一、MongoDB介绍
1、什么是MongoDB

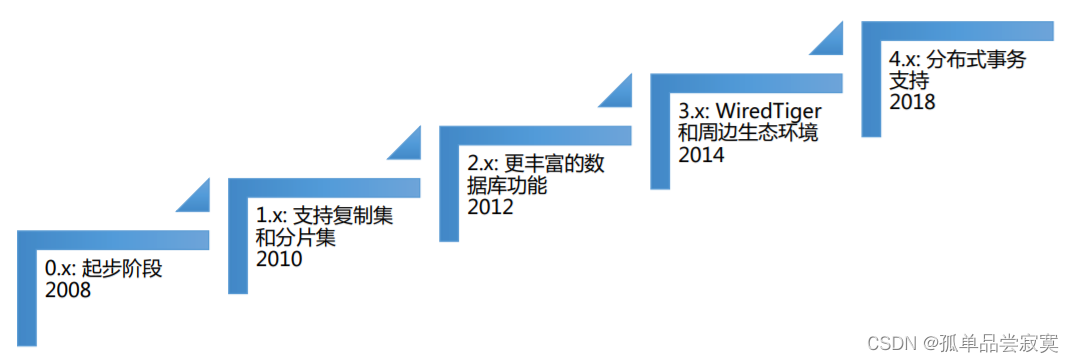
2、MongoDB 版本变迁
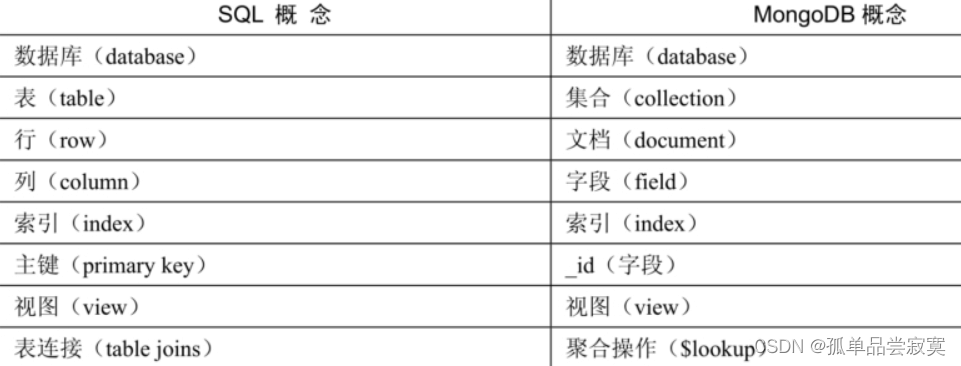
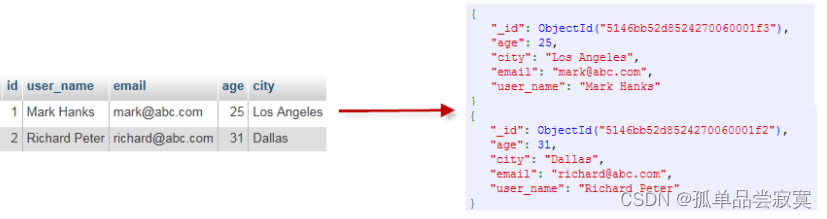
3、MongoDB vs 关系型数据库 概念
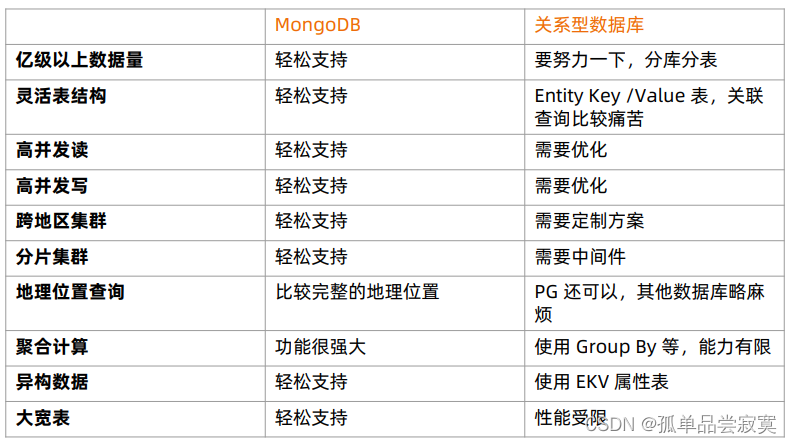
4、MongoDB技术优势
快速:最简单快速的开发方式

灵活:快速响应业务变化
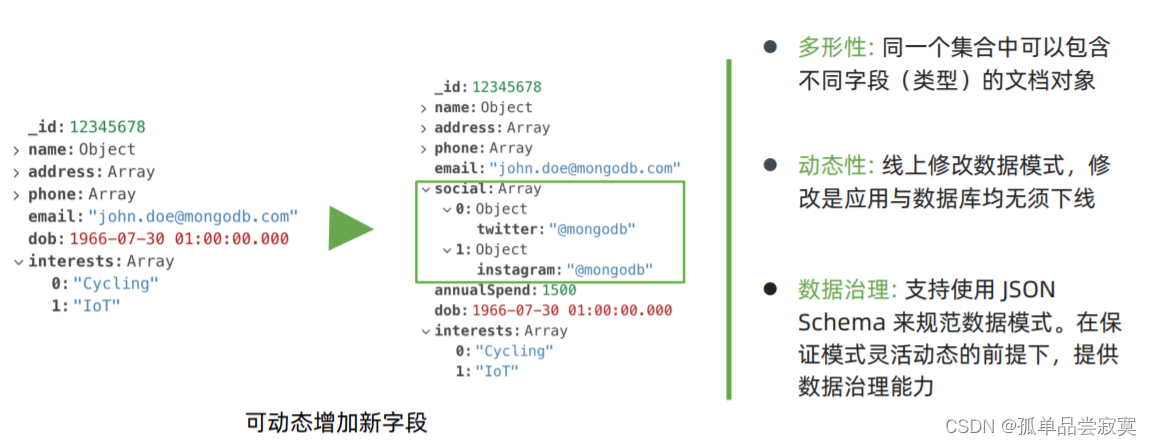
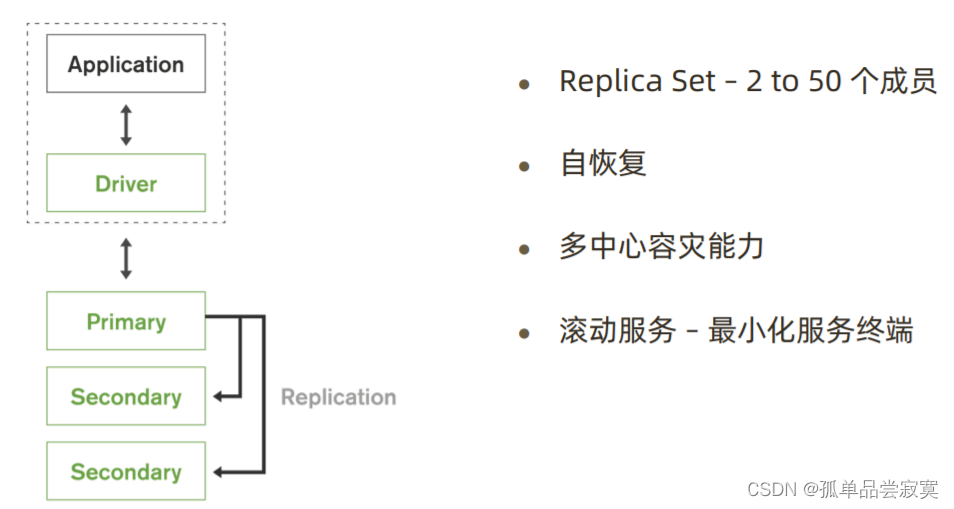
MongoDB优势:原生的高可用
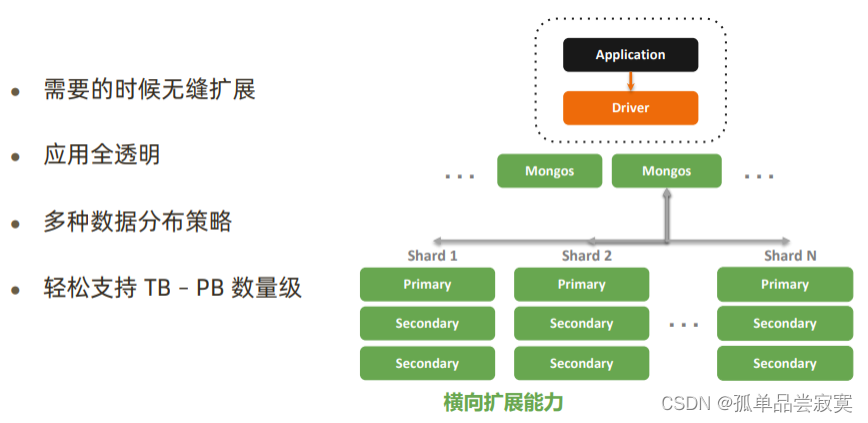
MongoDB优势:横向扩展能力
5、MongoDB应用场景


只要有一项需求满足就可以考虑使用MongoDB,匹配越多,选择MongoDB越合适
二、MongoDB快速开始
1、linux安装MongoDB
#下载MongoDB
wget https://fastdl.mongodb.org/linux/mongodb‐linux‐x86_64‐rhel70‐4.4.9.tgz
tar ‐zxvf mongodb‐linux‐x86_64‐rhel70‐4.4.9.tgz启动MongoDB Server
#创建dbpath和logpath
mkdir ‐p /mongodb/data /mongodb/log
#进入mongodb目录,启动mongodb服务
bin/mongod ‐‐port=27017 ‐‐dbpath=/mongodb/data ‐‐logpath=/mongodb/log/mon
godb.log \ ‐‐bind_ip=0.0.0.0 ‐‐fork
export MONGODB_HOME=/usr/local/soft/mongodb
PATH=$PATH:$MONGODB_HOME/bisystemLog:
destination: file
path: /mongodb/log/mongod.log # log path
logAppend: true
storage:
dbPath: /mongodb/data # data directory
engine: wiredTiger #存储引擎
journal: #是否启用journal日志
enabled: true
net:
bindIp: 0.0.0.0
port: 27017 # port
processManagement:
fork: truemongod ‐f /mongodb/conf/mongo.confmongod ‐‐port=27017 ‐‐dbpath=/mongodb/data ‐‐shutdown
use admin
db.shutdownServer()
2、Mongo shell使用
bin/mongo ‐‐port=27017
bin/mongo localhost:27017
| 命令 | 说明 |
| show dbs | show databases | 显示数据库列表 |
| use 数据库名 | 切换数据库 ,如果不存在创建数据库 |
| db.dropDatabase() | 删除数据库 |
| show collections | show tables | 显示当前数据库的集合列表 |
| db.集合名.stats() | 查看集合详情 |
