Spark是一个基于内存的大数据计算框架,可以与Hadoop集成,提供更快速的数据处理能力。本文将介绍如何在三个Ubuntu系统上搭建一个Spark集群。
主要步骤包括:
- 准备工作:下载安装包,设置环境变量,解压安装包。
- 安装配置Spark:编辑配置文件,指定Master节点,Worker节点,CPU核数,内存大小等。
- 启动Spark集群:启动服务,查看状态,使用客户端连接。
一、准备工作
- 首先确保已经安装配置好Hadoop和Java。本文假设已经搭建一个三节点的Hadoop集群,它们的IP地址和主机名分别如下:
| IP地址 | 主机名 |
|---|---|
| 192.168.1.100 | hadoop100 |
| 192.168.1.200 | hadoop200 |
| 192.168.1.201 | hadoop201 |
- 然后下载spark-3.2.3-bin-hadoop3.2的安装包,可以从官网下载。
- 接着在hadoop100上将下载的安装包放到桌面,然后解压到/usr/local/spark目录下,例如:
tar -zxvf spark-3.2.3-bin-hadoop3.2.tgz -C /usr/local
mv /usr/local/spark-3.2.3-bin-hadoop3.2 /usr/local/spark
- 最后在hadoop100上设置SPARK_HOME环境变量,可以在/etc/profile文件中添加如下内容:
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
然后执行source /etc/profile命令使配置生效。
二、安装配置Spark
- 编辑$SPARK_HOME/conf/spark-env.sh文件,取消以下几行的注释,并修改其中的值:
包含 Spark History Server配置,查看任务执行历史信息,通过spark-submit或者Intellij IDEA提交任务,应用程序运行期间都可以通过管理页面查看具体运行细节,但是运行结束Web界面也失效。
export JAVA_HOME=/usr/local/java/jdk1.8.0_341 # 配置java环境变量 根据实际的JAVA_HOME路径修改
export SPARK_MASTER_HOST=hadoop100 # 设置Spark Master节点的主机名
export SPARK_MASTER_PORT=7077 # 指定主节点端口
export SPARK_WORKER_CORES=2 # 设置每个Worker节点可用的CPU核数
export SPARK_WORKER_MEMORY=4G # 指定内存大小
export SPARK_MASTER_WEBUI_PORT=8080#指定web访问端口
export SPARK_CONF_DIR=/usr/local/spark/conf
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-3.2.4/etc/hadoop # 添加Hadoop的配置文件路径
