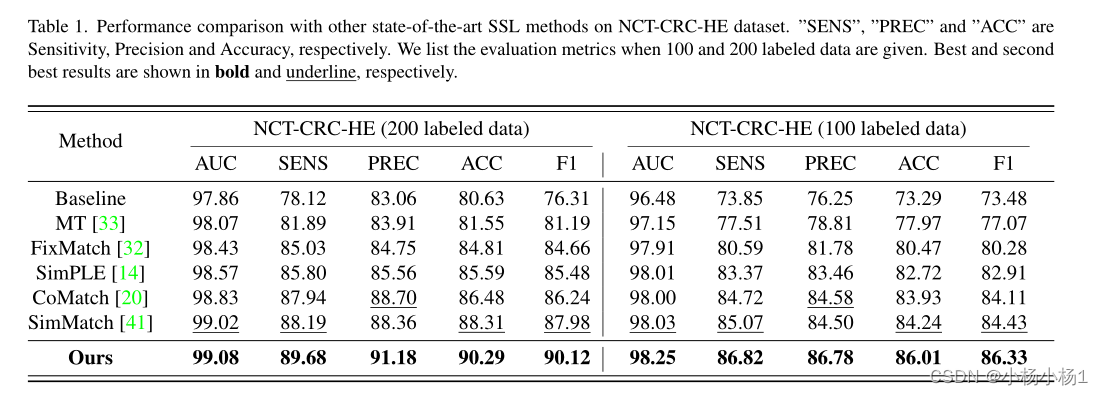
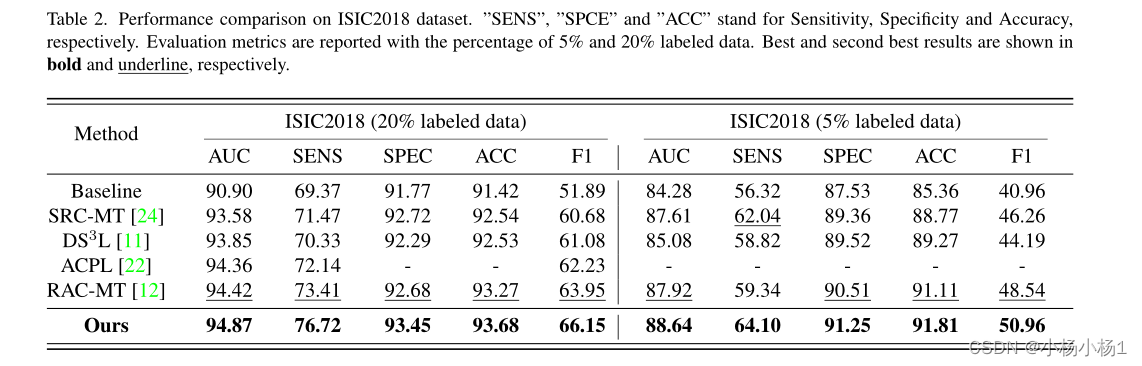
实验结果