文章目录
- 一、简介
- 二、基础知识
- 2.1 视觉任务的训练策略
- 2.2 VLM 基础
- 2.2.1 网络结构
- 2.2.2 预训练目标函数
- 2.2.3 评估和下游任务
- 2.3 数据集
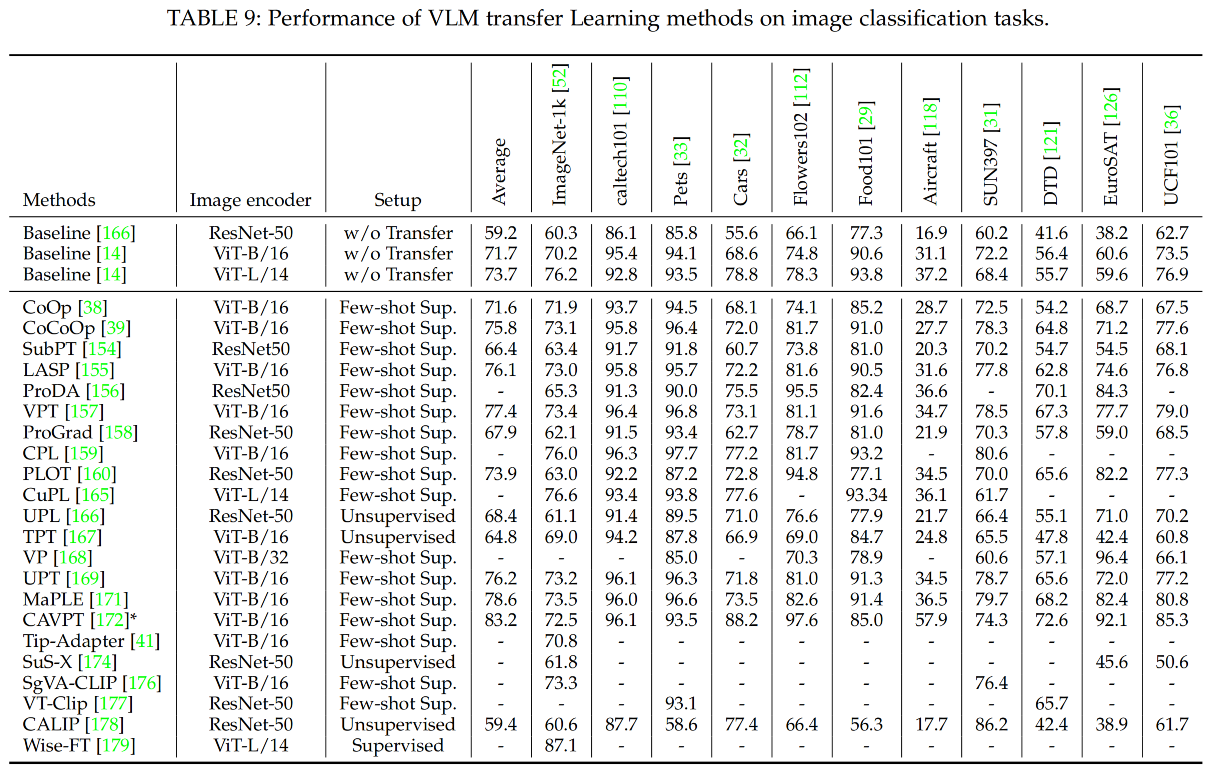
- 三、迁移学习
- 3.1 使用 prompt tuning 实现迁移学习
- 3.2 通过特征适应来进行迁移学习
- 四、VLM 的知识蒸馏
- 4.1 目标检测的知识蒸馏
- 4.2 语义分割的知识蒸馏
一、简介
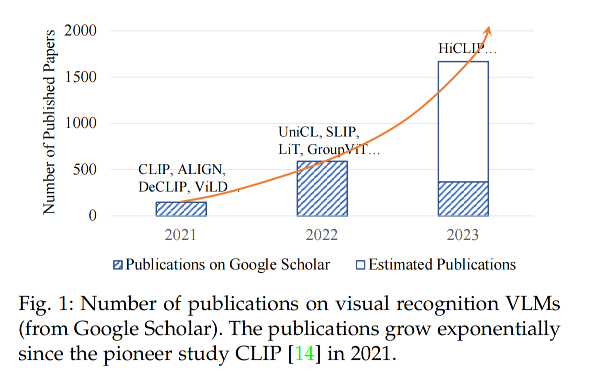
近来,一种新的学习范式 pre-training → Finetuning → Prediction 取得了很大的进步,并且在视觉识别任务中取得了很好的效果。
使用 pretrained 模型来学习丰富的知识,可以加速模型对下游任务的收敛速度并且提高效果
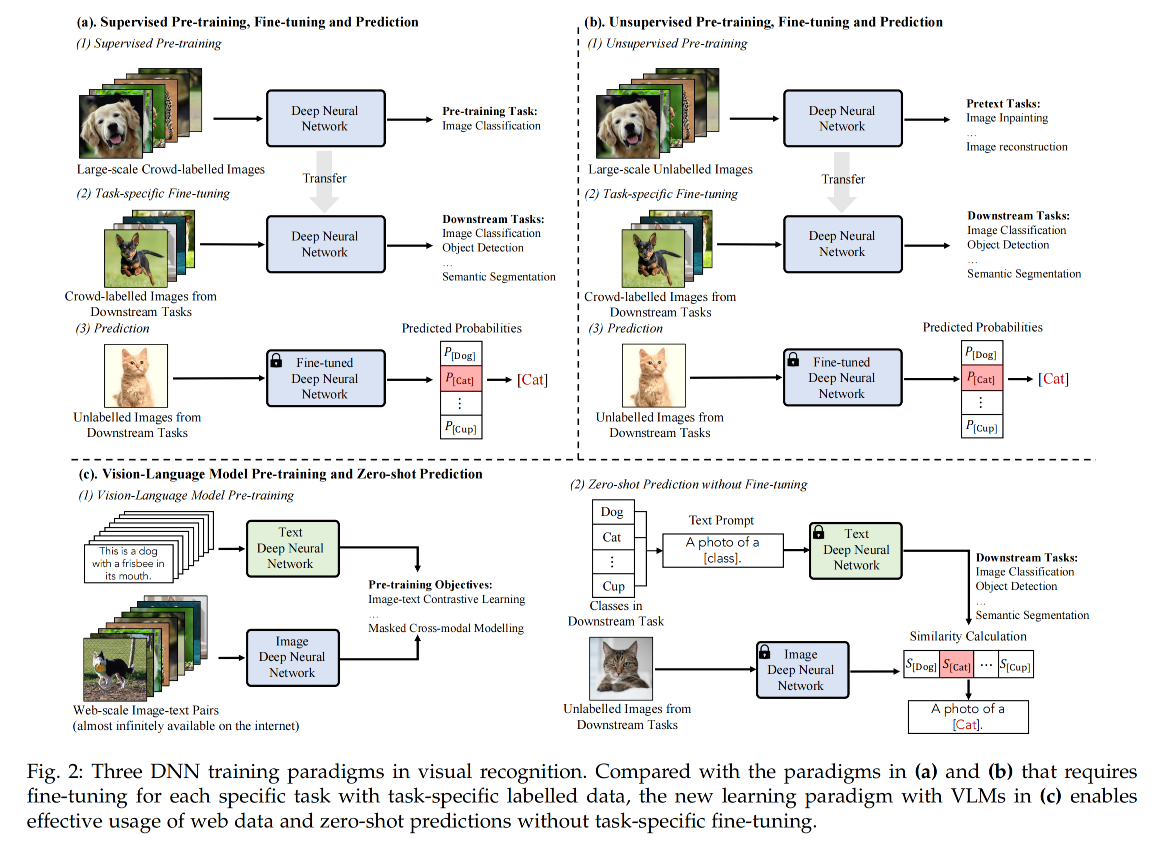
但是,这种学习范式在下游任务仍然需要很多带标注的数据,如图 2 所示
之后,受启发与自然语言处理的语言语义广泛性,研究者提出了新的学习范式:vision-language model pretraining and zero-shot prediction
在该范式下,使用超大规模的 image-text pairs 对 vision-language model(VLM)进行预训练,甚至可以不用微调直接用于下游任务,如图 2c。
VLM 模型可以使用 vision-language objective 来从超大规模的 image-text pairs 中学习 image 和 text 的对应关联。
