作为在编码这块自留地里深耕多年的码农,凭借着自认为丰富的经验加上专业领域的博览群书,自觉对程序优化还是有点感觉、有点心得的。但最近的经历让我不得不感慨,“不听老人言,吃亏在眼前“还是很有道理的。
软件优化这件事,说难也不难,说不难也难。怎么讲呢,说不难是因为通过一些简单的技巧,就能获得不错的结果。比如,结合编译器的选项,现代处理器的高性能,以及一些专业书籍中提供的闭坑指南,基本就能取得不错的效果。说难,是因为同所有的行业一样,从良好到优秀,是一个量变到质变的过程,难度就会递增,而从优秀到卓越,更是一种突破,不是努努力就可以达到的。这就好比,从60分到80分,努力还是主要因素,而从90到100,就需要天赋加持了。这方面,算法大牛高德纳就是最好的例子。在硅谷科学家、大师圈子中的编程比赛,高德纳常年霸榜,说明要做好程序优化,从底层到上层,从逻辑到数学,精湛的技能一样都不能少。现实中,大家要么缺乏底层机制的深刻理解,要么缺乏算法训练,十八般武艺,七十二绝技俱佳的,少之又少。
那有人就纳闷了。你即说简单,又说不简单,那到底是能做还是不能做?答案就是根据二八原理,咱们做到80分就可以了。也就是说,努努力还是可以做到的,而且最终效果也还能做的不错。剩下的那一截就留给优秀的人吧。
回到主线,就要谈谈具体实践的问题了。如标题所述,具体实践中,切不可盲目优化。缘木求鱼也就罢了,没优化至少还能保住低,南辕北辙就得不偿失了,没优化反倒退化,那是万万不可接受的。所以一些基本的原则还是需要掌握的。关于这些基本的原则,博主在很早之前发布的一篇博客里有所介绍,感兴趣的读者可以先看看。
嵌入式Linux开发调优之二:应用程序_龙赤子的博客-CSDN博客
今天我要说的是一个具体的案例,一个因为盲目优化,而事倍功半的故事。注意,是事倍功半,而不是事半功倍哦。
在具体介绍案例之前,插播一条法则:优化第一法则。在优化之前,先分析系统的瓶颈。
无论我们是平凡码农还是业界大牛,上述第一法则是一定需要践行的。好了,下面我就介绍一下故事的背景。
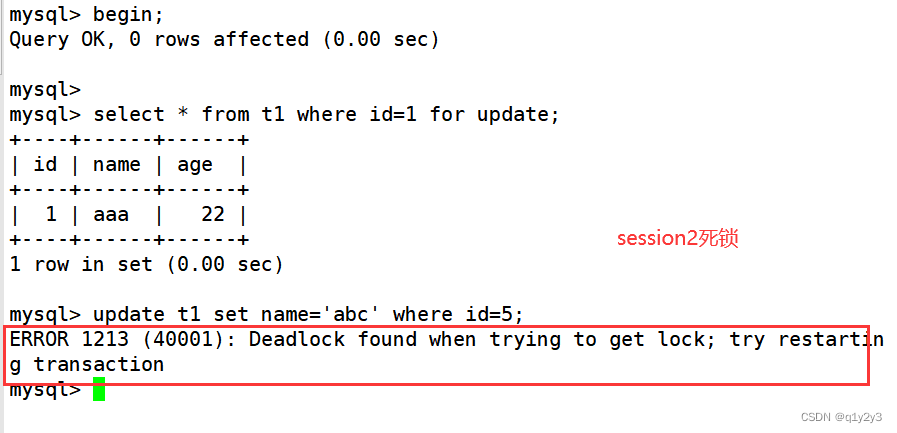
博主最近在开发一个相对高实时性要求的程序。这个程序需要在微妙级别的时间内完成算法处理。算法基本上都是一些数学公式的代码转换,参与运算的基本都是浮点数。当博主添加了数据均衡的处理后,时间不够用了。为了实时完成算法,功能都是在中断中进行的。结果,当算法占用时间超过中断间隔后,下一次的中断就可能被阻住,其他非中断中处理的逻辑,基本就都歇菜了。开始还以为是哪里死锁或者卡死了,最后才发现是中断处理耗时太长,卡住了非中断逻辑。调整中断时间后,功能基本恢复。
以上就是简单的背景。当时想着,应该是最后加的处理,进行了大量浮点乘除运算,占用了过多的处理器时间,导致了异常结果。后面对浮点数运算进行优化,问题应该能够应对。当时心里也有了直接的方法,就是浮点转整形,另外把一些不需要每次计算的值,提前计算了,以此减少浮点运算时间。心里有底后,就继续完成功能。直到这两天,终于有时间可以处理优化的问题了。这样选择,也是受Windows NT之父卡特勒的影响,据说卡特勒的原则是先实现功能,后优化。我也是想着,功能验证通了,优化就可以更加专心。否则,还不知道整体是否可以跑通,心里总是有个疙瘩的。