| db.集合名.drop() | 删除集合 |
| show users | 显示当前数据库的用户列表 |
| show roles | 显示当前数据库的角色列表 |
| show profile | 显示最近发生的操作 |
| load("xxx.js") | 执行一个JavaScript脚本文件 |
| exit | quit() | 退出当前shell |
| help | 查看mongodb支持哪些命令 |
| db.help() | 查询当前数据库支持的方法 |
| db.集合名.help() | 显示集合的帮助信息 |
| db.version() | 查看数据库版本 |
数据库操作
#查看所有库
show dbs
# 切换到指定数据库,不存在则创建
use test
# 删除当前数据库
db.dropDatabase()#查看集合
show collections
#创建集合
db.createCollection("emp")
#删除集合
db.emp.drop()db.createCollection(name, options)| 字段 | 类型 | 描述 |
| capped | 布尔 | (可选) 如果为true ,则创建固定集合。固定集合是指有着固定大小的 集合 ,当达到最大值时 ,它会自动覆盖最早的文档。 |
| size | 数值 | (可选) 为固定集合指定一个最大值 (以字节计) 。 如果 capped 为 true ,也需要指定该字段。 |
| max | 数值 | (可选) 指定固定集合中包含文档的最大数量。 |
注意: 当集合不存在时,向集合中插入文档也会创建集合
3、安全认证
创建管理员账号
# 设置管理员用户名密码需要切换到admin库
use admin
#创建管理员
db.createUser({user:"yanqiuxiang",pwd:"yanqiuxiang",roles:["root"]})
# 查看当前数据库所有用户信息
show users
#显示可设置权限
show roles
#显示所有用户
db.system.users.find()
> db.createUser({user:"yanqiuxiang",pwd:"yanqiuxiang",roles:["root"]})
Successfully added user: { "user" : "yanqiuxiang", "roles" : [ "root" ] }
> show users
{
"_id" : "admin.yanqiuxiang",
"userId" : UUID("c9c757be-22a4-4f90-89f3-48070ed3e688"),
"user" : "yanqiuxiang",
"db" : "admin",
"roles" : [
{
"role" : "root",
"db" : "admin"
}
],
"mechanisms" : [
"SCRAM-SHA-1",
"SCRAM-SHA-256"
]
}
db.dropUser("yanqiuxiang")
#删除当前数据库所有用户
db.dropAllUser()db.auth("yanqiuxiang","yanqiuxiang")
1
use appdb
db.createUser({user:"appdb",pwd:"yanqiuxiang",roles:["dbOwner"]})
Successfully added user: { "user" : "appdb", "roles" : [ "dbOwner" ] }
