也写到第八了 ~~ 这次还是和mac相关哦~~
先吹吹,苹果亲自下场优化,在iPhone、iPad、Mac等设备上以惊人的速度运行Stable Diffusion就是这么简单。
输入一句话就能生成图像的 Stable Diffusion 已经火爆数月。它是一个开源模型,而且在消费级 GPU 上就能运行,是一项普通人就能接触到的「黑科技」。
在该模型走红之初,就有人尝试将其移植到苹果设备上运行,比如 M1 Mac、iPhone 14 Pro,并把教程传授给大家。
但令人没想到的是,前几天,苹果竟亲自下场了,手把手教大家如何直接将 Stable Diffusion 模型转换为自家 iPhone、iPad 和 Mac 可以运行的版本。
以下是生成结果示例:
 在苹果设备上运行 Stable Diffusion 和 Core ML + diffusers 生成的图像。
在苹果设备上运行 Stable Diffusion 和 Core ML + diffusers 生成的图像。
苹果在 macOS 13.1 和 iOS 16.2 中发布了针对 Stable Diffusion 的 Core ML 优化,并通过一个代码库对部署过程进行了详细讲解。
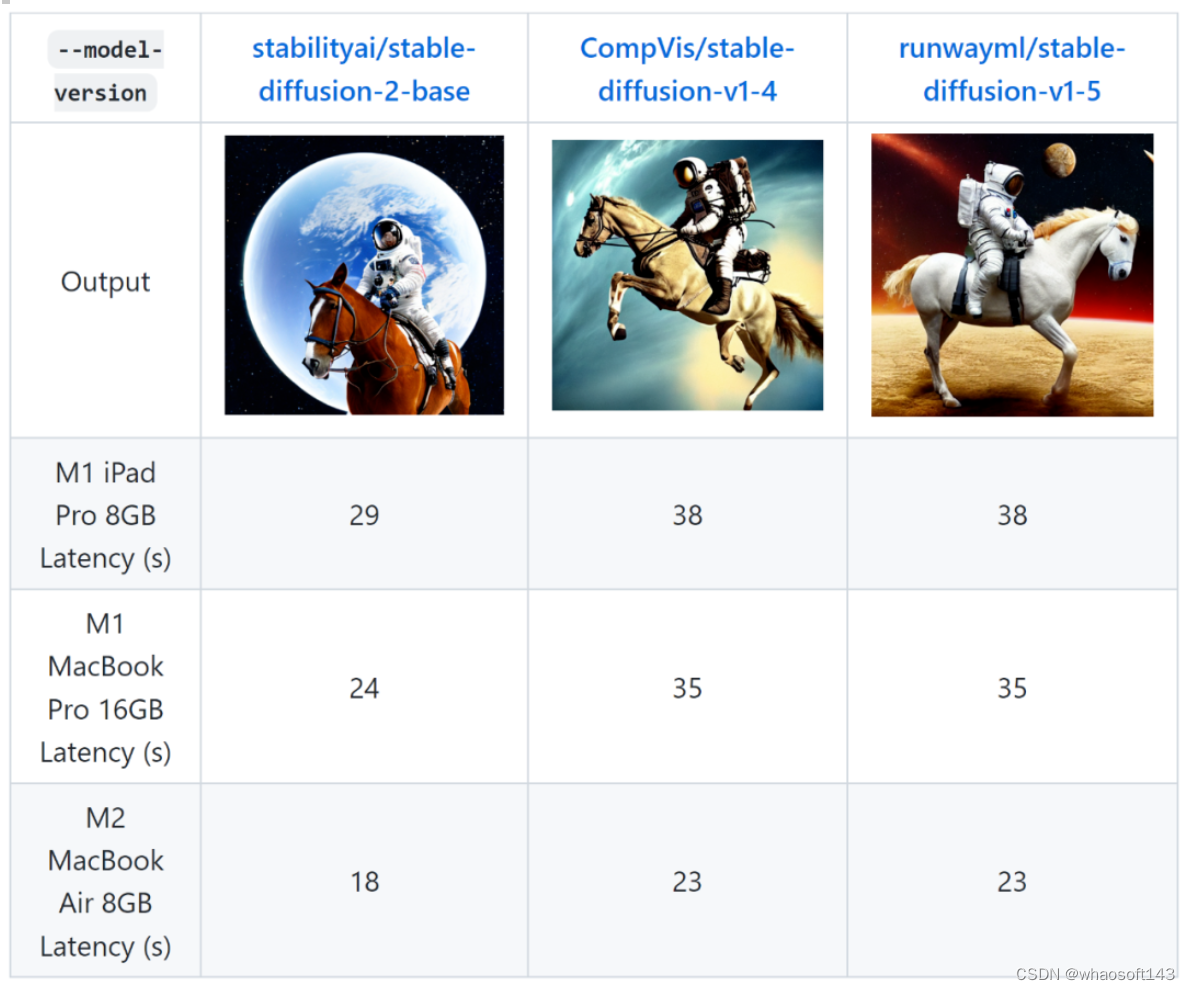
在三款苹果设备(M1 iPad Pro 8GB、M1 MacBook Pro 16GB、M2 MacBook Air 8GB)上的测试结果表明,苹果推出的相关优化基本可以保证最新版 Stable Diffusion(SD 2.0)在半分钟内生成一张分辨率为 512x512 的图。
对于苹果的这一举动,不少人感叹,一个开源社区构建的模型已经优秀到可以让大公司主动采用,确实非常了不起。
另外,大家也开始猜测,未来,苹果会不会直接把 Stable Diffusion 放到自己的设备里?
为什么要让 Stable Diffusion 可以在苹果设备上运行?
自 2022 年 8 月首次公开发布以来,Stable Diffusion 已经被艺术家、开发人员和爱好者等充满活力的社区广泛采用,能够以最少的文本 prompt 创建前所未有的视觉内容。相应地,社区在几周内就围绕这个核心技术构建了一个包含扩展和工具的庞大生态系统。Stable Diffusion 已经变得个性化,而且可以拓展到英语以外的其他语言,这要归功于像 Hugging Face diffusers 这样的开源项目。
