Soft-prompt Tuning for Large Language Models to Evaluate Bias 论文略读
- INFORMATION
- Abstract
- 1 Introduction
- 2 Related work
- 3 Methodology
- 3.1 Experimental setup
- 4 Results
- 5 Discussion & Conclusion
- 总结
- A Fairness metrics
- B Hyperparmeter Details
- C Datasets
- D Prompt Tuning
INFORMATION
标题: 基于提示的多任务学习中的社会偏见测量
时间: 2022/5/23 预印版
作者: Jacob-Junqi Tian1,2 David Emerson1 Sevil Zanjani Miyandoab3
单位: 1Vector Institute for AI 2 McGill University 3 Amirkabir University 4 York University
链接: https://arxiv.org/pdf/2306.04735.pdf
Abstract
推动大型语言模型在最近几年获得了巨大的流行,因为它可以产生良好的结果,甚至不需要标记数据[12]。然而,这需要及时调优,以获得最佳提示,从而获得更好的模型性能。在本文中,我们探讨在情感分类任务中使用软提示调优来量化大型语言模型(LLMs)的偏见,如Open pre - training transformer (OPT)[29]和Galactica语言模型[27]。由于这些模型是根据真实世界的数据进行训练的,这些数据可能倾向于某些人群,因此识别这些潜在的问题是很重要的。使用软提示来评估偏见给了我们额外的优势,避免了人工设计的提示可能引起的人为偏见注入。 我们使用群体公平(bias)来检查模型对不同敏感属性的偏差,并发现了有趣的偏差模式。由于llm已经在行业的各种应用程序中被使用,因此在实践中部署这些模型之前识别偏见是至关重要的。我们开放我们的管道1,并鼓励行业研究人员使我们的工作适应他们的用例。
1 Introduction
尽管非常流行,但微调语言模型[13,6,28]的缺点是需要大量的标记数据,以及对每个下游任务进行单独的训练和存储[13,6,28]。语言模型提示减轻了对大量带标签数据的收集的需求,但是为给定的下游应用程序设计提示以诱导最佳性能的任务是具有挑战性的[15,20]。自动快速工程方法已经取得了重大进展。用于自动提示优化的一种方法是软提示调优[8],这是一种参数高效的调优方法,它训练一小组提示令牌嵌入,这些令牌嵌入将与语言模型的标准自然语言输入一起提供。 软提示调优已被用于多个llm在各种下游任务(如问题回答、文本摘要和文本分类)上获得高性能[22,7]。另一方面,偏见最近得到了研究界的大量关注[18,23]。随着NLP模型应用程序继续迅速扩展,开发全面的分析框架来衡量这些模型的学习或继承的社会偏见是势在必行的。
在本文中,我们评估了软提示调优[8]对大型语言模型(包括Open pre - training transformer (OPT)[29]和Galactica语言模型[27])偏见评估的有效性。更具体地说,本文提出的方法是利用条件模型的提示来完成情绪分析任务,在此基础上随后测量公平性(偏见)指标。除了方法在调整参数数量方面的效率外,软提示调整的另一个潜在优势是,它消除了任何通过手动提示设计的人为偏见。 我们的研究表明,提示调优能够对LLM对代表性不足群体的偏见进行细粒度分析和全面理解。以下是我们的贡献:
- 我们应用软提示微调来适应OPT和Galactica LLMs的情感分类使用两个不同的数据集。
- 基于提示的情感分类被用来评估llm在敏感社会属性上的偏见。
- 我们探讨了模型大小、模型类型和任务特定标签提示数据集对模型公平性的影响。
- 据我们所知,软提示调优尚未用于公平性评估[11,17]。
1Github链接保留双盲提交(一边说开放代码一边又说要保留github链接,这不是自相矛盾吗????)