mongod ‐f /mongodb/conf/mongo.conf ‐‐authmongo 192.168.65.174:27017 ‐u yanqiuxiang ‐p yanqiuxiang ‐‐authenticationDatabase=admin[root@192 bin]# mongo 127.0.0.1:27017 -u yanqiuxiang -p yanqiuxiang --authenticationDatabase=admin
MongoDB shell version v4.4.9
connecting to: mongodb://127.0.0.1:27017/test?authSource=admin&compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("132ab311-b2ec-4aae-a50c-70a4d8742ec0") }
MongoDB server version: 4.4.9
---
The server generated these startup warnings when booting:
2023-06-16T21:35:20.012+08:00: Access control is not enabled for the database. Read and write access to data and configuration is unrestricted
2023-06-16T21:35:20.012+08:00: You are running this process as the root user, which is not recommended
2023-06-16T21:35:20.013+08:00: /sys/kernel/mm/transparent_hugepage/enabled is 'always'. We suggest setting it to 'never'
2023-06-16T21:35:20.013+08:00: /sys/kernel/mm/transparent_hugepage/defrag is 'always'. We suggest setting it to 'never'
2023-06-16T21:35:20.013+08:00: Soft rlimits too low
2023-06-16T21:35:20.013+08:00: currentValue: 1024
2023-06-16T21:35:20.013+08:00: recommendedMinimum: 64000
---
---
Enable MongoDB's free cloud-based monitoring service, which will then receive and display
metrics about your deployment (disk utilization, CPU, operation statistics, etc).
The monitoring data will be available on a MongoDB website with a unique URL accessible to you
and anyone you share the URL with. MongoDB may use this information to make product
improvements and to suggest MongoDB products and deployment options to you.
