【前言】随着ChatGPT席卷自然语言处理,Facebook凭借着Segment Anything在CV圈也算扳回一城。迄今为止,github的star已经超过3万,火的可谓一塌糊涂。作为AI菜鸟,可不得自己爬到巨人肩膀上瞅一瞅~
论文地址:https://arxiv.org/abs/2304.02643
代码地址:GitHub - facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model.
demo地址:
Segment Anything | Meta AI
1. 引言
作者首先阐述了此项研究的目的,那就是开发一个可提示的(promptable)模型,在大型数据集上通过特定的任务对其进行预训练,使之具有很强的泛化性,即能够通过提示(prompt)解决新数据集上的一系列下游分割任务。
实现此目的需要解决的问题包括:
- 什么样的任务可以具有zero-shot的泛化性?
- 对应的网络结构是怎样的?
- 什么样的数据集能够驱动此类任务和模型?
通过分析上述问题,作者提出了一套解决思路:首先需要定义一个可提示的分割任务(a promptable segmentation task),该任务可提供强大的预训练基础以支持一系列的下游应用。其次,开发一个支持灵活提示(flexible prompting)并能够实时输出分割掩膜的模型。最后需要一个具有丰富多样性的大规模数据集用于模型训练。
总言之,集齐任务(Task)、模型(Model)、数据(Data)三剑客,就可以召唤zero-shot的应用了。如下图所示。
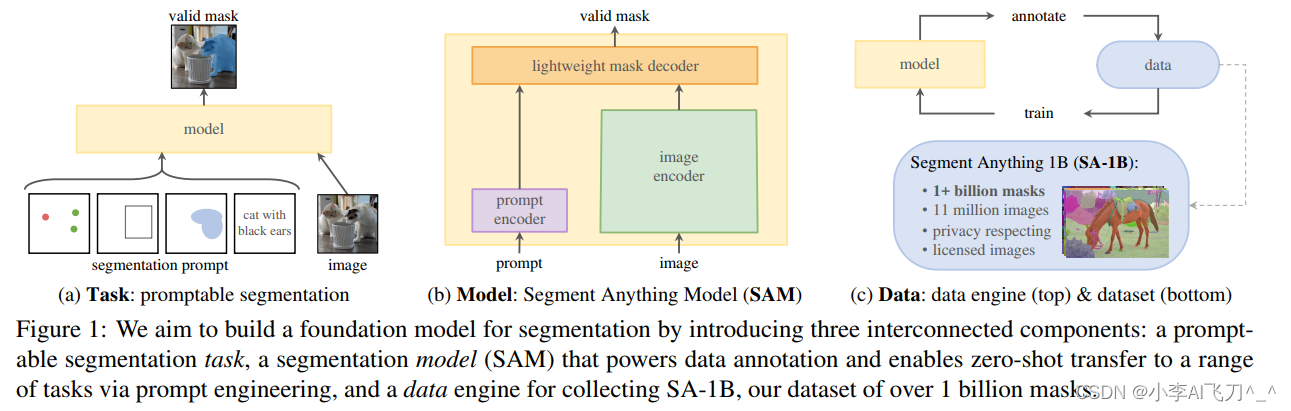
- 任务Task:建立一个可提示的分割任务,使得对于点、框选、mask、文本等任意形式的分割提示,都可返回一个有效的分割掩膜。即使输入的提示比较模棱两可,模型都能输出较合理的分割结果(比如一个点可能指向衣服,也可能指向人,输出的掩膜必须是这些潜在目标中的某一个,而不是随意生成的)。
- 模型Model:模型需要支持灵活的提示并能实时计算交互生成的掩膜,因此作者设计了一个图像编码器和一个提示编码器,然后通过一个轻量化的掩膜解码器进行结合并预测输出分割掩膜。
- 数据Data:强泛化性的模型需要丰富多样性的大规模数据集,为此作者建立一个数据引擎,通过人工(全人工)、半自动(人工校验)、全自动三个阶段生成数据,构建了数据集SA-1B,包括超过1.1千万的影像和10亿掩膜,是现有数据集规模的400多倍。
下面分别具体介绍这三部分的内容。
2. Segment Anything Task
在NLP的翻译任务中,提示prompt为下一个文本(token),由此可以设计分割任务的提示,即前景/背景的点、边界框、掩膜或文本等任何可以表明分割目标的信息。对于给定任意提示,模型都可以返回一个有效的分割掩膜(“有效”可以简单理解为当一个提示是模棱两可的时候都能得到合理的掩膜输出)。

【预训练】该分割任务需要结合一系列提示(点、边界框、掩膜或文本等)进行模型预训练,并将模型输出结果与真实结果进行对比。与交互式分割不同,本任务针对任意的提示都可预测一个有效的掩膜,因此需要选择特定的模型和训练损失函数。
【Zero-shot transfer】因为该预训练模型在推理时可对任何提示作出响应,因此可结合相应的提示完成下游任务。