除了通过文本 prompt 生成图像,开发人员还发现了 Stable Diffusion 其他创造性的用途,如图像编辑、修复、补全、超分辨率、风格迁移。随着 Stable Diffusion 应用的增多,要想打造出任何地方的创意人员都能使用的应用程序,就需要确保开发者能够有效地利用这项技术,这一点至关重要。
在所有应用程序中,模型在何处运行是 Stable Diffusion 的一大关键问题。有很多原因可以解释为什么在设备上部署 Stable Diffusion 比基于服务器的方法更可取。首先,终端用户的隐私可以受到保护,因为用户提供的作为模型输入的任何数据都保留在用户自己的设备上。
其次,在初次下载之后,用户不需要连接互联网就可以使用该模型。最后,在本地部署此模型能让开发人员减少或消除服务器方面的成本。
用 Stable Diffusion 产出可观的结果需要经过长时间的迭代,因此在设备上部署模型的核心挑战之一在于生成结果的速率。这需要执行一个复杂的流程,包括 4 个不同的神经网络,总计约 12.75 亿个参数。要了解更多关于如何优化这种大小和复杂性的模型,以在 Apple Neural Engine 上运行,可以参阅以前的文章:Deploying Transformers on the Apple Neural Engine。
文章地址:https://machinelearning.apple.com/research/neural-engine-transformers
上文中概述的优化原则可以推广到 Stable Diffusion,尽管它比文中研究的模型大 18 倍。为 Stable Diffusion 优化 Core ML 和简化模型转换,可以让开发者更容易在他们的应用程序中以保护隐私和经济可行的方式利用该技术,并使其在 Apple Silicon 上展现出的性能达到最佳状态。
这次发布的版本包括一个 Python 包,用于使用 diffusers 和 coremltools 将 Stable Diffusion 模型从 PyTorch 转换到 Core ML,以及一个 Swift 包来部署模型。请访问 Core ML Stable Diffusion 代码存储库以启动,并获取关于基准测试和部署的详细说明。
项目地址:https://github.com/apple/ml-stable-diffusion