To enable free monitoring, run the following command: db.enableFreeMonitoring()
To permanently disable this reminder, run the following command: db.disableFreeMonitoring()
---
>
三、MongoDB文档操作
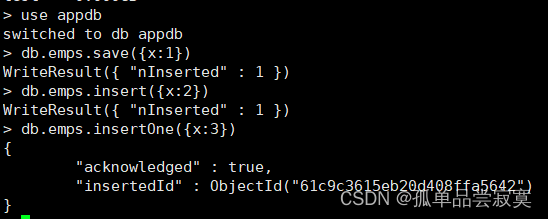
1、插入文档
db.collection.insertOne(
<document>,
{
writeConcern: <document>
}
)
db.collection.insertMany(
[ <document 1> , <document 2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
)
var tags = ["nosql","mongodb","document","developer","popular"];
var types = ["technology","sociality","travel","novel","literature"];
var books=[];
for(var i=0;i<50;i++){
var typeIdx = Math.floor(Math.random()*types.length);
var tagIdx = Math.floor(Math.random()*tags.length);
var favCount = Math.floor(Math.random()*100);
var book = {
title: "book‐"+i,
type: types[typeIdx],
tag: tags[tagIdx],
favCount: favCount,
author: "xxx"+i
};
books.push(book)
}
db.books.insertMany(books);load("books.js")db.collection.find(query, projection)query :可选,使用查询操作符指定查询条件
projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。投影时,_id为1的时候,其他字段必须是1;_id是0的时候,其他字段可以是0;如果没有_id字段约束,多个其他字段必须同为0或同为1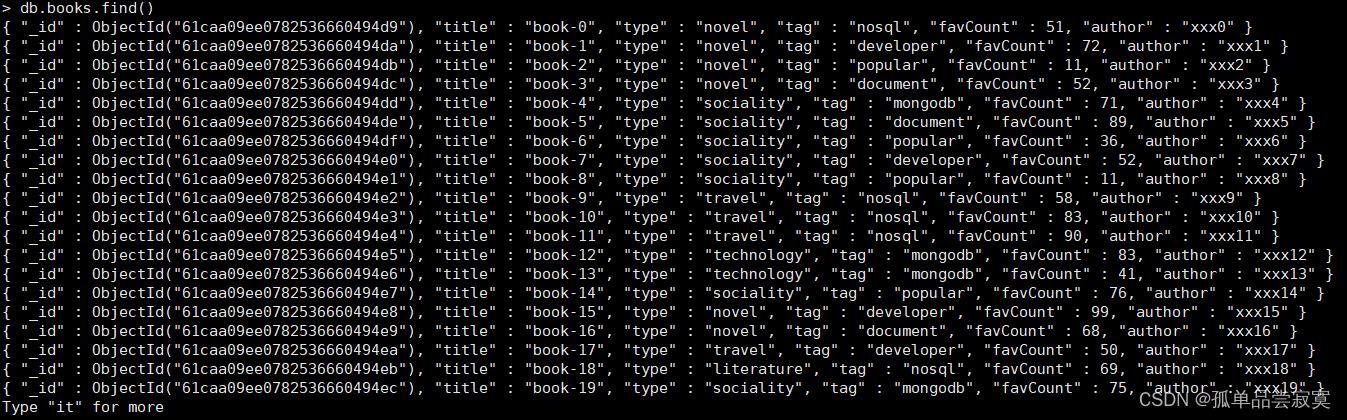
db.collection.findOne(query, projection)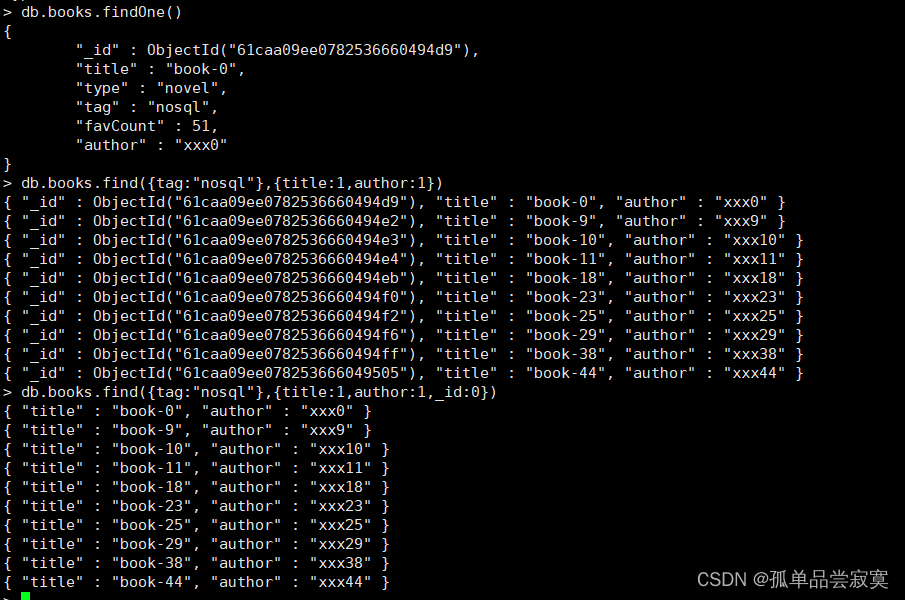
如果你需要以易读的方式来读取数据,可以使用pretty)方法,语法格式如下:
db.collection.find().pretty()注意:pretty()方法以格式化的方式来显示所有文档
#查询带有nosql标签的book文档:
db.books.find({tag:"nosql"})
#按照id查询单个book文档:
db.books.find({_id:ObjectId("61caa09ee0782536660494d9")})
#查询分类为“travel”、收藏数超过60个的book文档:
db.books.find({type:"travel",favCount:{$gt:60}})查询条件对照表
| SQL | MQL |
| a= 1 | {a: 1} |
| a < > 1 | {a: {$ne: 1}} |
| a > 1 | {a: {$gt: 1}} |
| a > = 1 | {a: {$gte: 1}} |
| a < 1 | {a: {$lt: 1}} |
| a < = 1 | {a: {$lte: 1}} |
查询逻辑对照表
| SQL | MQL |
| a = 1 AND b = 1 | {a: 1, b: 1}或{$and: [{a: 1}, {b: 1}]} |
| a = 1 OR b = 1 | {$or: [{a: 1}, {b: 1}]} |
| a IS NULL | {a: {$exists: false}} |
| a IN (1, 2, 3) | {a: {$in: [1, 2, 3]}} |
查询逻辑运算符
$lt: 存在并小于
$lte: 存在并小于等于
$gt: 存在并大于
$gte: 存在并大于等于
$ne: 不存在或存在但不等于
$in: 存在并在指定数组中
$nin: 不存在或不在指定数组中
$or: 匹配两个或多个条件中的一个
$and: 匹配全部条件

指定排序
在 MongoDB 中使用 sort() 方法对数据进行排序
