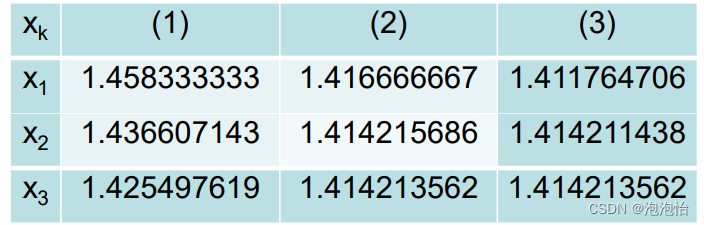
文章目录
- 程序是如何执行的?
- 翻译
- 预编译
- 条件编译
- 文件的包含
- 嵌套引用
- 不同的引用方式
- 预定义符号
- 编译
- 汇编
- 链接
- 运行
程序是如何执行的?
有时候会问自己,程序的运行是那么简单的事情吗?
我鼠标点到 visual studio 上,程序就跑起来了,然后在界面就能看到我们想要看到的输出或者是我们不想看到的错误
实际上,程序的运行会经过一个复杂的阶段之后才会被执行
这个阶段就是翻译

而翻译中还有许多小步骤等着我们去实现
翻译
整个翻译的过程,可以分成两个大的步骤
分别是编译和链接

我们的源文件,通过编译器编译可以生成目标文件(.o为后缀名的二进制文件)
所有的源文件转换为目标文件后
随后使用链接器,将工程中的多个目标文件,以及头文件引入的标准库,链接生成一个可执行程序
编译本身可以分成多个步骤,分别是
预编译,编译和汇编

而每一步都有独特的作用
预编译
预编译,也叫编译预处理
预编译实现的是一种文本操作
他将 define 的宏定义替代
并且执行或者忽略条件编译
并且将头文件替换进到源文件中
举个简单的例子
#define MAX 100
int main()
{
printf("%d",MAX);
return 0;
}
其中 define 定义的 MAX 会在预编译的环节就被替换成100
int main()
{
printf("%d",100);
return 0;
}
相当于复制粘贴
条件编译
有时候,有一些代码我们不想让他们运行,但是又不想删除他们
为了不让他们占用我们的使用空间,我们可以有选择地去编译他们
C语言给了几个条件编译指令
| 编译指令 | 功能 |
|---|---|
| #if A | 若条件A成立则编译 |
| #elif B | 如果if A 不成立,elif B条件成立则进行编译 |
| #else | 当上述条件都不成立,就进行编译 |
| #endif | 结束条件编译 |
| #ifdef DEFINE | 如果定义了 DEFINE(可以是任意内容) 则进行编译 |
| #ifndef DEFINE | 如果没有定义 DEFINE,则进行编译 |
#define MAX 1
int main()
{
#if MAX
printf("%d\n",MAX);
#endif
printf("%d",10);
return 0;
}
如果定义了MAX 那么程序预编译后会变成这样
#define MAX 1
int main()
{
printf("%d\n",1);
printf("%d",10);
return 0;
}
若没有定义 MAX 则程序预编译后 第一个 printf 会被删除
int main()
{
printf("%d",10);
return 0;
}
这个就是条件编译
条件编译的使用方式和 C语言的选择语句十分相似,条件编译也是可以嵌套的。
都是选择处理,但是条件编译是在预编译过程中直接对代码进行处理,后面的编译,汇编,链接都没有那些代码,大大节省了空间
不过每次条件编译都需要在最后加 #endif 来结束编译
文件的包含
预编译还有一个功能就是把引用的头文件拷贝到程序的文本里面
举个例子
如果在源文件中你
#include<stdio.h>
int main()
{
return 0;
}
对应的引用的位置通过预编译会被替换为整个库文件内容,实际显示效果就会是这样
<stdio.h> 的 文件内容(一大堆)
int main()
{
return 0;
}
嵌套引用
那就意味着,如果你这样写代码
#include<stdio.h>
#include<stdio.h>
#include<stdio.h>
int main()
{
return 0;
}
那对应 的头文件引用的位置,就会被拷贝 三次,再通过后面的 编译汇编过程,相同的代码就要编译汇编三次,相当浪费时间
或许你会说: 我怎么可能这样写代码呢?
但是你可能无意间就写成了这样
尤其是嵌套文件包含的情况
如果你是这样文件的话,就会导致嵌套文件包含
# include"comm.h"
# include"test.h"
int main()
{
return 0;
}
但是,comm .h 和 test .h 中内部又引用了头文件 fin.h
那在编译中,fin.h 就会被编译两次
如何避免这个问题,之前我们就讲了条件编译
#ifndef
#define __FIN_H__
#endif
通过这个条件编译,就能够达到一个效果
如果 fin.h 没有引用,就引用这个头文件(define FIN_H)
如果 已经引用 后面就不用再进行引用(不用 define FIN_H)
条件编译 #pragma once 也能达到同样的效果
他们都为了避免头文件的重复引用
不同的引用方式
曾经我们在引用头文件时候,有两种不同的引用方式
#include <stdio.h>
#include "file.h"
一种是 <> 一种是 " "
两种的找到头文件的机制不同
利用 <> 来引用头文件,是直接在头文件的标准路径下查找(编译器自动安装放在某个文件夹的路径)
一种是利用 " " 来找,这个情况,首先编译器会在源文件所在的目录下查找,如果没找到,就去标准路径下查找,会查找两个地方
预定义符号
补充一个小知识点,C语言有一些内置的预定义符号
| FILE | //进行编译的源文件 |
| LINE | //文件当前的行号 |
| DATE | //文件被编译的日期 |
| TIME | //文件被编译的时间 |
| STDC | //如果编译器遵循ANSI C,其值为1,否则未定义 |
这些符号我们是可以直接打印的,除了 STDC 可能因为编译器不是完全按照 ANSI 导致出错
因为显示的问题 , 前后有两个 __ 博客显示不出来,具体看看下面的代码
printf("%s,%d",__FILE__, __LINE__);
编译
现在我们已经能够得到这幅图,随后就是编译的过程