例如 CLIP,就是使用 image-text 对比学习目标函数来将成对儿的 image-text 的编码距离拉近,将不成对儿的 image-text 编码距离推远。
这样的学习方式能够允许模型利用大量的来源于网络的数据,并且可以无需训练即可实现零样本迁移。
基于此, VLM 有两条研究方向:
- 迁移学习
- 知识蒸馏:如何将 VLM 的能力蒸馏到下游任务,如目标检测和语义分割
二、基础知识
2.1 视觉任务的训练策略
1、传统的机器视觉:
主要靠手工提取特征来作为图像特征,如 SIFT 等,无法适应复杂的任务
2、从头训练的深度学习和预测
设计深度的神经网络结构来进行图像特征的提取,如 ResNet 使用残差连接实现了很好的特征提取,在 1000-class ImageNet 分类任务上获得了优于人类的结果
3、有监督预训练,微调和预测
有监督的预训练如图 2a 所示,使用大量的数据训练了模型, 然后使用微调的方法迁移到其他数据集上去,能够加速模型的收敛并且帮助获得更好的效果
4、无监督预训练、微调和预测
有监督的训练需要大量的监督数据,会带来一些困难,所以有方法使用了无监督训练,让模型从无标签的数据中学习有用的信息,如图 2b 所示。可以使用 image inpainting 来学习上下文信息,使用 masked image modeling 来建模 patch 间的关系。使用对比学习来学习更丰富的特征。由于其在预训练阶段不需要大量的带标签数据,所以能使用更多的数据来学习到更多更有用的特征。
5、VLM pre-training 和 zero-shot prediction
和 pre-training、fine-tuning 相比,这种方式更能利用超大规模的网络数据
2.2 VLM 基础