项目介绍
整个代码库包括:
-
python_coreml_stable_diffusion,一个 Python 包,用于将 PyTorch 模型转换为 Core ML 格式,并使用 Python 版的 Hugging Face diffusers 执行图像生成;
-
StableDiffusion,一个 Swift 包,开发者可以把它作为依赖包添加到他们的 Xcode 项目中,在他们的应用程序中部署图像生成功能。Swift 包依赖于 python_coreml_stable_diffusion 生成的 Core ML 模型文件。
将模型转换为 Core ML 版本
步骤 1:创建 Python 环境并安装依赖包:

步骤 2:登录或注册 Hugging Face 账户,生成用户访问令牌,并使用令牌通过在终端窗口运行 huggingface-cli login 来设置 Hugging Face API 访问。
步骤 3:找到想在 Hugging Face Hub 上使用的 Stable Diffusion 版本,接受使用条款。默认型号版本为 “CompVis/stable-diffusion-v1-4”。
步骤 4:从终端执行以下命令生成 Core ML 模型文件 (.mlpackage)
python -m python_coreml_stable_diffusion.torch2coreml --convert-unet --convert-text-encoder --convert-vae-decoder --convert-safety-checker -o <output-mlpackages-directory>M1 MacBook Pro 一般需要 15-20 分钟。成功执行后,构成 Stable Diffusion 的 4 个神经网络模型将从 PyTorch 转换为 Core ML 版 (.mlpackage),并保存到指定的 < output-mlpackages-directory>.
用 Python 生成图像
使用基于 diffusers 的示例 Python 管道运行文本到图像生成。
python -m python_coreml_stable_diffusion.pipeline --prompt "a photo of an astronaut riding a horse on mars" -i <output-mlpackages-directory> -o </path/to/output/image> --compute-unit ALL --seed 93使用 Swift 生成图像