编译过程主要进行什么操作呢?
将 .c 的文本文件 变成 .s 的汇编文件
就是 里面我们的 c 语言 会被翻译 成对应 的 汇编语言
既然是翻译的过程
就要分析里面的语法,词法,语义
就有三个步骤
词法分析,语法分析,词法分析
还有一个比较重要步骤就是符号汇总,就是汇总全局符号(如 全局变量,函数等)的符号
比如你的 源文件 A/.c 中 定义了 main 函数,引用了 sum 函数 那文件 A.s 就会生成符号 _main,_sum
源文件 B.c 中定义 sum 函数 文件 B.s 会生成 _sum 的符号
汇编
我们已经经过了这些过程

现在我们能够得到一个.s 的汇编文件 ,最后我们要得到一个可执行的.o目标文件
汇编的作用就是得到一个独立的二进制.o文件
汇编会大概会经过两个过程
- 得到符号表
- 将汇编语言翻译成二进制语言,得到单独二进制文件
这里主要讲一下符号表是个什么东西
之前在汇编过程中,我们得到了符号汇总
假设我们的工程有两个源文件
一个是 main .c 文件
extern int sum(int,int);
int main()
{
sum(1,2);
return 0;
}
一个是 sum.c 文件
int sum(int a,int b)
{
return a+b;
}
通过编译汇编后,会得到符号表
符号表包含 符号名称 和 符号地址

符号表,我的理解
是能够引导执行文件到对应地址执行代码的工具
链接
到此为止,我们已经将每一个单独的文件都编译完了

最后一步就是链接

链接实现两种功能
- 合并段表
- 符号表的合并和重定位
段表可以理解为程序段的整合,但这不是重点
重要的是 符号表
回到这幅图

还是这个例子,链接就会把两个文件整合到一起
符号表示用来帮助找到运行程序的,main 中的 sum 程序没有内容,在运行时就要借助整合后的符号表跑到 sum.c 文件的 sum 函数的地址运行
而链接就是删除没有用的 main .c 的sum 的符号,然后给有用的 sum.c 的 sum函数一个空间,并且保存这个地址
main.c 的符号会包含 _sum 但是在main 文件中,sum 没有任何意义,如果找不到对应的运行程序,链接就会报错,导致 Link 的链接错误
最后我们就能得到这个

运行
一共四步
- 程序载入内存,有操作系统,操作系统自动载入,没有操作系统,手动载入
- 调用main函数
- 执行代码,用栈储存局部变量和函数调用,并且用静态内存储静态变量
- 终止程序