来源:投稿 作者:小灰灰
编辑:学姐

论文标题:TraND: Transferable Neighborhood Discovery for Unsupervised Cross-domain Gait Recognition
论文链接: https://arxiv.org/pdf/2102.04621v1.pdf
步态识别开始应用在公共场域身份识别中。
步态识别,俗称“走姿”识身份,不同人的“走姿”是不一样的,走姿是人的“另一种身份”。
另外,人在不同场域的步态也是不一样的,比如在超市里购物步伐偏慢,而在火车站赶车步伐急促,所以跨域步态识别为“走姿”识身份增加了难度。
而视觉步态识别的目的是利用多个摄像头捕捉到的步态序列来识别一个人。这项任务已经研究了十多年,因为步态是一种无需受试者合作即可远程获取的鉴别生物特征。
由于深度学习在各种计算机视觉任务中取得了巨大成功,基于深度学习的步态识别方法在单个数据集上也取得了优异的性能。然而,在实际应用中,更实际的做法是在从一个场景(即源域)收集的数据集上学习模型,同时将其应用于另一个场景(即目标域)。
什么是可迁移邻域发现算法
作者说可迁移邻域发现算法是:
“如果想让一个小孩识别国内的动物种类,你会给他一些动物图片和对应的动物名字。通过学习,小孩能认出许多动物。你可能觉得还不够,希望小孩能识别国外的动物,于是给小孩一些国外动物的图片,让他把属于同一物种的图片都放到一起进行分类。”由于小孩之前学习了很多国内的动物,一开始会比较顺利,能够挑选出一张或者几张长得最像老虎的放一组、像狮子的放一组,等等。接着,小孩可能会继续寻找那些还长得比较像老虎、狮子等的图片,直到他再也找不到自己学过的图片之后,他发现剩余那些之前没见过的图片里,有好几张长得很类似,于是猜测它们属于一个新物种。小孩可能同时发现好几个新物种,把它们分别放一组,接着继续寻找和这些新物种长得很像的图片。
可迁移邻域发现算法模拟了上述一过程,直到所有图片都被找完为止。可迁移邻域发现算法与传统聚类赋伪标签识别不一样。
---摘抄至第一作者的官方报道。
网络结构
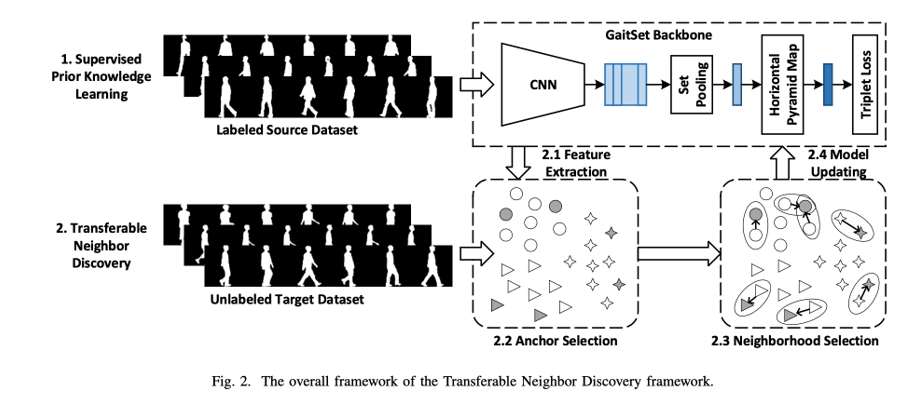
具有两个主要阶段的Transferable Neighborhood Discovery方法。
在第一阶段,我们采用GaitSet作为主干网络,从轮廓序列中学习步态特征。我们在标记的源数据集上训练GaitSet网络来学习gaits的先验知识。
在第二阶段,我们首先用训练好的主干将未标记的目标样本映射到特征空间。然后,利用从源数据中学习到的先验知识,将目标样本分布在流形中。采用样本熵度量的类一致性指标,以渐进的方式选择样本的置信邻域。探索了一种高熵优先策略来选择可信的邻居点,最终用于更新网络。
2.1 GaitSet as the Backbone
为了从步态序列中学习区分性表示,我们采用最先进的基于CNN的模型,即Gait- Set [1],作为TraND框架中的主干网络,根据网络结构图可见。GaitSet网络直接将轮廓序列作为输入,将该序列视为一个集合,但基于轮廓的外观包含其位置信息的假设,忽略帧的顺序。
通过这种方法,首先可以保留所有帧的空间特征,从而对步态表示进行综合建模。然后,我们使用Set Pooling (SP)操作将帧级特征聚合为序列级特征,最后,为了发现多尺度特征,采用水平金字塔映射(HPM)生成步态序列的判别表示,将SP提取的特征映射分解。给定步态轮廓序列。Xk是一个silhouette image, K是一个序列的长度,GaitSet网络的整体过程可以公式化如下:
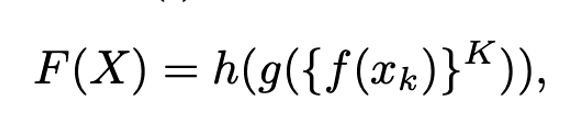
f(·)是提取帧级特征的CNN,g(·)是生成序列级特征的SP函数,h(·)是GaitSet中的HPM操作。
2.2 对先前知识的监督学习
由于我们只有源数据的标签,但没有关于目标域的知识,因此有必要有效地利用源数据集中步态表示的先验知识。
受无监督人员重新识别方法的启发,我们在源数据集上训练主干,由于源数据和目标数据中的ID不重叠,因此最好让模型学习样本之间的相似性或差异,而不是对它们进行分类。因此,我们采用Triplet Loss 代替交叉熵损失进行先验知识学习。

