一、FastDeploy的gitee地址
https://gitee.com/leiqing1/FastDeploy/blob/release/0.3.0/docs/cn/faq/use_sdk_on_windows.md#21-%E4%B8%8B%E8%BD%BD%E9%A2%84%E7%BC%96%E8%AF%91%E5%BA%93%E6%88%96%E8%80%85%E4%BB%8E%E6%BA%90%E7%A0%81%E7%BC%96%E8%AF%91%E6%9C%80%E6%96%B0%E7%9A%84sdk

https://gitee.com/leiqing1/FastDeploy/blob/release/0.3.0/docs/cn/build_and_install/download_prebuilt_libraries.md
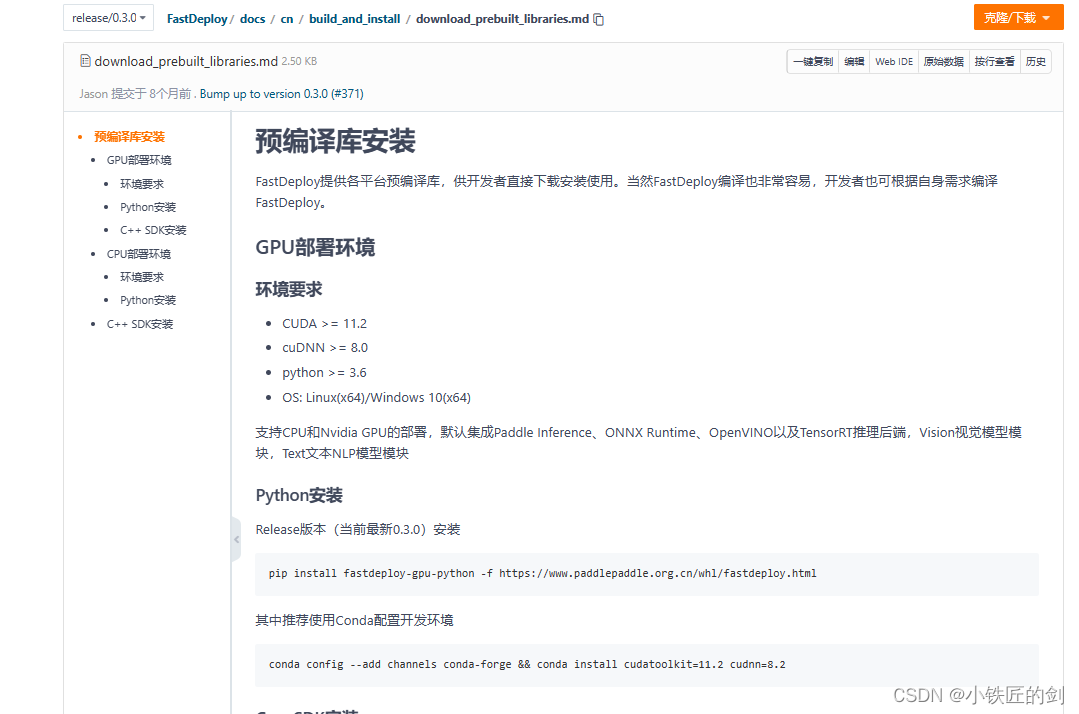
二、某知乎大神使用FastDeploy Windows c++ 预编译库进行部署的流程
https://zhuanlan.zhihu.com/p/598740190

三、FastDeploy的github地址
https://github.com/PaddlePaddle/FastDeploy
https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/faq/use_sdk_on_windows_build.md#VisualStudio2019
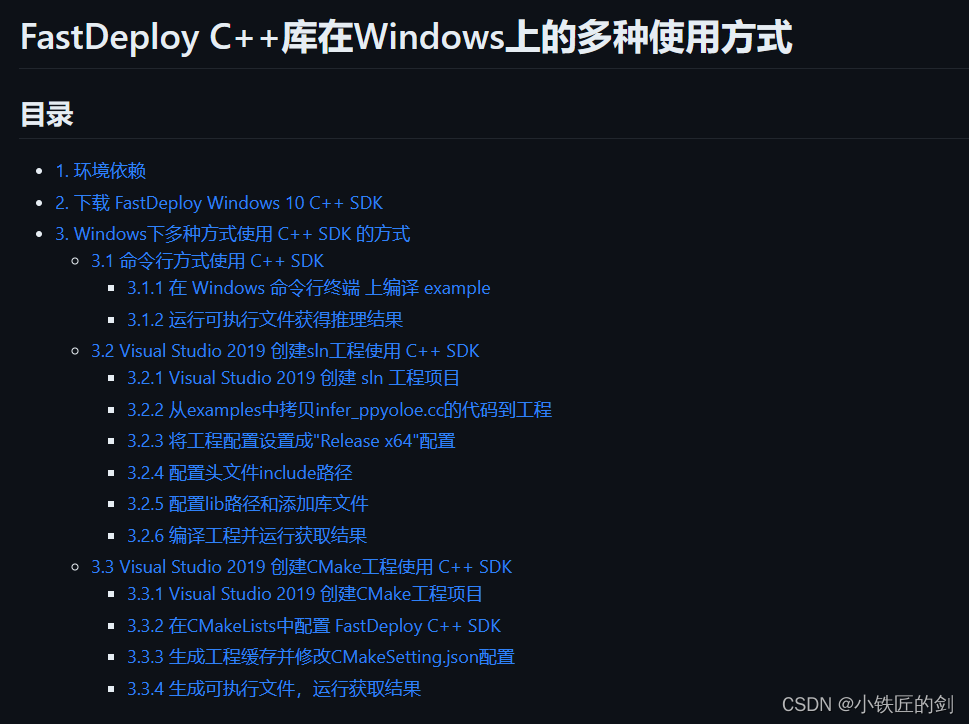
重要:参考以上链接完全可以自己实现部署,以下内容是为了方便个人理解。
FastDeploy使用Cmake进行部署的程序
project(infer_ppyoloe_demo C CXX)
cmake_minimum_required(VERSION 3.12)
# Only support "Release" mode now
set(CMAKE_BUILD_TYPE "Release")
# Set FastDeploy install dir
set(FASTDEPLOY_INSTALL_DIR "D:/qiuyanjun/fastdeploy-win-x64-gpu-0.2.1"
CACHE PATH "Path to downloaded or built fastdeploy sdk.")
# Set CUDA_DIRECTORY (CUDA 11.x) for GPU SDK
set(CUDA_DIRECTORY "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.7"
CACHE PATH "Path to installed CUDA Toolkit.")
include(${FASTDEPLOY_INSTALL_DIR}/FastDeploy.cmake)
include_directories(${FASTDEPLOY_INCS})
add_executable(infer_ppyoloe_demo ${PROJECT_SOURCE_DIR}/infer_ppyoloe.cpp)
target_link_libraries(infer_ppyoloe_demo ${FASTDEPLOY_LIBS})
# Optional: install all DLLs to binary dir.
install_fastdeploy_libraries(${CMAKE_CURRENT_BINARY_DIR}/Release)
需要编译使用的 infer_ppyoloe.cpp
#include "fastdeploy/vision.h"
#ifdef WIN32
const char sep = '\\';
#else
const char sep = '/';
#endif
void CpuInfer(const std::string& model_dir, const std::string& image_file) {
auto model_file = model_dir + sep + "model.pdmodel";
auto params_file = model_dir + sep + "model.pdiparams";
auto config_file = model_dir + sep + "infer_cfg.yml";
auto option = fastdeploy::RuntimeOption();
option.UseCpu();
auto model = fastdeploy::vision::detection::PPYOLOE(model_file, params_file,