给定 image-text pairs,首先使用 text encoder 和 image encoder 来抽取 image 和 text 特征,然后学习 vision-language 之间的关系,通过大量的 image-text 关系的学习,VLM 模型已经见过非常多的数据,就可以在未见过的数据上使用 image 和 text 的匹配来进行 zero-shot 的任务
2.2.1 网络结构
VLM 预训练模型是从 N 个 image-text pairs 中学习图像和文本的特征
VLM 一般由两部分组成:
- image encoder:对图像进行编码
- text encoder:对文本进行编码
1、学习图像编码特征
一般有两种网络结构:
-
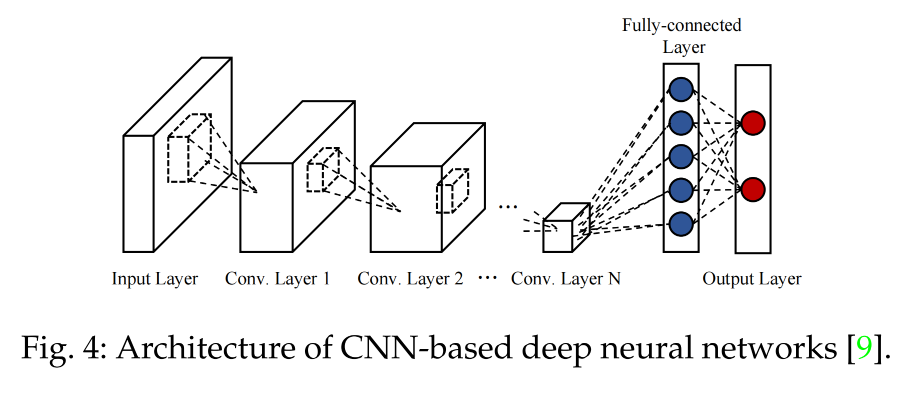
CNN-based:ResNet 等
-
Transformer-based:ViT 等(如图 5 所示)
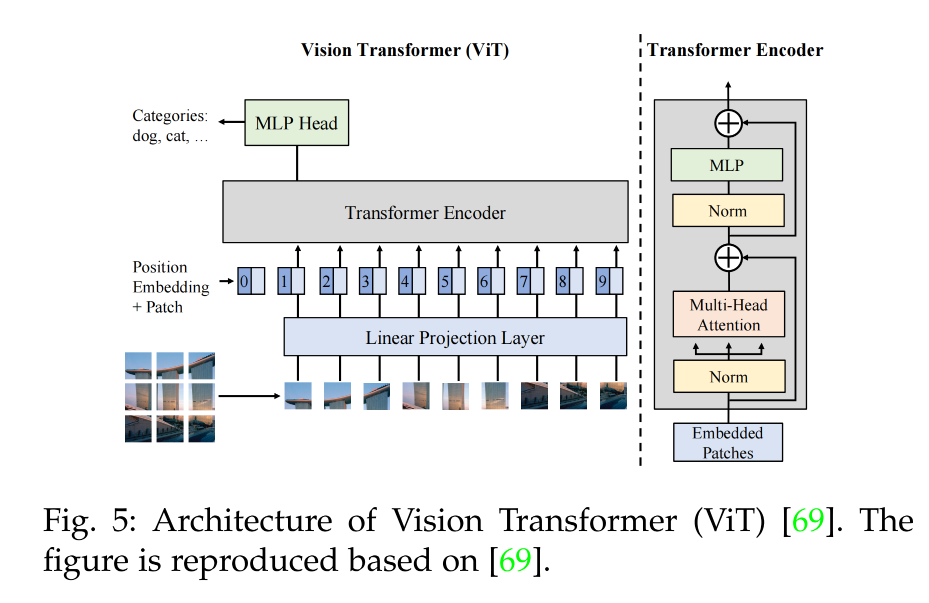
2、学习文本编码特征
一般 Transformer 都是 encoder-decoder 结构,如图 6,encoder 有 6 个 blocks,decoder 也有 6 个 blocks
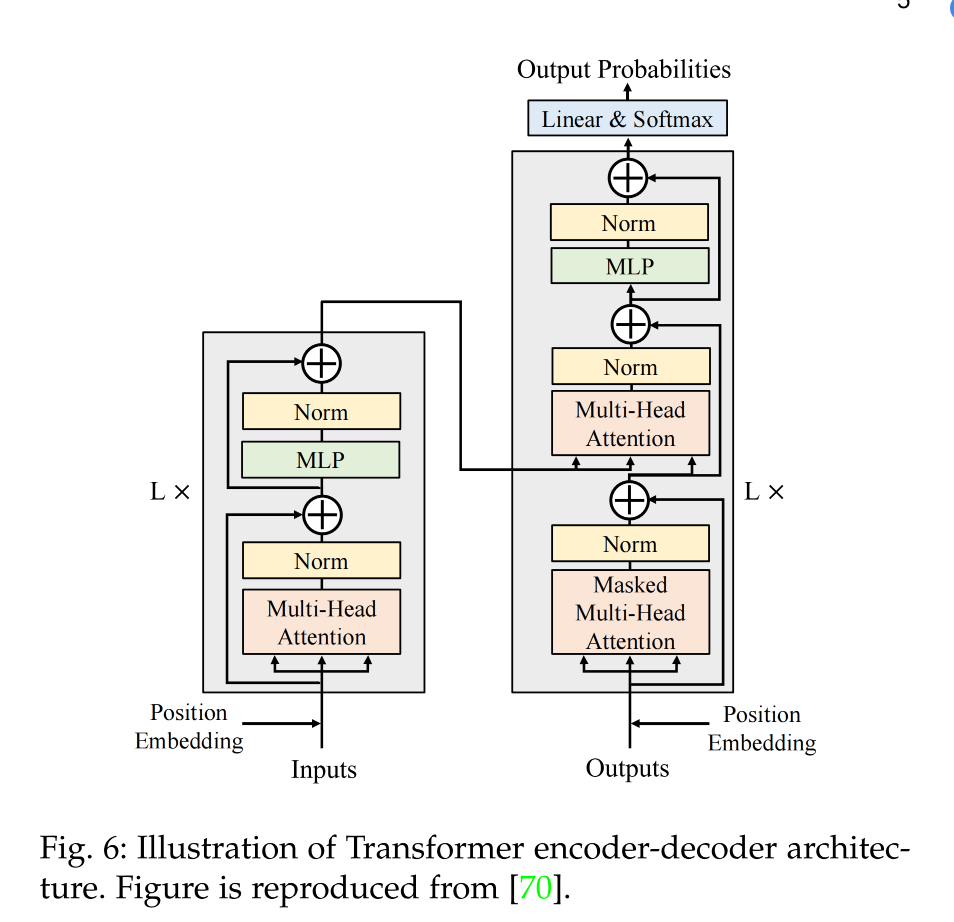
2.2.2 预训练目标函数
1、对比学习目标函数
① Image contrastive learning :
主要通过学习具有区分能力的 image features 来让 query image 和其 positive keys 拉近距离
给定一个 batch B B B 的数据,对比学习目标函数形式一般如下:

- z i I z_i^I ziI:query embedding,即图像的编码特征也就是查询的特征编码