构建 Swift 项目需要:
-
macOS 13 或更新版本
-
安装了命令行工具的 Xcode 14.1 或更新版本。
-
Core ML 模型和 tokenization 资源。
如果将此模型部署到:
-
iPhone: iOS 16.2 及以上版本和 iPhone 12 及以上版本
-
iPad: iPadOS 16.2 或更新版本和 M1 或更新版本
-
Mac: macOS 13.1 或更新版本和 M1 或更新版本
Swift 包包含两个产品:StableDiffusion 库和 StableDiffusionSample 命令行工具。这两个产品都需要提供 Core ML 模型和 tokenization 资源。
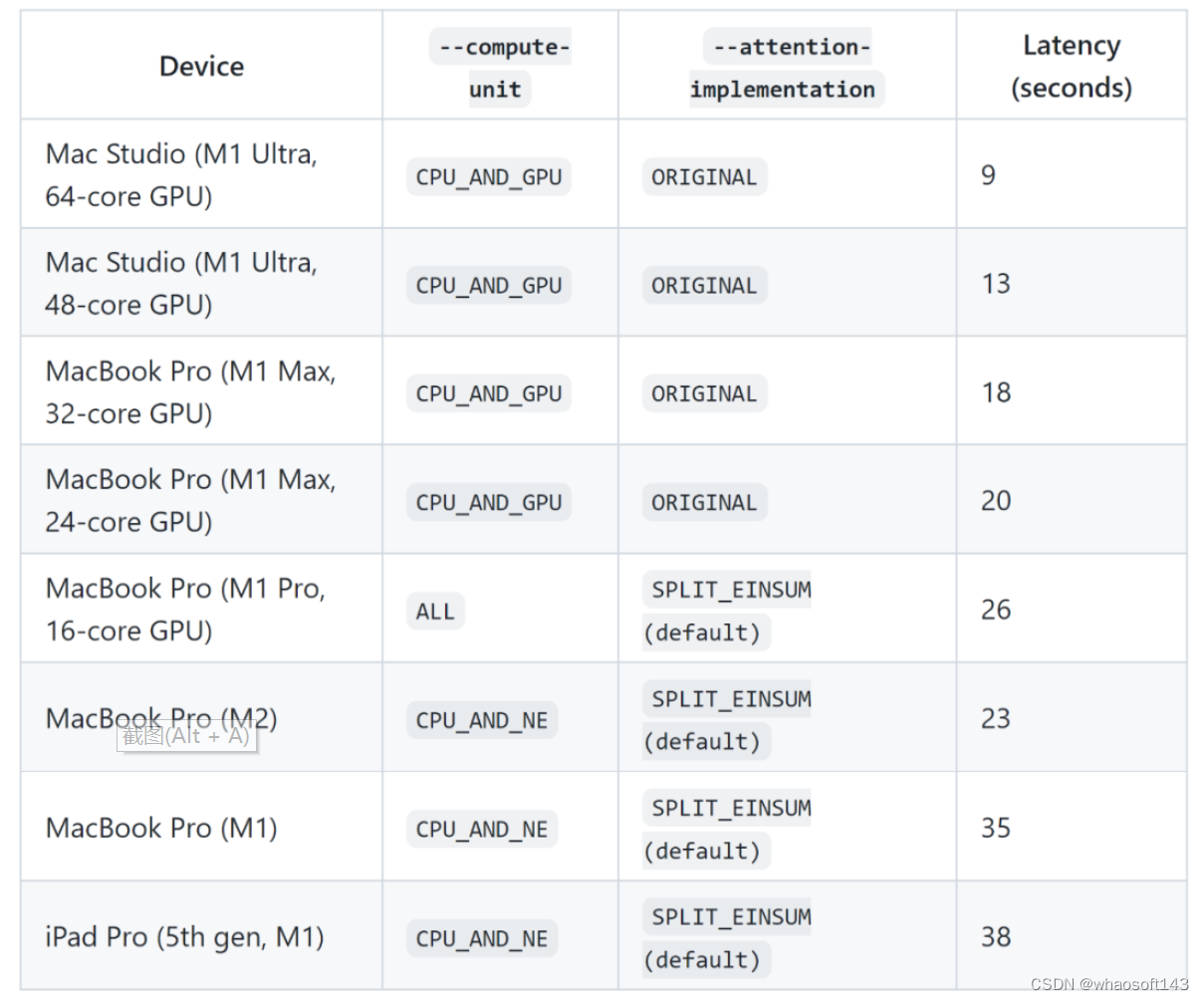
性能基准测试
标准 CompVis/stable-diffusion-v1-4 基准。该基准测试由苹果公司在 2022 年 11 月使用 iOS 16.2、iPadOS 16.2 和 macOS 13.1 的公开测试版进行。
针对 macOS 设备,执行的程序是 python_coreml_stable_diffusion。对于 iOS 和 ipad 设备,有一个建立在 StableDiffusion Swift 包上的最小 Swift 测试应用程序。
图像生成过程遵循标准配置:
50 个推理步骤,512x512 输出图像分辨率,77 文本 token 序列长度,无分类器引导 (unet 批大小为 2)。
 参考文章:https://machinelearning.apple.com/research/stable-diffusion-coreml-apple-silicon
参考文章:https://machinelearning.apple.com/research/stable-diffusion-coreml-apple-silicon
whaosoft aiot http://143ai.com
![Matplotlib入门[03]——处理文本](https://img-blog.csdnimg.cn/16822e96a11c40a4b0181ddb97d8632a.png)