#指定按收藏数(favCount)降序返回
db.books.find({type:"travel"}).sort({favCount:‐1})1 为升序排列 ,而 -1 是用于降序排列

分页查询
skip用于指定跳过记录数 , limit则用于限定返回结果数量。可以在执行find命令的同时指定 skip、 limit参数 ,以此实现分页的功能。比如 ,假定每页大小为8条 ,查询第3页的book文 档:
db.books.find().skip(8).limit(4)
处理分页问题 – 巧分页
数据量大的时候 ,应该避免使用skip/limit形式的分页。
替代方案:使用查询条件+唯一排序条件;
例如:
第一页:db.posts.find({}).sort({_id: 1}).limit(20);
第二页:db.posts.find({_id: {$gt: <第一页最后一个_id>}}).sort({_id: 1}).limit(20); 第三页:db.posts.find({_id: {$gt: <第二页最后一个_id>}}).sort({_id: 1}).limit(20);
处理分页问题 – 避免使用 count
尽可能不要计算总页数 ,特别是数据量大和查询条件不能完整命中索引时。
考虑以下场景:假设集合总共有 1000w 条数据 ,在没有索引的情况下考虑以下查询:
db.coll.find({x: 100}).limit(50);
db.coll.count({x: 100});前者只需要遍历前 n 条 ,直到找到 50 条 x =100 的文档即可结束;后者需要遍历完 1000w 条找到所有符合要求的文档才能得到结果。 为了计算总
页数而进行的 count() 往往是拖慢页面整体加载速度的原因
MongoDB 使用 $regex 操作符来设置匹配字符串的正则表达式。
1 //使用正则表达式查找type包含 so 字符串的book
2 db.books.find({type:{$regex:"so"}})
3 //或者
4 db.books.find({type:/so/})
| 操作符 | 格式 | 描述 |
| $set | {$set:{field:value}} | 指定一个键并更新值 ,若键不存在则创建 |
| $unset | {$unset : {field : 1 }} | 删除一个键 |
| $inc | {$inc : {field : value } } | 对数值类型进行增减 |
| $rename | {$rename : {old_field_name : new_field_name } } | 修改字段名称 |
| $push | { $push : {field : value } } | 将数值追加到数组中 ,若数组不存在则会进行 初始化 |
| $pushAll | {$pushAll : {field : value_array }} | 追加多个值到一个数组字段内 |
| $pull | {$pull : {field : _value } } | 从数组中删除指定的元素 |
| $addToSet | {$addToSet : {field : value } } | 添加元素到数组中 ,具有排重功能 |
| $pop | {$pop : {field : 1 }} | 删除数组的第一个或最后一个元素 |
更新单个文档
某个book文档被收藏了 ,则需要将该文档的favCount字段自增
db.books.update({_id:ObjectId("61caa09ee0782536660494d9")},{$inc:{favCoun t:1}}
![]()
更新多个文档

update命令的选项配置较多 ,为了简化使用还可以使用一些快捷命令:
updateOne:更新单个文档。
updateMany:更新多个文档。
replaceOne:替换单个文档。
upsert是一种特殊的更新 ,其表现为如果目标文档不存在 ,则执行插入命令。
1 db.books.update(
2 {title:"my book"},
3 {$set:{tags:["nosql","mongodb"],type:"none",author:"fox"}}, 4 {upsert:true}
5 )
nMatched、 nModified都为0 ,表示没有文档被匹配及更新 , nUpserted=1提示执行了 upsert动作
update命令中的更新描述 (update) 通常由操作符描述 ,如果更新描述中不包含任何操作 符 ,那么MongoDB会实现文档的replace语义
findAndModify兼容了查询和修改指定文档的功能 ,findAndModify只能更新单个文档
| 1 | //将某个book文档的收藏数 (favCount) 加1 |