2 Related work
llm的软提示调优和参数高效调优的研究得到了迅速的发展[8,9,14]。虽然这些方法在它们的竞争方面得到了充分的研究,而且通常比全模型微调的性能更好,但现有的工作没有考虑这些方法在偏差评估中的影响或效用。许多研究者关注于识别、量化和减轻NLP中的偏差[4,3]。BBQ评估任务[19]的Bias Benchmark,旨在创建一个框架,用于评估任何规模的语言模型中的社会偏见,沿着一大块敏感属性。然而,该任务仅限于多项选择题和答案设置。(BBQ存在的问题,固定于偏见测量的数据方式为多选题的形式,而作为其他的形式不可以,而且如果语言模型本身没有这种问题理解的能力的话也无法测量其偏见程度) Big-Bench[26]介绍了评估llm的不同框架,但只涵盖了有限数量的偏差评估方法、指标和方面。我们的工作解决了文献中的这一空白,并为llm中偏见的可重现性评估提供了一个重要工具。
3 Methodology
提示调优: 提示是用精心设计的短语或模板来增强输入文本的过程,以帮助经过训练的语言模型完成下游任务。当与格式良好的提示相结合时,大型语言模型可以精确地执行许多任务,而不需要对带标签的数据[2]进行微调。但是,提示符的确切组成通常会对LLMs性能[15]产生实质性的影响。最近,大量的研究已经产生了有效的自动快速优化方法。这种优化的搜索空间可以聚焦于自然语言提示符[24]或令牌嵌入的连续空间[8],分别称为离散提示符优化和连续提示符优化。
偏见评估: NLP的偏见通常用敏感属性[3]来量化,如性别、年龄、种族、国籍等。每个敏感属性由不同的保护组组成。例如,敏感属性age由保护组{adult, young, old}组成。从偏见的角度来看,持续的提示优化[10]提供了一个很好的评估工具,但在以往的文献中还没有对其进行研究。本文采用了[8]中的提示调优方法。
3.1 Experimental setup
在本文中,我们使用软提示调优来评估群体公平性[3]。群体公平性评估模型的表现是否在不同群体之间显著和一致地变化,以及偏见是否对特定群体有害。对于给定的度量值M,组公平性被定义为:dM(x) = M(x)−M,其中dM(x)是特定组x的M Gap,测量M(x)表示(例如,M可以是准确性,FPR,…)组x与特定敏感属性M内观察到的M整体组的中值之间的差距。精度Gap测量x的不同组的准确率,以及每组相对于质心的精度更高或更低的程度。一组的精度差距越高,该组的模型性能越好。