config_file, option);
if (!model.Initialized()) {
std::cerr << "Failed to initialize." << std::endl;
return;
}
auto im = cv::imread(image_file);
fastdeploy::vision::DetectionResult res;
if (!model.Predict(im, &res)) {
std::cerr << "Failed to predict." << std::endl;
return;
}
std::cout << res.Str() << std::endl;
auto vis_im = fastdeploy::vision::VisDetection(im, res, 0.5);
cv::imwrite("vis_result.jpg", vis_im);
std::cout << "Visualized result saved in ./vis_result.jpg" << std::endl;
}
void KunlunXinInfer(const std::string& model_dir, const std::string& image_file) {
auto model_file = model_dir + sep + "model.pdmodel";
auto params_file = model_dir + sep + "model.pdiparams";
auto config_file = model_dir + sep + "infer_cfg.yml";
auto option = fastdeploy::RuntimeOption();
option.UseKunlunXin();
auto model = fastdeploy::vision::detection::PPYOLOE(model_file, params_file,
config_file, option);
if (!model.Initialized()) {
std::cerr << "Failed to initialize." << std::endl;
return;
}
auto im = cv::imread(image_file);
fastdeploy::vision::DetectionResult res;
if (!model.Predict(im, &res)) {
std::cerr << "Failed to predict." << std::endl;
return;
}
std::cout << res.Str() << std::endl;
auto vis_im = fastdeploy::vision::VisDetection(im, res, 0.5);
cv::imwrite("vis_result.jpg", vis_im);
std::cout << "Visualized result saved in ./vis_result.jpg" << std::endl;
}
void GpuInfer(const std::string& model_dir, const std::string& image_file) {
auto model_file = model_dir + sep + "model.pdmodel";
auto params_file = model_dir + sep + "model.pdiparams";
auto config_file = model_dir + sep + "infer_cfg.yml";
auto option = fastdeploy::RuntimeOption();
option.UseGpu();
auto model = fastdeploy::vision::detection::PPYOLOE(model_file, params_file,
config_file, option);
if (!model.Initialized()) {
std::cerr << "Failed to initialize." << std::endl;
return;
}
auto im = cv::imread(image_file);
fastdeploy::vision::DetectionResult res;
if (!model.Predict(im, &res)) {
std::cerr << "Failed to predict." << std::endl;
return;
}
std::cout << res.Str() << std::endl;