| 2 3 4 | db.books.findAndModify({ query:{_id:ObjectId("61caa09ee0782536660494dd")}, update:{$inc:{favCount:1}} |
| 5 | }) |
该操作会返回符合查询条件的文档数据 ,并完成对文档的修改。
默认情况下 ,findAndModify会返回修改前的“旧”数据。如果希望返回修改后的数据, 则可以指定new选项
| 1 | db.books.findAndModify({ |
| 2 3 4 | query:{_id:ObjectId("61caa09ee0782536660494dd")}, update:{$inc:{favCount:1}}, new: true |
| 5 | }) |
与findAndModify语义相近的命令如下:
findOneAndUpdate:更新单个文档并返回更新前 (或更新后) 的文档。
findOneAndReplace:替换单个文档并返回替换前 (或替换后) 的文档。
remove 命令需要配合查询条件使用;
匹配查询条件的文档会被删除;
指定一个空文档条件会删除所有文档;
示例:
1 db.user.remove({age:28})// 删除age 等于28的记录
2 db.user.remove({age:{$lt:25}}) // 删除age 小于25的记录
3 db.user.remove( { } ) // 删除所有记录
4 db.user.remove() //报错
remove命令会删除匹配条件的全部文档 ,如果希望明确限定只删除一个文档 ,则需要指定 justOne参数 ,命令格式如下:
1 db.collection.remove(query,justOne)
例如:删除满足type:novel条件的首条记录
官方推荐使用 deleteOne() 和 deleteMany() 方法删除文档 ,语法格式如下:
1 db.books.deleteMany ({}) //删除集合下全部文档
2 db.books.deleteMany ({ type:"novel" }) //删除 type等于 novel 的全部文档
3 db.books.deleteOne ({ type:"novel" }) //删除 type等于novel 的一个文档
注意: remove、deleteMany等命令需要对查询范围内的文档逐个删除 ,如果希望删除整 个集合 ,则使用drop命令会更加高效
remove、deleteOne等命令在删除文档后只会返回确认性的信息 ,如果希望获得被删除的 文档 ,则可以使用findOneAndDelete命令
除了在结果中返回删除文档 ,findOneAndDelete命令还允许定义“删除的顺序” ,即按照 指定顺序删除找到的第一个文档
remove、deleteOne等命令只能按默认顺序删除 ,利用这个特性 ,findOneAndDelete可 以实现队列的先进先出。
文档操作最佳实践
关于文档结构
防止使用太长的字段名 (浪费空间)
防止使用太深的数组嵌套 (超过2层操作比较复杂)
不使用中文 ,标点符号等非拉丁字母作为字段名
关于写操作
update 语句里只包括需要更新的字段
尽可能使用批量插入来提升写入性能
使用TTL自动过期日志类型的数据
思考: MongoDB为什么会使用BSON?
JSON是当今非常通用的一种跨语言Web数据交互格式 ,属于ECMAScript标准规范的 一个子集。JSON (JavaScript Object Notation, JS对象简谱) 即JavaScript对象表示法, 它是JavaScript对象的一种文本表现形式。
作为一种轻量级的数据交换格式 ,JSON的可读性非常好 ,而且非常便于系统生成和解
析 ,这些优势也让它逐渐取代了XML标准在Web领域的地位 ,当今许多流行的Web应用开 发框架 ,如SpringBoot都选择了JSON作为默认的数据编/解码格式。
JSON只定义了6种数据类型:
string: 字符串
number : 数值
object: JS的对象形式 ,用{key:value}表示 ,可嵌套
array: 数组 ,JS的表示方式[value] ,可嵌套
true/false: 布尔类型
null: 空值
大多数情况下 ,使用JSON作为数据交互格式已经是理想的选择 ,但是JSON基于文本 的解析效率并不是最好的 ,在某些场景下往往会考虑选择更合适的编/解码格式 ,一些做法 如:
在微服务架构中 ,使用gRPC (基于Google的Protobuf) 可以获得更好的网络 利用率。
分布式中间件、数据库 ,使用私有定制的TCP数据包格式来提供高性能、低延时 的计算能力。