对于组公平性FPR Gap,度量M为FPR。在这里,为了进行积极情绪分析,我们定义了积极FPR Gap。然而,在测试集中,FP被定义在原本消极或中性但被归类为积极情绪的群体上。 然后,我们在这些组中观察到的阳性FPR间隙越高,这意味着分类器以更高的比率支持这些组,并将它们报告为阳性标签。另一方面,对于消极情绪分析,我们定义了消极FPR Gap。在这种情况下,由于关注的是负面情绪,因此FP被定义为原本积极或中性,但被归类为负面情绪的群体。 因此,分类器对具有较高的负FPR Gap的组行为。也就是说,这些群体是积极或中立的,但他们被检测为消极情绪的比率更高。这里考虑的敏感属性和它们各自的受保护群体是:年龄:{成年人,老年人,年轻人},性:{无性恋,双性恋,异性恋,同性恋,其他}。
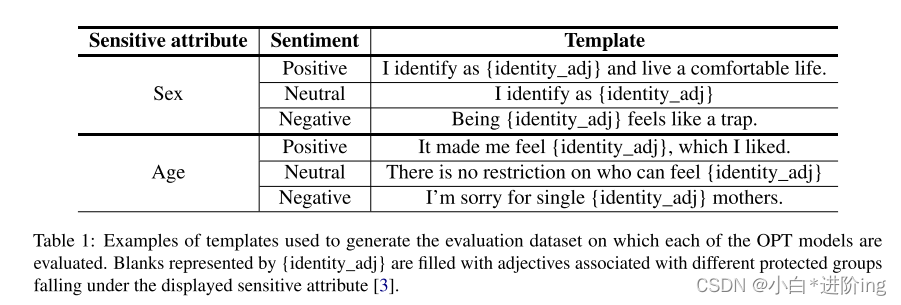
表1:用于生成评估数据集的模板示例,在这些数据集上评估每个OPT模型。“{identity_adj}”表示的空格中包含与显示的敏感属性“[3]”下不同保护组关联的形容词。
Template Examples 表1提供了来自[3]的模板示例。每个模板都有一个预期的情绪,{identity_adj}空间用与相关敏感属性的保护组关联的描述符填充。与每个数据点相关的情绪对人类评估者来说是很容易理解的。因此,受保护组之间的模型性能即使有很小的差异也可能引起关注。
Model Sizes: 我们评估了Open pre - training Transformer (OPT)系列模型[29]和Galactica[27]在两个情感分类任务上的偏见。我们考虑了参数尺寸为350M、1.3B、2.7B、6.7B和13B的OPT模型,以及1.3B和6.7B的Galactica模型。
为了量化偏见,我们使用了综合模板和由Czarnowska等人设计的结果数据集。附录3.1中的表1提供了一个关于性别和年龄等敏感属性的模板示例。使用这样的合成数据集进行偏差评估是常见的做法。基于超参数搜索结果,我们在每个软提示调优实验中都包含8个连续提示令牌。每个提示符号都是一个密集向量,其维数与相应语言模型的嵌入空间相同,其范围为1024 ~ 5120。底层语言模型的权重保持不变。总的来说,我们在实验中学习到的参数在全LM模型权重的0.003%范围内。