- { z j I } j = 1 , j ! = i B + 1 \{z_j^I\}_{j=1, j!=i}^{B+1} {zjI}j=1,j!=iB+1:key embedding,文本编码特征,
- z + I z_+^I z+I: z i I z_i^I ziI 的 positive key,每个 query embedding 只会有一个与之匹配的正样本,其他的都是负样本
- τ \tau τ:温度超参,越大则分布越平缓,会缩小不同样本的差距,越小则分布越尖锐,会增大输出的差距。
- 当 query 和唯一配对儿的正样本特征更相似,且和其他负样本都不相似的时候,loss 的值会比较低,反之 loss 会高
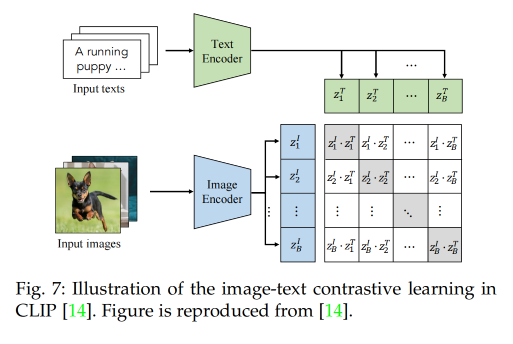
② Image-Text Contrastive Learning:
主要为了推近成对儿的 image 和 text 的距离,推远不成对儿的 image 和 text 距离,学习更好的 image-text 表达。
一般都是通过最小化对称的 image-text infoNCE loss 来实现,该 loss 能够通过 image 和 text 编码特征的内积来衡量 image 和 text 的相似程度,如图 7 所示:
L i n f o N C E I T = L I → T + L T → I L_{infoNCE}^{IT} = L_{I\to T} + L_{T\to I} LinfoNCEIT=LI→T+LT→I
- L I → T L_{I\to T} LI→T:是 query image 和 text key 的对比
- L T → I L_{T\to I} LT→I:是 query text 和 image key 的对比