实验结果
3.1 定性结果
下图a是 CASIA-B数据集中一个人在不同条件和视角下的步态序列。图b是 从OU-LP数据集中的四个视点捕获一个人的步态序列。

3.2 定量结果
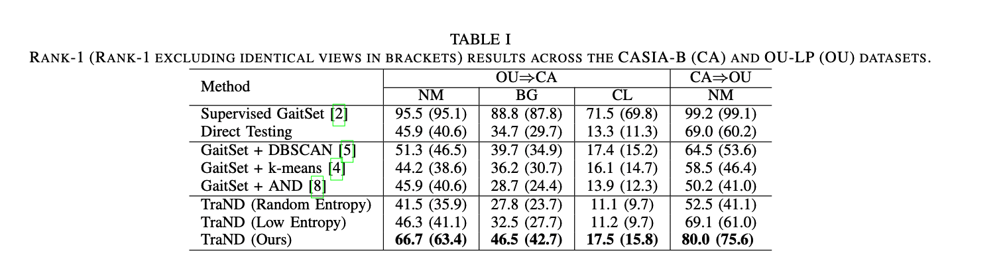
实验结果如表1所示,我们首先可以发现,与在目标数据上训练的模型相比,直接将在源数据上训练的模型应用于目标数据会获得非常差的结果。结果表明,不同数据集之间的领域差异会极大地影响模型的适应能力。
此外,基于聚类的方法,即GaitSet+DBSCAN和Gait-Get+k均值,不能很好地完成这项任务。这是因为聚类算法生成的伪标签可能会产生误导,这会在微调模型时带来大量噪声。通过比较不同的邻域选择策略,我们的方法获得了最好的性能。这反映了我们的方法可以通过类一致性指标和高熵优先策略有效地发现自信邻域。
在OU-LP上训练的模型转移到CASIA-B上的BG和CL条件下时,所有方法的结果都很差。这是因为OU-LP没有有标志的图片,这使得模型们对这些知识一无所知。因此,应进一步研究交叉条件设置,以提高性能。
参考文献: [1] Weijian Deng, Liang Zheng, Qixiang Ye, Guoliang Kang, Yi Yang, and Jianbin Jiao. Image-image domain adaptation with preserved self- similarity and domain-dissimilarity for person re-identification. In IEEE CVPR, pages 994–1003, 2018.
关注下方《学姐带你玩AI》🚀🚀🚀
回复“500”获取AI必读论文合集
码字不易,欢迎大家点赞评论收藏!