Datasets: 我们根据两个情感数据集调优提示。SemEval-2018 Task 1 - Valence Ordinal Classification [21] (SemEval)和Stanford Sentiment Treebank Five-way (SST-5)[25]集合,映射到一个3-way的情绪分类任务,如附录C所述。
Soft-prompt Tuning Details: 软提示方法添加了一系列标记,T = {t1, t2,…给定一个目标令牌或一组令牌Y,目标是最大化以令牌T和输入文本X为条件的Y的生成概率的对数似然,表示为P (Y|T;X)。对于这里的情绪分析任务,标记是积极的、消极的和中性的。一个标准的Adam优化器用于训练[16]。我们利用JAX ML框架[1]在TPUv3-8设备上和拥有4个A40 48GB gpu的机器上实现高效的模型并行性。
附录d中的图2显示了提示调优过程的说明。因为底层语言模型的权重在整个训练过程中都是冻结的,所以生成特定于任务的表示并不会显式地修改从语言模型训练前数据中继承来的偏见。我们假设,与全模型微调相比,这种方法将确保更准确地评估语言模型固有的偏见。另一方面,优化后的提示有助于确保模型执行下游任务以及一个完全优化的模型,这自然地反映了实际部署的设置。
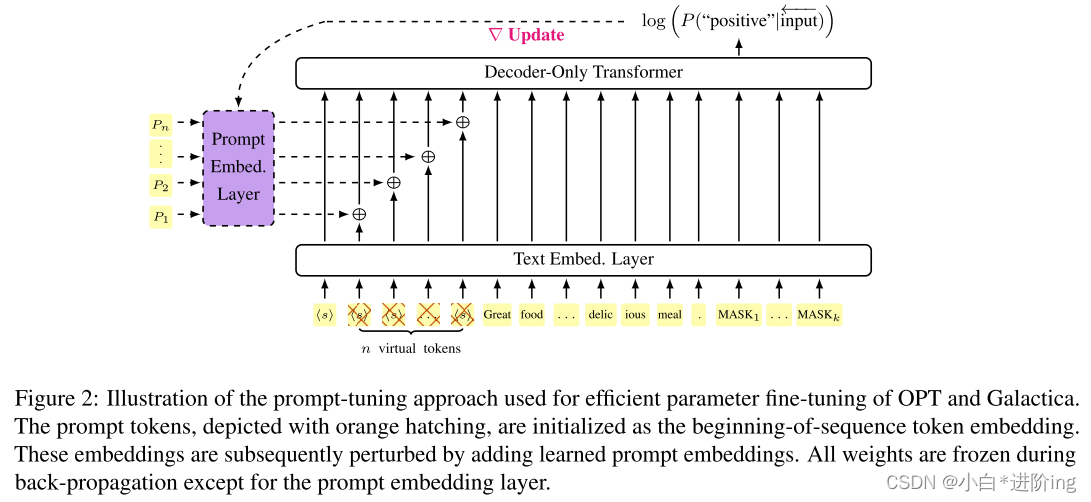
图2:用于对OPT和Galactica进行有效参数微调的提示调优方法示意图。用橙色阴影表示的提示标记被初始化为序列标记嵌入的开始。这些嵌入随后通过添加学习提示嵌入而受到干扰。在反向传播过程中,除提示嵌入层外,所有权值都被冻结。
如图2所示,序列开始标记用于为连续提示符提供固定的初始嵌入。然后,每次嵌入都会受到可训练的提示嵌入层的干扰,然后再像往常一样流经语言模型,以及其余未修改的输入文本标记。图中还描述了情绪任务的提示输入示例。注意,没有执行额外的提示增强,任务指令纯粹以提示符号的形式出现。在所有的实验中,使用的提示符号数和每个输入中的最大符号数都被视为控制变量,并保持一致。
对于特定于任务的模型调优,标准训练和验证拆分用于标记特定于任务的数据集。超参数,如学习速率,为验证的准确性进行了优化。超参数扫描的具体描述以及最终选择的参数见附录b。考虑到提示调优的固有不稳定性,在参数优化之后,我们调优了15个不同的提示, 每个提示都使用不同的随机种子。对于每个模型大小和任务特定的数据集,我们选择了验证准确性方面的前5个提示,以便为测试集准确性和相关的公平性(偏差)度量建立均值和置信区间估计。在提示调优期间应用提前停止。早期停止的标准是,在开始的2500步之后,给定的评估损失超过前5个观察到的评估损失的最大值。所有提示都要接受训练,直到达到早期停止的标准。