假设给定一个 batch B B B image-text pairs:

- z I z^I zI :image embedding
- z T z^T zT:text embedding
③ Image-Text-Label Contrastive Learning
Image-Text-Label Contrastive Learning 引入有监督的对比学习到 image-text 对比学习中
定义如下:
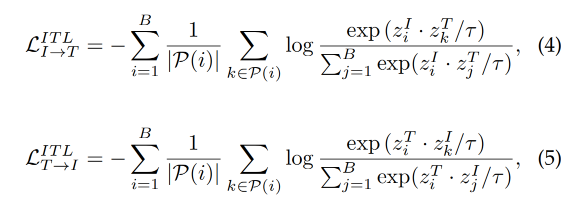
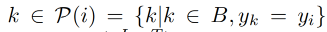
-
y 是 ( z I , z T ) (z^I, z^T) (zI,zT) 的类别标签
-
image-text-label infoNCE loss:
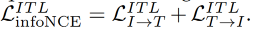
即会将 image、text、classification label 编码到一个相同的特征空间,如图 8 所示,能够同时使用有监督的基于 image label 的预训练和无监督的基于 image-text pairs 的 VLM 预训练

2、生成式目标函数
① Masked Image Modelling
② Masked Language Modelling
③ Masked Cross-Modal Modelling
3、对齐目标函数
对齐目标函数是通过 global image-text matching 或 local region-word matching 来对齐 image-text pair
① Image-text matching