auto vis_im = fastdeploy::vision::VisDetection(im, res, 0.5);
cv::imwrite("vis_result.jpg", vis_im);
std::cout << "Visualized result saved in ./vis_result.jpg" << std::endl;
}
void TrtInfer(const std::string& model_dir, const std::string& image_file) {
auto model_file = model_dir + sep + "model.pdmodel";
auto params_file = model_dir + sep + "model.pdiparams";
auto config_file = model_dir + sep + "infer_cfg.yml";
auto option = fastdeploy::RuntimeOption();
option.UseGpu();
option.UseTrtBackend();
auto model = fastdeploy::vision::detection::PPYOLOE(model_file, params_file,
config_file, option);
if (!model.Initialized()) {
std::cerr << "Failed to initialize." << std::endl;
return;
}
auto im = cv::imread(image_file);
fastdeploy::vision::DetectionResult res;
if (!model.Predict(im, &res)) {
std::cerr << "Failed to predict." << std::endl;
return;
}
std::cout << res.Str() << std::endl;
auto vis_im = fastdeploy::vision::VisDetection(im, res, 0.5);
cv::imwrite("vis_result.jpg", vis_im);
std::cout << "Visualized result saved in ./vis_result.jpg" << std::endl;
}
int main(int argc, char* argv[]) {
if (argc < 4) {
std::cout
<< "Usage: infer_demo path/to/model_dir path/to/image run_option, "
"e.g ./infer_model ./ppyoloe_model_dir ./test.jpeg 0"
<< std::endl;
std::cout << "The data type of run_option is int, 0: run with cpu; 1: run "
"with gpu; 2: run with gpu and use tensorrt backend; 3: run with kunlunxin."
<< std::endl;
return -1;
}
if (std::atoi(argv[3]) == 0) {
CpuInfer(argv[1], argv[2]);
} else if (std::atoi(argv[3]) == 1) {
GpuInfer(argv[1], argv[2]);
} else if (std::atoi(argv[3]) == 2) {
TrtInfer(argv[1], argv[2]);
} else if (std::atoi(argv[3]) == 3) {
KunlunXinInfer(argv[1], argv[2]);
}
return 0;
}
编译之后需要运行时,需要的操作:
cd Release
infer_ppyoloe_demo.exe ppyoloe_crn_l_300e_coco 000000014439.jpg 0 # CPU
infer_ppyoloe_demo.exe ppyoloe_crn_l_300e_coco 000000014439.jpg 1 # GPU
infer_ppyoloe_demo.exe ppyoloe_crn_l_300e_coco 000000014439.jpg 2 # GPU + TensorRT







![读书笔记-《ON JAVA 中文版》-摘要17[第十七章 文件]](https://img-blog.csdnimg.cn/7913f53fd314422d8f612f3e3093d1b2.png)