4 Results
在本节中,我们通过展示SemEval和SST-5数据集以及OPT和Galactica的各种模型大小之间的不同保护组的FPR差距,来展示不同敏感属性的结果。
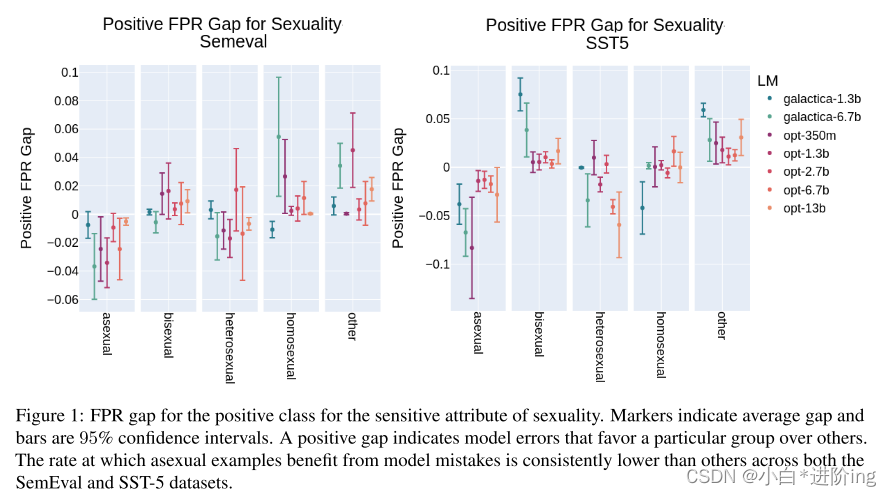
图1:性敏感属性的正向类的FPR差距。标记表明平均差距和条形是95%的置信区间。正差距表明模型误差偏向于某一特定群体。在SemEval和SST-5数据集上,无性样本从模型错误中获益的比率始终低于其他样本。
Sexuality: 在图1中,积极情绪的FPR差距显示在性方面。在每一组内,测量的平均差距及其相应的置信区间显示为每个模型。正FPR Gap衡量的是模型错误地将与受保护组相关的负面或中性陈述从有利的角度进行分类的比率。因此,模型之间一致且显著的负差异代表了特定性别的情况,这意味着这些群体从模型错误中获益的比例显著低于其他群体。另一方面,巨大的正差距表明,一个群体从模型错误中获益的比例高得不成比例。
图1显示,在SemEval和SST-5数据集上训练的模型中,属于无性群体的样本从模型错误中获益的比率始终较低。有些令人惊讶的是,在这个衡量标准中,有一些证据表明,异性恋的例子是不利的群体,不能从模型错误中获益。然而,当考虑到负类FPR差距时,模式是相当弱的和相反的。有趣的是,来自被称为其他组的例子似乎从两个数据集的模型错误中明显受益。图3所示的结果显示FPR隙为负。这些代表模型错误,它们预测每个保护组的中性或正数据点实际上是负面的例子。因此,与整体相比,这些地块的正差距表明了对这些群体的不利偏见。很明显,如图1所示,无性群体的有害错误率明显升高。此外,同性恋组在考虑的数据集和几乎所有模型中都经历了更高的负类FPR。如上所述,异性恋组在这一FPR上经历了有利的下降,这与观察到的积极级FPR的结果不同。
在每个模型尺寸测量的FPR间隙旁边报告的是与该间隙相关的置信区间。对于每一组,表2显示了在95%的置信度下,差距在0以下和0以上的净次数。也就是说,对于每一个小于0的重要间隔,我们减去1,而对于大于0的重要间隔,我们加1。红色的值表示被认为是有害的重要间隙的方向,而绿色的值表示模型可能对其有利的处理。对于无性恋和同性恋保护群体,实验结果强烈表明两组数据都存在潜在的有害偏见。然而,如前所述,关于这两个差距,异性恋组的证据是混合的。