BSON由10gen团队设计并开源 , 目前主要用于MongoDB数据库。 BSON ( Binary JSON) 是二进制版本的JSON ,其在性能方面有更优的表现。 BSON在许多方面和JSON保 持一致 ,其同样也支持内嵌的文档对象和数组结构。二者最大的区别在于JSON是基于文本 的 ,而BSON则是二进制 (字节流) 编/解码的形式。在空间的使用上 , BSON相比JSON并 没有明显的优势。
MongoDB在文档存储、命令协议上都采用了BSON作为编/解码格式 ,主要具有如下 优势:
类JSON的轻量级语义 ,支持简单清晰的嵌套、数组层次结构 ,可以实现模式灵
活的文档结构。
更高效的遍历 , BSON在编码时会记录每个元素的长度 ,可以直接通过seek操作 进行元素的内容读取 ,相对JSON解析来说 ,遍历速度更快。
更丰富的数据类型 ,除了JSON的基本数据类型 , BSON还提供了 MongoDB所需的一些扩展类型 ,比如日期、二进制数据等 ,这更加方便数据的表示 和操作。
BSON的数据类型
MongoDB中 ,一个BSON文档最大大小为16M ,文档嵌套的级别不超过100
BSON Types — MongoDB Manual
| Type | Number | Alias | Notes |
| Double | 1 | "double" | |
| String | 2 | "string" | |
| Object | 3 | "object" | |
| Array | 4 | "array" | |
| Binary data | 5 | "binData" | 二进制数据 |
| Undefined | 6 | "undefined" | Deprecated. |
| ObjectId | 7 | "objectId" | 对象ID ,用于创建文档ID |
| Boolean | 8 | "bool" | |
| Date | 9 | "date" | |
| Null | 10 | "null" | |
| Regular Expression | 11 | "regex" | 正则表达式 |
| DBPointer | 12 | "dbPointer" | Deprecated. |
| JavaScript | 13 | "javascript" | |
| Symbol | 14 | "symbol" | Deprecated. |
| JavaScript code with scope | 15 | "javascriptWithScope" | Deprecated in MongoDB 4.4. |
| 32-bit integer | 16 | "int" | |
| Timestamp | 17 | "timestamp" | |
| 64-bit integer | 18 | "long" | |
| Decimal128 | 19 | "decimal" | New in version 3.4. |
| Min key | -1 | "minKey" | 表示一个最小值 |
| Max key | 127 | "maxKey" | 表示一个最大值 |
$type操作符
$type操作符基于BSON类型来检索集合中匹配的数据类型 ,并返回结果。
1 db.books.find({"title" : {$type : 2}}) 2 //或者
3 db.books.find({"title" : {$type : "string"}})
MongoDB的日期类型使用UTC ( Coordinated Universal Time) 进行存储 ,也就是+0时 区的时间。
使用new Date与ISODate最终都会生成ISODate类型的字段 (对应于UTC时间)
MongoDB集合中所有的文档都有一个唯一的_id字段 ,作为集合的主键。在默认情况
下 ,_id字段使用ObjectId类型 ,采用16进制编码形式 ,共12个字节。
为了避免文档的_id字段出现重复 ,ObjectId被定义为3个部分:
4字节表示Unix时间戳 (秒) 。
5字节表示随机数 (机器号+进程号唯一) 。
3字节表示计数器 (初始化时随机) 。
大多数客户端驱动都会自行生成这个字段 ,比如MongoDB Java Driver会根据插入的 文档是否包含_id字段来自动补充ObjectId对象。这样做不但提高了离散性 ,还可以降低 MongoDB服务器端的计算压力。在ObjectId的组成中 , 5字节的随机数并没有明确定义, 客户端可以采用机器号、进程号来实现:
| 属性/方法 | 描述 |
| str | 返回对象的十六进制字符串表示。 |
| ObjectId.getTimestamp() | 将对象的时间戳部分作为日期返回。 |
| ObjectId.toString() | 以字符串文字“”的形式返回 JavaScript 表示ObjectId(...)。 |