实现全局的 image 和 text 的关联学习,可以使用 score function S ( . ) S(.) S(.) 来衡量 image 和 text 之间的 alignment probability
二分类 loss 如下:
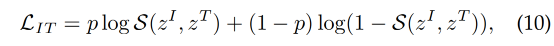
- p=1:image 和 text 是一对儿
- p=0:image 和 text 不是一对儿
加上给定一个 batch 的 image-text pairs,FLAVA[83] 通过分类器(binary classification loss)来实现对 image 和 text 的匹配
② Region-word matching
对 local cross-modal 关联建模(对 image region 和 word 建模),主要针对密集预测,如目标检测, loss 如下:
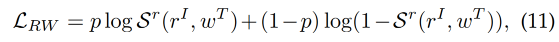
- ( r I , w T ) (r^I, w^T) (rI,wT) 是 region-word pair
- p=1 表示 region 和 word 是一对
- p=0 表示 region 和 word 不是一对
- S r ( . ) S^r(.) Sr(.) 表示 image region 和 word 之间的相似程度
例如 GLIP、FIBER、DetCLIP,使用 region-word alignment score 代替了 object classification logits,regional visual features 和 token-wise 特征的关联如图 12 所示。

2.2.3 评估和下游任务
1、zero-shot prediction
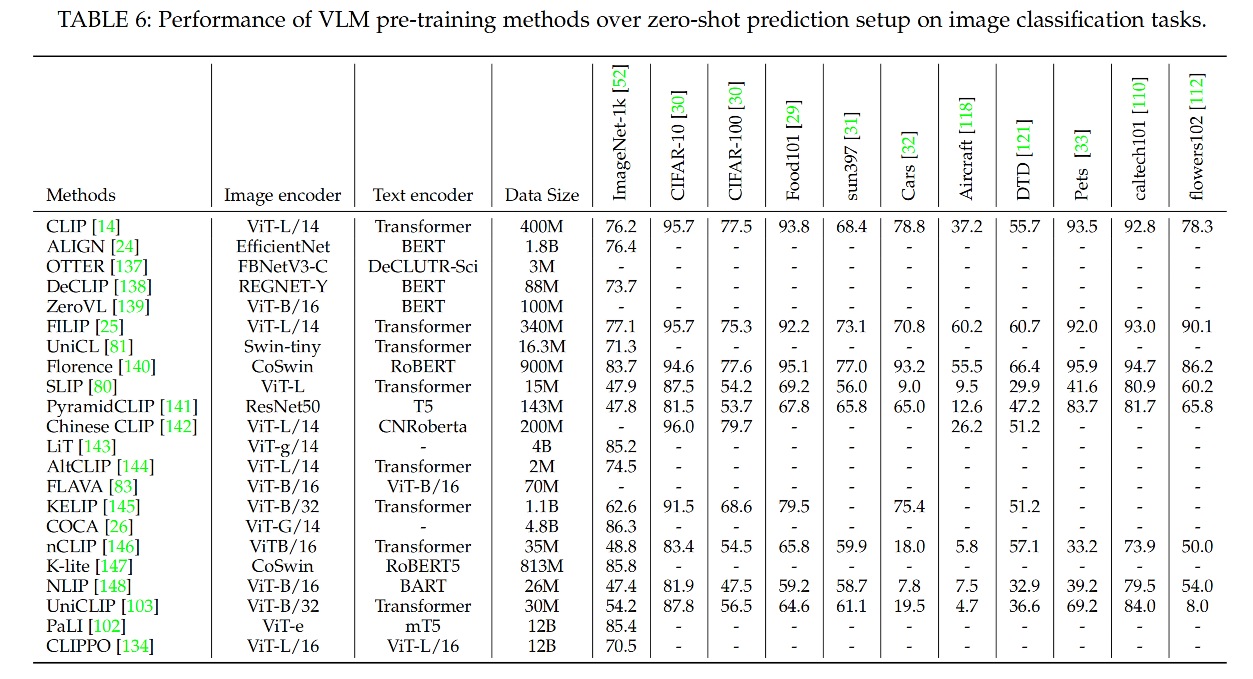
① 图像分类:是为了将图像分类到预定义的类别中。
VLM 通过对比 image 和 text 的编码特征来实现 zero-shot 图像分类,prompt 一般使用 “a photo of a [label]”
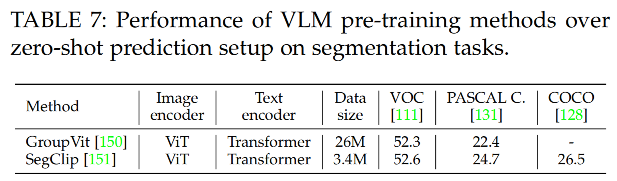
② 语义分割
VLM 模型通过对比 image pixels 和 text 的编码特征来实现 zero-shot 预测
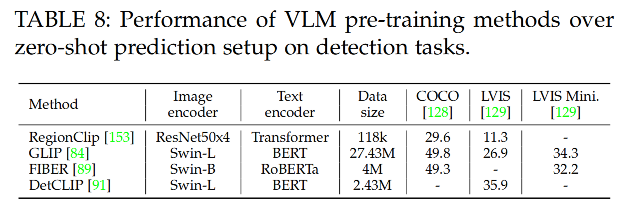
③ 目标检测
VLM 模型通过对比 object proposal 和 text 的 embedding 来实现目标检测
④ image-text 检索
2、Linear Probing
Linear Probing 也被用于 VLM 模型的评估,就是冻结预训练的 VLM,然后训练一个 linear classifier 来对 VLM-encoded embedding 进行分类,评估 VLM 的表达特征。
2.3 数据集
1、Image-text dataset


2、辅助数据集

三、迁移学习
- 有监督迁移学习
- 少样本监督迁移学习
- 无监督迁移学习
3.1 使用 prompt tuning 实现迁移学习
受启发于 NLP,VLM 也使用了 prompt learning 方法来实现对下游任务的适配
1、使用 text prompt tuning 进行迁移学习
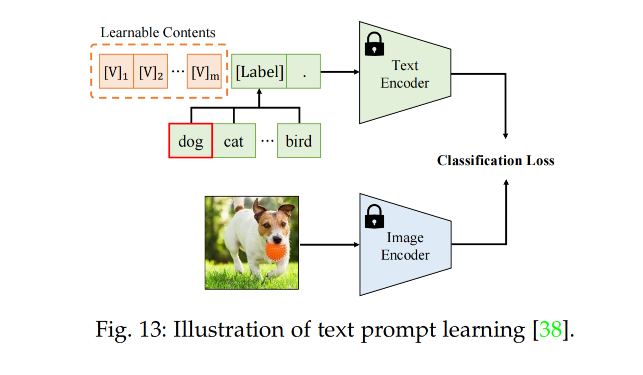