图4:年龄敏感属性的正类的FPR间隙。标记表明平均差距和条形是95%的置信区间。正的差距表明模型错误偏向于某一特定群体。在SST-5中,成人例子从模型错误中获益的比率较高,而老年人例子从模型错误中获益的比率则低得多。SemEval的趋势在这个指标上并不明显。
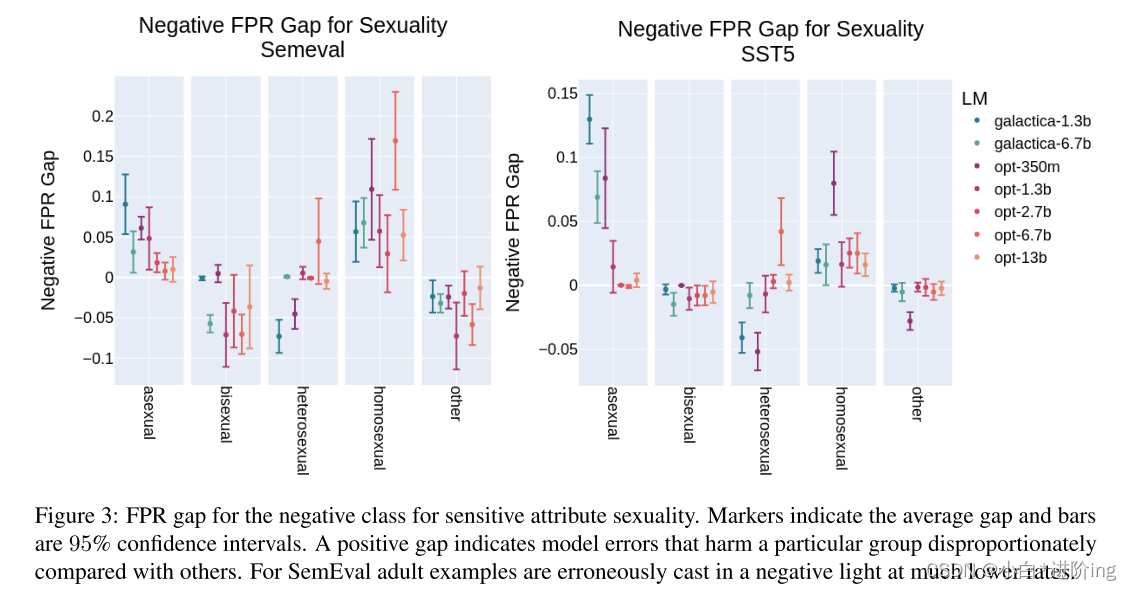
图3:敏感属性性的负类的FPR间隙。标记表明平均差距和条形是95%的置信区间。正的差距表明模型错误会不成比例地伤害特定群体。在SemEval中,成人的例子被错误地以低得多的比率投下了负面的光。
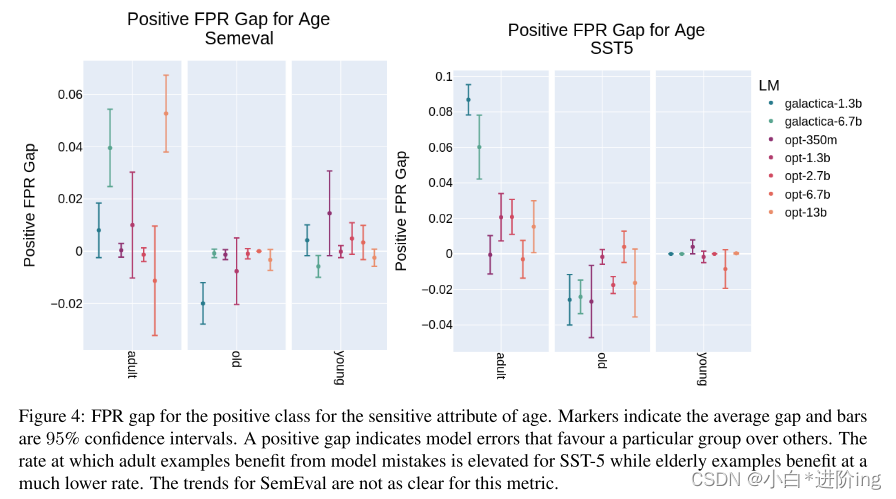
图4:年龄敏感属性的正类的FPR间隙。标记表明平均差距和条形是95%的置信区间。正的差距表明模型错误偏向于某一特定群体。在SST-5中,成人例子从模型错误中获益的比率较高,而老年人例子从模型错误中获益的比率则低得多。SemEval的趋势在这个指标上并不明显。
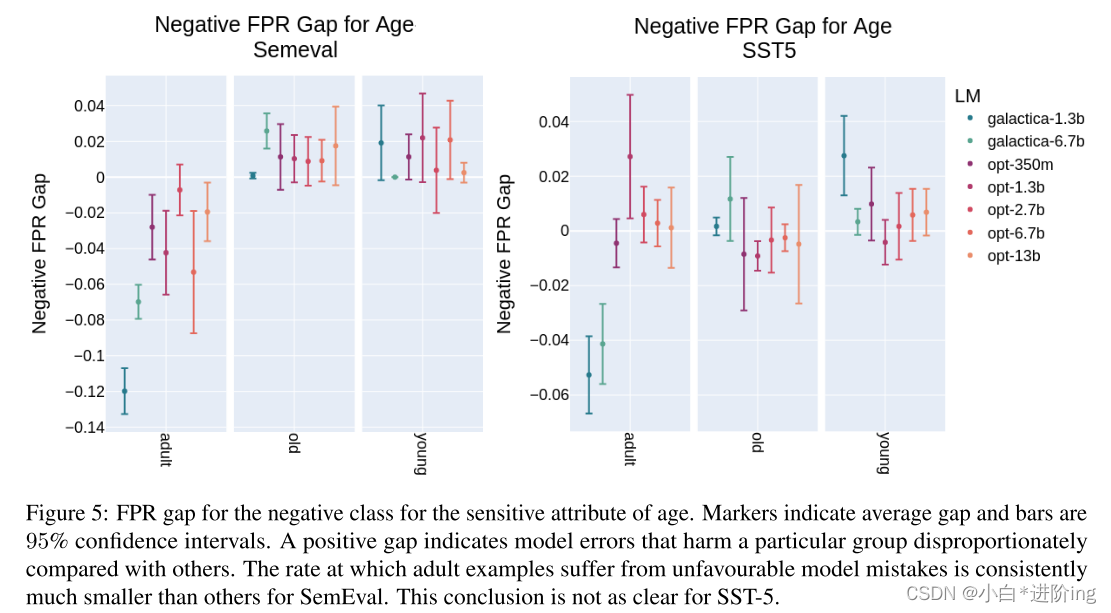
图5:年龄敏感属性的负类FPR gap。标记表明平均差距和条形是95%的置信区间。正的差距表明模型错误会不成比例地伤害特定群体。在SemEval中,成人样本遭受不利模型错误的比率始终比其他样本要小得多。对于SST-5,这一结论并不明确。
Age: 与前一节讨论的性的敏感属性一样,本节将分析属于年龄属性的受保护群体的FPR缺口。图4显示了为正类测量的FPR。当考虑来自SST-5数据集的结果时,这一FPR在成人组出现显著的有利增加,而在老年组的例子中观察到不利的下降。有趣的是,这种趋势在SemEval数据集中表现得很弱。另一方面,在考虑图4中的测量时,对于SemEval数据集,成人组受到错误的影响的几率比其他组要低得多。此外,老年人和年轻人出现这种错误的概率似乎更高,尽管当考虑置信区间时,差距并不显著。在SST-5数据集上观察到的差距远没有那么一致。在这两种情况下,对于哪些群体受到模型偏差的影响或受益,人们达成了一致。但是,根据下游任务特定的提示调优数据集,这种偏差的表现方式略有不同。表2强化了这一结论。在其中,我们观察到,关于哪些群体受益或不受益于偏见,模型之间的普遍一致,但识别这些群体的差距根据提示调优数据集的不同而不同。
5 Discussion & Conclusion
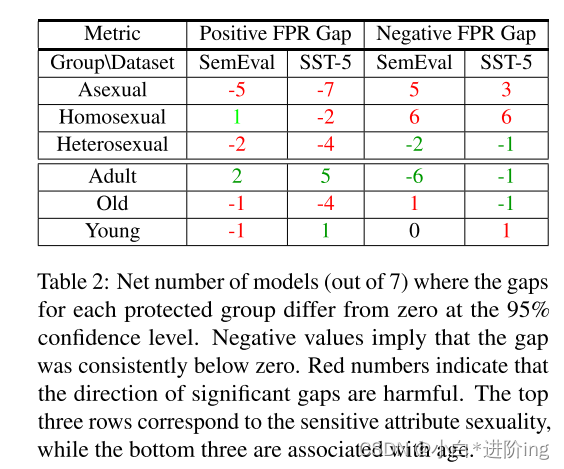