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.2.4/etc/hadoop
export YARN_CONF_DIR=/usr/local/hadoop/hadoop-3.2.4/etc/hadoop
export SPARK_HOME=/usr/local/spark
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/hadoop-3.2.4/bin/hadoop classpath)
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hadoop100:9000/log/spark/spark_directory"- 编辑$SPARK_HOME/conf/workers文件,添加以下内容:
# A Spark Worker will be started on each of the machines listed below.
hadoop100
hadoop200
hadoop201这里指定了三个节点都作为Spark的Worker节点,负责执行任务。
- 将配置好的Spark安装包分发到其他两个节点上,例如:
scp -r /usr/local/spark c914@hadoop200:/usr/local/
scp -r /usr/local/spark c914@hadoop200:/usr/local/
这里假设已经在三个节点上配置了免密登录,否则需要输入密码。
三、启动Spark集群
- 在hadoop上执行如下命令启动Spark集群:
start-all.sh
- 在任意一个节点上执行如下命令查看Spark集群的状态:
jps
如果输出中显示了Master和Worker进程,说明该节点已经加入到集群中。
- 在任意一个节点上执行如下命令使用命令行客户端连接到Spark集群:
spark-shell --master spark://master:7077
如果连接成功,会进入一个交互式的shell环境,可以输入一些命令来操作Spark,例如:
scala> val rdd = sc.parallelize(1 to 10)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> val sum = rdd.reduce(_ + _)
sum: Int = 55
scala> :quit
Quitting...四、管理界面
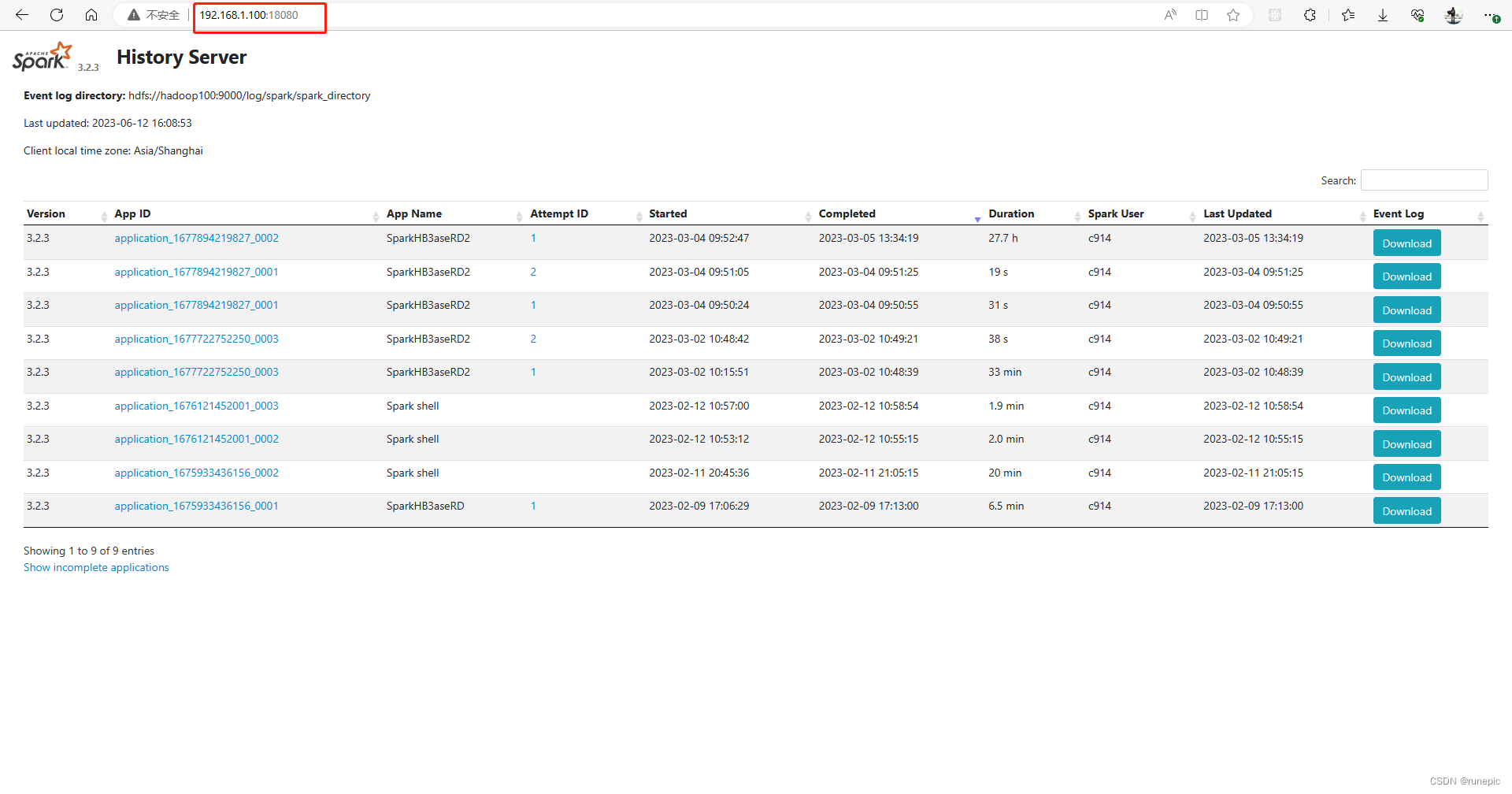
可以到浏览器中查看管理网页:
http://192.168.1.100:8080/
IP地址:8080/

历史任务网页:
http://192.168.1.100:18080/
IP地址:18080/



![[元带你学: eMMC协议详解 13] 数据读(Read) 写(Write) 详解](https://img-blog.csdnimg.cn/img_convert/262abfa94e2b5642120b21810384ce4b.png)