【相关任务】分割是一个广泛的领域,包括交互式分割、语义分割、实例分割、目标检测、前景分割等。这个可提示的分割任务的目标是建立一个适用于大多数分割任务的通用模型,能够作为一个组件在新的、不同的任务上进行推理。
3. Segment Anything Model
该模型基于Transformer结构,由图像编码器(Image Encoder)、提示编码器(Prompt Encoder)和掩膜解码器(Mask Decoder)组成。
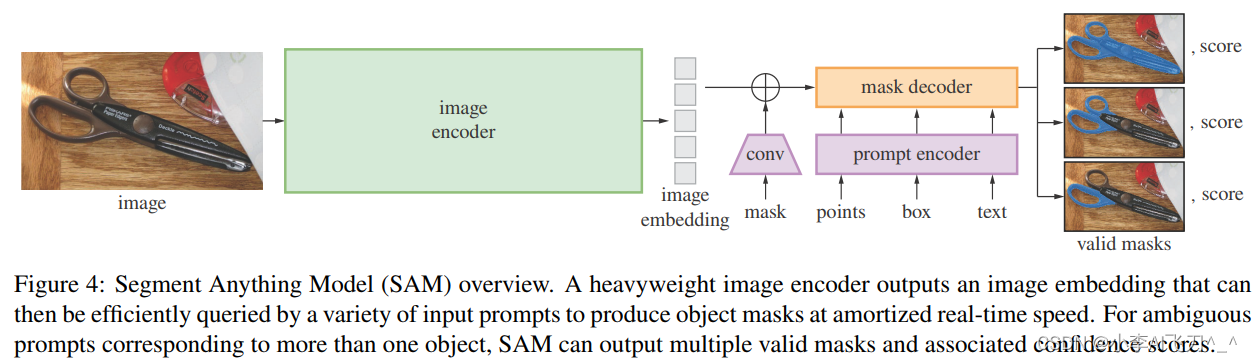
【Image Encoder】使用MAE预训练的ViT模型处理高分辨率的输入。
【Prompt Encoder】通过位置编码表示点和框(离散的),并对不同的提示进行求和。密集的提示(masks)采用卷积进行编码并使用image embedding进行逐元素累加。
【Mask Decoder】将image embedding、 prompt embeddings以及输出的token映射为mask掩膜。由一个transformer解码块后接一个动态掩膜预测头组成。
【模糊输出的解决办法】针对单个提示,模型可存在多个输出(3种输出足够解决大多数问题)。在训练时,只对最小loss的掩膜进行后向传播。最后可通过置信度对输出的每个mask进行排序。
【效率】在CPU的浏览器上可达50ms,支持无缝实时交互。
【训练】模型损失函数为 focal loss 和 dice loss的线性组合。
4. Segment Anything Data Engine
【人工阶段】通过基于SAM的交互式标注工具进行标注并优化,标注时没有给掩膜赋予标签信息。在这个阶段,SAM首先通过常见公开的分割数据集进行训练,提供非精确的掩膜信息(此处SAM的作用类似于EISeg交互式标注工具),并对掩膜进行优化,然后仅采用优化后新生成的标注数据进行再次训练。六次迭代训练后,共生成了12万张图像的430万掩膜。
【半自动阶段】首先自动检测显著的目标,然后人工校正未被标注的目标,达到增加样本多样性的目的。迭代训练后共生成了18万张图像的590万掩膜。
【全自动阶段】自动化的基础是: ①大规模、多样性的掩膜样本数据提升了模型的性能;②开发了一个模糊感知模型,即使存在多种可能的结果,也能有合理的输出。
具体地,通过生成32x32的格网,并在每个格网点预测一系列对应的有效目标掩膜而实现。输出结果采用(IOU=0.5)+NMS进行生成,共计11亿的高质量掩膜。
5. Segment Anything Dataset
通过三个阶段生成了数据集SA-1B,该数据集包括:
- 影像:1.1千万张,通过下采样保证最短边长为1500。
- 掩膜:11亿,99.1%为全自动生成(SA-1B只包含全自动生成的数据)。
- 掩膜质量:随机采样500张图,并采用交互式工具修正,然后通过IOU进行结果比对,95%影像对的IOU精度高于90%。
后面作者也采用了一系列方式来验证SA-1B的质量和可靠性,以及该模型在不同任务中的应用效果,可参见文章第5-7章。一句话言之就是构建了一个非常大规模、高质量的分割数据集和一个具有强泛化性的支持可提示任务的模型。
6. Discussion
- 该模型可作为计算机视觉的基准模型(foundation model)并用于下游任务。
- 通过创建SAM与其他组件的接口,使得SAM具有较强的可集成性。
- SAM具有泛化性和通用性,并能够实时处理提示信息。