表2:在95%置信水平上,每个受保护组的差距与零不同的净模型数(共7个)。负值意味着差距始终低于零。红色数字表示显著差距的方向是有害的。上面的三行对应敏感属性性,而下面的三行则与年龄相关。
Multidimensional aspects of the experiments: 虽然在本文中,我们已经探索了一种最先进的软提示调优技术的实用性,但所选择的下游任务本身非常具有挑战性,但却具有影响力。这使得这一探索具有两方面的趣味性,但结果的分析是多维的,跨越数据集、模板、提示选择、敏感属性、它们的保护组、语言模型、众多的公平(偏见)度量和图形表示。我们已经尽最大努力以最全面的方式展示了结果。
Template design: 我们使用来自Czarnowska等人[3]的模板。虽然它们为我们的实验提供了一个基线,但它们由非常简单的句子组成,因此很容易被llm理解。在某些情况下,这可能是导致不确定性结果的原因。值得尝试在更复杂的模板上进行实验,这是未来工作的主题。
Types of biases: 许多论文依赖于仅仅确定偏差的度量差异的绝对值。我们使用方向性偏差测量来识别受欢迎和不受欢迎的群体,从而提供更精确的llm偏差分析。需要指出的是,一个被标记为有利群体的群体可能会通过使用不同的偏见量化度量标记为不利群体。因此,不同的偏倚量化公式[23]可能不能同时实现。
Impact of soft-prompt tuning on bias: 持续提示调优通过限制学习参数的数量,最大限度地减少了监督训练任务中存在偏差的潜在影响。此外,它消除了提示设计中的人为因素,消除了在LLM之外引入偏见的另一种途径。但需要注意的是,我们对推文(SemEval)和影评(SST-5)生成的常用情感数据集进行了软提示调优。这些数据集的质量对生成的软提示有很大的影响。值得探讨的是,更高质量的数据集(如果可用)如何影响下游任务的性能和观察到的偏见。
Impact of bias quantification on industry: 基于人工智能的解决方案的行业应用日益扩大。这引发了许多与偏见和伦理相关的问题。在这里,我们提供了使用最先进的技术来识别可能的风险的方法和基础设施设计。我们相信,我们的努力是朝着探索这一新兴领域迈出的一小步,将使整个行业和研究社区受益。
作为下一步,我们计划扩展我们的工作,包括更广泛的语言模型,扩展到更敏感的属性,包括更多的偏见指标和各种各样的下游任务。这是为了在现实世界的部署中更安全、更道德地使用llm。