具体的优化,就如前面所述。对浮点转整形后,发现效果不理想。通过查资料,分析代码,包括分析汇编验证,确定CPU支持浮点协处理器,也就是指令级别支持浮点运算的,编译选项中也支持了浮点的相关选项,所以,转整形其实没有什么必要(这一点,大家在实际中可以查看生成的汇编代码来确认)。浮点转整形,其实是没有浮点协处理器之前的优化招数,现代CPU上,这一招基本已经过时了。所以读书时多思考,多验证,就会有额外的收获。如果再深挖,我们会发现,因为处理器已经原生支持了浮点运算,此时转整形反而多此一举,适得其反,让运行更慢了,因为转换本身也消耗了额外的汇编指令。这一点可能超出很多人的直觉。
排除浮点数的原因后,方向就转向如何减少汇编指令,特别是循环中的。还别说,这一招初看还挺管用。将重复计算的东西移除循环体,使用部分全局变量代替函数,测试下来,外部执行从最开始的每五秒13000次提升到了22000次。看这效果杠杠的,人也如打了一针强心剂,准备继续修改,目标是达到25000次,基本实现翻倍的效果。
结果,现实打脸了。再继续修改测试,发现提升很有限,似乎到了极限。总不能自己实现数学库里的函数吧,别逼我用汇编实现。本以为爬到一个山头后,下一个山头必将是新目标,突然发现路没有了。
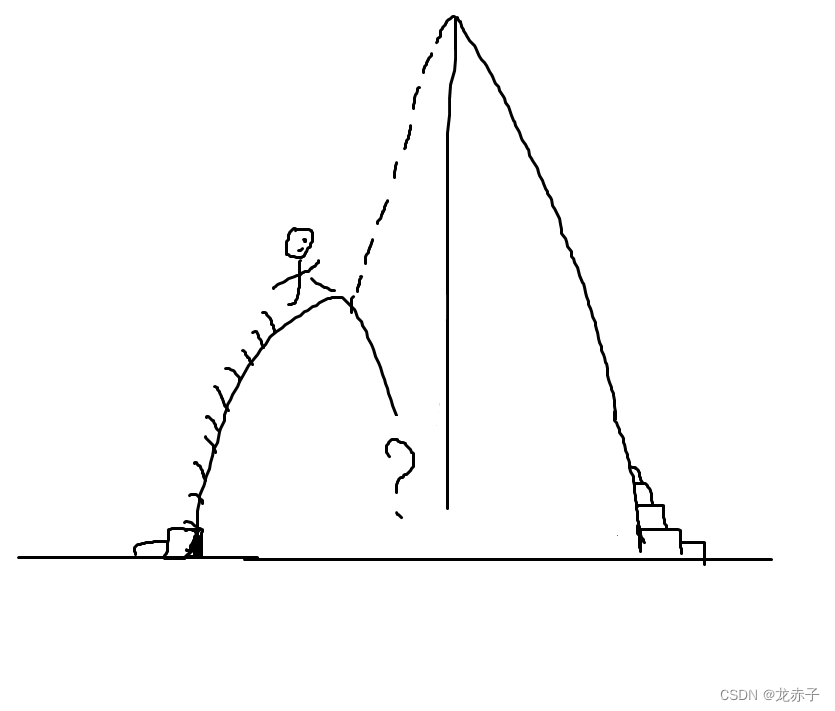
就在这样的迷茫中,对代码进行各种修改尝试。反复尝试没有效果后,告诉自己静下来思考思考,是真的到极限了还是路没有走对。也许你该从另一边爬才对。
就在思考过程中,一段访问外设内存的代码引起了我的注意。会不会是这段代码导致?为了不影响测试,将其进行了改写,部分使用构造数据,减少了外部访问的次数。再次测试,发现之前的计数可以飙升到70000次以上。这超乎了我的想象。难道我之前的优化都白做了?根据现在的测试结果,看来是如此。为啥这段代码会造成严重的性能问题?可能与设备时钟有关。我估算了一下,周期为20纳秒的时钟,一个存储地址的访问,很容易到百纳秒级别,这样1K的空间,少说就需要几十微妙,CPU把时间耗在这里,自然没时间干别的事情。这个结果也完全打破了我对CPU的认知,其实一开始出现性能问题时,心中就有所疑惑,即便是微妙级别,CPU也不至于这么不经敲打。现在来看,冤枉CPU了。
多次测试确认后,决定从新的方向重新入手来优化这个问题。
写这篇博文时,问题还没有得到完全解决。优化访问设备的代码仍在调测中。目前的改进方向包括调整对Cache的使用策略以及增加DMA的使用。另外,总线的配置也是一个改进方向,比如优先级等。后续等问题彻底解决后,再来补充下篇详细介绍过程。
写这个上篇,主要是通过这个过程,再强化一下第一法则的重要性。有时候,你的感觉跟实际可能就是差那么几微米的神经元来帮你关联一下。