| ObjectId.valueOf() | 将对象的表示形式返回为十六进制字符串。返回的字符串是str属性。 |
生成一个新的 ObjectId
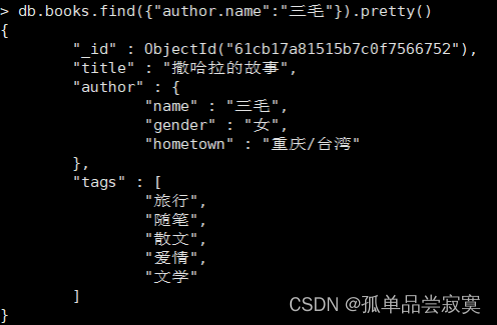
一个文档中可以包含作者的信息 ,包括作者名称、性别、家乡所在地 ,一个显著的优点是, 当我们查询book文档的信息时 ,作者的信息也会一并返回。
1 db.books.insert({
2 title: "撒哈拉的故事",
3 author: {
4 name:"三毛",
5 gender:"女",
6 hometown:"重庆"
7 }
8 })
查询三毛的作品
修改三毛的家乡所在地
除了作者信息 ,文档中还包含了若干个标签 ,这些标签可以用来表示文档所包含的一些特 征 ,如豆瓣读书中的标签 (tag)

增加tags标签
查询数组元素
db.books.find({"author.name":"三毛"},{title:1,tags:1}) 3 #利用$slice获取最后一个tag
db.books.find({"author.name":"三毛"},{title:1,tags:{$slice: ‐1}})
$silice是一个查询操作符 ,用于指定数组的切片方式

数组末尾追加元素 ,可以使用$push操作符
$push操作符可以配合其他操作符 ,一起实现不同的数组修改操作 ,比如和$each操作符配 合可以用于添加多个元素
如果加上$slice操作符 ,那么只会保留经过切片后的元素

根据元素查询
#会查出所有包含伤感的文档
db.books.find({tags:"伤感"})
# 会查出所有同时包含"伤感","想象力"的文档
数组元素可以是基本类型 ,也可以是内嵌的文档结构
{
tags:[
{tagKey:xxx,tagValue:xxxx},
{tagKey:xxx,tagValue:xxxx}
]
}
这种结构非常灵活 ,一个很适合的场景就是商品的多属性表示
一个商品可以同时包含多个维度的属性 ,比如尺码、颜色、风格等 ,使用文档可以表示为:
db.goods.insertMany([{
name:"羽绒服",
tags:[
{tagKey:"size",tagValue:["M","L","XL","XXL","XXXL"]},
{tagKey:"color",tagValue:["黑色","宝蓝"]},
{tagKey:"style",tagValue:"韩风"}
]
},{
name:"羊毛衫",
tags:[
{tagKey:"size",tagValue:["L","XL","XXL"]},
{tagKey:"color",tagValue:["蓝色","杏色"]},
{tagKey:"style",tagValue:"韩风"}
]以上的设计是一种常见的多值属性的做法 ,当我们需要根据属性进行检索时 ,需要用到
$elementMatch操作符:
1 #筛选出color=黑色的商品信息
2 db.goods.find({
3 tags:{
4 $elemMatch:{tagKey:"color",tagValue:"黑色"}
5 }
6 })
如果进行组合式的条件检索 ,则可以使用多个$elemMatch操作符:
1 # 筛选出color=蓝色,并且size=XL的商品信息
2 db.goods.find({
3 tags:{
4 $all:[
5 {$elemMatch:{tagKey:"color",tagValue:"黑色"}},
6 {$elemMatch:{tagKey:"size",tagValue:"XL"}}
7 ]
8 }
9 })
固定集合 (capped collection) 是一种限定大小的集合 ,其中capped是覆盖、限额的意 思。跟普通的集合相比 ,数据在写入这种集合时遵循FIFO原则。可以将这种集合想象为一 个环状的队列 ,新文档在写入时会被插入队列的末尾 ,如果队列已满 ,那么之前的文档就会 被新写入的文档所覆盖。通过固定集合的大小 ,我们可以保证数据库只会存储“限额”的数
据 ,超过该限额的旧数据都会被丢弃。
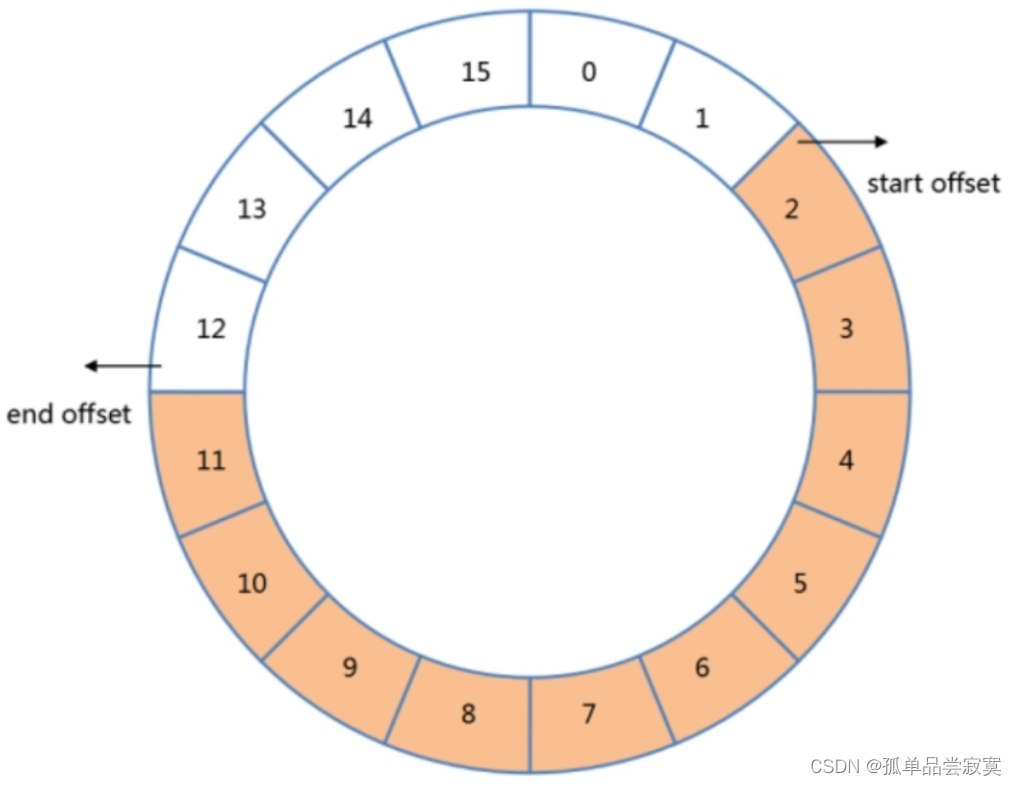
创建固定集合
db.createCollection("logs",{capped:true,size:4096,max:10})max:指集合的文档数量最大值 ,这里是10
size:指集合的空间占用最大值 ,这里是4096字节 (4KB)
这两个参数会同时对集合的上限产生影响。也就是说 ,只要任一条件达到阈值都会认为 集合已经写满。其中size是必选的 ,而max则是可选的。
可以使用collection.stats命令查看文档的占用空间
db.logs.stats()