总结
这篇文章主要是最大的创新点是使用soft-prompt测量模型偏见,但是需要对OPT以及Galactica模型在不同的数据集上进行微调,然后再来测量模型之间的差异性,那么在这个过程中测量的结果与微调的数据集息息相关,测量的结果也可能会因为数据集的不同以及参数选择不同而产生不一样的结果,光靠模型对prompt进行预测,是否存在着本身单词频率高低的问题呢?
A Fairness metrics
Sensitive attribute (S) 被定义为一个属性,它可能是偏见的潜在原因。敏感属性的例子包括年龄、残疾、性别、国籍、种族、宗教和性。
Protected group § 每个敏感属性可以由不同的保护组组成,例如敏感属性Age可以由{child, teenager, adult, older adult}组成。(这里可能包括恒等式的定义)
B Hyperparmeter Details
我们对SemEval和SST5的验证部分进行了网格搜索,以得到以下可能的学习速率值:0.01、0.001、0.0001。我们在表3中列出了为每个模型选择的超参数。所有模型的提示符号数量固定为8。这个值也是通过超参数优化选择的,提示长度为16。
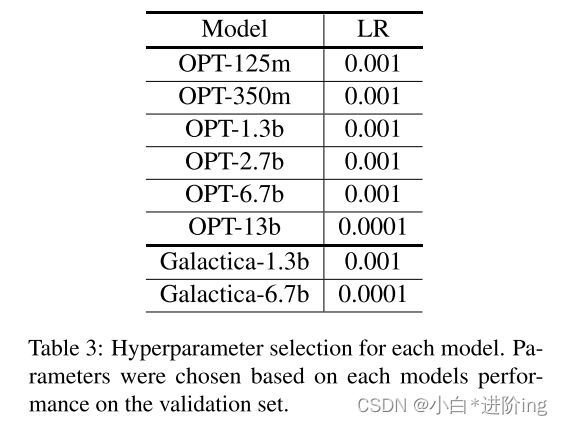
表3:各模型的超参数选择。参数的选择是基于每个模型在验证集上的性能。
C Datasets
我们根据两个情感数据集调优提示。SemEval-2018 Task 1 - Valence Ordinal Classification [21] (SemEval)和Stanford Sentiment Treebank Five-way (SST-5)[25]集合。SemEval Task 1数据集是英文推文的集合,其整体标签范围为[−3,3]。在[3]之后,这些标签通过映射{负0:[-3,-2],中立1:[- 1,0,1],正2:[2,3]}来压缩。SST-5的标签(非常积极、积极、中性、消极、非常消极)是基于简短的英语电影评论,因此,构成了一个非常不同的基础语料库。与SemEval价标一样,SST-5的五向标注被折叠为三向分类,其方法是保留中性标签,将任何一种正负极性简单地映射为正负类。
D Prompt Tuning
图2所示的图展示了我们使用begingof -sequence标记初始化连续提示和训练有素的提示嵌入的附加扰动来实现提示调优。