CoOp[38] 使用 learnable word vectors 来为每个类别学习,将类别标签 [label] 扩展到了句子,‘[V]1, [V]2, …, [V]m, [label]’,其中 [V] 表示 learnable word vectors(通过最小化分类 loss 来优化),如图 13 所示。
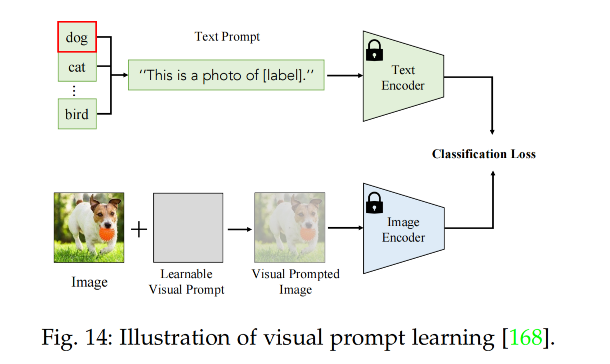
2、使用 visual prompt tuning 来进行迁移学习
比如 VP[168] 使用可学习的图像干扰 v 来修正输入图像 x I x^I xI,变为 x I + v x^I+v xI+v,通过调整 v 来最小化 loss
visual prompt tuning 能够将 pixel-level 带入下游任务,有利于密集预测任务
3、使用 Text-Visual prompt tuning 来进行迁移学习
如 UDP 同时优化 text 和 image prompt
3.2 通过特征适应来进行迁移学习
四、VLM 的知识蒸馏
VLM 的只是蒸馏是将 VLM 的通用的、鲁棒的知识蒸馏到 task-specific 模型上
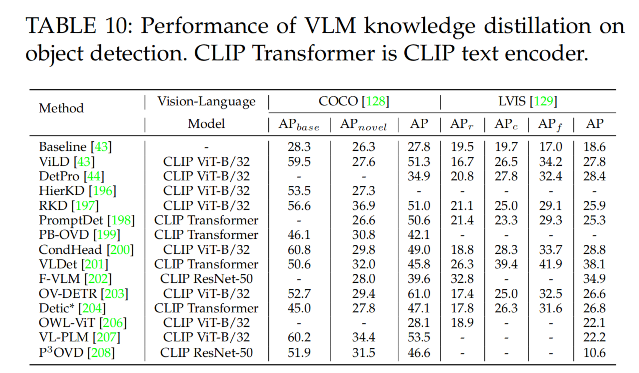
4.1 目标检测的知识蒸馏
开集目标检测是为了检测出任意文本描述的东西
一些 VLM 如 CLIP 是在超大尺度的 image-text pair 上训练的,能够覆盖很多的类别词汇
- 如 ViLD 将 VLM 的知识蒸馏到了一个两阶段检测器上
- HierKD 提出了层级 global-local 知识整理
- RKD 提出了 region-based 知识整理,能够对齐 region-level 和 image-level 的编码特征
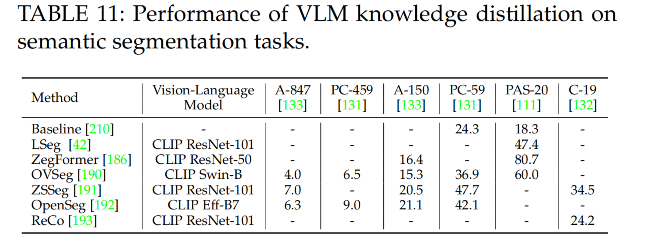
4.2 语义分割的知识蒸馏